
ES6之 字符串和正则表达式
字符串和正则表达式
ES6 为我们增添几个常用的字符串操作方法
-
includes() 方法。检测指定文本,匹配到结果返回true,否则为false。可以用来替换indexOf来判断字符串是否存在于另一个字符串中。
-
"abc".indexOf("a") > -1 => "abc".includes("a") -
当需要获取字段的索引值时,只能依靠indexOf(或lastIndexOf),匹配到的索引值为字符串第一个字符在 另一个字符串中的位置。
"abcd".indexOf("bc") //1
-
-
startsWith() 方法。在字符串的开始部分是否是以指定文本,是则返回true,反之为false。
-
endsWith() 方法。在字符串的结尾部分是否是以指定文本,是则返回true,反之为false。
-
上面两个方法均可接受两个参数。以startsWith为例。
-
"abc".startsWith('b', 1)// true-
第一个参数为匹配文本
-
第二个参数设置检测的起始位置
-
endsWith中,第二个参数设置起始位置为
字符长度 - 参数值
-
-
-
repeat() 方法。接收一个number类型参数,表示改字符串的重复次数。
-
"ab".repeat(2) // abab -
若接收字符串可转为数字。则进行隐式转换。
-
若接收字符串不可转为数字。则返回空。
-
新增3个字符编码的方法。
JavaScript的字符编码方式为 UTF-16 进行构建,即用 16个 0 / 1的组合表示一个字符。
-
编码单元:这16个 0或1 的组合称为一个编码单元。
-
基本多文种平面:编码单元的取值范围称为基本多文中平面。
- 基本多文种平面 -> Basic Multilingual Plane. (以下简称:BMP)
对于超出BMP的字符,16位编码就无法表示了。为此UTF-16引入了代理对,用两个16位编码单元表示一个字符。
-
codePointAt() // 将字符转换为字符编码。
-
对于BMP字符集中的字符,与charCodeAt()效果相同。
"a".charCodeAt() // 97 "a".codePointAt() // 97 -
对于非BMP字符集中的字符,会展示完整的字符编码。
-
"𠮷".charCodeAt() // 55362 "𠮷".charCodeAt(0) // 55362 "𠮷".charCodeAt(1) // 57271 "𠮷".codePointAt() // 134071 "𠮷".codePointAt(0) // 134071 "𠮷".codePointAt(1) // 57271 "𠮷".codePointAt(2) // undefined -
根据以上的代码,我们可以知道,ES 5 中的charCodeAt()方法,对于非BMP字符集中的字符,只截取代理对中的第一段16位编码,第二段则默认忽略。
-
而ES 6新增的codePointAt()方法,很合理的使用了整个代理对来进行解析。且代理对的第二段作为辅助平面,而不做单独解析。
-
-
关于检测一个字符占用的编码单元数量,以下函数可提供参考。
function is32Bit(c) { return c.codePointAt(0) > 0xFFFF; } console.log(is32Bit("𠮷")) // true console.log(is32Bit("a")) // false
-
-
String.fromCodePoint() // 将字符编码转换为字符
-
对于BMP字符集中的字符,与fromCharCode()效果相同。
-
String.fromCharCode(97) // a -
String.fromCodePoint(97) // a
-
-
对于非BMP字符集中的字符,fromCodePoint能展示更完整的字符。
-
String.fromCharCode(9731, 9733, 9842, 0x2F804) // ☃★♲ -
String.fromCodePoint(9731, 9733, 9842, 0x2F804) // ☃★♲你
-
-
-
normalize() // 统一标准化编码的表示形式,通常在国际化应用中使用较多
-
有很多欧洲国家的语言中有语调和重音符号。Unicode提供了两种方法来进行编码。
-
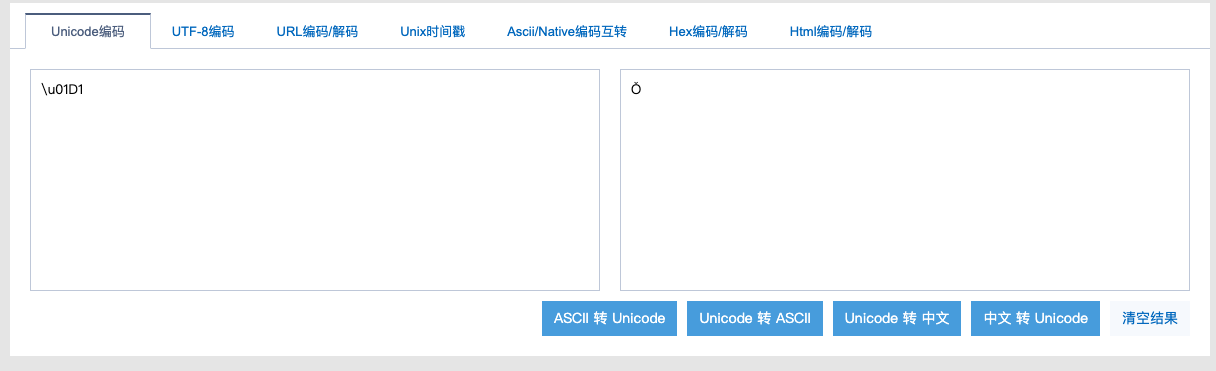
一种是直接带重音符号的字符 例如:Ǒ (\u01D1)
-
![]()
-
另一种是合成符号:O (\u030C) 和 ̌(\u030C) 组成 Ǒ (\u01D1)
![]()
-
-
两种方式变现的字符相同,但字符并不相同
'\u01D1'==='\u004F\u030C' //false。ES 6新增的normalize(),能将Unicode正规化。可传入四个可选值。-
NFC。默认参数,按照标准等价分解,然后在以标准等价方式进行重组。
-
NFD。按照标准等价分解。
-
NFD。按照兼容等价分解。
-
NFKD。按照兼容等价分解,然后在以兼容等价方式进行重组。
-
标准等价:视觉展示和语义上等价。
-
兼容等价:语义等价、视觉展示不等价。
-
-
在进行排序时,建议统一标准化进行处理。以下例子可供参考:
-
arr.sort(function(first, second) { let firstNormalized = first.normalize(), secondNormalized = second.normalize(); if (firstNormalized < secondNormalized) { return -1; } else if (firstNormalized === secondNormalized) { return 0; } else { return 1; } });
-

正则表达式的u修饰符
JavaScript的正则默认会将字符进行16位编码处理,某些单个字符解析成两个编码。例如:"𠮷"
let text = "𠮷";
console.log(/^.$/.test(text)); // 匹配一个字符时得到 false
ES 6加如了 u修饰符,使编码操作处理变为按字符处理。
let text = "𠮷";
