Machine_Learning_in_Action02 - K-Nearest Neighbors
K-Nearest Neighbors
KNN algorithm
从文件读数据
画散点图
归一化数值型数据
根据距离分类
- 优点
- 精度高
- 对奇异点不敏感
- 对数据没有假设
- 缺点
- 计算量大
- 需要大量内存
- 数据类型
- 数值型,名词性数值
算法描述
没有训练过程,直接进行分类。当获取了新的数据,遍历已有数据(训练集),计算新数据与每个训练数据的距离,然后按照距离顺序排列,取前k的数据,然后根据这k个数据进行投票,哪个类获得的投票多,那就将新数据分为这一类。
knn实现
import numpy as np
import operator
def createDataSet():
group = np.array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
def classify(intX, dataSet, labels, k):
diff = np.array(dataSet)-np.array(intX)
diff_2 = diff**2
diff_sum = np.sum(diff_2, axis=1)
dist = diff_sum**0.5
sort_idx = np.argsort(dist)
label_count = {}
for i in range(k):
idx = sort_idx[i]
label = labels[idx]
label_count[label] = label_count.get(label, 0) + 1
label_count_sort = sorted(label_count.items(), key=lambda a: a[1], reverse=True)
return label_count_sort[0][0]
if __name__ == '__main__':
dataSet, labels = createDataSet()
x = [0.8,0.2]
target = classify(x, dataSet, labels, k=3)
print('target class:', target)
画散点图
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
def file2matrix(file_name):
with open(file_name) as file:
lines = file.readlines()
lines_num = len(lines)
mat = np.zeros((lines_num, 3))
labels = []
idx = 0
for line in lines:
line = line.strip()
line_split = line.split('\t')
mat[idx, :] = line_split[0:3]
labels.append(int(line_split[-1]))
idx += 1
return mat, labels
if __name__ == '__main__':
mat, labels = file2matrix('datingTestSet2.txt')
print(mat, labels)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(mat[:,1], mat[:,2])
plt.show()
- 结果
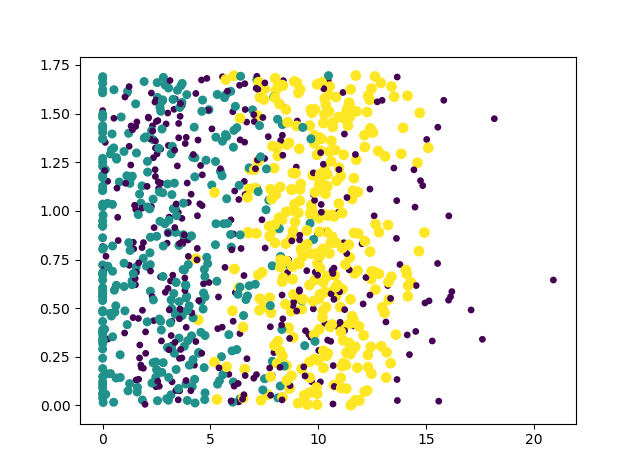
案例分析
def datingClassTest():
hoRatio = 0.10
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify(normMat[i,:],normMat[numTestVecs:m,:], datingLabels[numTestVecs:m],3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
if (classifierResult != datingLabels[i]): errorCount += 1.0
print("the total error rate is: %f" % (errorCount/float(numTestVecs)))
if __name__ == '__main__':
datingClassTest()
手写数字分类
def handwritingClassTest():
hwLabels = []
trainingFileList = os.listdir('digits/trainingDigits')
m = len(trainingFileList)
trainingMat = np.zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('digits/trainingDigits/%s' % fileNameStr)
testFileList = os.listdir('digits/testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('digits/testDigits/%s' % fileNameStr)
classifierResult = classify(vectorUnderTest, trainingMat, hwLabels, 3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0
print("\nthe total number of errors is: %d" % errorCount)
print("\nthe total error rate is: %f" % (errorCount/float(mTest)))
完整代码
import os
import numpy as np
import operator
import matplotlib
import matplotlib.pyplot as plt
def createDataSet():
group = np.array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
def classify(intX, dataSet, labels, k):
diff = np.array(dataSet)-np.array(intX)
diff_2 = diff**2
diff_sum = np.sum(diff_2, axis=1)
dist = diff_sum**0.5
sort_idx = np.argsort(dist)
label_count = {}
for i in range(k):
idx = sort_idx[i]
label = labels[idx]
label_count[label] = label_count.get(label, 0) + 1
label_count_sort = sorted(label_count.items(), key=lambda a: a[1], reverse=True)
return label_count_sort[0][0]
def classify_test():
dataSet, labels = createDataSet()
x = [0.8,0.2]
target = classify(x, dataSet, labels, k=3)
print('target class:', target)
def file2matrix(file_name):
with open(file_name) as file:
lines = file.readlines()
lines_num = len(lines)
mat = np.zeros((lines_num, 3))
labels = []
idx = 0
for line in lines:
line = line.strip()
line_split = line.split('\t')
mat[idx, :] = line_split[0:3]
labels.append(int(line_split[-1]))
idx += 1
return mat, labels
def scatter_test():
mat, labels = file2matrix('datingTestSet2.txt')
print(mat, labels)
fig = plt.figure()
ax = fig.add_subplot(111)
# ax.scatter(mat[:,1], mat[:,2])
ax.scatter(mat[:,1], mat[:,2],
15.0*np.array(labels), 15.0*np.array(labels))
plt.show()
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = np.zeros(np.shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - minVals
normDataSet = normDataSet/ranges
return normDataSet, ranges, minVals
def norm_test():
dataSet, labels = createDataSet()
print(autoNorm(dataSet))
def datingClassTest():
hoRatio = 0.10
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify(normMat[i,:],normMat[numTestVecs:m,:], datingLabels[numTestVecs:m],3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
if (classifierResult != datingLabels[i]): errorCount += 1.0
print("the total error rate is: %f" % (errorCount/float(numTestVecs)))
def classifyPerson():
resultList = ['not at all','in small doses', 'in large doses']
percentTats = float(input("percentage of time spent playing video games?"))
ffMiles = float(input("frequent flier miles earned per year?"))
iceCream = float(input("liters of ice cream consumed per year?"))
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = np.array([ffMiles, percentTats, iceCream])
classifierResult = classify((inArr-minVals)/ranges,normMat,datingLabels,3)
print("You will probably like this person: ", resultList[classifierResult - 1])
## handwritten digits
def img2vector(filename):
returnVect = np.zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = os.listdir('digits/trainingDigits')
m = len(trainingFileList)
trainingMat = np.zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('digits/trainingDigits/%s' % fileNameStr)
testFileList = os.listdir('digits/testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('digits/testDigits/%s' % fileNameStr)
classifierResult = classify(vectorUnderTest, trainingMat, hwLabels, 3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0
print("\nthe total number of errors is: %d" % errorCount)
print("\nthe total error rate is: %f" % (errorCount/float(mTest)))
if __name__ == '__main__':
# classify_test()
# scatter_test()
# norm_test()
# datingClassTest()
# classifyPerson()
handwritingClassTest()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号