
OO第三单元总结
OO第三单元总结
设计策略
Homework1
-
总览-决定下笔顺序。观察到主要需要实现Network和Person接口得到MyNetwork和MyPerson类,MyPerson类中需要包含人的基本属性和对人属性操作的方法,而MyNetwork类中含有所有的人,并且需要实现人与人交互的各种方法,在特定条件下还需要抛出异常。考虑到第一次作业对社交网络的机构还不是很熟悉,所以选择先实现MyPerson类,熟悉对个体的操作后,再实现MyNetwork类,完成对整体的操作,并且了解抛出各个异常的条件,最后实现4个异常类。
-
准备-初步选择容器。由于各个类中的各个属性作用不同、性能要求也不同,所以总览后了解各个属性的大致操作后需要初步选择容器,可以先选择ArrayList或者HashMap,后续再进行修改,具体经验将留到第三部分“容器经验”讲述。
-
开工-细致阅读各个方法JML。本单元的主要工作时实现方法规格,方法规格包括:执行前对输入的要求----前置条件(precondition) ,一般以requires开头;执行过程中对于环境(参数、所在this)的改变描述----副作用(Side-Effects),一般以assignable开头 ; 执行后返回结果应该满足的约束----后置条件(postcondition),一般以ensures开头。阅读时也按照顺序,将条件分类归为正常行为和异常行为,注意每种条件可以改变的属性,需要对属性进行的操作以及需要返回的结果。
下面附上常见的用法:
\result表示一个非void类型的方法执行后所获得的结果,即方法执行后的返回值
\old表示一个表达式expr在相应方法执行前的取值,该表达式涉及到评估expr中的对象是否发生变化。b_expr1 <==> b_expr2 b_expr1 <=!=> b_expr2等价关系操作符
b_expr1 ==> b_expr2 b_expr1 ==> b_expr2推理操作符,当前值条件为真时,后置调节也保证为真
\nothing \everything变量引用操作符,前者空集,后者全集,经常用在assignable语句中,assignable \nothing表示当前作用域下每个变量都不可以在方法执行过程中被赋值(/*@ pure @ */)指不会对对象的状态进行任何改变,也不需要提供输入参数,这样的方法无需描述前置条件,也不会有任何副作用,且执行一定会正常结束
public normal_behavior public exception_behavior定义正常行为和异常行为
