【Web前端Talk】“用数据说话,从埋点开始”-带你理解前端的三种埋点
埋点到底是什么呢?
引用自百科的原话是,埋点分析网站分析的一种常用的数据采集方法。因此其本质是分析,但是靠什么分析呢?靠埋点得到的数据。通俗来讲,就是当我想要在某个产品上得到用户的一些行为数据用来分析,就可以用埋点了。举个栗子,A用户把某本书加到了自己的书架了,我可以通过该用户书架的书的类型,由此分析该用户的阅读偏好,更深一步,通过对用户偏好的判断,我可以自动像用户推荐同类型的书,或者可以根据用户加入书架的时间,判断用户的碎片时间,在此时间段,可以定点向用户推送一些消息等。
我们可以看出,充分的埋点数据,有助于准确的分析用户的行为,为产品的调整提供方向。
欢迎关注我们的微信公众号:Web前端Talk 获取更多好的前端内容

怎么埋点呢?
要想知道埋点的方法,首先要了解埋点的分类,目前埋点主要分为三大类,分别是:
-
代码埋点
-
无埋点
-
可视化埋点(可认为是无埋点的一种)
已经知道了埋点的分类了,那么具体怎么实施呢,因其依靠数据,因此其步骤有三:
-
获取数据
-
展示数据
-
分析数据
充分准确的埋点是第一步,对后续的展示及分析都有重要的意义,因此本文重点介绍该方面。
埋点类别详解
1. 代码埋点
-
优点:监控用户行为,监测数据准确
-
缺点:工作量大,需要手动在需要埋点的地方进行埋点,因此需要侵入业务代码,比如点击事件的回调函数、页面的生命周期、ajax回调等。
常用代码埋点类型分两类,分别为命令式、声明式,可查看如下举例。
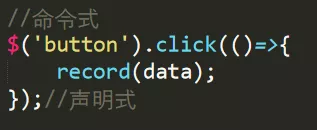

