
sklearn算法模型
Sklearn分为6大模块
线性算法、回归算法、聚类算法、降维算法、模型选择、预处理
sklearn所有的建模流程都符合以下的步骤
1、导入并建立自己想要的模型
2、把数据导入模型当中训练成自己想要的样子
3、把测试数据导入训练好的模型来预测或者得到答案
本页只提及以下算法
1、决策树之分类树:DecisionTreeRegressor:监督学习
2、逻辑回归之基础回归算法:LogisticRegression:监督学习
3、一元线性回归与多元线性回归:LineraRegression:监督学习
4、聚类算法之K均值聚类:两种表现形式(类,方法)KMeans, k_means:无监督学习
5、模型评估指标:所有的方法都在sklearn.metrics中
决策树
概述
1、对特征进行提问来得到答案
2、不纯度:越低对训练集的拟合程度越好
3、根据对某个节点进行提问来得到相应的答案
点击查看:DecisionTreeClassifier(): 分类树
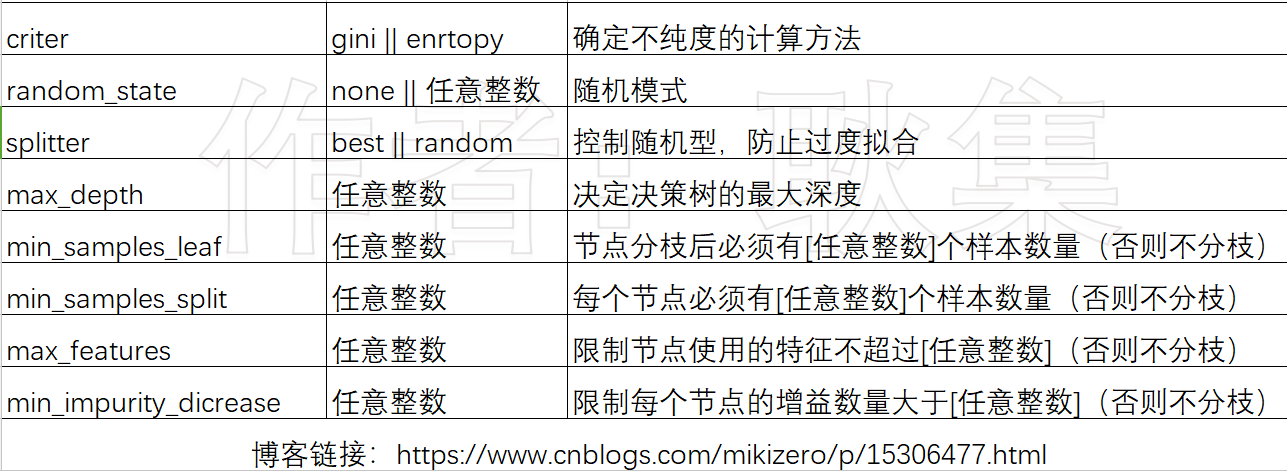
# 参数列表,通常使用gini,当数据拟合程度不够时可以试试entropy
criterion = ("gini" or "enrtopy"):确定不纯度的计算方法,两个值(【gini:基尼系数】【entropy:信息增益】)
random_state = ("none" or 任意整数):设置分枝中随机模式的参数,控制随机性
splitter = ("best" or "random"):控制决策树节点的随机性,防止过于拟合
max_depth = (任意整数):决定了决策树的最大深度
min_samples_leaf = (任意整数):限定一个节点在分枝后都必须有min_samples_leaf个训练样本,否则就不会发生分枝
min_samples_split = (任意整数):限定每个节点都必须有min_samples_split个训练样本
max_features = (任意整数):限制每个节点使用的特征数量,超过则不会分枝
min_impurity_dicrease = (任意整数):限制每个节点的增益大小,小于设定值分枝不会发生
#--------------实例----------------------
# 回归树模型中填入的参数和分类树模型中的参数是一致的
# 导入决策树库
from sklearn import tree
# 导入datasets数据集
from sklearn import datasets
# 导入分割训练集和测试集的工具
from sklearn.model_selection import train_test_split
# 提取datasets中的房价数据
x2_data, y2_data = datasets.load_boston(return_X_y=True)