signals (Exception e) b_expr满足b_expr条件时,抛出异常e(\forall A1;A2;A3)全称量词修饰的表达式,表示对于所有的A1,在A2条件成立时,每个元素都满足A3
(\exists A1;A2;A3)存在量词修饰的表达式,表示A1中存在元素,使得在A2条件成立时,满足A3
\sum返回给定范围内的表达式的和invariant Pinvariant指不变式,表示P是要求在所有可见状态下都必须满足的特性,其中invariant为关键词, P为谓词(参考:https://blog.csdn.net/piaopu0120/article/details/89527175)
-
实现-代码实现方法规格。注意以下几点:
- 根据正确的前置条件,将正常行为和异常行为分别实现,不能忘记抛出异常。
- 实现异常时注意顺序,满足两个异常条件时抛出前面异常而忽略后面的异常。
- 注意条件中可以修改的属性和不可以修改的属性,保证不可修改的属性不被修改。
- 注意括号,比如\old修饰的表达式到底是什么,\sum求和的表达式。
- 在实现过程中,若想减少遍历操作,尽量使用HashMap,查找效率会高一些。
Homework2 && Homework3
-
总体思路与第一次作业相同,先总览查看需要增加的类和方法,理解每个类的用途,决定完成顺序,然后根据前面作业的经验选择数据结构,阅读JML后实现。
-
但由于后面作业对性能的要求较高,所以需要对原有的O(n^2)的方法修改。
-
增加类后细节增多,需要关注每个操作的细节,精准实现JML规格。
测试方法
总体来说:测试分为准备测试数据→触发测试→将期望结果与实际结果对照→输出测试结果,示意图如下。
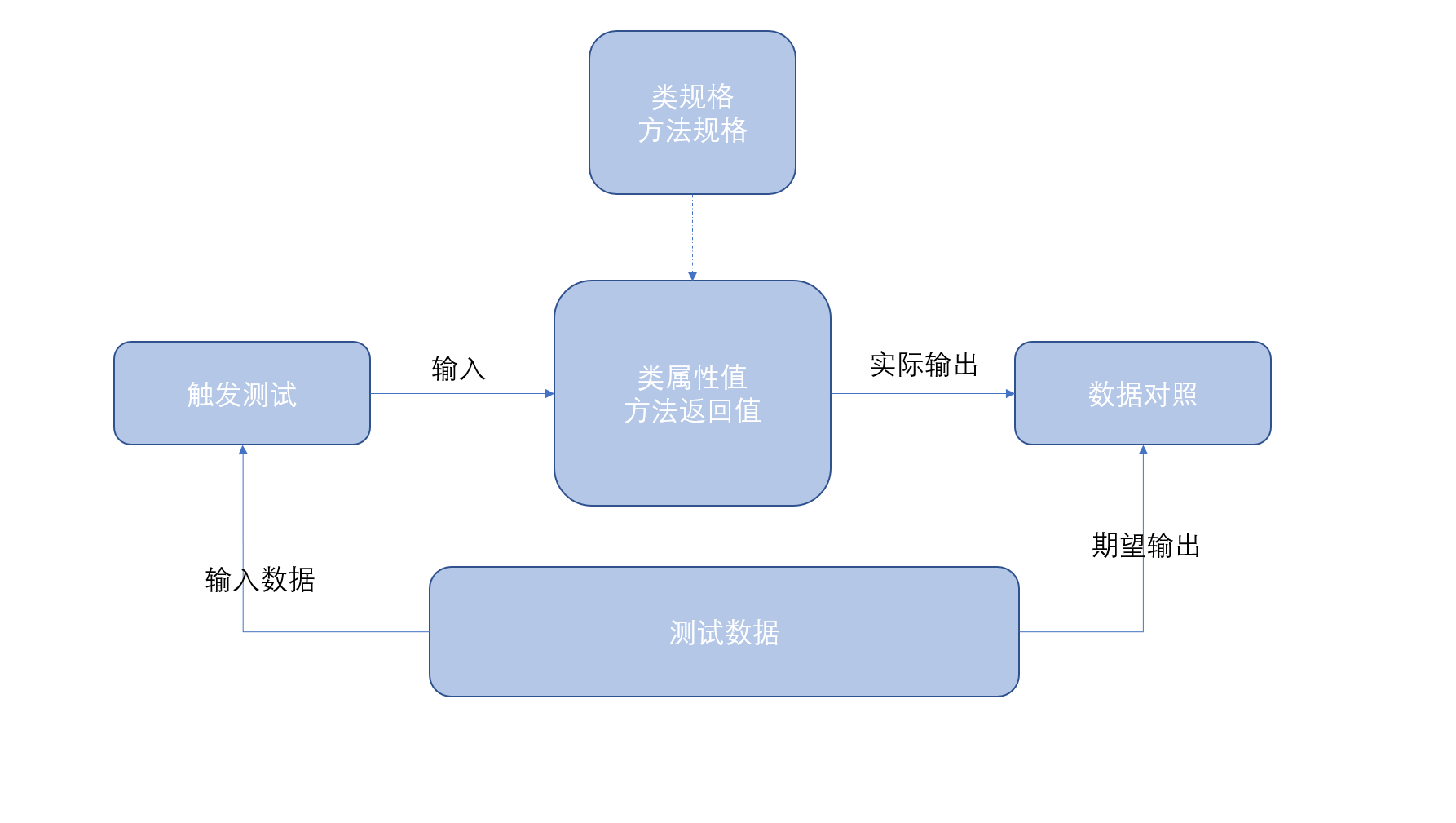
- 准备测试数据
- 前置条件涉及的数据和方法输入参数。大的划分:满足前置条件、不满足前置条件;细致划分:针对每个数据项,按照约束条件和数据特征来划分。包含正常行为和异常行为的数据,正常行为可能又包括几种情况,需要尽量全面。可以针对某个方法人工构造易错数据,如测试自己和自己是否isLinked,注意覆盖全面。
- 后置条件涉及的数据。用以判断执行效果的参考数据,即期望输出,用以与所得输出对照,此时可以利用python强大的库函数。特点:常常与输入数据和对象状态有关,具有动态性。
- 不变式和修改约束涉及的数据。可以在方法调用时通过输出中间变量或者调用另一个方法获得相应的对象状态,是用以判断状态是否正确的参考数据。
- 可以人工构造数据,注意易错的方法重点测试。也可以按照一定策略随机自动生成数据。
-
触发测试和数据比对
使用JUnit针对JML进行单元测试,确保每个方法都满足规格,在任何使用场景下,类都能确保状态正确。
