
python爬虫反爬
反爬原因
- 爬虫占总PV高,浪费了服务器的流量资源
- 资源获取太多导致公司造成损失
- 法律的灰色地带
种类
- 数据污染反爬,数据陷阱反爬,大文件url反爬,这些都需要累计熟练度来进行处理
解决方案:没有什么技巧,都是通过观察,如果提取不到想要数据就需要多尝试,这是一个熟练度的问题
- 数据加密反爬,猫眼电影评分数据加密
![image]()
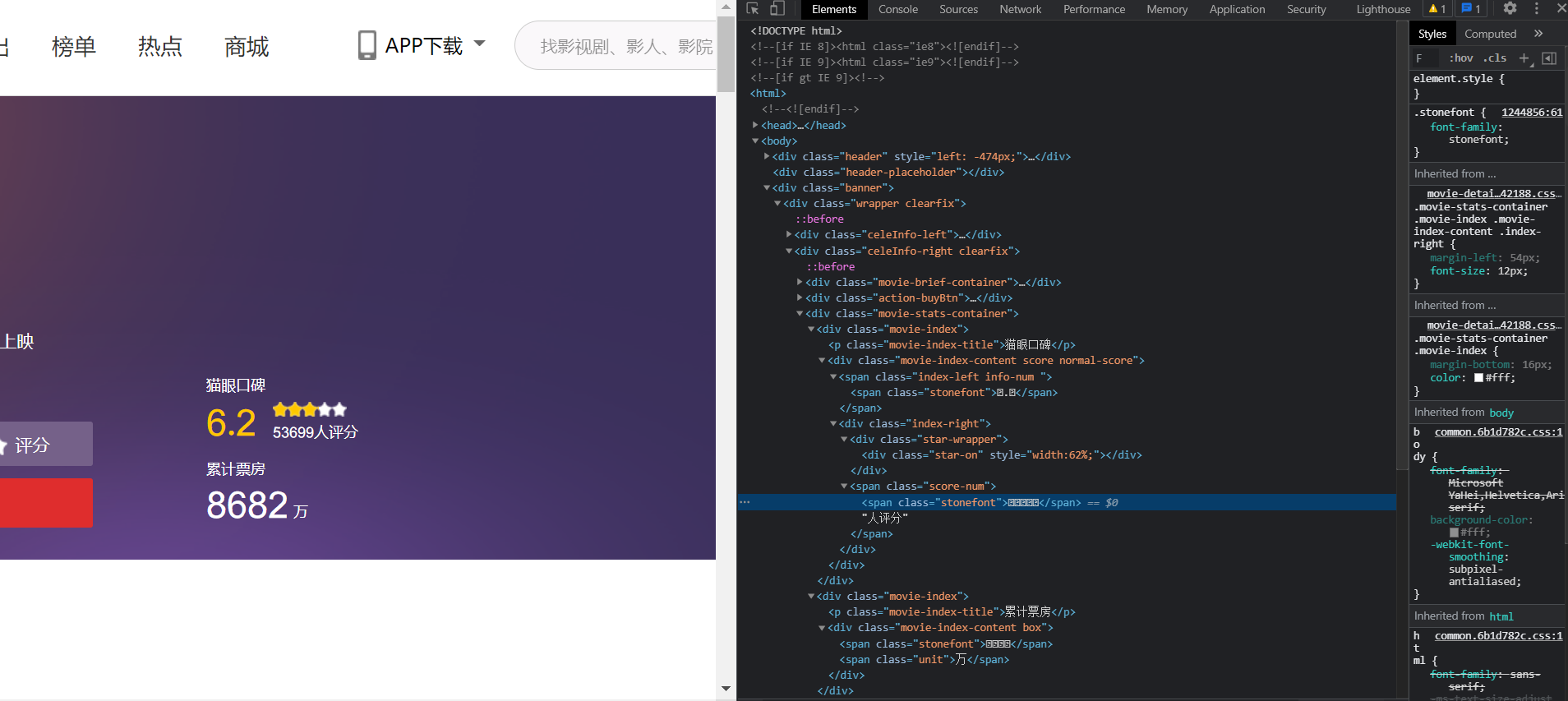
解决方案1:先右键检查元素
通过对比就可以发现他是有自己的一个字体库,只要把这个加密的数据进行一个一对一翻译,就可以拿到我们想要的数据
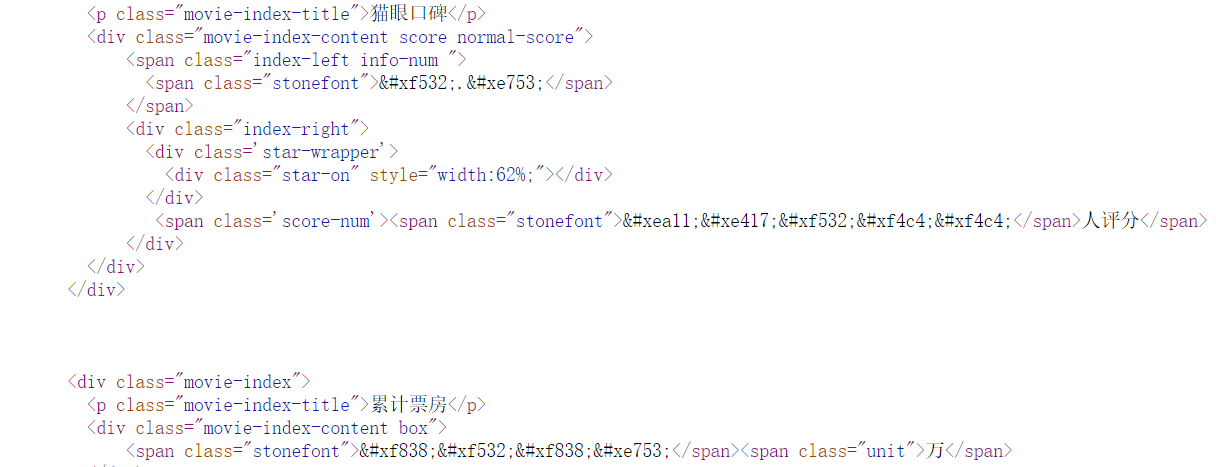
解决方案2:可以切换手机端查看数据
可以发现他的数据是没有加密的,可以直接获取
