FPGA相关的一些基础概念以及知识储备
一、FPGA基本结构及原理
- FPGA(Field Programmable Gate Array,现场可编程门阵列)是一种可以通过反复重新编程来实现用户所需逻辑电路的半导体器件。
- 逻辑代数对偶关系:如果对换逻辑表达式中的逻辑值0和1、逻辑运算符与和或,对换后得到的新逻辑表达式与对换前的表达式运算顺序不变,那么新逻辑表达式就称为原逻辑表达式的对偶式。
- 逻辑函数的描述方式:
1.逻辑表达式:描述运算过程的算式,由逻辑运算符、任意逻辑变量、必要的括号、常数值0或1组成。先在各个逻辑变量内代入逻辑值0和1,然后依照逻辑表达式的计算步骤计算这些组合,就可以得到值为0或1的计算结果。即逻辑表达式定义了具有某种逻辑功能的逻辑函数。
a.逻辑变量以原变量或反变量的形式出现,统称为字面量,其逻辑与的项叫积之和,包含所有字面量的与项称为最小项。
b.字面量或的项叫做和之积,包含所有逻辑变量的或项叫做最大项。
2.真值表:针对逻辑函数所有可能的输入组合意义列出输出值,就可以得到真值表,描述逻辑函数的逻辑表达式可以有许多个,但其真值表只有一个,实现真值表所定义的功能的电路称为查找表(Look-Up Table,LUT),是当前FPGA的基本单元。从真值表推导逻辑表达式的方式有两种:
a.在真值表输出为1的行中取输入变量的与项(最小项),然后将这些与项相或,即可得到标准积之和表达式。
b.在真值表输出为0的行中取输入变量的或项(最大项),然后将这些或项相与,即可得到标准和之积表达式。
3.逻辑门
- 组合逻辑电路:不包含记忆元件,某时间点的输出(逻辑函数值)仅取决于当时的输入。允许有多个输入/输出,内部由与(AND)、或(OR)、非(NOT)基本逻辑门以及门电路间的连线组成,实现逻辑电路的器件为PLA(Programmable Logic Array,可编程逻辑阵列)
- 时序逻辑电路:含有记忆元件的逻辑电路,当前的输入并不足以确定当前的输出,过去的电路状态也会对输出产生影响。
a.同步时序逻辑电路:输入和内部状态的变化由时钟信号控制同步进行
b.异步时序逻辑电路:没有统一的时钟信号,电路状态的改版依靠外部输入信号变化直接作用。
- 有限状态机(Finite State Machine,FSM):时序逻辑电路中过去的输入所形成并保留下来的状态对当前的输出有影响,可以用FSM来描述该状态。米勒型(Mealy)输出由内部状态和输入共同决定,摩尔型(Moore)输出仅由内部状态决定。米勒型状态数通常比莫尔型少,然而由于输入会立刻反映到输出,所以逻辑元件或不等长的布线所带来的信号延迟容易引起信号竞争,进而导致非预期的错误输出(冒险)。相比之下摩尔型直接使用记忆状态的输出,因此电路速度快且不容易发生冒险,但电由于状态数多,电路规模相对较大。
