Dify 工作流实践--PDF工商信息识别(进阶版本,接入本地知识库识别代码)
接前面一篇文章,完成PDF中图片中文字的识别
今天的场景中,我们会根据自己定义的标准(可能是国标,或者欧标等,因为各个地区表准不一样),进行分类识别,这里引入本地知识库查询
自己定义出分类标准
看看流程:

增加了知识库:
注意:当我们想要用关键字检索时(文本匹配),请将knowlage retrive配置改为:
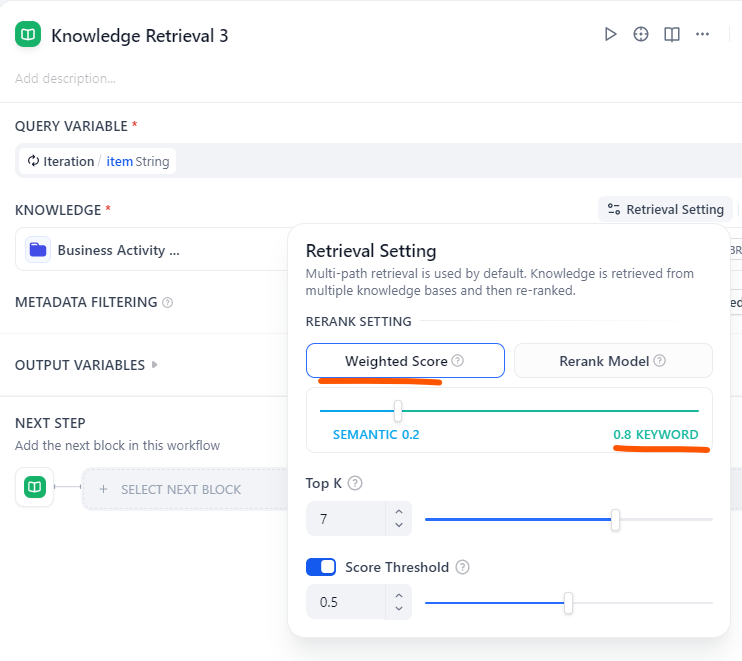
增大关键字匹配的权重,经测试效果非常好(类似于文本匹配)
关于knowlage base的配置:
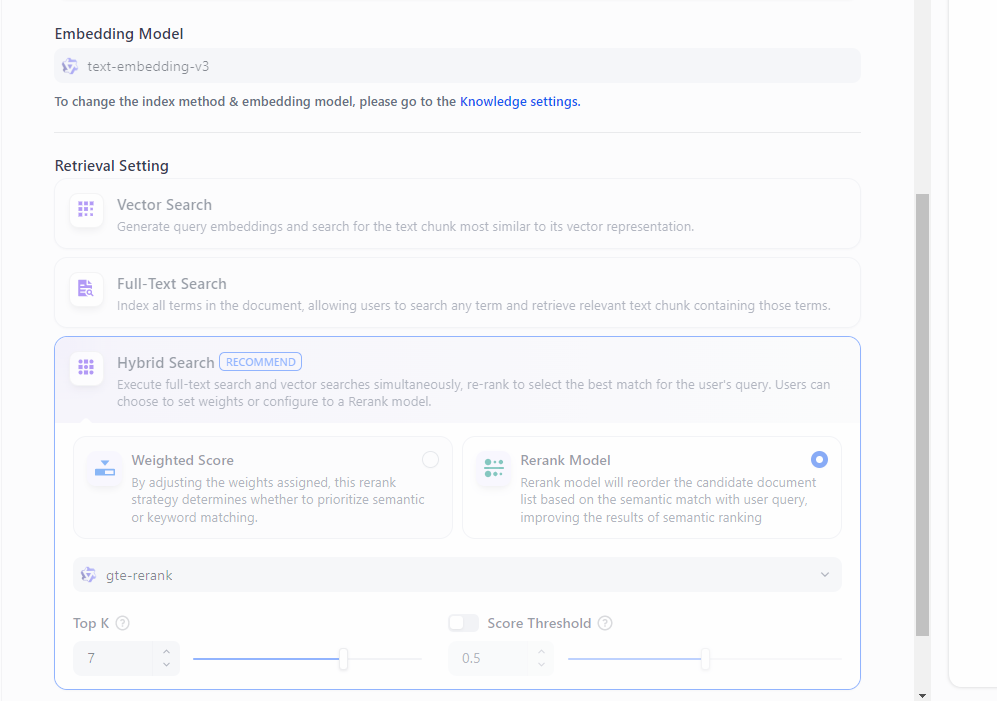
选择embedding和rerank模型:
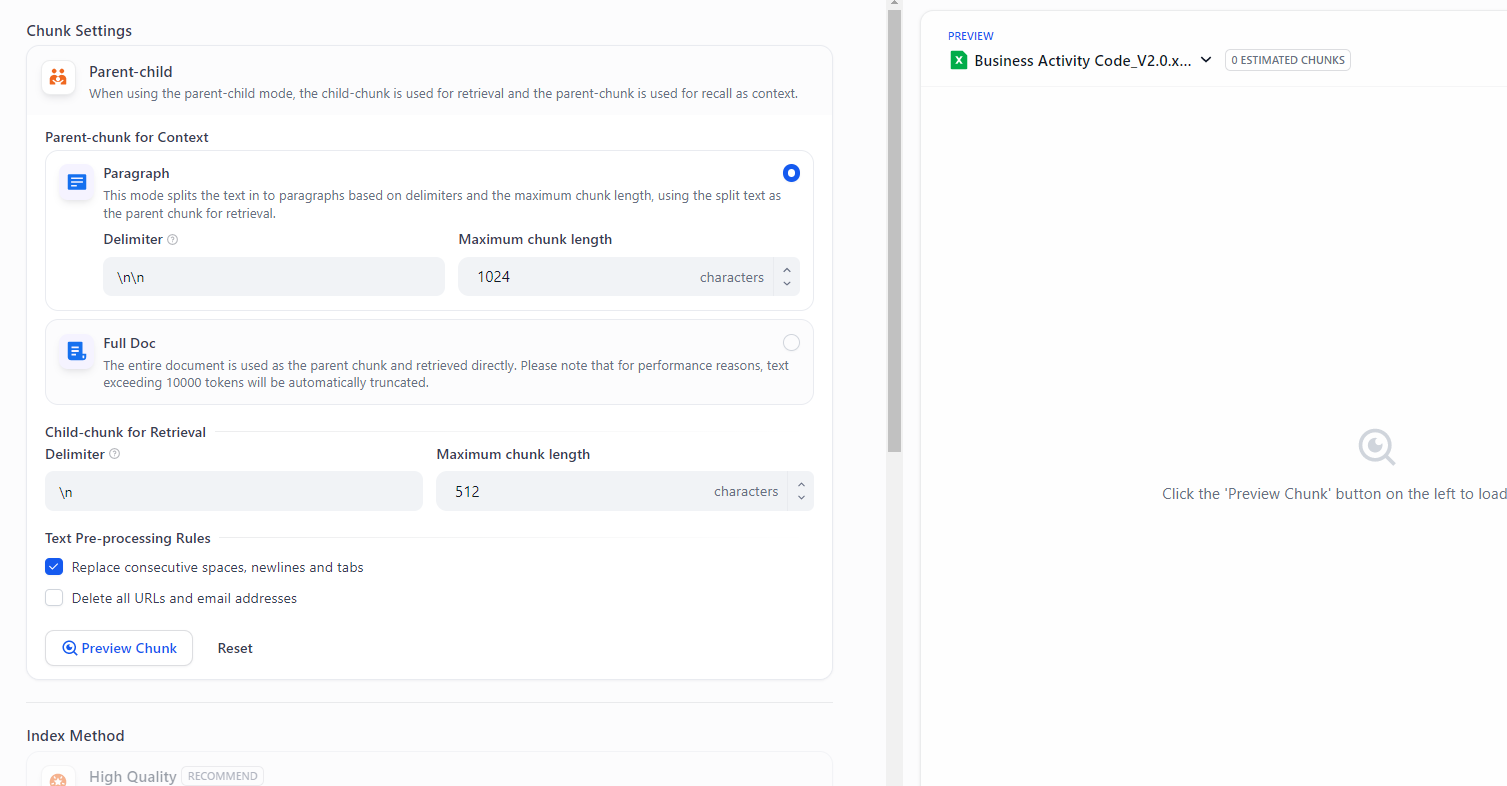
文本知识库格式Excel:

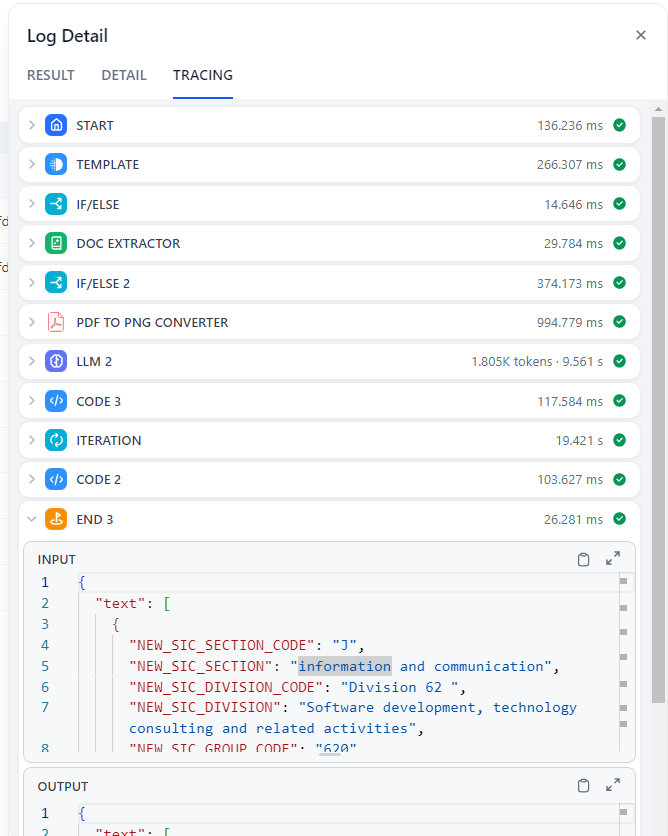
执行效果:
分享DSL

 浙公网安备 33010602011771号
浙公网安备 33010602011771号