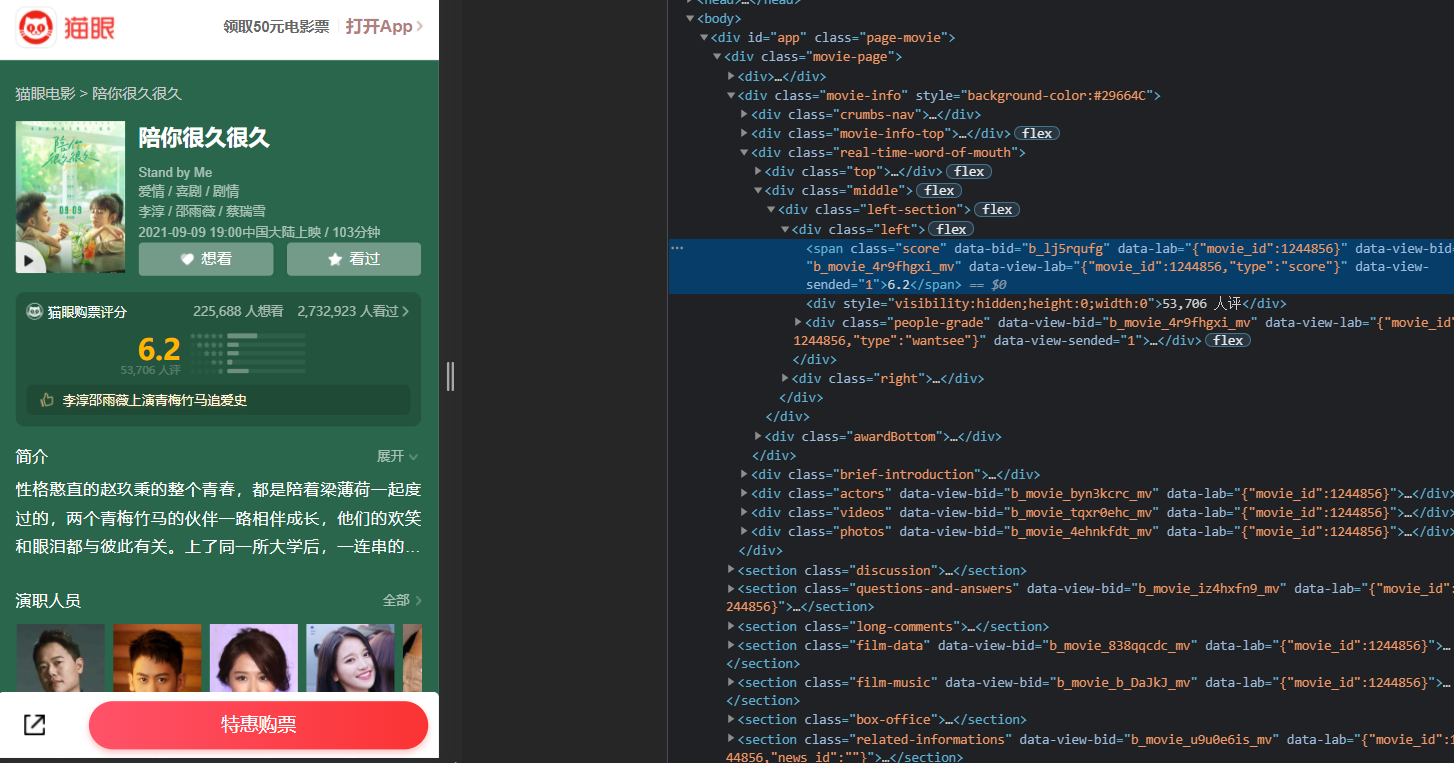
- 对此又出现了一套新的反爬方案,每次进入浏览器都会更新这个字体方案
- css数据偏移反爬
简单来说就是通过css来把数据分开标签来存储,增加数据解析的难度
解决方案:只是增加了我们的数据分析步骤
- 通过js生成数据渲染到浏览器进行反爬
通过post请求获取js的数据即可
- 通过图片进行反爬
把数据放入一张图片中不让直接获取数据
陷阱
1、有时候对方的服务器不一定只检查请求头当中的cookies和user-agent信息,也可能会检查那些请求头中不经常使用的信息
隐藏表单
1、有时浏览器会在HTML中添加隐藏表单,当爬虫提交的时候就会被封
2、也有可能是把表单设置在的浏览器之外,总之多观察浏览器结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号