- 同步电路设计将系统状态的变化与时钟信号同步,通过这种理想的方式降低电路设计难度,同步电路设计是FPGA设计的基础。
- 触发器:
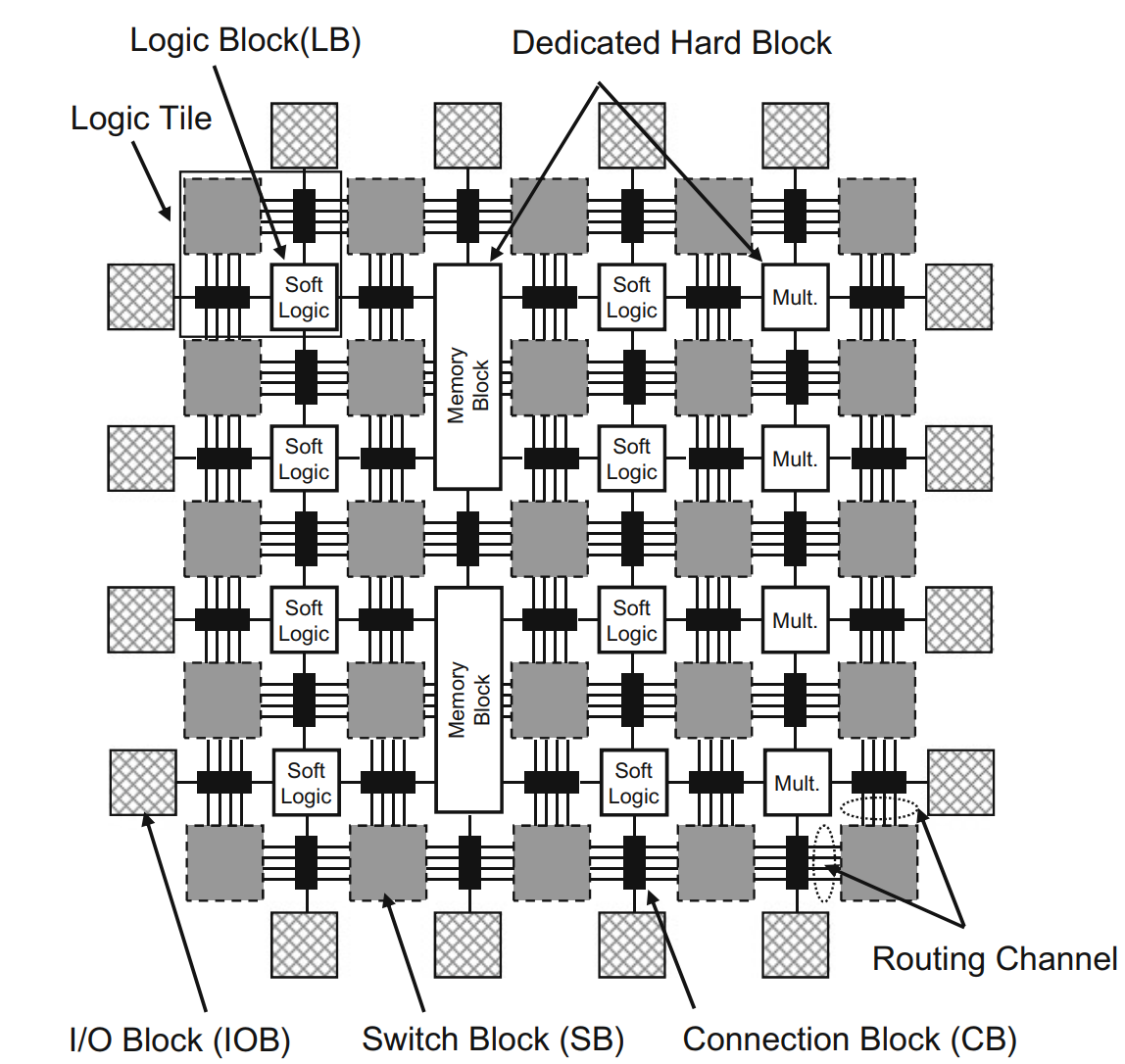
1.逻辑块
- 逻辑块(Logic Block,LB):基本要素都包含基本逻辑单元(Basic Logic Element,BLE),BLE又由 实现组合逻辑的查找表(LUT)、实现时序逻辑的触发器(FF)以及数据选择器(MUX)构成。数据选择器在配置存储器比特位MO的控制下选择直接输出查找表的值还是触发器中的值。
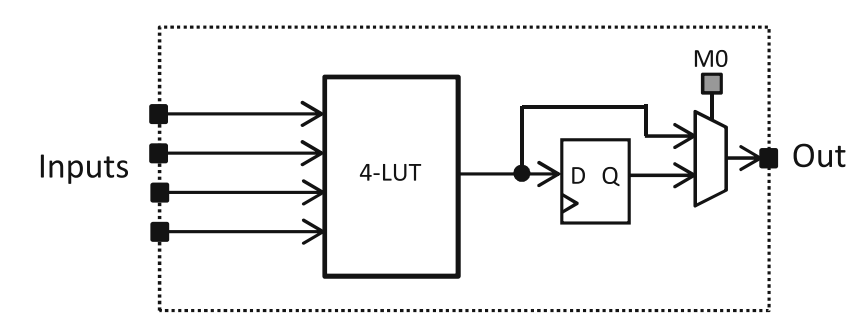
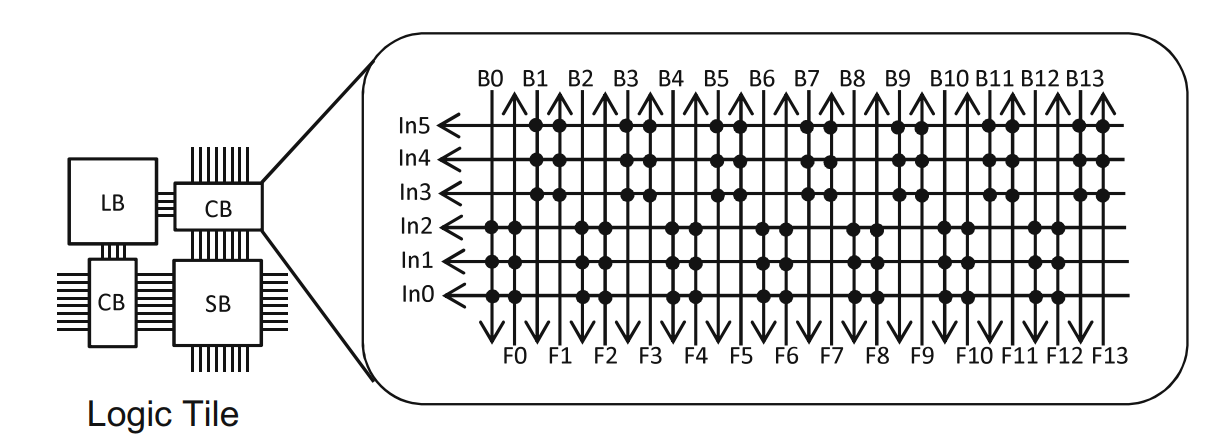
- LUT的逻辑实现:LUT-k是由2k个SRAM单元和2k-1个数据选择器组成,可以看到是从右往左,从上到下开始索引,X作为最右端的那一个MUX的sel信号,Y作为中间两个MUX的sel,Z负责最左边四个MUX的sel。根据XYZ的不同取值去到的不同路径最终将索引到的对应的M的值赋给f作为最终输出。2k个SRAM单元,每个单元可以是0/1两种状态,所以一共有22k种逻辑函数。使用LUT时,可先将函数值f写入配置内存M中,然后在电路中就可以根据输入值的组合对结果进行查找。当所要实现的逻辑函数的输入数比LUT支持的输入数要多时,可以联合使用多个LUT来实现。
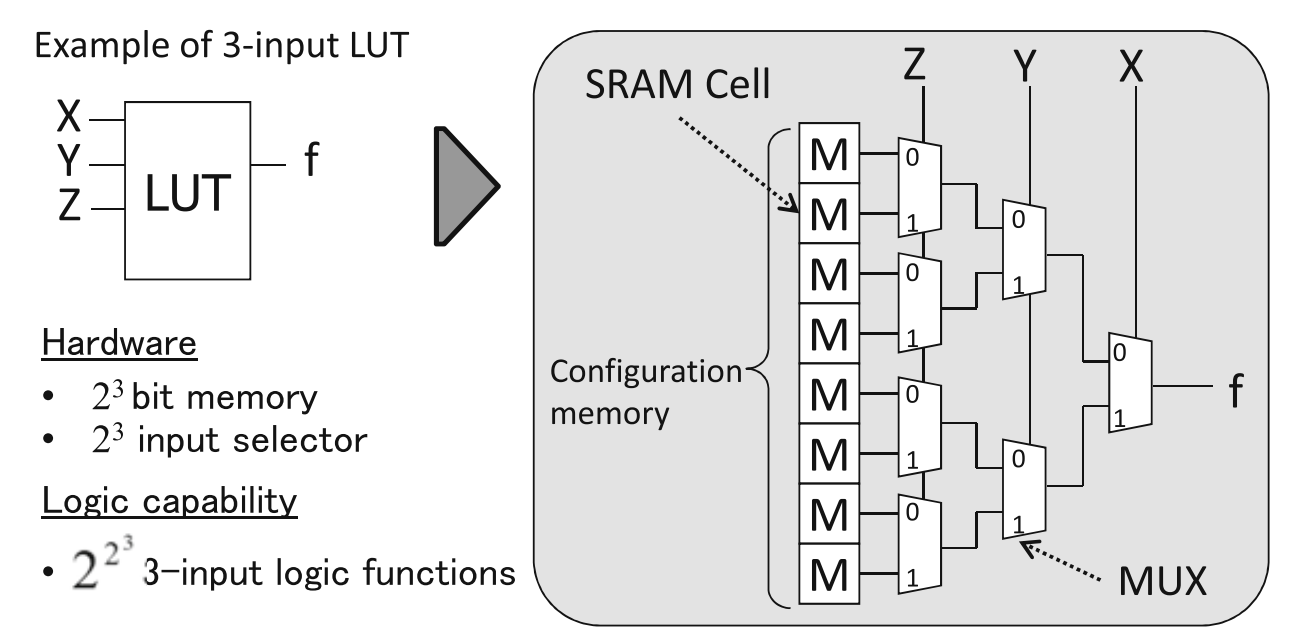
- LB大小对面积影响:如果增加每个LB的功能,就可能以更少的LB实现电路,但是LB自身面积和输入输出数量会增大。对LB功能影响最大的是LUT的大小,采用较大的查找表有助于减少LB的使用数量,但是k-LUT需要2k个配置存储单元,因此LB自身的面积会增大,此外LB输入输出引脚数量的增大也会导致布线面积的增大;FPGA的总面积=LB块数x单位可重复LB面积,所以FPGA的总面积也会受到影响。
- LB大小速度影响:如果增加每个LB的功能,所实现电路的逻辑深度(logic depth)就更小,但同时会增加LB自身的内部延迟。逻辑深度是指通过关键路径的LB块数量,它由FPGA设计环节中的技术映射过程决定。降低逻辑深度可以有效减少布线,从而提高电路速度。增加LB功能的同时会增加内部延迟,逻辑深度也就较深。
- 总的来说,增大LUT输入k可以降低逻辑深度,有助于加快电路速度,但是实际输入数小于k时会产生资源浪费;而减小LUT输入k会增加逻辑深度,从而降低电路速度,但是有助于改善面积效率。
- 在决定LB结构时,除了LUT的输入大小k以外,评测使用的面积模型、延迟以及制程的影响也很大。经过测试,LUT-6的面积速度最适合。