-
命令式埋点:在一些事件操作的回调函数中进行埋点,埋点的数据和方法可能多种多样的,比如图片上带数据,ajax发送数据等。
-
声明式埋点:将埋点信息封装在自定义属性中,通过sdk识别自定义属性然后获取埋点数据。
2. 无埋点
-
优势:不需要关注埋点逻辑
-
缺点:给数据传输增加压力、无法定制
无埋点统计数据基本流程
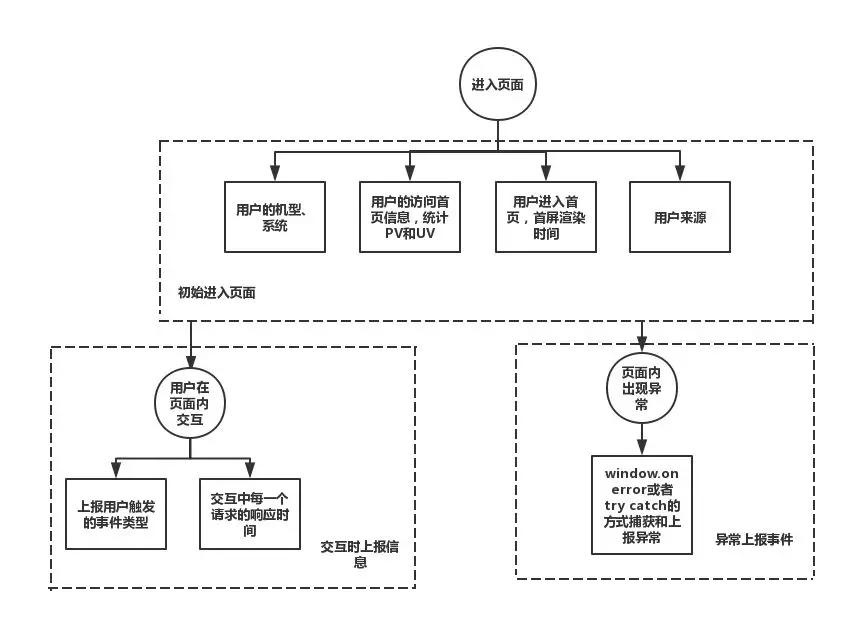
通常,当页面打开时,页面中的埋点js片段会被执行,这段js代码会异步加载一个js文件,该文件就是无埋点的sdk,会被浏览器请求到并执行,通过该脚本进行数据收集,当数据收集完成后,可以利用一些方法将数据传递给后端进行收集整理。
无埋点sdk执行阶段
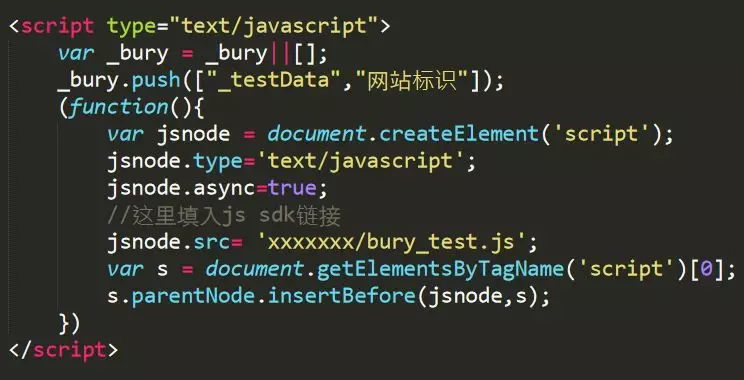
通过在页面或者基础脚本中集成这段代码,可以在对应的页面上引入我们的bury_test脚本,而bury_test脚本就是我们的埋点sdk。
埋点sdk
(function() { var buryData = {}; //常用信息 if (document) { //域名 buryData.domain = document.domain || ''; //标题 buryData.title = document.title || ''; //访问来源 buryData.referrer = document.referrer || ''; //分辨率 buryData.sw = window.screen.width || 0; buryData.sh = window.screen.height || 0; //设备信息 buryData.lang = navigator.language || ''; buryData.ua = navigator.userAgent || ''; //页面加载时间 buryData.loadT = window.performance.timing.domContentLoadedEventEnd - window.performance.timing.navigationStart || 0; } //整理埋点数据 var arg = []; if (buryData) { for (var i in buryData) { arg.push(encodeURIComponent(i) + '=' + encodeURIComponent(buryData[i])); } } var args = arg.join('&'); })
通过以上方法,可以获取一些基本的页面数据,更多详细的数据,可以根据具体的业务需求进行添加。 如何将采集到的数据进行上报呢,需要根据具体的情况来分析了,如果没有跨域的话,最简单的当然是ajax了。但是很多sdk都涉及到跨域了,目前主流的一种方法是用js脚本创建Image对象,将image的src指向后端脚本,并将数据拼接上。
3. 可视化埋点
-
优点:通过集成sdk,运营可自主选择,操作便捷。
-
缺点:
-
无法定制详细的业务数据,比如 金额、商品数量等,该类数据需要实时变化;
-
需要统一规范,无法用在不同的设备上,比如某些特殊的设备imei并不能识别。
可视化埋点与代码埋点的对比
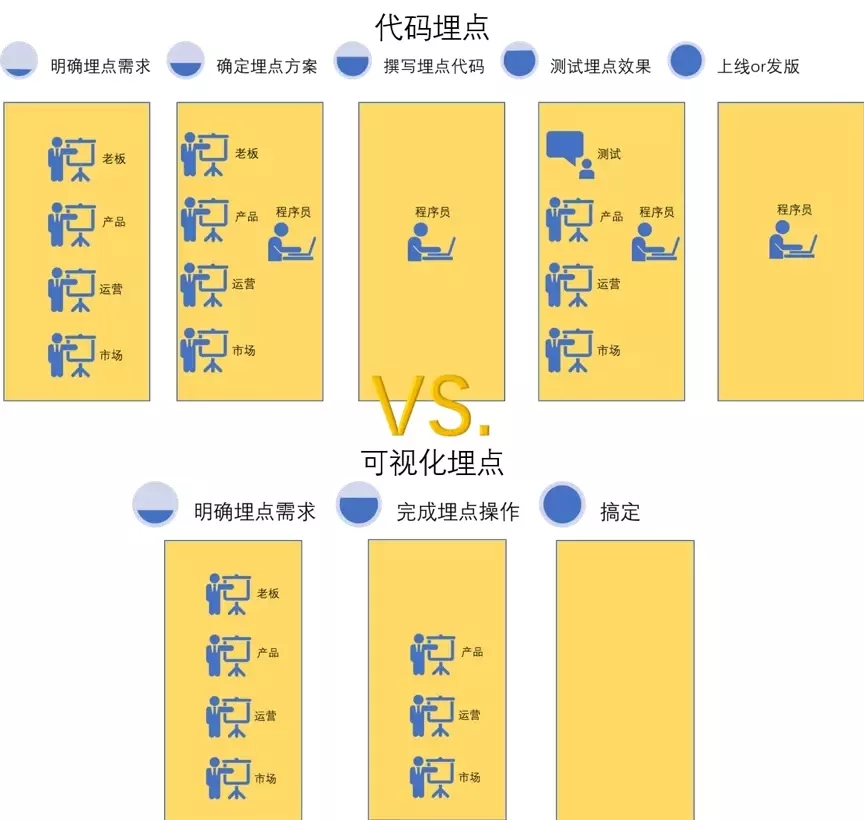
目前很多商用软件比如Mixpanel、TalkingData、诸葛IO、腾讯MTA等都可以用来可视化埋点,用户仅需要点击想要监测的元素,然后对该埋点起个对应的名字,并给个编号,就进行了埋点。
可视化埋点的核心方案是利用xpath,是在xml文档中查找信息的语言,如下图所示