# 实例回归树模型
regressor = tree.DecisionTreeRegressor()
# 分割数据
x2_train, x2_test, y2_train, y2_test = train_test_split(x2_data, y2_data, test_size=0.3)
# 数据填入模型训练
regressor.fit(x2_train, y2_train)
# 查看模型评分
score2 = regressor.score(x2_test, y2_test)
print(score2)
逻辑回归
概述
1、逻辑回归对线性的数据预测效果非常的好,拟合效果强,速度快
2、但是对于环形数据就不是那么友善了
3、逻辑回归虽然说是用来做分类数据,但是返回的却不是固定的0和1,而是一个小数
4、比如判断一个人是否会违约,不能只说会还是不会,还要给出违约的概率是多少,逻辑回归就很好的做到了这一点
5、逻辑回归不是只能做二分类,也可以多分类
6、逻辑回归天生容易过拟合,我们需要防止逻辑回归过拟合,这个过程就叫做正则化
点击查看:linear_model.LogisticRegression:逻辑回归分类器(又名logit回归)
python
# 参数列表
# 如果penalty选择了l1,则solver参数只能选择liblinear
penalty = 'l1' or 'l2':默认l2,正则化,防止逻辑回归过拟合
c = (大于0的小数最大1.0):默认为1.0,用来控制正则化的强度,越小惩罚强度越重
solver = "liblinear", "lbfgs", "newton-cg", "sag", "saga":优化损失函数
"""
当正则化选择了l1的方式时,优化损失函数的方式只能适用<liblinear>和<saga>
liblinear: 比较适合小数据集
sag和saga适合大数据集,因为速度快
总结:大数据集时优先适用saga,小数据集优先liblinear
"""
# ------------------实例-----------------------
# 导入逻辑回归算法
# 导入乳腺癌数据集
# 导入np和plt画图用
# 导入训练集和测试集的分割方法
# 导入查看分数的方法
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 获取数据
data = load_breast_cancer()
# 获取数据样本
x = data.data
# 获取特征标签
y = data.target
# 建立两个使用了不一样正则化的模型
lr1 = LogisticRegression(penalty="l1", C=0.5, solver="liblinear", max_iter=1000)
# 分割训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y)
# 训练模型
lr1.fit(x_train, y_train)