下载JUnit插件后,右击需要测试的方法点击Go To->Test即可自动生成测试模板,在其中填写测试本方法的代码语句即可。
- 使用JUnit时,方法头顶的注解归纳如下:
@Test表示方法作为一个测试案例。测试异常时,可以将Test与expected一起使用,例如: @Test(expected = ArithmeticException.class)
@Before方法在test方法前运行,常用来表示开始某方法测试。
@After方法在test方法后运行,常用来表示结束某方法测试。
@BeforeClass方法在类中所有方法前运行,常用来表示开始总测试。只执行一次。
@AfterClass方法在所有测试结束后执行,常用来表示结束总测试。只执行一次。- JUnit中使用断言来判断方法得到的输出与期望输出是否一致,常用的方法如下:
void assertEquals(boolean expected, boolean actual)检查两个变量或者等式是否平衡void assertTrue(boolean expected, boolean actual)检查条件是否为真void assertFalse(boolean condition)检查条件是否为假void assertNotNull(Object object)检查对象是否不为空void assertNull(Object object)检查对象是否为空void assertSame(boolean condition)检查两个相关对象是否指向同一个对象void assertNotSame(boolean condition)检查两个相关对象是否不指向同一个对象void assertArrayEquals(expectedArray, resultArray)检查两个数组是否相等(参考:https://www.jianshu.com/p/a3fa5d208c93)
- 编写好测试代码后,点击运行即可获得本方法的测试结果。测试失败可能有两种情况:1、Failures一般由单元测试使用的断言方法判断失败所引起的,表示程序输出的结果与我们预期的不一样。2、Errors是由代码异常引起的,它可以产生于测试代码本身的错误,也可以是被测试代码中的一个隐藏bug
- JUnit的好处:可以查看每个类以及类中的方法,甚至是每一行代码在测试中的覆盖率,没被覆盖到的代码会有红色标记,可以查看branch执行的情况,从而进行代码级别的全面测试。可以单独对每个方法、每个类进行单独编写测试用例,进行单元测试。
容器经验
-
