

MySQL优化 - 所需了解的基础知识
时隔一年半,期间一直想写但却觉得没有实质性的内容可记录,本文为 [高性能MySQL] 的学习日志整理分享(感兴趣建议读原书)。
优化应贯穿整个产品开发周期中,开发过程中考虑一些性能问题与影响,总比出问题才开始重构优化代价要低,所以这些优化知识其实应算需具备的常识。
1、MySQL构架的一些知识
1.1 纵观全貌,逻辑结构如下:
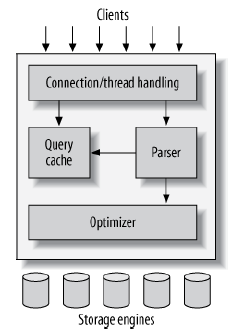
关于优化,是一个比较复杂的过程,可能涉及操作系统配置、网络/磁盘IO、内存、文件系统与应用程序等,知识深入并且面比较广,本文只针对MySQL服务器本身的一些可优化点做记录。
1.2 选择合适的Storage engine很关键,MySQL锁定模型和并发性如下:
| 加锁策略 | 并发 | 系统开销 | 引擎举例 |
| 表级加锁 | 最低 | 最低 | MyISAM、Merge、Memory |
| 行级加锁 | 高 | 高 | NDB Cluster |
| 支持MVCC的行级加锁 | 最高 | 最高 | InnoDB |
部分存储引擎说明:
MyISAM
1. MyISAM 是表级别锁。
2. 并且不支持数据恢复(服务突然崩溃应该使用之前进行check)。
3. 不支持事务。
4. 只有索引被缓存在内存中。
5. 数据紧密存储, 数据读取比较快速。
InnoDB
1. 合适大量短事务,使用MVCC机制控制并发锁定问题,行锁。
2. 默认隔离级别为Repeatable Read, 并且使用Next-key locking策略防止幻读。
3. InnoDB表基于聚簇索引建立,非主键索引也包含主键列,所以主键定义尽量小一些。
Memory
1. 数据存储于内存,重启表结构保留,但数据丢失。
2. 支持哈希索引,但是表级加锁,只适合低写入,并且不支持TEXT和BLOB。
注:Temporary table 和 Memory table是两个不同的东西,临时表只在单个连接中可见,连接断开则消失。
Archive
1. 只支持insert和select,并且不支持索引。插入时用zlib算法压缩,占用空间小。
2. 任何查询都会导致全表扫描。
NDB Cluster:
1. 包含Data Node, Manager Node, SQL Node, 数据冗余于多个数据节点。
2. 要求高性能的网络环境,解决复制的延时问题。
3. 该引擎不作为一个通用的存储引擎设计,使用前需要深入了解它是否符合应用场景,它很庞杂。
关于存储引擎的选择参考因素:
1. 事务, InnoDB处理事务型场景很好。
2. 并发,如果少量插入并且大量读取,数据可接受崩溃丢失的情况下,MyISAM效率很好。
3. 备份,是否需要联机备份。
4. 崩溃恢复,MyISAM在大量数据情况下崩溃恢复时间很长。
5. 特有特性,如有时候使用到Memory引擎。
对于一般性的应用,InnoDB通常是很常规的引擎选择。
2、关于字符集的关系(虽与优化无关, 但值得一提)
2.1 创建内置对象
对于MySQL服务创建的对象,在不指定字符集情况下:table继承database, database继承server default character。
所以,通常建议在my.cnf中指定数据库默认的字符集, 如下:
[mysqld] collation-server=utf8_general_ci character-set-server=utf8
同时建议建立数据库的时候显式定义数据库字符集,便于迁移或升级(如果迁移的目标服务器没定义的话, dump后import就可能字符集就不对应上,导致乱码等)。
2.2 client / server 通信使用的字符集
