


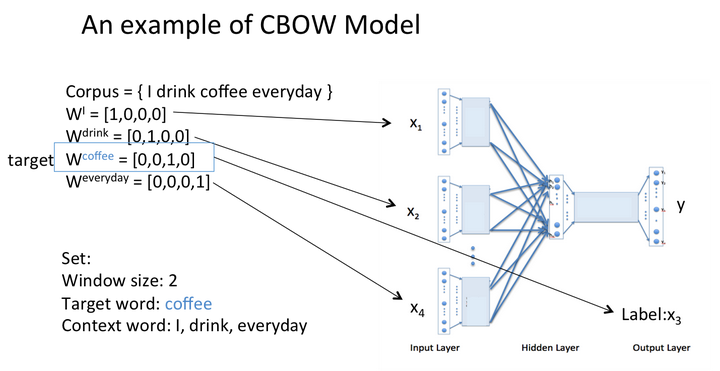
假设我们现在的Corpus是这一个简单的只有四个单词的document:
{I drink coffee everyday}
我们选coffee作为中心词,window size设为2
也就是说,我们要根据单词"I","drink"和"everyday"来预测一个单词,并且我们希望这个单词是coffee。
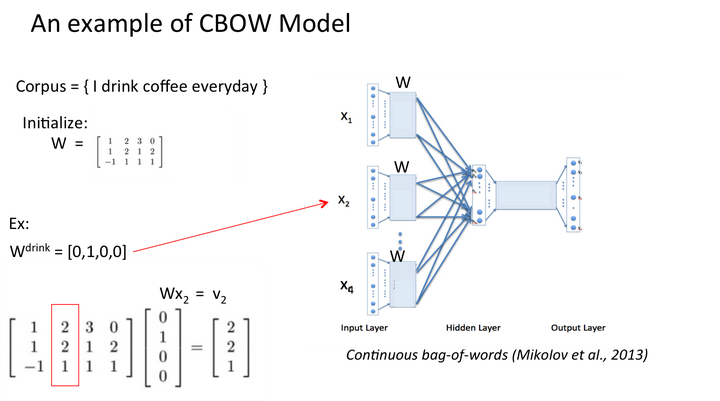
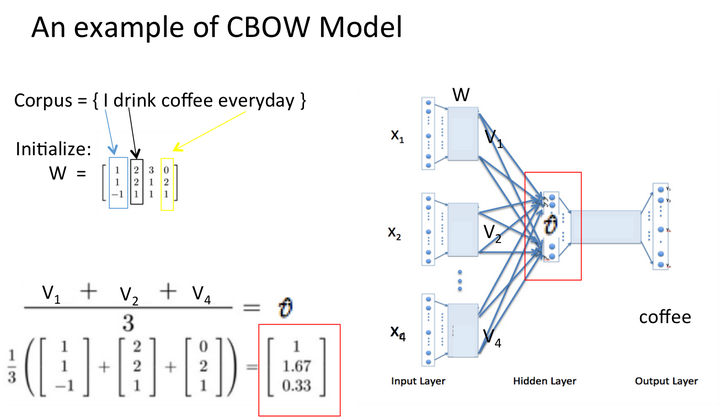
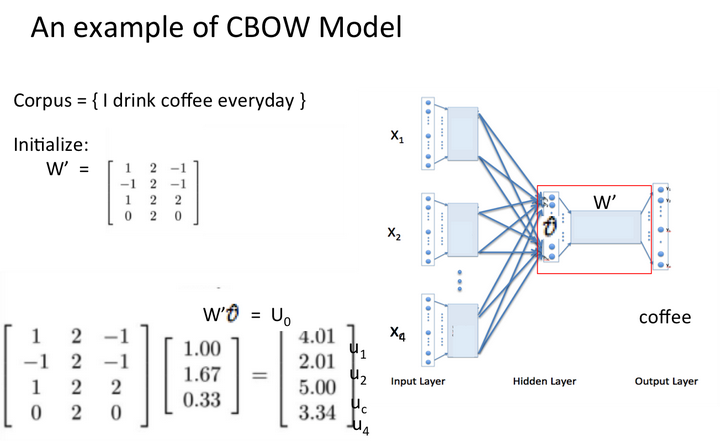
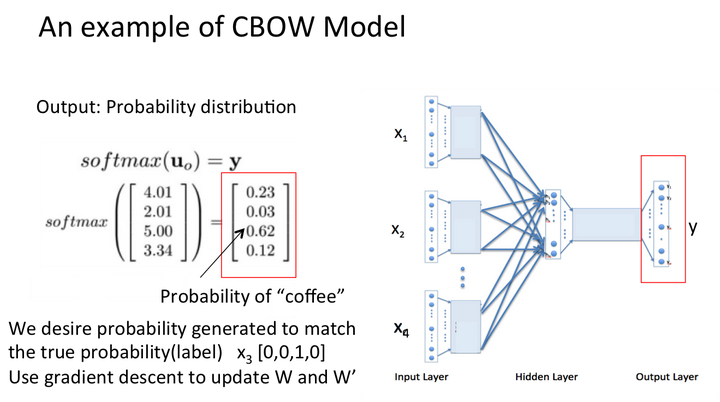
假设我们此时得到的概率分布已经达到了设定的迭代次数,那么现在我们训练出来的look up table应该为矩阵W。即,任何一个单词的one-hot表示乘以这个矩阵都将得到自己的word embedding。