- 专用进位逻辑:为提高算术运算电路的性能,FPGA LB块中还有专用的进位电路。下图中的两个全加器为专用进位逻辑,FA0的进位输入(carry_in)连接到相邻逻辑块的进位输出(carry_out),这条路径称为高速进位链。
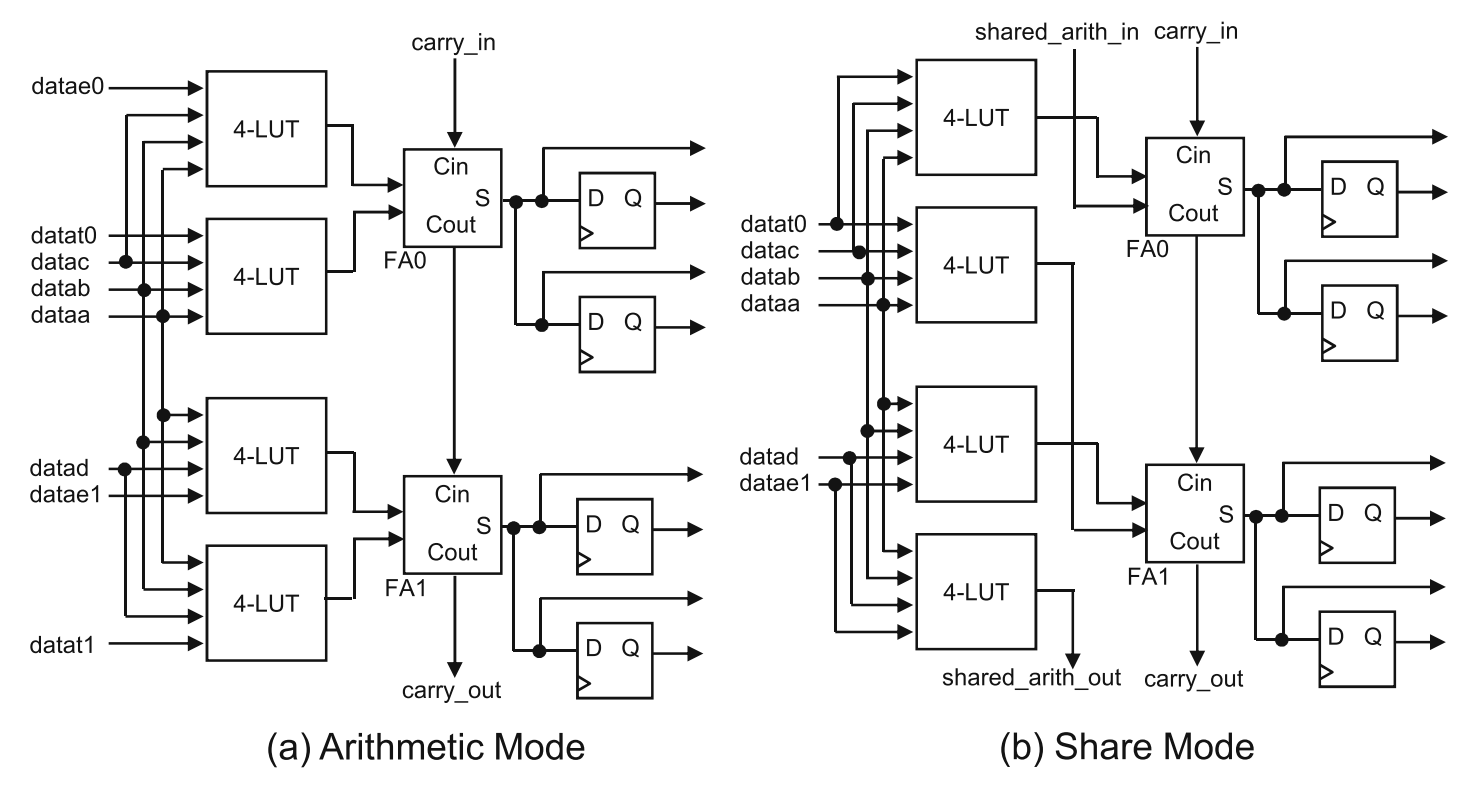
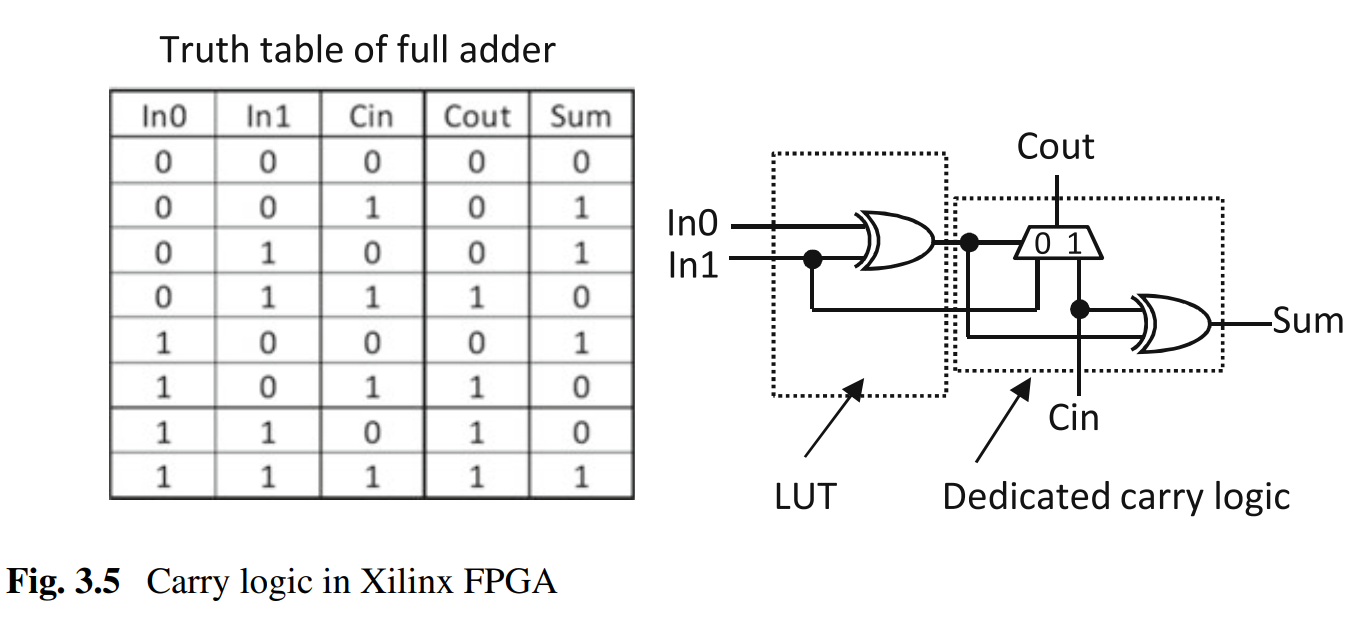
Xilinx没用设计专用的全加器电路,而是使用查找表和进位生成电路的组合来实现加法,其中加法部分Sum用两个2输入的EXOR实现,而进位输出Cout由一个EXORE和1个MUX组成。前一级的EXORE由LUT实现,后一级的MUX和EXORE使用专用电路,它的进位信号也通过进位链和相邻的LB块连接来实现多位加法器。
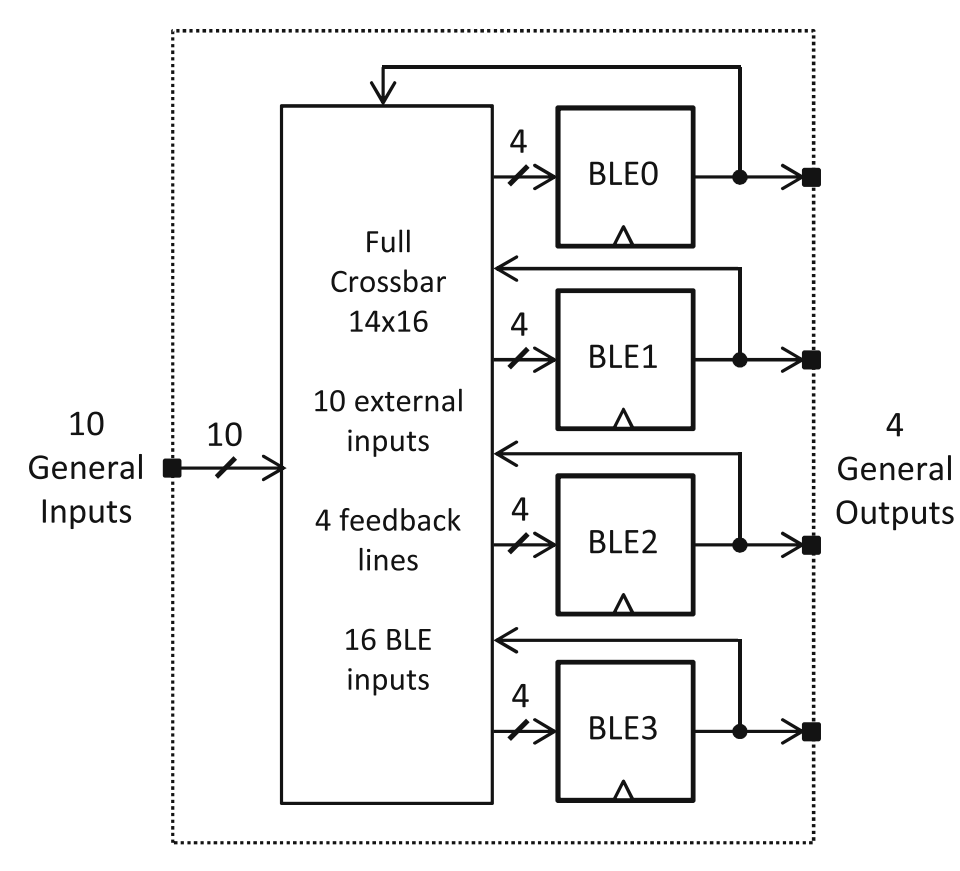
2.逻辑簇
- 逻辑簇:由多个BLE群组化形成的逻辑块结构,可以提高逻辑块的功能性又不额外增加LUT的输入数。它的结构如下所示,有通用的外部输入10个,每个BLE到全交叉矩阵的反馈线4根,每个BLE有4个输入,4x4=16,总共需要的16大于外部输入10,这是怎么办到的呢?因为在这个全交叉矩阵中外部输入对于其中所有的BLE都是共享的。称这个全交叉矩阵的规模是14x16,其中的14是10+4得来的。逻辑簇有以下三个特点:
1.逻辑簇内的局部布线采用硬连线相连,比外部的通用布线速度更快。
2.内部布线负载电容比外部通用布线电容负载更小,对于FPGA动态功耗之类的耗电更友好。
3.内部BLE可以共享外部输入,可以减少局部连接块的开关数量。
逻花簇最大的优势在于在增加功能性的同时又不会大幅度影响FPGA的面积。我们知道查找表的面积会随着BLE输入k的增大呈指数增长,而增加逻辑簇中BLE的个数N,逻辑块的面积只按二次函数增长。经验公式:I = k(N+1)/2 拿上图举例,单个BLE输入k为4,逻辑簇中BLE个数为4,代入后可算出I = 10。如果不用逻辑簇,那么逻辑块总共需要I = N x k =16个输入。研究表明逻辑簇中N取3~10 k取4~6最佳。
3.自适应LUT
- 自适应LUT:逻辑块输入k可变的方案。
4.布线架构
- 布线架构:布线架构又分为全局布线架构和详细布线架构两种,全局布线架构主要解决LB块的连接、布线通道宽度等高层次问题,而不关心开关细节。详细布线架构则要决定具体的连接方式,比如LB块和布线通道间的开关布局等。全局布线架构中全连接和一维连接已经失去市场,现在主要是二维(岛型)和层次型布线结构。
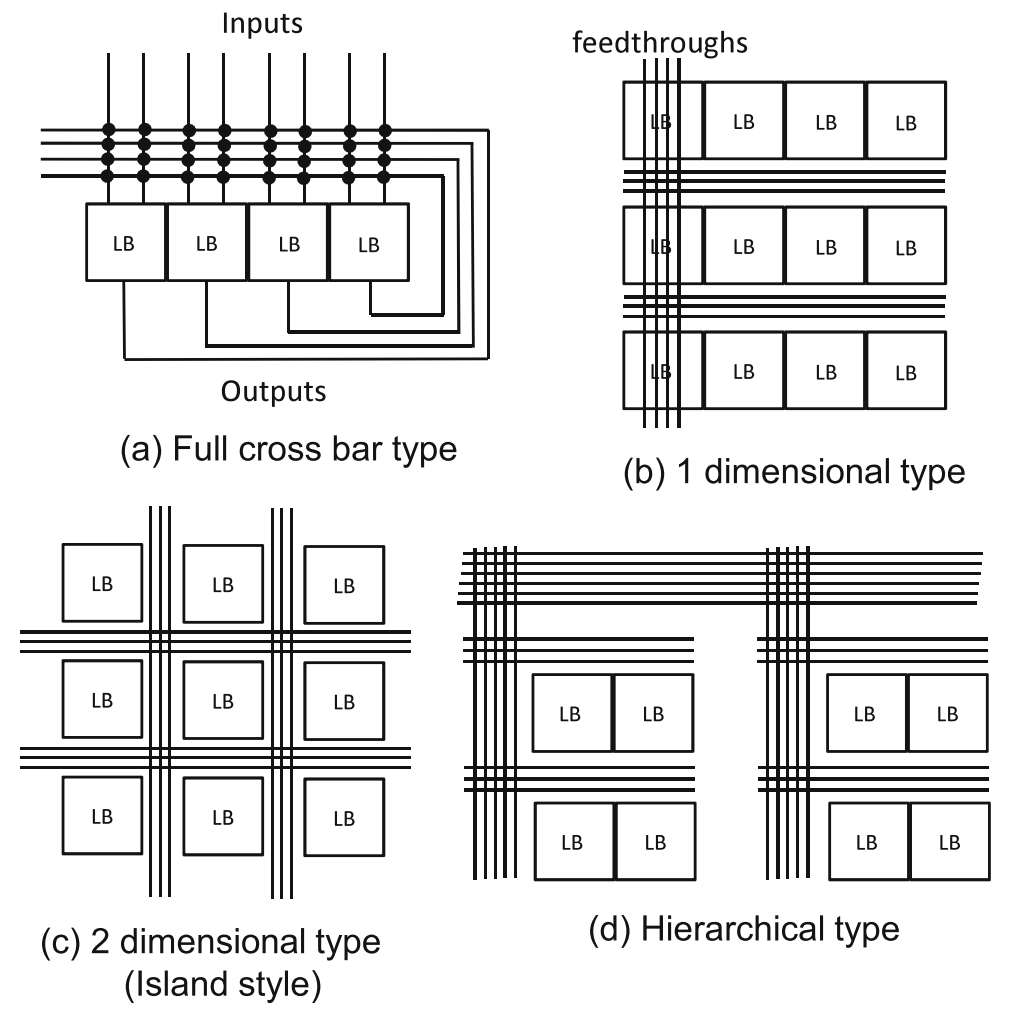
- 全局布线架构