# 逻辑回归模型评估时应该使用sklearn.metrics.accuracy_score,而不是模型自带的score
print(accuracy_score(lr1.predict(x_test), y_test))
# 不能直接使用预测的结果来进行模型评估,需要使用accuracy_score()
print(lr1.predict(x_test))
# coef_可以查看这个逻辑回归的θ参数,前提是要训练过的模型
# θ参数表示的是每个特征所对应的参数
# 这个参数相当于时lr1.predict(x_test)预测出来的结果
# 但逻辑回归不只有0和1,查看的时候需要使用lr1.coef_
l1 = lr1.coef_
聚类算法
1、概述
2、目标是把数据划分成有用或有意义的组(簇)
3、比如把一些客户分成多组方便调研
4、再比如图片,声音,视频等高维特征的数据分成一列以压缩空间
5、聚类算法是把一堆没有标签的数据分成一类,所以数据肯定会有不准确的
所有方法(聚类算法有类和方法两种调用形式)
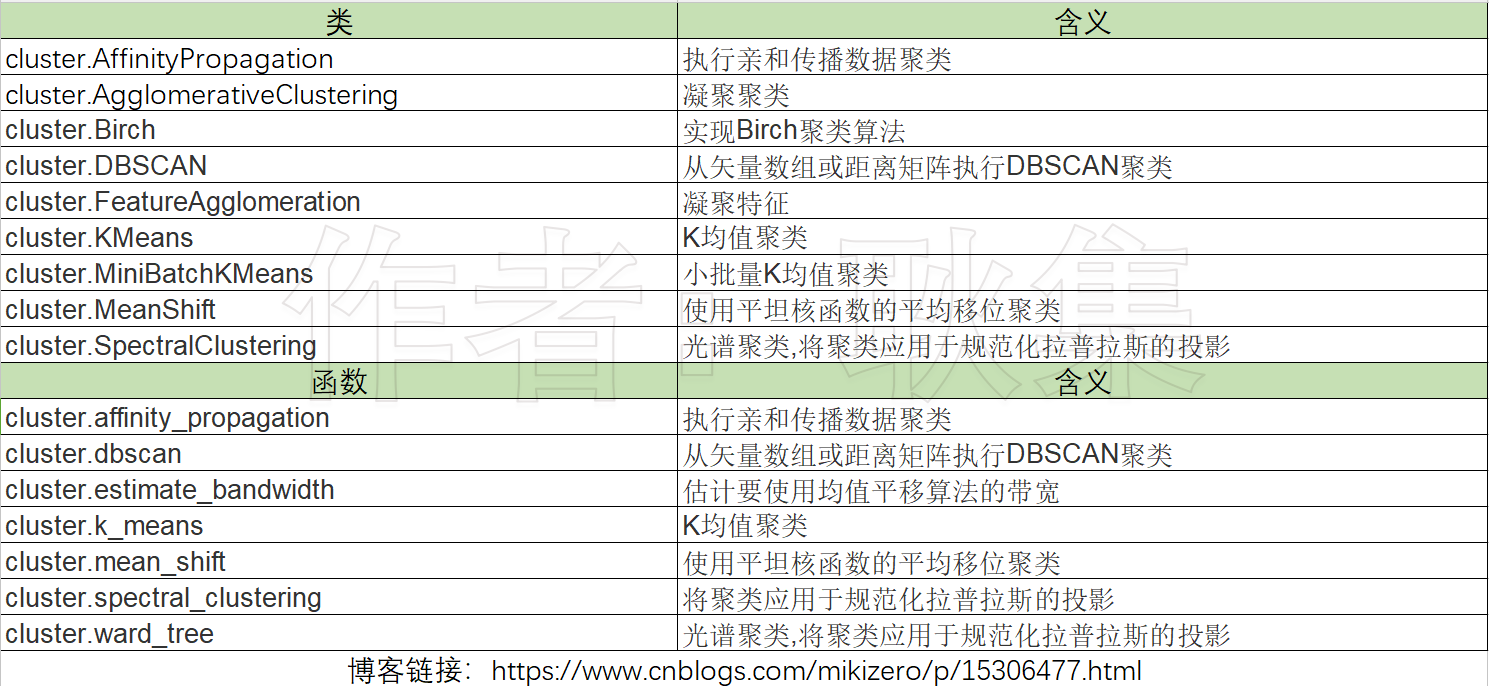
点击查看:k均值算法:cluster.KMeans,cluster.k_means
# 导入聚类算法模型
# 导入自动创建数据的函数
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
"""
make_blobs用于生成聚类函数的样本
n_samples:样本个数
n_features: 数据的特征数量
centers:数据的中心点(表示数据都是围绕着设定的这几个核心来创建的)
random_state:随机模式
"""
x, y = make_blobs(n_samples=500, n_features=2, centers=3, random_state=1)
fig = plt.figure(figsize=(10, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax1.set_title("old_data")
ax1.scatter(x[:, 0], x[:, 1], marker='o', s=7)
clusters_num = 4
# 创建模型
# n_clusters:定义多少个簇心
k = KMeans(n_clusters=clusters_num, random_state=0)
data = k.fit(x)
# 查看聚类的分类标签
labels = data.labels_
# 查看质心
cluster_centers = data.cluster_centers_
# 查看总距离平方和
inertia = data.inertia_
线性回归算法模型
1、概述
2、线性回归有一元线性回归和多元线性回归以及其他
3、一元线性回归就是只有一个特征的数据进行回归算法的模型