通信使用的字符集设置通常包括character_set_client、character_set_connection、character_set_result,它们的关系如下图:
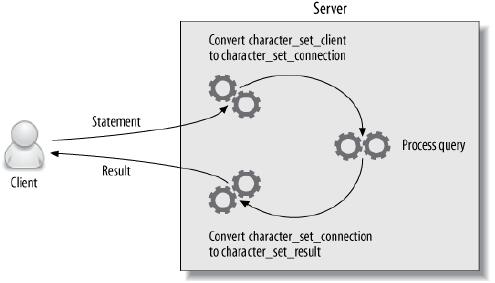
在mysql客户端的命令下使用show variables like '%character%'; 显示当前连接使用的字符集参数。
注:对于mysql客户端命令,通过配置下面参数以修改上面所说的参数(通过mysql --help --verbose查看默认加载配置文件的路径):
[mysql] default-character-set=utf8
对于JDBC,可以url中加入如useUnicode=yes&characterEncoding=UTF-8来指定特定的字符集,通常建议都使用统一的一种字符集以防止出现未知麻烦。
3、优化数据类型
优化数据类型通常包含以下几点说明:
1. 更小的数据类型通常更快,对于使用ORM自动生成的表结构通常不合适(如有些项目使用hibernate自动创建表,一般来说不建议,刚开始省时间,代价后面还是需要还回来)。
2. 尽量避免使用NULL, mysql难以优化可使用空列的查询,可以考虑使用0/特殊值/空串等替代,如果计划对该列进行索引,就尽量避免设置为空。。
3. 整数有tinyint,smallint,mediumint,int,bigint,它们分别需要8,16,24,32,64位存储空间。
4. 主键:通常整数作为主键有非常快的索引速度,并且可以自增长,尽量避免使用字符串类型作为标识符,特别注意完全随机的字符串(MD5,SHA1()或者UUID()),它们产生的新值会被任意地保存很多的空间范围内,减慢INSERT(插入的值被随机放入索引中,导致分页,随机磁盘和聚集存储引擎上的聚集索引碎片)和一些SELECT(因为它分布在磁盘和内存中的各个地方,导致多次的读取)查询。
Note: 如果对一些毫不关心性能或者数据量极小的应用,自动生成代码等情况为了赶项目就用吧,UUID比MD5,SHA1相比不均匀分布并且有一定的顺序性。
5. 字符串类型(VRAHCR与CHAR), VARCHAR使用可变长字符串, ROW_FORMAT默认为dynamic,如果使用FIXED则消耗固定长度空间。VARCHAR额外的使用1-2字节存储长度(小于255则使用1字节)。MySQL会使用固定的内存来存储varchar的值,如使用varchar(20)和varchar(50)来保存同样长度的数据,即使它们在磁盘上的消耗是一样的,但是内存消耗却相差很大。
4、关于索引的一些知识
对于MySQL索引,默认是B-TREE(目前只有这个),所以了解一些B-TREE的知识比较有帮助(需要查找专门讲解该结构的书籍),有一些可以参考的点:
1. 如果要对长字符串做索引,索引会变得很大并且很慢,则可模拟哈希索引,取前一部分冲突概率较小的字符串。
2. 多余索引: 如果对(A, B)列建立组合索引,则不必要再单独对A列建立索引(对于B-Tree而言),由于最左前缀匹配使得A索引生效,但对B单独建索引则不是多余(因为不是最左前缀)。
3. InnoDB在事务提交后才会给行解锁,所以尽量减少对行的锁定。锁定超过需要的行会增加竞争并减少并发。InnoDB只有在存储引擎级过滤不需要的数据才能不锁定不需要的行,如果是返回给MySQL服务后再使用where过滤的话,已经无法避免对不需要的行进行锁定。如下图则对不需要的第一行进行锁定 (对于MySQL 5.1 或更新的版本, InnoDB可以在服务器过滤后进行对不需要的行释放,旧版本会一直锁定到事务提交, 建议使用最新的稳定MySQL版本):


 浙公网安备 33010602011771号
浙公网安备 33010602011771号