1.层次型布线架构中第一层最低层次用来实现分组内多个LB之间的布线,高层次用来实现低层次之间的布线连接,层次越高通道里连线的数量就越多,布线的交点上包含着各层上的开关,同层次内的连接所需开关少,所以信号传输速度快,一旦跨层连接延迟就会增大。
2.岛型布线结构是近些年多采用的布线结构,LB呈阵列状布置,它们之间具有横向和纵向的布线通道,布局布线时可以更快地计算延迟。
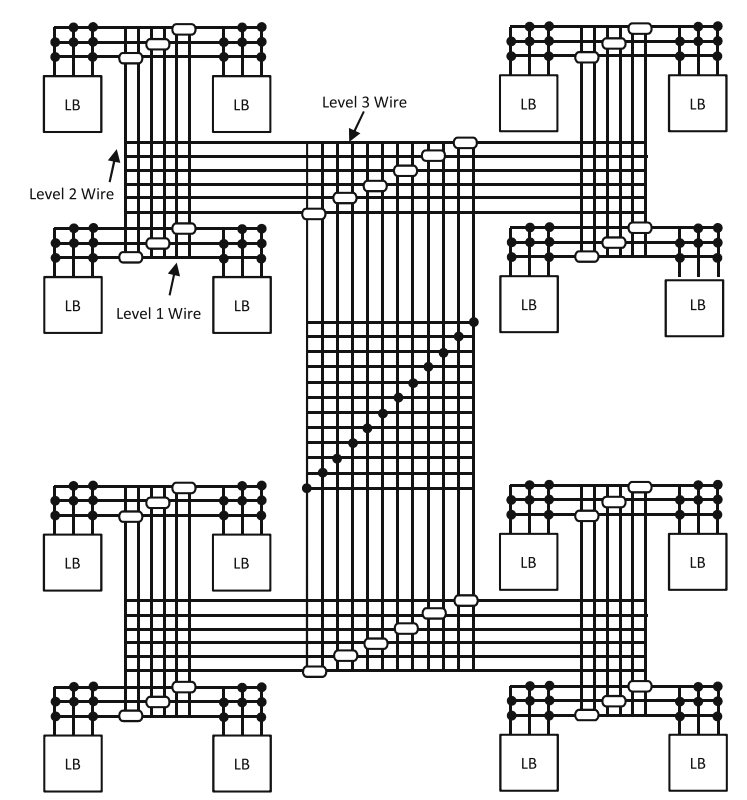
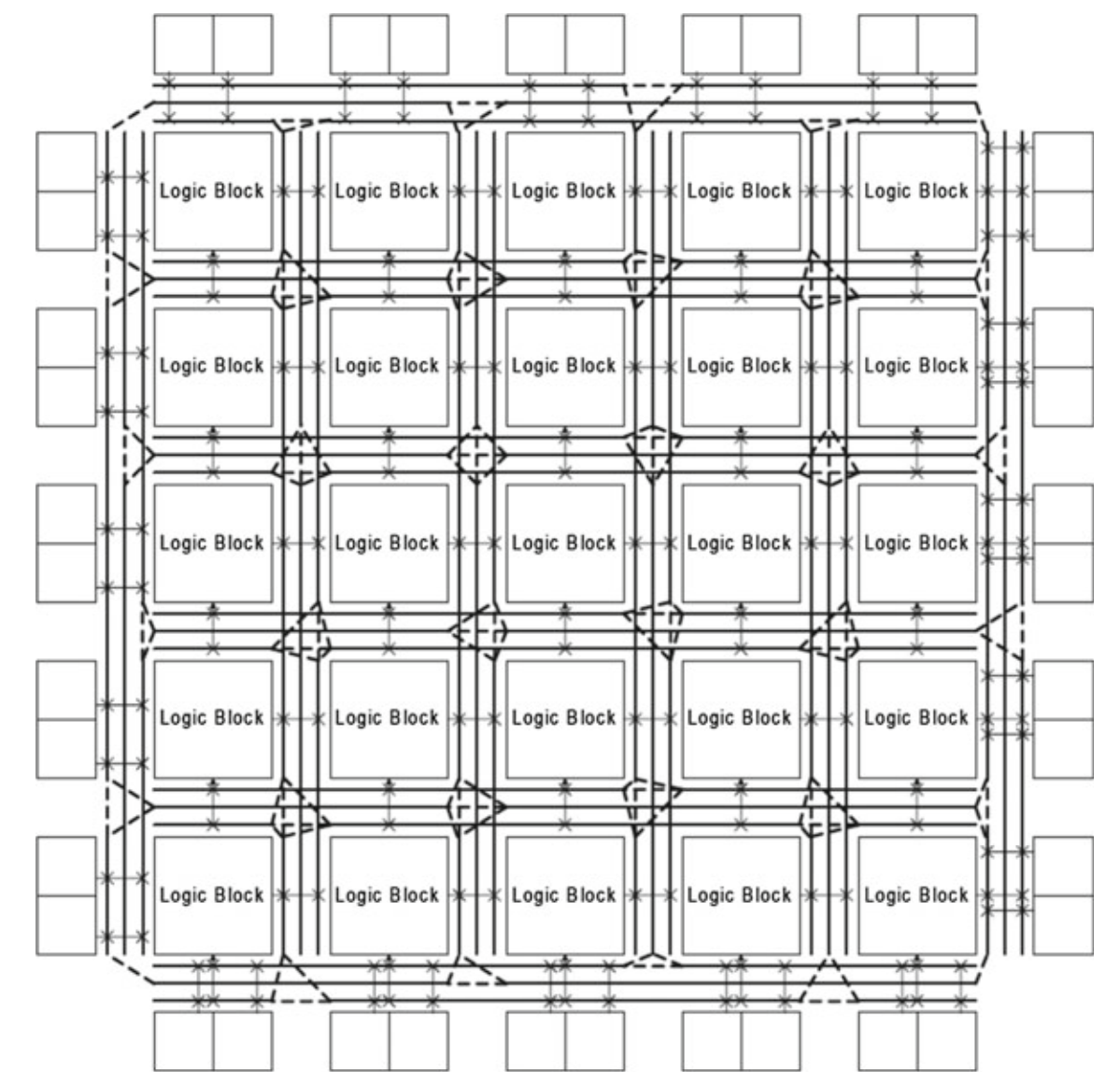 、
、
- 详细布线架构
在详细布线架构中需要确定LB和布线通道之间的开关布置以及布线的线段长度,连接LB和布线通道之间的连接块(CB)有输入型和输出型两种,纵向和横向布线通道的交叉处有可编程开关块(SB)。布局布线时会同时用到短距离、中距离、长距离三种长度的布线线段,布线线段长度指连线所跨越的LB的数量,此外,Xilinx还有跨越整个器件的长距离连线,传输信号的连接线还分单向和双向。
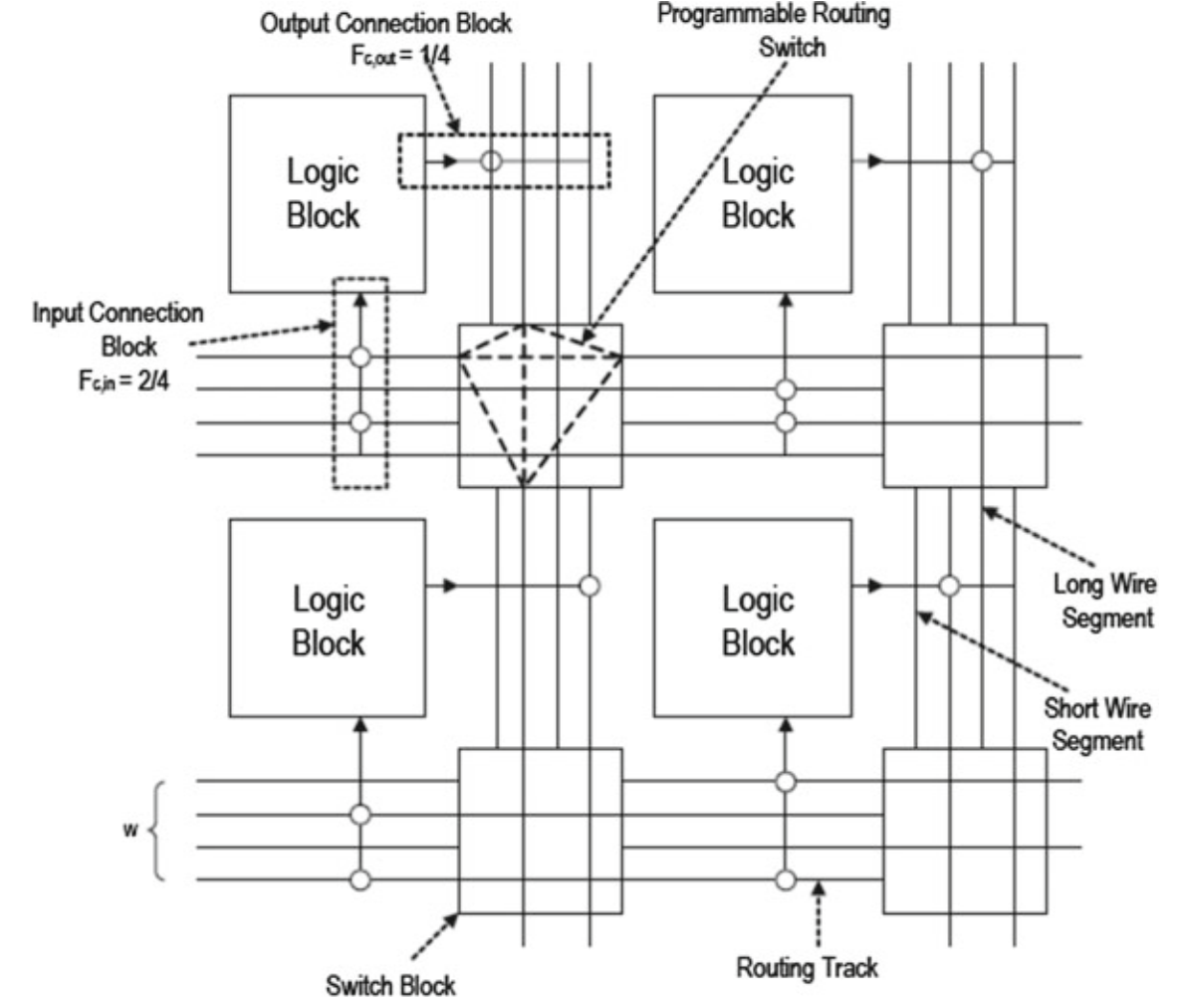
5.开关块
- 开关块(SB):可编程布线开关块(SB)位于横向和纵向布线通道的交叉处,通过CB来控制布线路径。有传输晶体管和三态缓冲器两种,前者由于会影响信号质量用于短路径中,后者适合驱动长距离连线。
6.连接块
- 连接块(CB):连接块也由可编程开关构成,其功能是连接布线通道和LB之间的输入/输出。
7.I/O块
- I/O块:负责器件的I/O引脚与LB之间的接口部分。FPGA的I/O除了固定用途的电源、时钟等专用引脚,还有用户可配置I/O,近些年FPGA I/O块的结构大致如下图所示,有以下几个特征:
1.输出部分有上拉和下拉电阻,可以让输出锁定为0或者1。
2.输出使能信号OE控制输出缓冲器。
3.输入/输出各自都有触发器,可以用来调整信号延迟。
4.输出缓冲器的转换速率可调。
5.输入缓冲器阈值符合TTL或者CMOS标准。
6.MUX6带有延时电路,可以用来保证输入的保持时间。
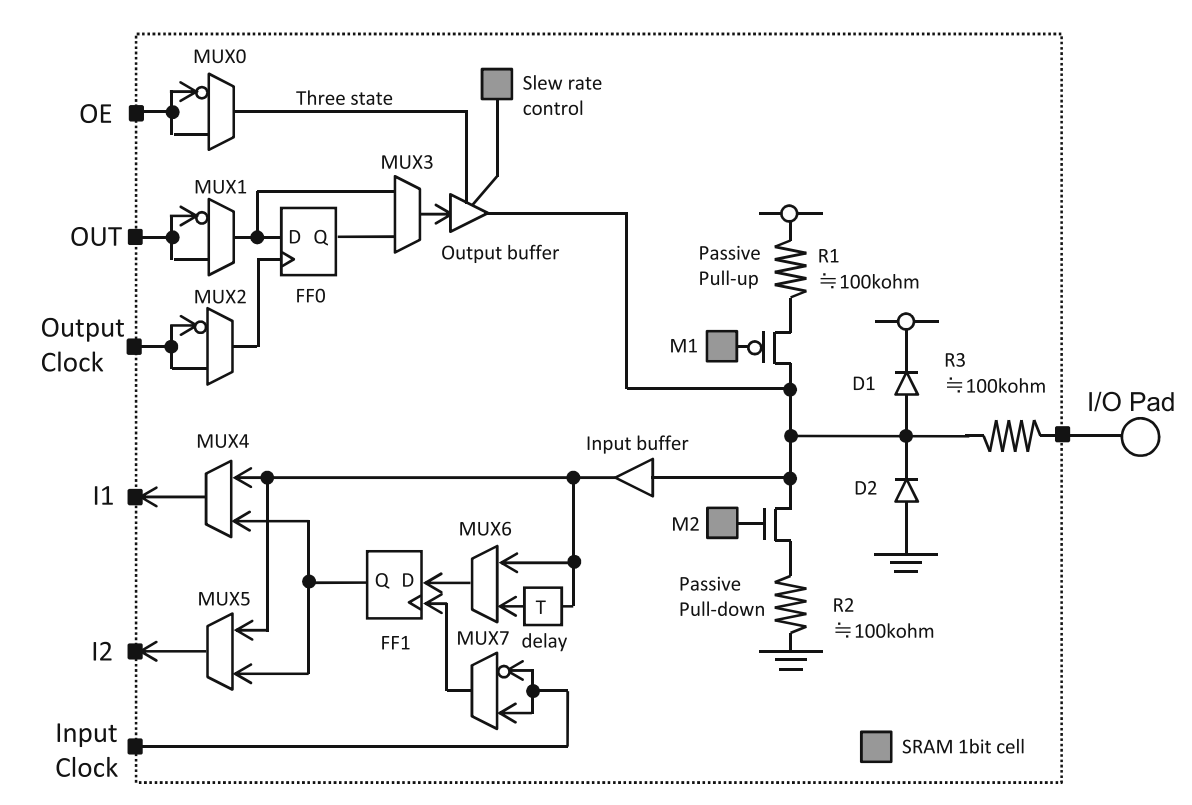
- 近些年FPGA将多个I/O划分成一组,并以I/O分组为单位进行功能划分和管理,不同器件中每个分组里的I/O引脚数都不相同,每个分组内共享电源电压和参考信号不同,对于不同的I/O规格
8.DSP块
- DSP块:Digital Signal Processing,数字信号处理。像FIR(Finite Impulse Response,有限脉冲响应)滤波器、高速傅里叶变换等此类需要大量乘法运算的应用,如果使用乘法器,需要输入的信号就会非常多,基于逻辑块的查找表实现需要大量逻辑块相互连接,布线延迟会增大,运算性能就会受限,DSP块集成了诸多如乘法器等复杂运算功能,专门用来进行数字信号处理。
