explain分析sql效果
1.id: 代表select 语句的编号, 如果是连接查询,表之间是平等关系, select 编号都是1,从1开始. 如果某select中有子查询,则编号递增.如下一条语句2个结果
mysql> explain select goods_id,goods_name from goods where goods_id in (sele
ct goods_id from goods where cat_id=4) \G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: goods
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 31
Extra: Using where
*************************** 2. row ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: goods
type: unique_subquery
possible_keys: PRIMARY,cat_id
key: PRIMARY
key_len: 3
ref: func
rows: 1
Extra: Using where
2. select_type simple 不包含子查询, primary 包含子查询
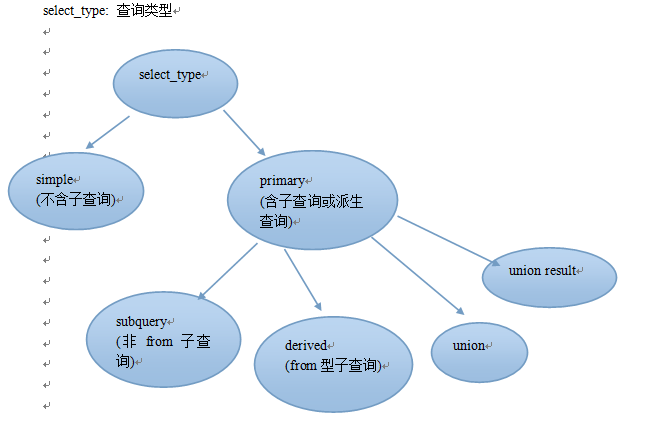
3.
table: 查询针对的表
有可能是
实际的表名 如select * from t1;
表的别名 如 select * from t2 as tmp;
derived 如from型子查询时 select * from (select id from )
null 直接计算得结果,不用走表 例如:select 1+2;
4.possible_key: 可能用到的索引
注意: 系统估计可能用的几个索引,但最终,只能用1个.
key : 最终用的索引.
key_len: 使用的索引的最大长度,key_len越小越好
5.type列: 是指查询的方式, 非常重要,是分析”查数据过程”的重要依据可能的值
all: 意味着从表的第1行,往后,逐行做全表扫描.,运气不好扫描到最后一行. (最差)
index: 比all性能稍好一点,通俗的说: all 扫描所有的数据行,相当于data_all index 扫描所有的索引节点,相当于index_all
range: 意思是查询时,能根据索引做范围的扫描,
ref: 意思是指 通过索引列,可以直接引用到某些数据行
eq_ref: 是指,通过索引列,直接引用某1行数据
const, system, null 这3个分别指查询优化到常量级别, 甚至不需要查找时间.
从左往右,越来越好: all->index->range->ref->eq_ref->const->system->null
一般按照主键来查询时,易出现const,system或者直接查询某个表达式,不经过表时, 出现NULL
6.ref列 指连接查询时, 表之间的字段引用关系.例如下面的id.2 的ref
mysql> explain select goods_id,cat_name,goods_name from goods inner join ec
_category using(cat_id) where ecs_category.cat_name='' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goods
type: ALL
possible_keys: cat_id
key: NULL
key_len: NULL
ref: NULL
rows: 31
Extra:
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: ecs_category
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: shop. goods.cat_id
rows: 1
Extra: Using where
7.rows : 是指估计要扫描多少行.
8.extra:
using index: 是指用到了索引覆盖,效率非常高
using where 是指光靠索引定位不了,还得where判断一下
using temporary 是指用上了临时表, group by 与order by 不同列时,或group by ,order by 别的表的列.
using filesort : 文件排序(文件可能在磁盘,也可能在内存),
Using filesort
看 到这个的时候,查询就需要优化了。MYSQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来 排序全部行
Using index
列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表 的全部的请求列都是同一个索引的部分的时候
Using temporary
看到这个的时候,查询需要优化了。这 里,MYSQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上
Using where
使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。如果不想返回表中的全部行,并且连接类型ALL或index, 这就会发生,或者是查询有问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号