console.log(/^.$/.test(text)); // 匹配一个字符时得到 false
console.log(/^.$/u.test(text)); // 匹配一个字符时得到 true
判断浏览器JS解释器是否支持正则中的 u修饰符,以下函数可提供参考:
function hasExpU () {
try {
var pattern = new RegExp(",", u);
return true;
} catch (ex) {
return false;
}
}
正则表达式的y修饰符
正则采用y修饰符后,匹配将会从lastIndex属性值的位置为起点开始匹配。若从lastIndex开始的字符匹配到结果,则返回true,否则为false。换种说法,以lastIndex值为起点,进行startsWith匹配。
let text = "hello1 hello2 hello3",
pattern = /hello\d/y;
console.log(pattern.test(text)); // true
pattern.lastIndex = 1; // 初始化匹配起始位置
console.log(pattern.test(text)); // false
-
lastIndex = 1,即从"ello1 hello2 hello3"中匹配。正则中是以h开头,与e不同,所以返回false。
-
当y修饰符的正则匹配到结果后,lastIndex会更新为匹配到结果的最后一个索引值。再次正则匹配操作,会进行叠加,称为粘滞行为。
let text = "hello1 hello2 hello3",
pattern = /hello\d\s/y;
console.log(pattern.test(text)); // true
console.log(pattern.test(text)); // true
console.log(pattern.test(text)); // false (因为hello3后面无空格)
- 注意:只有调用正则对象的方法才会涉及粘滞行为。test、exec等。而字符串的方法不会触发,如match。
正则表达式的复制
- 通过给RegExp构造函数传递第二个参数,可进行修饰符的覆盖。
let re1 = /abc/i,
re2 = new RegExp(re1, "g");
console.log(re2); // /abc/g
正则的其他
- flags 可获取正则表达式的修饰符。
let re1 = /abc/img;
console.log(re1.source); // abc (ES5 获取正则表达式文本)
console.log(re1.flags); // img (ES6 获取正则表达式修饰符)
模版字面量
模版字面量使用一对反引号表示( `` ),具有以下特点:
-
支持字符串拼接
-
支持换行
-
支持空格记录 (换行情况下)
-
支持占位符 ( ${}, 且占位符中可以正常执行函数,表达式)
-
标签函数
对于ES 6之前的字符串拼接, '+' 和 '' 虽然能够完成拼接,但变量插入,换行、空格记录等十分繁琐。ES 6 提供的模版字面量提高了这一方面的开发效率。
let text = "test",
str = `This is
${text} sentence!` ;
console.log(str);
// This is
test sentence!
标签函数:对模版字面量进一步处理的函数,放在反引号之前。
-
标签函数接收两个参数,literals 和 ...substitutions。
-
第一个参数是一个数组。以占位符为分割符号,分割元素组成的数组,累死split()函数分割后的返回值。
-
第二个参数为 占位符的集合,是一种类数组结构,有length属性
let message = tag`hello world`; // tag 是我们自定义的一个标签模版函数
function tag(literals, ...substitutions) {
// 内容
}
用法:模版处理、规避恶意脚本
- 模版处理。先看下面的例子,例子中str变量正确的获取了字符串。
let a = 1, b = 2,
str = `${a} + ${b} = ${a + b}`;
console.log(str); // 1 + 2 = 3
现在需求变成 '10 + 20 = 30',模版变成:
str = `${a * 10} + ${b * 10} = ${a * 10 + b * 10}`; // 10 + 20 = 30
不免有些麻烦,模版较长时,维护起来并不容易。使用标签函数试试。
const a = 1, b = 2;
const str = strWork`${a} + ${b} = ${a + b}`;
function strWork(literals, ...substitutions) {
let result = '';
for (let i = 0; i < substitutions.length; i++) {
result += literals[i];
result += String(Number(substitutions[i]) * 10);
}
return result;
}
console.log(str); // 10 + 20 = 30
- 规避恶意脚本
// 模板标签过滤HTML字符串
function safeHTML(templateData) {
let s = templateData[0];
const args = arguments;
for (let i = 1, len = args.length; i < len; i++) {
let arg = String(args[i]); // 特殊字符的替换
s += arg.replace(/&/g, "&").replace(//g, ">");
s += templateData[i];
}
return s;
}
const str = ' <&&&&';
console.log(safeHTML`hello world ${str}`); // hello world <p> <&&&&
参考书籍:
《深入理解ES6》[美] NICHOLAS C. ZAKAS 著 刘振涛 译

 浙公网安备 33010602011771号
浙公网安备 33010602011771号