- 下图为Xilinx 7系列采用的DSP48E1 slice结构,其中前端为25位x18位的带符号整数乘法器,后端是48位累加运算单元。在信号处理领域,将累乘结构累加的情况非常多,即MACC(Multiply-Accumulate),AxB+Y,将最后一级寄存器输出反馈为操作数,就可以独立完成MACC运算。48位累加器可以实现加减法,也可以用作逻辑运算等其他多种运算器,具体实现哪种运算器可以通过编程指定,该DSP Slice可以实现3值相加、桶式移位器等各种各样的运算。此外,48位模式检测器还可以用于计数器的触发检测、运算结果的范围检测等多种用途。运算器间的寄存器还可以帮助实现运算的流水线化。
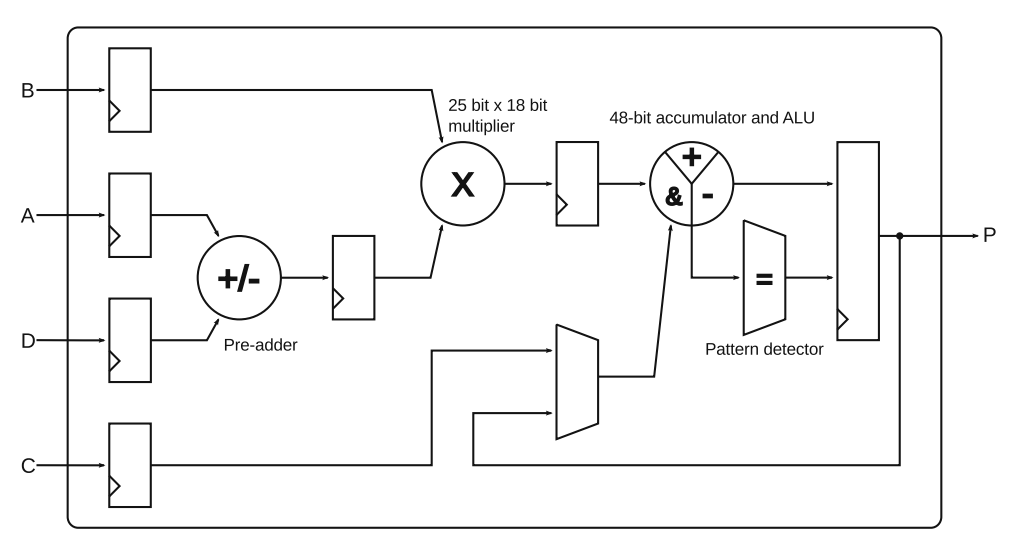
- 运算粒度是指运算器的位数,当运算所需要的粒度大于硬核块粒度时,需要结合多个块来实现,多个块之间的布线就会影响运算性能,当运算需要的粒度小于硬核粒度时,就会闲置部分硬件资源,面积使用率就会降低,像Xilinx 的DSP48E1 slice采用了:1.级联路径机制 两个相邻的slice之间设有专用的高速连接路径,可以直接连接2个slice实现多位运算,不需要消耗通用逻辑资源。 2. SIMD运算(Single Instruction Stream Multiple Data Stream,单指令流多数据流),可以实现4个独立的12位加法或2个24位的加法。
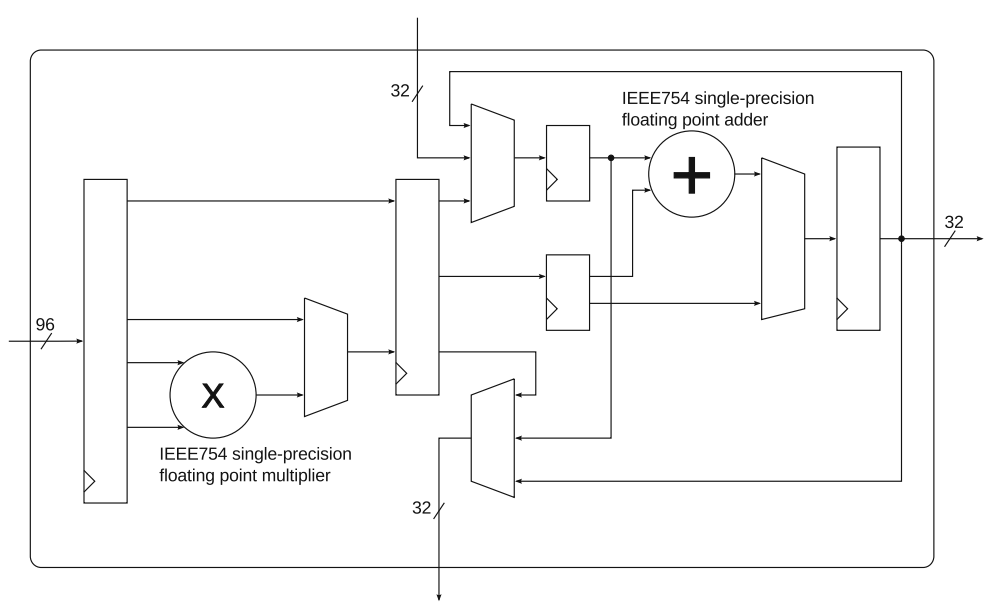
- Alteral多种系列也有不同的DSP块,如下所示,该DSP块的结构中就包含了单精度浮点数乘法器和单精度浮点数加法器用来进行多乘加浮点数复杂运算,该结构也有专用路径来进行相邻slice间的级联。该架构还可以进行18位、27位定点数运算。
- DSP使用方式:同一种运算可以选择用DSP块实现,也可以选择用逻辑块实现,DSP块实现其运算性能更强,但是FPGA中的DSP块资源是有限的,使用时要进行注意。当调用IP库里已有的运算器或信号滤波器IP时,只要该IP可以在DSP块上实现,就可以通过工具选择是否使用DSP块实现该IP。按照FPGA厂商推荐的方式编写运算器程序,逻辑综合工具就能自动识别并使用DSP块,该方式可以在不同架构甚至不同厂商FPGA之间具有可移植性。此外,还可以在代码中直接实例化DSP块的模块,从而实现低层次的访问,但是不具有移植性。
9.硬宏
- 硬宏:hard macro,即用于专用集成电路(asic)或现场可编程逻辑阵列(fpga)中的预先设计好的电路功能模块,硬宏的逻辑在其本身内部已经集成好,根据工艺库进行调用即可。这样比用户自行设计再占用逻辑资源更高效;FPGA上一般有硬件乘法器、DSP块、PCIE接口、高速串行通信接口、外部DRAM接口、模拟数字转换器接口等常见硬宏。在外围电路设备高速化以及高频时钟驱动接口电路多样化的趋势下,接口电路硬核化十分必要。