笔者第一次作业使用的是TreeMap,TreeMap与HashMap的区别在于TreeMap基于树结构,是按key值顺序存储的,在key需要排序的时候效率较高,但后来发现,只有姓名需要排序,而姓名可能有重复的,所以作为key值会很麻烦,需要value值是一个容器,而由于添加或者删去元素时,TreeMap需要维持数据结构的原来形式,所以甚至比HashMap还要慢一些。
-
较为建议使用HashMap,复杂度为O(1)。考虑到每个人的id唯一,可以唯一地确定这个人从而访问他的所有属性,所以这里使用了人的id作为key值,value值依据需要确定。HashMap的增删改查都有对应的方法,效率都很好。
这里介绍几个常用的方法:
hashMap.put(key,value); //向hashMap中添加键值对key-value
hashMap.get(key); //在hashMap中得到key对应的value
hashMap.remove(key); //删除hashMap中的指定键key的映射关系
hashMap.size(); //返回hashMap中键值对的数目
hashMap.containsKey(key); //查看hashMap中是否包含对应的键key
hashMap.keySet() //用于迭代,返回hashMap的所有key
hashMap.values() //用于迭代,返回hashMap的所有value
-
使用hashMap时需要注意以下几点:
-
key不能重复,若键相同,后面添加的新键值对会覆盖原来的键值对。所以若一个key需要对应多个值,可以考虑把值设置为容器
-
遍历hashMap进行删除时,直接删除会出现异常,所以需要用到迭代器或者removeIf+lambda,这里提供一个使用后面方法删除的例子:
emojiHeatList.entrySet().removeIf(emojiId -> (emojiId.getValue() < limit)); //当emojiId.getValue()<limit时,删除emojiHeatList里,emojiId作为键的键值对
-
-
考虑到有些地方不需要根据id进行索引,所以也使用了ArrayList,例如MyPerson类中的acquaintance属性(表示和这个人有联系的人),利用ArrayList
或者ArrayList 存储或者group(表示这个人加入的群体),利用ArrayList 或者ArrayList 存储。
性能优化
Homework1
-
isCircle()方法由于需要寻找两个点之间是否有路径,需要遍历图,而采用BFS或者DFS性能稍低。可以考虑使用并查集,记录每个节点的父节点,一开始加入的节点父节点是它自身,加入新的有关联的节点时将其中一个的根节点的父节点设置为另一个的祖先节点,这样加入时即可形成类似森林的结构,简化了查找的时间复杂度。而判断两点之间是否有路径时查找两点的根节点是否相同即可,相关查找根节点的find方法代码如下:
private int find(int findId) { //寻找其根节点 if (father.get(findId) == findId) { return findId; } else { father.put(findId, find(father.get(findId))); //父节点设置为根节点 return father.get(findId); } } -
queryBlockSum()方法用来查找连通分量的个数,若完全按照JML进行两层循环判断两点是否有路径来计算连通分量,则性能容易爆炸。依旧可以利用前面的并查集解决性能问题,计算连通分量只需要看森林结构的树的个数即可,所以计算父节点是它自身的节点个数即是根节点的节点数目即可。
Homework2
- qgvs查询群体内各个人之间的value值时若采取双层循环暴力查询的方法,可能会出现性能问题。这里采取了在group中维护了valueSum的属性的方法。其中,有以下几种情况:(1)将A加入群体时,群体中存在B和A有关联。所以addPerson()方法中需要遍历群体中的人,寻找与A有关系的人并且将valueSum加对应的值。(2倍!!!)(2)将A和B加入群体后,再将A与B关联。所以在addRelation()方法执行时需要寻找A和B共有的群体,增加对应的valueSum。考虑到这种情况,需要在MyPerson类中增加group的属性,即记录这个人加入的群体(3)将A移出群体时,需要删除对应群体的valueSum。此处应该注意,还需要修改对应人的group属性。
Homework3
-
sendIndirectMessage方法中需要找到最短路径,需要在性能方面有所考虑。这里采用了堆优化的Dijkstra算法,即采用优先队列对Dijkstra算法进行优化,提高效率。可以考虑采用java自带的prioriQueue和pair等数据结构实现。代码实现如下:
public int dijkstra(Message message, int src) { PriorityQueue<Node> priorityQueue = new PriorityQueue(new Comparator<Node>() { @Override public int compare(Node o1, Node o2) { return o1.getDistance() - o2.getDistance(); } }); //比较器,根据最短距离决定优先队列的排列 