雪花算法详解(原理优缺点及代码实现)

雪花算法简介
雪花算法,英文名为snowflake,翻译过来就是是雪花,所以叫雪花算法。
在大自然雪花形成过程中,会形成不同的结构分支,所以说不存在两片完全一样的雪花,表示生成的id如雪花般独一无二。

雪花算法,它最早是twitter内部使用的分布式环境下的唯一分布式ID生成算法。
雪花算法的优缺点
雪花算法,它至少有如下4个优点:
1.系统环境ID不重复
能满足高并发分布式系统环境ID不重复,比如大家熟知的分布式场景下的数据库表的ID生成。
2.生成效率极高
在高并发,以及分布式环境下,除了生成不重复 id,每秒可生成百万个不重复 id,生成效率极高。
3.保证基本有序递增
基于时间戳,可以保证基本有序递增,很多业务场景都有这个需求。
4.不依赖第三方库
不依赖第三方的库,或者中间件,算法简单,在内存中进行。
雪花算法,有一个比较大的缺点:
依赖服务器时间,服务器时钟回拨时可能会生成重复 id。
雪花算法原理
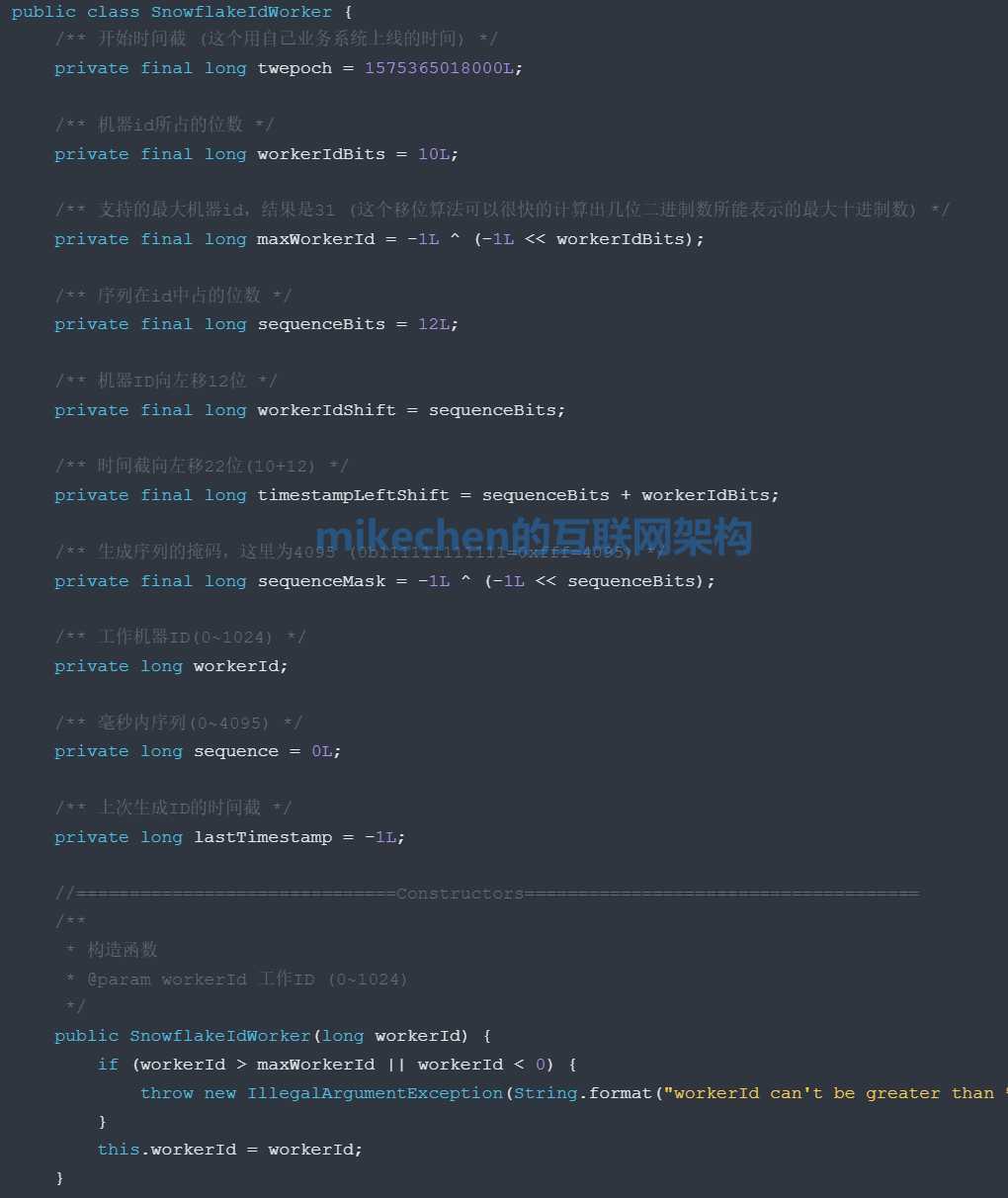
详细的雪花算法构造如下图所示:

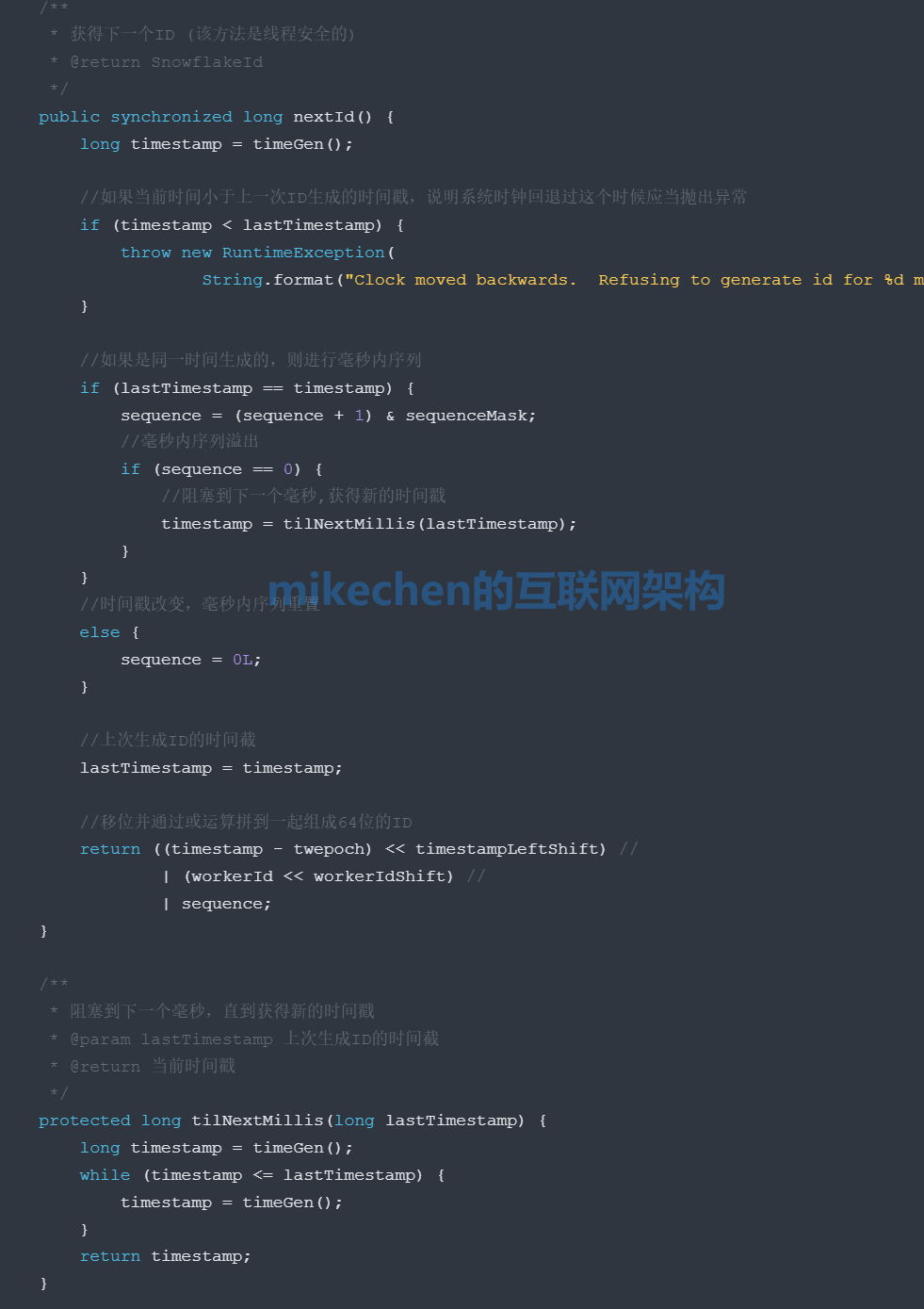
雪花算法的原理:就是生成一个的 64 位的 long 类型的唯一 id,主要分为如下4个部分组成:
1)1位保留 (基本不用)
1位标识:由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0,所以这第一位都是0。
2)41位时间戳
接下来 41 位存储毫秒级时间戳,41位可以表示2^41-1个毫秒的值,转化成单位年则是:(2^41−1)/(1000∗60∗60∗24∗365)=69年 。
41位时间戳 :也就是说这个时间戳可以使用69年不重复,大概可以使用 69 年。
注意:41位时间截不是存储当前时间的时间截,而是存储时间截的差值“当前时间截 – 开始时间截”得到的值。
这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的,一般设置好后就不要去改变了,切记!!!
因为,雪花算法有如下缺点:依赖服务器时间,服务器时钟回拨时可能会生成重复 id。
3)10位机器
10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId,最多可以部署 2^10=1024 台机器。
这里的5位可以表示的最大正整数是2^5−1=31,即可以用0、1、2、3、….31这32个数字,来表示不同的datecenterId,或workerId。
4) 12bit序列号
用来记录同毫秒内产生的不同id,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号。
理论上雪花算法方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。

作者简介
陈睿|mikechen,10年+大厂架构经验,《BAT架构技术500期》系列文章作者,专注于互联网架构技术。
阅读mikechen的互联网架构更多技术文章合集
Java并发|JVM|MySQL|Spring|Redis|分布式|高并发

 浙公网安备 33010602011771号
浙公网安备 33010602011771号