Dify 工作流实践--PDF工商信息识别
接上篇,这次做一个PDF识别的案例,提取用户上传的工商营业执照PDF中的营业范围信息,并以JSON 格式返回。
做的过程中识别到几个问题,可能也是大家会遇到的:
1.关于PDF中图片的处理方法
一般情况下PDF中是文本内容,但是有时候会出现图片内容,所以针对文本的大模型无法解析,需要想起他办法
我这里是先将PDF转为PNG,然后解析文件内容进行处理
2.关于插件PDF process默认错误处理方法
在Dify的market中安装后,使用时会报错:need http,https file protocal.解决方法:在源文件.env中增加一行:FILES_URL=http://your-ip,重启即可(这样上传的文件将会有一个完整的URL,可以在浏览器中预览)
-----------分割线-------
先看下整体流程结构:

流程描述:
1.上传文件
2.格式判断,非PDF直接报错
3.DOC EXTRCTOR 解析PDF为text
4.判断如果text非空则表明为纯文本PDF,使用qwen-long长文本大模型进行文件读取分析,按照prompt格式返回结果
5.如果text为空表明为图片型PDF,先试用PDF PROCESS插件将PDF转换为PNG,然后使用qwen-vl-72b视觉大模型进行处理,提取文本进行分析,并按照prompt格式返回结果
构建过程就是拖拖拽拽,省略
运行结果:
1.纯PDF文件解析
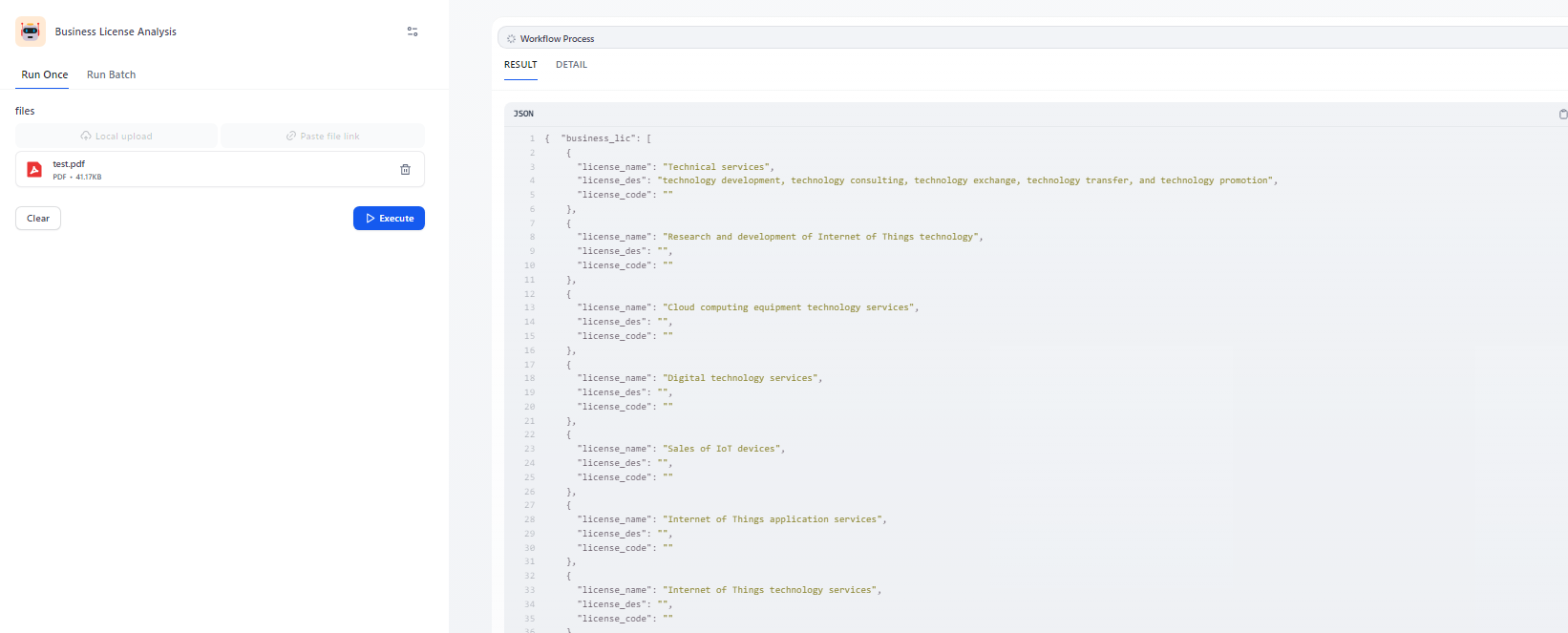
2.图片型PDF解析

附上dsl文件供参考:DSL

 浙公网安备 33010602011771号
浙公网安备 33010602011771号