- 在FPGA上实现完整的复杂系统,微处理器(Micro Process Unit,MPU,区别于MCU,即Micro Control Unit,MCU,微控制单元,MPU更侧重于需要复杂计算及高速数据交互的场景,MCU更适合于对外设进行控制的简单低阶消费电子领域)一般是必不可少的,FPGA可以通过调用基本部件以纯逻辑电路的形式实现处理器,以这样的方式实现的处理器称为软核处理器,Xilinx 有MicroBlaze软核,Alteral有Nios II软核。由于是通过纯逻辑电路的形式实现的,软核处理器的性能受限,因此有作为硬宏嵌入的硬核处理器,Xilinx和Alteral嵌入的都是ARM处理器,Xilinx家这样的产品就是SOC系列产品,如Zynq-7000,Alteral 也有这样的FPGA产品。
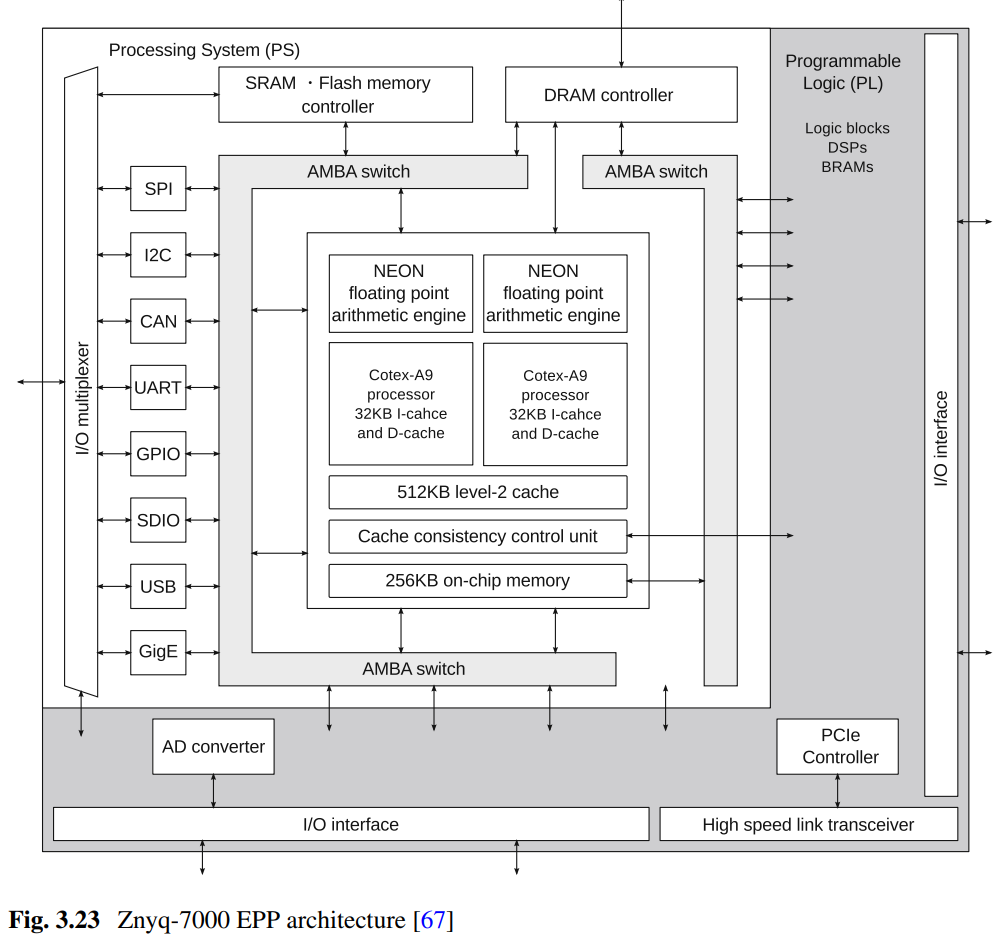
- 上图所示就是Zynq-7000 EPP(Extensible Processing Platform)架构,可以看到该芯片分为处理器部分和可编程逻辑部分。硬核处理器搭载了拥有两颗ARM Cortex A9核心的多核处理器,可以直接运行Linux等通用OS。外部的存储器接口以及各种输入/输出接口控制器全部硬宏化,并通过AMBA总线和处理器连接。可编程逻辑部分和普通FPGA相同,由基于LUT的逻辑块、DSP块以及嵌入式存储器等组成。只要用户遵从标准设计电路接口, 就可以将可编程逻辑上的用户电路连接到AMBA交换模块上,然后再跟硬核处理器相连,通过这种方式可以实现硬件电路的加速。
10.嵌入式存储器
- 早期FPGA架构中只使用基于LUT和触发器的逻辑块实现电路,可用作存储要素的只有逻辑块中的触发器,因此很难在芯片内保存大量的数据,如果要保存大量的数据要在FPGA上连接外部存储器,但是FPGA和外部存储器间的带宽会成为系统的瓶颈。后来FPGA架构开始集成高效的片上存储器,这些FPGA内部的存储器统称为嵌入式存储器,内部主要含有两种嵌入式存储器:
1.存储器块硬宏:即以硬宏的形式在架构中嵌入存储器块。Xilinx公司的架构中,这种硬宏型存储器块被称为块存储器(Block RAM,BRAM).
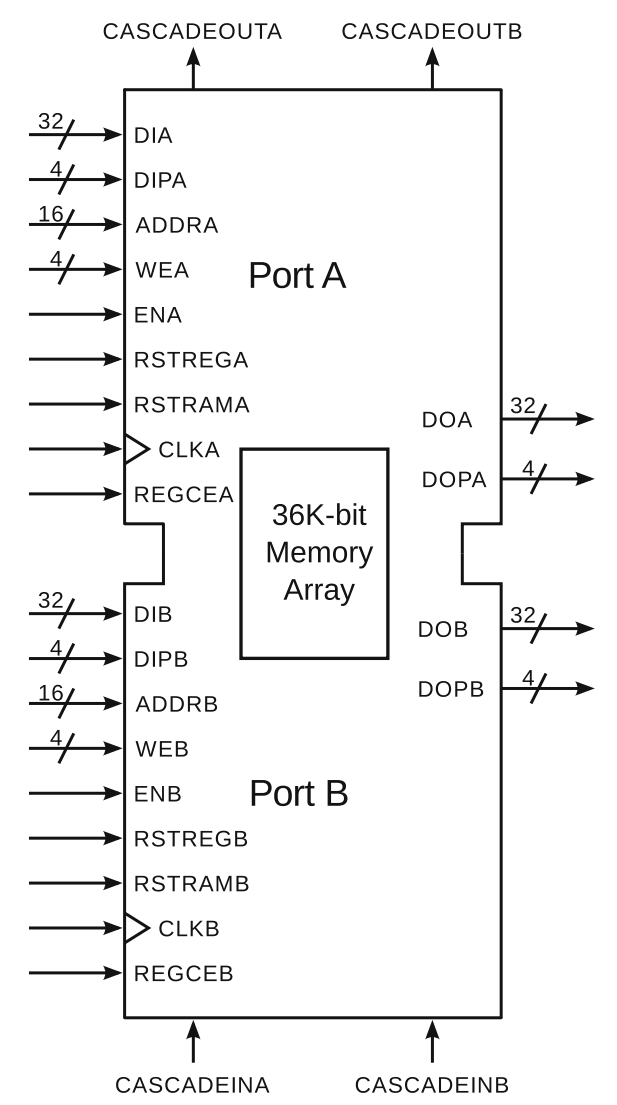
- 上图就是Xilinx 7系列架构中搭配的BRAM模块的接口,每个BRAM有36Kbit的容量,一般FPGA中有数十个至数百个BRAM,一个BRAM可以作为一个36Kbit存储器使用,也可以拆分为两个独立的18Kbit存储器使用,相邻的两个BRAM也可以结合起来实现72Kbit存储器使用。