3、并且线性回归是监督学习,训练模型需要有特征值和目标值
点击查看:linear_model.LinearRegression线性回归
"""
线性回归:一元线性回归和多元线性回归,利用最小二乘法做线性回归
一元线性回归: 只涉及一个自变量(特征值)的线性回归称为一元线性回归
线性回归是监督学习
"""
# 导入房价数据集
# 导入数据分割函数
# 导入线性回归类
# 导入模型评定方法
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 使用均值误差来评估模型
from sklearn.metrics import mean_squared_error
# 使用交叉验证评估模型
from sklearn.model_selection import cross_val_score
# 提取数据
housevalue = fetch_california_housing()
x = housevalue.data
y = housevalue.target
# 分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# 建立模型
model = LinearRegression()
# 训练模型
model.fit(x_train, y_train)
# 预测数据
g = model.predict(x_test)
# 探索模型
print("探索模型")
print("所有特征对应的系数,越大特征越重要:", model.coef_) # 查看每一个特征对应的系数,系数越大,特征越重要
print("查看模型截距:", model.intercept_) # 查看这个模型的截距,如果截距与真实数据差距大说明拟合效果不太好
# 模型评估方法(是否预测到正确的数值),这个方法可以输出预测值的平均值
# 用来跟真实值的最大值跟最小值来比较判断模型分数
print("预测值的均值:", mean_squared_error(g, y_test))
print("真实值最小值:", y_test.min())
print("真实值最大值:", y_test.max())
# 交叉验证评估方法
print(cross_val_score(model, x_test, y_test))
本文提及的所有算法
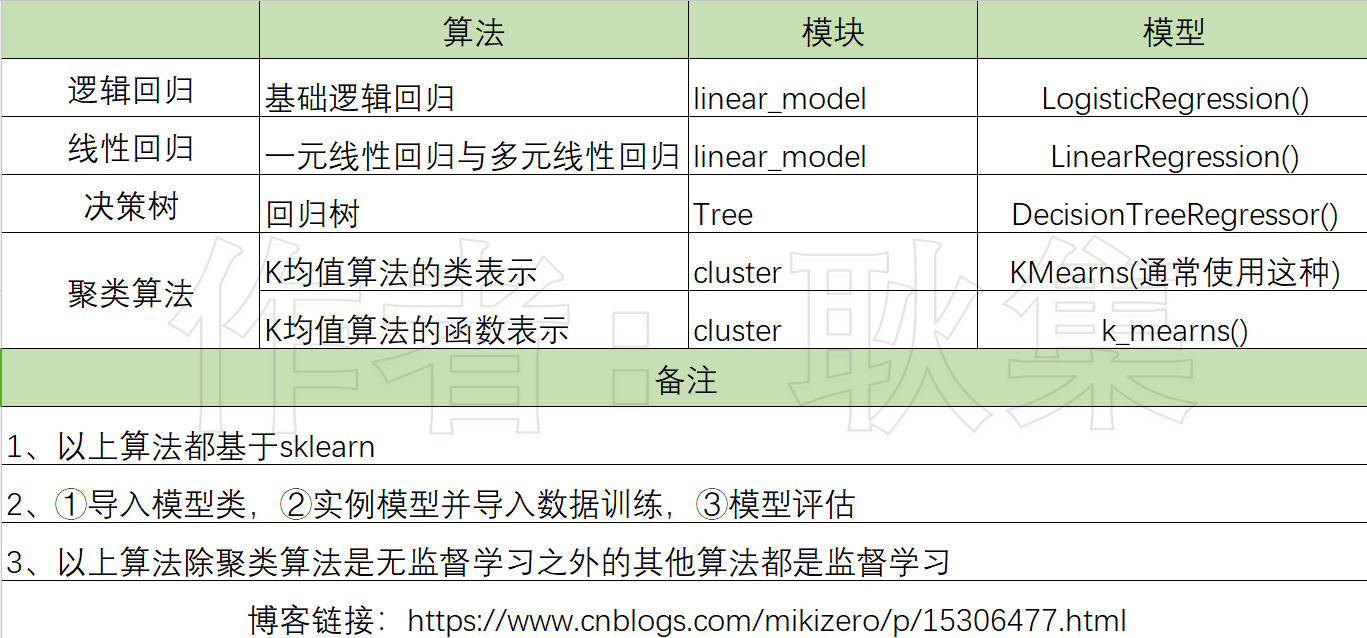
本文提及的所有算法的参数
决策回归树
逻辑回归

聚类算法(k均值)
主要参数就两个
n_cluster: 设置多少个簇心
random_state: 设置随机模式
线性回归
fit_intercept:默认True,表示是否计算截距
normalize:默认False,是否对特征进行标准化
n_jobs:默认none,表示使用多少个处理器进行计算,提速度的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号