第一次个人编程作业
| 这个作业属于哪个课程 | [软件工程] |
|---|---|
| 这个作业在哪里 | 作业要求 |
| 这个作业的目标 | 论文查重 |
作业链接
预计PSP表格
| PSP 各个阶段 | 自己预估的时间(分钟) | 实际的记录(分钟) |
|---|---|---|
| 计划 | 60 | |
| 需求分析 (包括学习新技术) | 60 | |
| 生成设计文档 | 20 | |
| 设计复审 | 25 | |
| 代码规范 (为目前的开发制定合适的规范) | 10 | |
| 具体设计 | 60 | |
| 具体编码 | 180 | |
| 代码复审 | 60 | |
| 测试(自我测试,修改代码,提交修改) | 40 | |
| 报告 | 50 | |
| 测试报告 | 30 | |
| 计算工作量 | 25 | |
| 事后总结, 并提出过程改进计划 | 60 | |
| 合计 | 680 |
计算模块接口的设计与实现过程
1.application中的main方法来接收3个参数
2.通过Hanlp分词器进行处理
3.calculation算法进行两篇文章比较
4.outPutFile对答案输出进行处理
算法关键
余弦相似度算法:一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。
举一个例子来说明,用上述理论计算文本的相似性。为了简单起见,先从句子着手。
句子A:这只皮靴号码大了。那只号码合适
句子B:这只皮靴号码不小,那只更合适
怎样计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,列出所有的词。
这只,皮靴,号码,大了。那只,合适,不,小,很
第三步,计算词频。
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第四步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
第五步,根据余弦向量公式计算
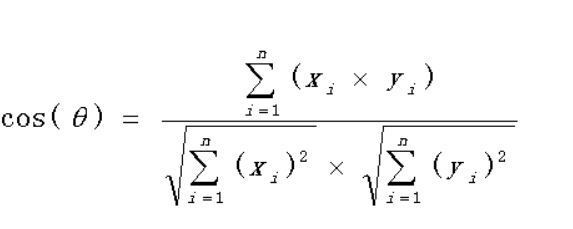
性能分析


单元测试展示
@BeforeClass
public static void beforeTest(){
System.out.println("=======测试即将开始========");
}
@AfterClass
public static void afterTest(){
System.out.println("=========测试结束==========");
}
/*
输入空文件
E:/test/empty.txt是我创建的空文本
*/
@Test
public void example2(){
String [] test={"E:/test/orig.txt","E:/test/empty.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException a) {
a.printStackTrace();
Assert.fail();
}
}
/*
输入错误的路径
输入一个空路径
输出路径也为空
*/
@Test
public void example1(){
String [] test={"","E:/test/orig.txt ",""};
try {
new application.application().main(test);
} catch (IOException a) {
a.printStackTrace();
Assert.fail();
}
}
/*
输入错误的输出文件路径
E:/test是我本地文件夹
*/
@Test
public void example3(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_add.txt","E:/test"};
try {
new application.application().main(test);
} catch (IOException a) {
a.printStackTrace();
Assert.fail();
}
}
/*
原文本与其他文本测试
*/
//测试调换语序文本
@Test
public void example6(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_dis_1.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException a) {
a.printStackTrace();
Assert.fail();
}
}
//测试调换语序文本
@Test
public void example7(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_dis_10.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException a) {
a.printStackTrace();
Assert.fail();
}
}
//测试调换语序文本
@Test
public void example8(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_dis_15.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException a) {
a.printStackTrace();
Assert.fail();
}
}
//测试增加20%的文本
@Test
public void example4(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_add.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException a) {
a.printStackTrace();
Assert.fail();
}
}
//测试删除20%的文本
@Test
public void example5(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_del.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException a) {
a.printStackTrace();
Assert.fail();
}
}
//测试相同文本
@Test
public void example9(){
String [] test={"E:/test/orig.txt","E:/test/orig.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException a) {
a.printStackTrace();
Assert.fail();
}
}
//测试相同文本
@Test
public void example10(){
String [] test={"E:/test/orig_0.8_dis_1.txt","E:/test/orig_0.8_dis_1.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException a) {
a.printStackTrace();
Assert.fail();
}
}
}
实际PSP表格
| PSP 各个阶段 | 自己预估的时间(分钟) | 实际的记录(分钟) |
|---|---|---|
| 计划 | 60 | 50 |
| 需求分析 (包括学习新技术) | 60 | 120 |
| 生成设计文档 | 20 | 25 |
| 设计复审 | 25 | 30 |
| 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| 具体设计 | 60 | 60 |
| 具体编码 | 180 | 180 |
| 代码复审 | 60 | 70 |
| 测试(自我测试,修改代码,提交修改) | 40 | 50 |
| 报告 | 50 | 50 |
| 测试报告 | 30 | 30 |
| 计算工作量 | 25 | 25 |
| 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 465 | 765 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号