通过上图方法,得到的xpath为//*[@id="1"]/div/div[2]/p[1]
如果将其换做dom的选择器,则为:#1>div>div:nth-of-type(2)>p:nth-of-type(1),由此,可以定位到固定的DOM节点。
如何获取xpath呢,这里可以提供一种方法可供参考:
var getPath = function(elem) { if (elem.id != '') { return '//*[@id=\"' + elem.id + '\"]'; } if (elem == document.body) { return '/html/' + elem.tagName.toLowerCase(); } var index = 1, siblings = elem.parentNode.childNodes; for (var i = 0, len = siblings.length; i < len; i++) { var sibling = siblings[i]; if (sibling == elem) { return arguments.callee(elem.parentNode) + '/' + elem.tagName.toLowerCase() + '[' + (index) + ']'; } else if (sibling.nodeType == 1 && sibling.tagName == elem.tagName) { index++; } } }
通过上述方法,当我们点击某个元素时,将触发的元素event.target传入,即可得到完整的xpath。
三种埋点的区别
以百度举例:
当用户点击百度一下的时候,无埋点和可视化埋点可以获取的信息有某个时刻、某个设备进行了一次搜索,甚至可以获得部分搜索信息等,但是用户在输入搜索信息时,是否进行了修改、反复删除重新输入几次等深度的业务信息,无埋点和可视化埋点是统计不到的,则需要代码埋点。
数据分析处理
针对埋点的数据进行分析处理,我认为将两个维度的任意组合即可,两个维度我将其定义为客观维度和主观维度,客观维度比如:时间、用户id、设备id、地理位置、渠道等;主观维度比如:触发事件、触发次数、入口来源、异常集合及次数等。
两个维度任意组合,可以组成任意统计数据,比如:
1月份某个页面的访问量统计、2月份某个设备购买的图书数量、3月份某个用户在某个页面用某个设备点赞的次数...
微-信-公-众-号: Web前端Talk(migufe)

↑↑↑这里推荐下我们的技术公众号,欢迎您的加入,一起探讨↑↑↑

 浙公网安备 33010602011771号
浙公网安备 33010602011771号