- 访问存储器所需的地址总线、数据总线、控制信号等一系列信号都有两套(端口A和端口B),因此BRAM既可以作为单端口存储器,也可以作为双端口存储器使用。利用双端口存储器可以方便地实现子模块间传输数据用的FIFO。但是访问BRAM时要和时钟同步,即不能在同一个时钟周期同时进行读写。
2.查找表存储器
- 当逻辑块实现组合逻辑电路时,LUT中存储的真值表就可以用作小规模存储器,因为不可能所有LUT都会被用来实现组合逻辑电路,利用LUT为用户电路实现存储器,既可以实现芯片内部的存储功能,又可以提高硬件资源使用率。
- Xilinx FPGA架构中这种由LUT构成的存储器就叫做分布式存储器(distributed RAM),但并非所有LUT都可以作为分布式RAM,只有被称为SLICEM的逻辑块中的LUT才可以,分布式RAM可以实现BRAM不能实现的异步访问。但是使用分布式RAM实现大规模存储器,可以用来实现逻辑的LUT会减少,因此建议只在需要小规模存储器时使用该方式。
3.嵌入式存储器的使用方式
- FPGA产商提供RAM、ROM、双端口ROM、FIFO等各种存储器的IP生成工具来实现各种存储器功能,同时可以选择使用BRAM还是分布式RAM来实现。
- 如果按照FPGA厂商推荐的方式编写HDL程序,设计工具就会自动推测使用嵌入式存储器,这种方式的可移植性更高。
11.配置链
将电路编程到FPGA的过程叫做配置(Configuration),向FPGA中写入的电路信息叫配置数据。配置数据中包含在FPGA上实现电路的所有信息,如LUT中真值表的数据、开关块中各个开关的开闭状态等。FPGA需要一种在芯片上存储配置数据的机制,根据所使用的存储单元的不同,可以分为以下3类:
- SRAM型。使用SRAM存储配置信息,优点是没有重写次数的限制,但SRAM是易失性存储器,断电后FPGA上的电路信息会丢失。
- 闪存型(FLASH)。闪存为非易失性存储器,因此作为配置存储器使用即使断电电路信息也不会丢失,它也没有写入次数的限制,但是写入速度比SRAM慢(猜测可能是SRAM是FPGA内部BRAM或分布式RAM,所以带宽高速度快,FLASH是外部存储器,数据传输带宽低速度慢导致的)。
- 反熔丝型。反熔丝的初始状态是绝缘体,加高压熔化后导通,可以利用该特性来存放配置数据。虽然反熔丝具有非易失性,但是导通一次后便不可复原,配置一次后FPGA便无法改变了。
- 大多数FPGA支持通过JTAG接口对其进行配置,JTAG(Joint Test Action Group)是边界扫描测试标准IEEE 1149.1标准化测试组织的总称缩写。边界扫描(boundary scan)是一种将半导体芯片输入/输出上的寄存器串联成一条长的移位寄存器链,通过外部访问移位寄存器,在输入引脚上设置测试值观察输出引脚上输出值的机制。