priorityQueue.add(new Node(src, 0)); //Node类存储了节点id和到目的地的距离 HashMap<Integer, Boolean> visit = new HashMap<>(); //是否访问过此节点 visit.put(src, true); HashMap<Integer, Integer> dist = new HashMap<>(); //起点到i点的距离 dist.put(src, 0); for (Person personFind : people.values()) { if(persinFind.getId() != src){ dist.put(personFind.getId(), Integer.MAX_VALUE); visit.put(personFind.getId(), false); } } //初始化 while (!priorityQueue.isEmpty()) { Node x = priorityQueue.poll(); //取出距离最短的节点 if (visit.get(x.getNodeId())) { continue; } visit.put(x.getNodeId(), true); //标记已经访问过 if (x.getNodeId() == message.getPerson2().getId()) { break; } //已经到达目的节点,可以推出循环 for (Person person ((MyPerson)getPerson(x.getNodeId())).getAcquaintance()) { if (!visit.get(person.getId()) && dist.get(person.getId()) > x.getDistance()+person.queryValue(getPerson(x.getNodeId()))) { dist.put(person.getId(), x.getDistance()+person.queryValue(getPerson(x.getNodeId()))); priorityQueue.add(new Node(person.getId(),dist.get(person.getId()))); } } //寻找是否有未访问过且距离下一个节点较近的节点 } return dist.get(message.getPerson2().getId()); //返回最短距离 }
架构设计
Homework1
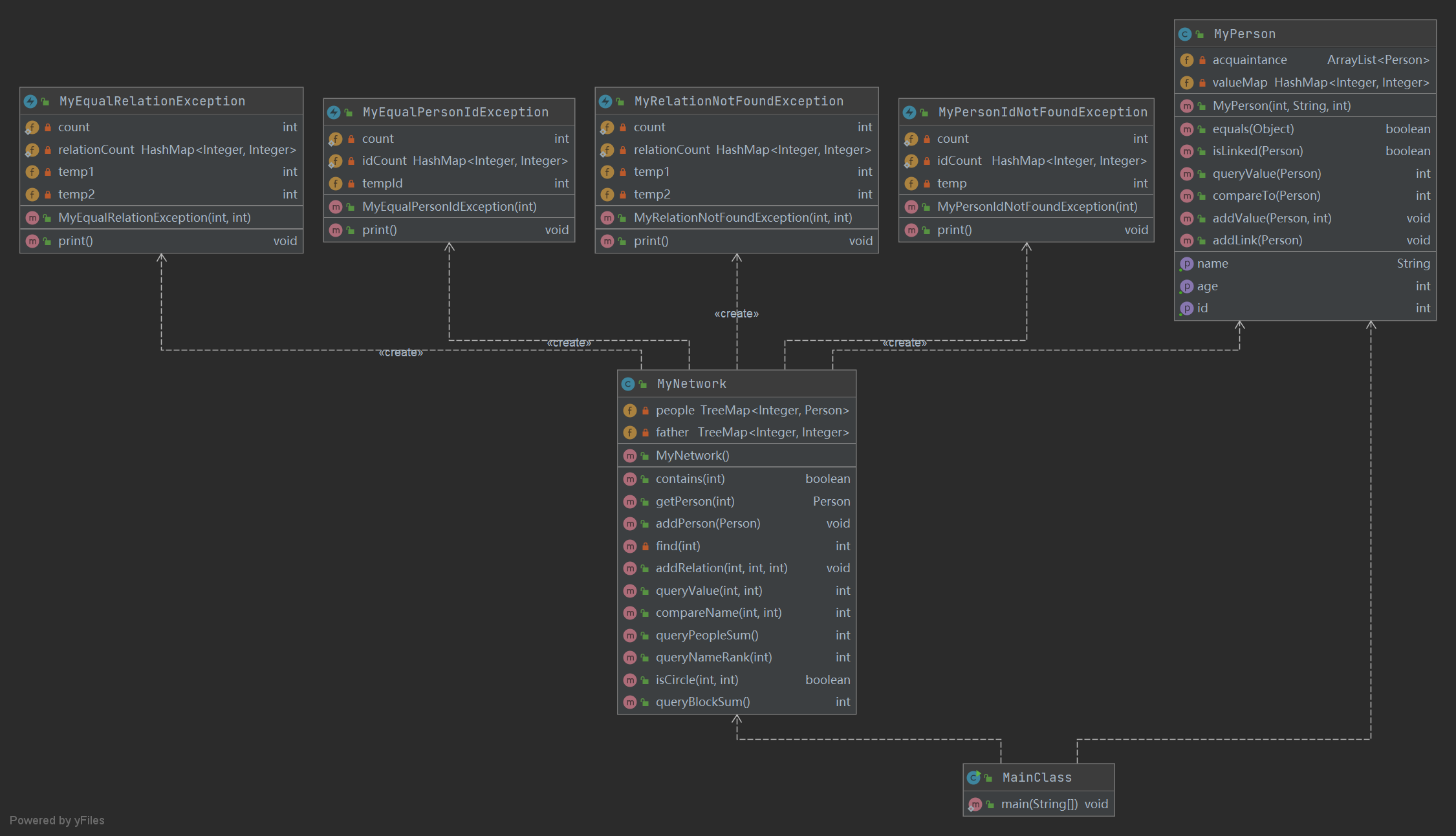