- 使用JTAG接口进行配置时,要先将配置数据一位一位序列化,再通过边界扫描用的移位寄存器写入FPGA。这条移位寄存器的路径就称为配置链。
- 使用边界扫描的方式可以将多个FPGA串联到一条移位寄存器链上,因此可以使用一条配置链配置多个FPGA。
12.PLL
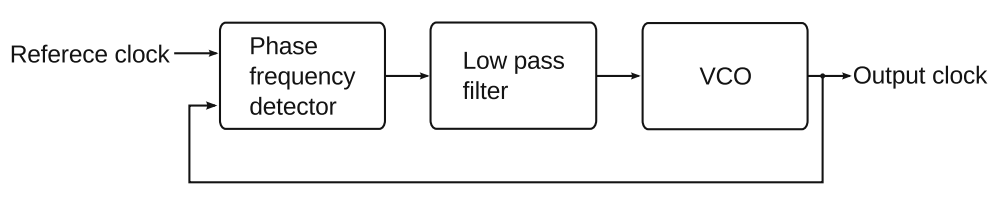
- PLL(Phase-Locked Loop)锁相环基本结构如下图,生成时钟信号的核心部分是压控振荡器(Voltage-Controlled Oscillator,VCO),VCO是可以根据所加的电压调整频率的振荡器,鉴相器可以比较外部输入的基准时钟和VCO自身输出时钟间的相位差。如果两个时钟一致则维持VCO电压,如果VCO主频过高就降低电压,反之就提升电压,一般使用电荷泵(Charge pump)电路来实现这种模拟电压信号的转换。
- 通过上述方式得到的时钟可能会不稳定,因此反馈时钟信号还要用一个低通滤波器去掉高频成分后再输入VCO。PLL一般用模拟电路实现。
- 上面的PLL结构只能以和从外部输入的基准时钟相同的频率振荡,但是在实际FPGA应用中需要各种不同的时钟频率,因此基于上述结构添加几个可编程分频器的情况更常见。
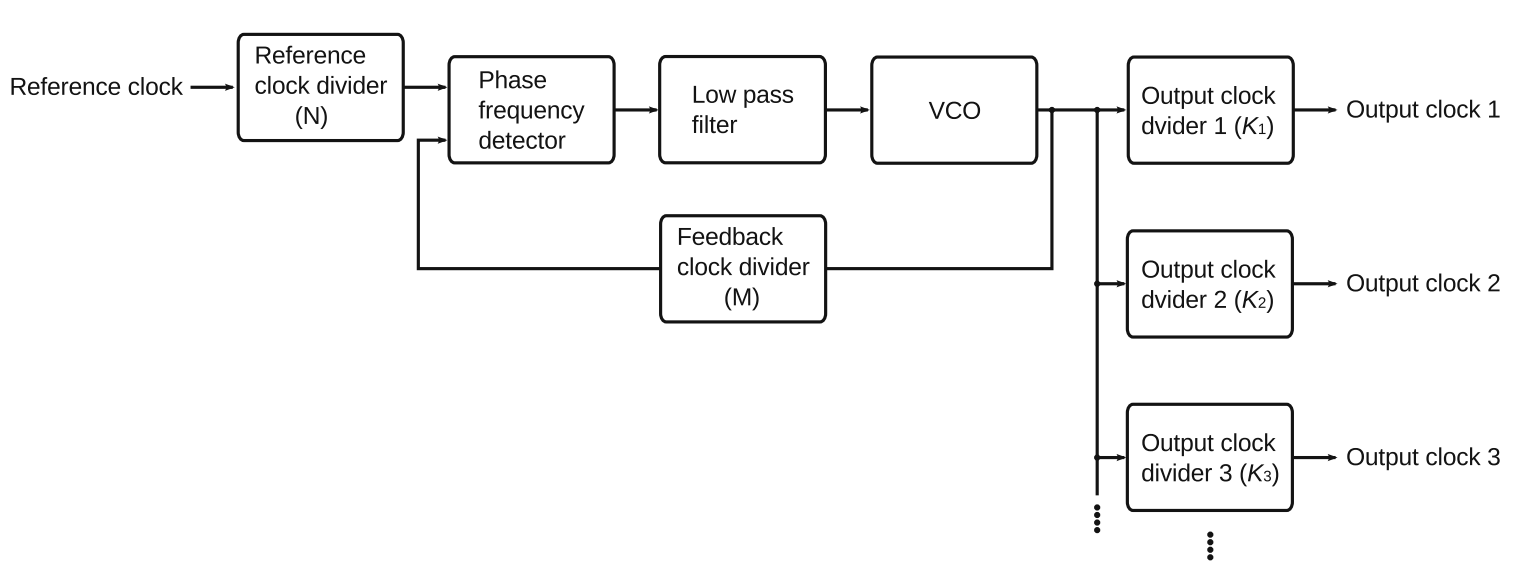
- 基准时钟在输入鉴相器前要通过分频器,如果分频比为N,VCO的目标频率就为基准时钟频率的1/N。VCO输出时钟到鉴相器的路径也添加了分频器,这里的分频比为M时,反馈控制的目标就是让VCO振荡频率的1/M和目标频率一致。可以得到 1/M * Fvco = 1/N * Fref,即Fvco = M/N * Fref。
- VCO后端也有多个分频器,可以将VCO振荡产生的时钟信号再次分频,这样就可以产生多个不同频率的时钟。Fi = 1/K * Fvco,将其带入上面的式子可得 Fi = [M/(N*K)] * Fref,设置M、N、K的值就可以根据外部输入的基准时钟信号生成各种频率的时钟信号。
- 反馈系统需要一定时间才能让VCO的振荡稳定下来,当VCO输出稳定并和基准时钟吻合时,称PLL为锁定状态,即loced信号,置1时表示稳定可以使用,未置1时不稳定。
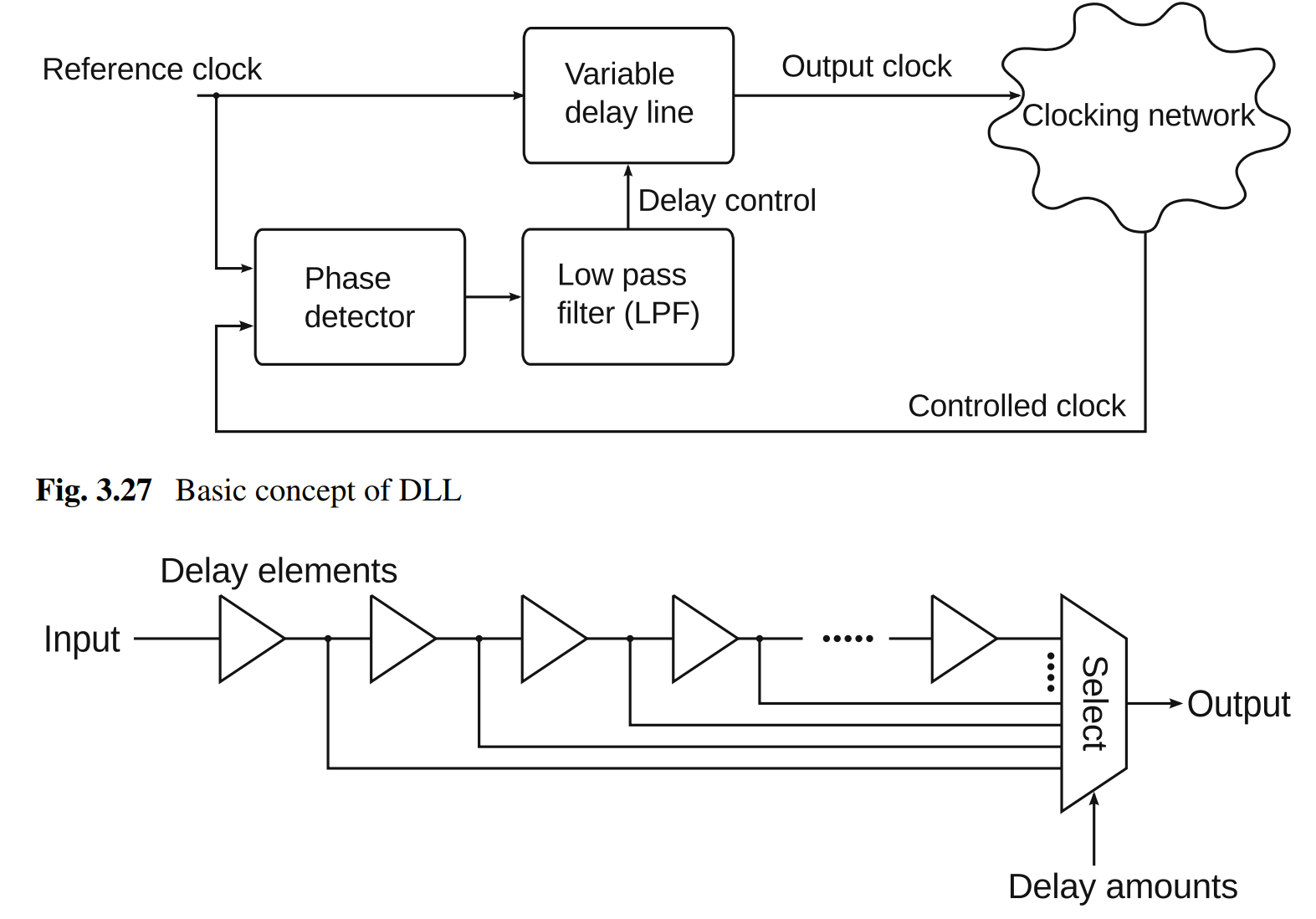
- DLL通过可变延迟线控制时钟信号的延迟量,没有用VCO,预置多个延迟单元,再通过选择器选择所需延迟量的路径,与PLL相比,它可以消除时钟分配网络引起的偏移。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号