第一次作业实现了MyNetwork类、MyPerson类和四个异常类。四个异常类负责输出对应的异常信息,不再赘述。Myperson类维护了人的数据并且对其进行操作,包含了acquaintance(熟人序列)和valueMap(存储与另一个人的value值),通过addLink方法构建节点与节点之间的关联,addValue方法赋予边权值。MyNetwork维护了所有人节点,包含了people(所有的人节点)和father(节点的父节点,为了并查集而设计),通过addPerson加入人节点,addRelatioin来使得节点与节点之间关联。而其它方法均不对属性进行修改。具体类与方法图示如下:
Homework2
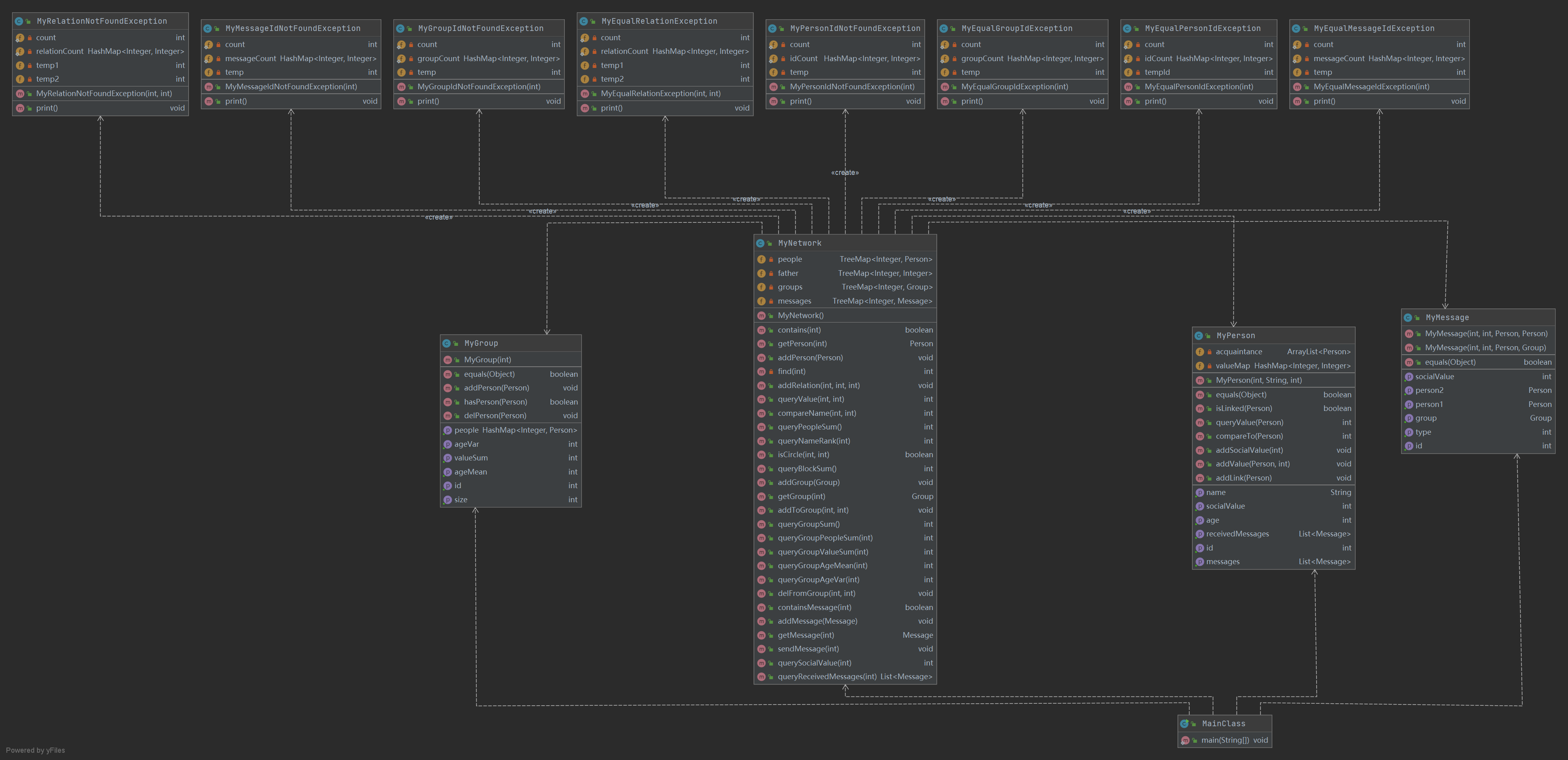
第二次作业在第一次作业的基础上实现了MyGroup类、MyMessage类和另外四个异常类并且对MyPerson类和MyNetwork类进行了补充,总体来说,多了群体的概念并且增加了人与人的交互。增加了MyPerson的messages属性(表示这个人受到的消息)以及socialValue属性,MyNetwork中增加了groups属性和messages属性,可以在addGroup或者addMessage等方法中修改整体的群体或消息属性,在addToGroup或者sendMessage方法中修改人的属性。MyGroup中维护了群体中的人序列,addPerson/delPerson可以对其修改。Mymessage维护了一系列消息的属性,主要记录消息的信息。总体图的架构建立在第一次作业基础上,只是节点多了一些额外的属性。具体类与方法图示如下:
Homework3
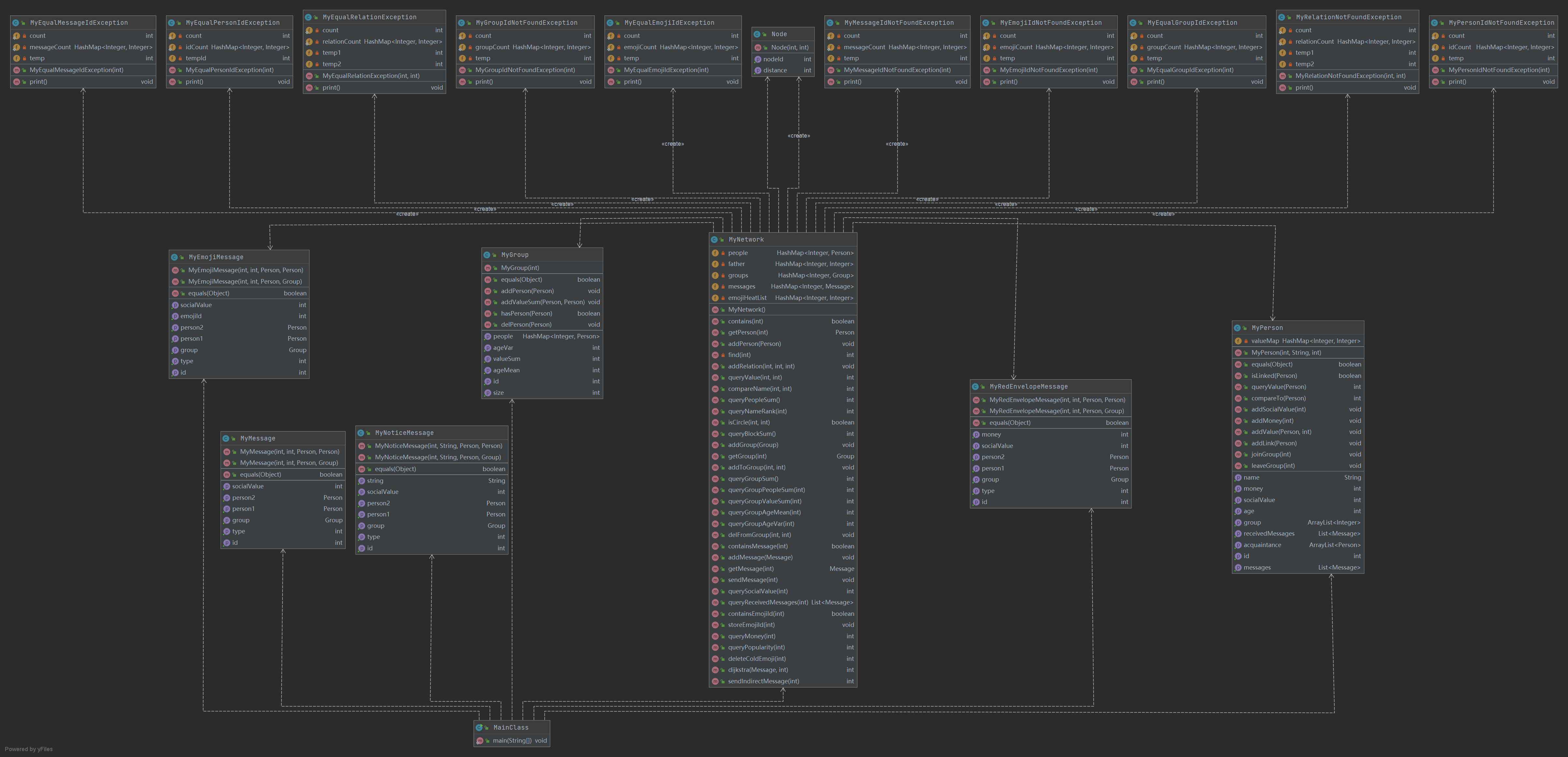
第三次作业在第二次作业的基础上增加了MyRedEnvelopMessage类、MyEmojiMessage类、MyNoticeMessage类和额外的两个异常类。MyNetwork增加了emojiHeatList属性,记录表情的使用热度,MyPerson加入money属性,表示人所拥有的的钱数。新增加的三个xxxMessage类均继承自Message接口,属于不同种类的消息,各自有不同的操作。总体来说与第二次作业仅仅增加了一些细节,并且考察了最短路径的求法,整体图的构造与前两次作业无太大区别。(Node类保存了节点的id和距离某节点的距离,用于堆优化的Dijkstra算法,但是其实可以用java所带的数据结果pair代替)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号