RAG核心
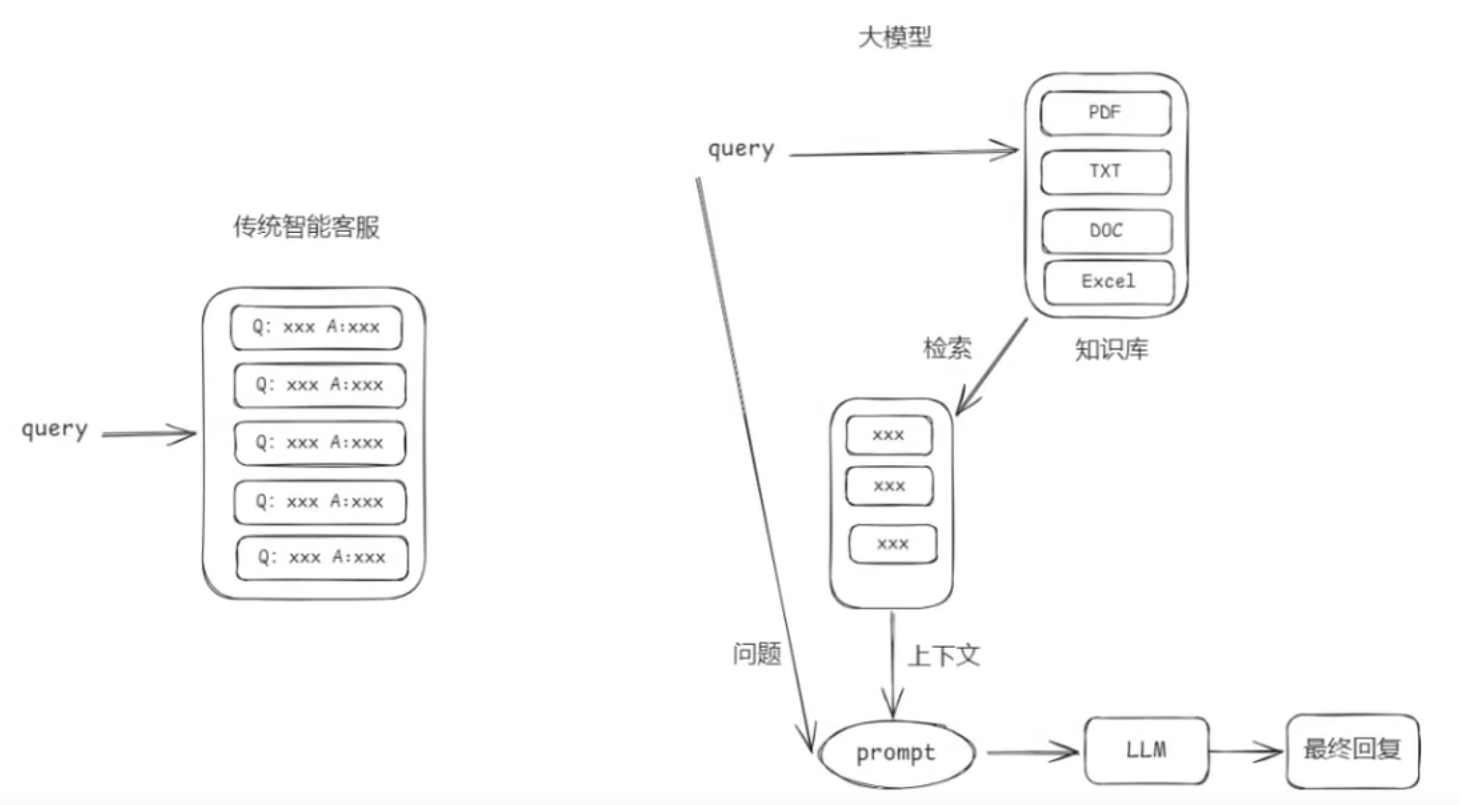
传统VS大模型
智能客服系统在没有大模型之前我们也是可以设计完成的只是实现的效果没有大模型那么好。下面是两则设计的原理
向量与Embeddings的定义
在数学中,向量(也称为欧几里得向量),指具有大小(magnitude)和方向的量。它可以形象化地表示为带箭头的线段。箭头所指:代表向量的方向;线段长度:代表向量的大小。
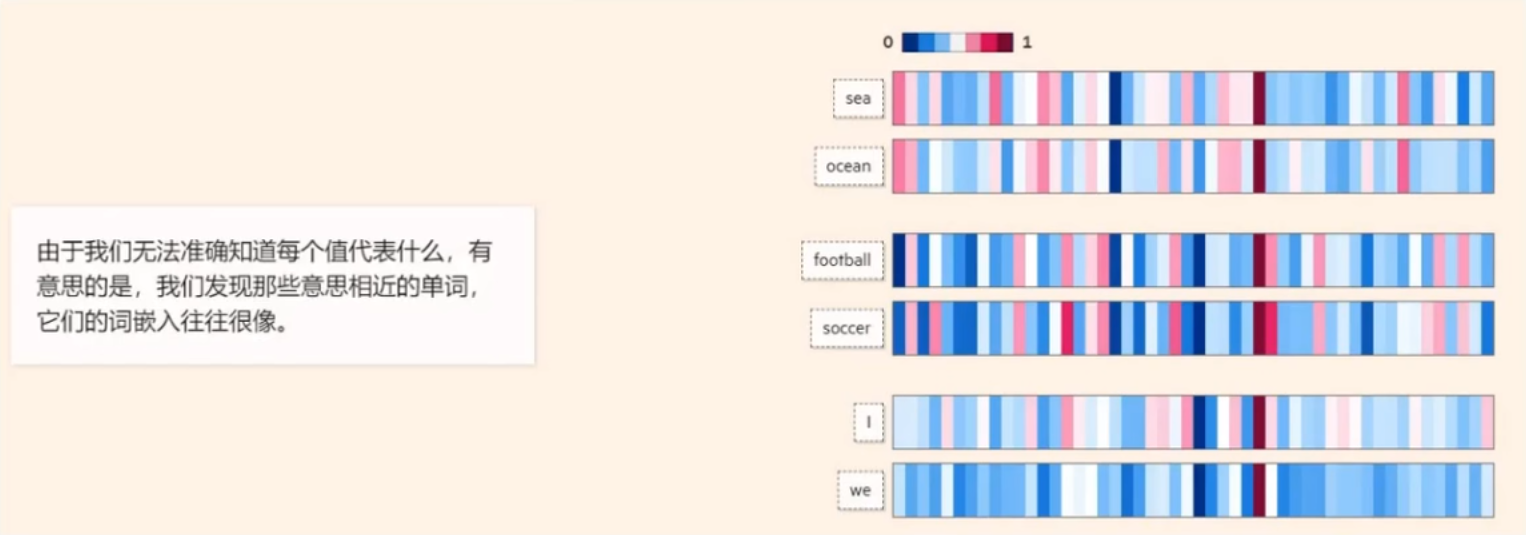
text-heartedeing-3-light 是 OpenAI 推出的一个文本嵌入模型,属于 text-embedding-3 系列中的大尺寸版本,是一个功能强大、灵活性高的文本嵌入模型,适合处理复杂的自然语言任务。
向量间的相似度计算
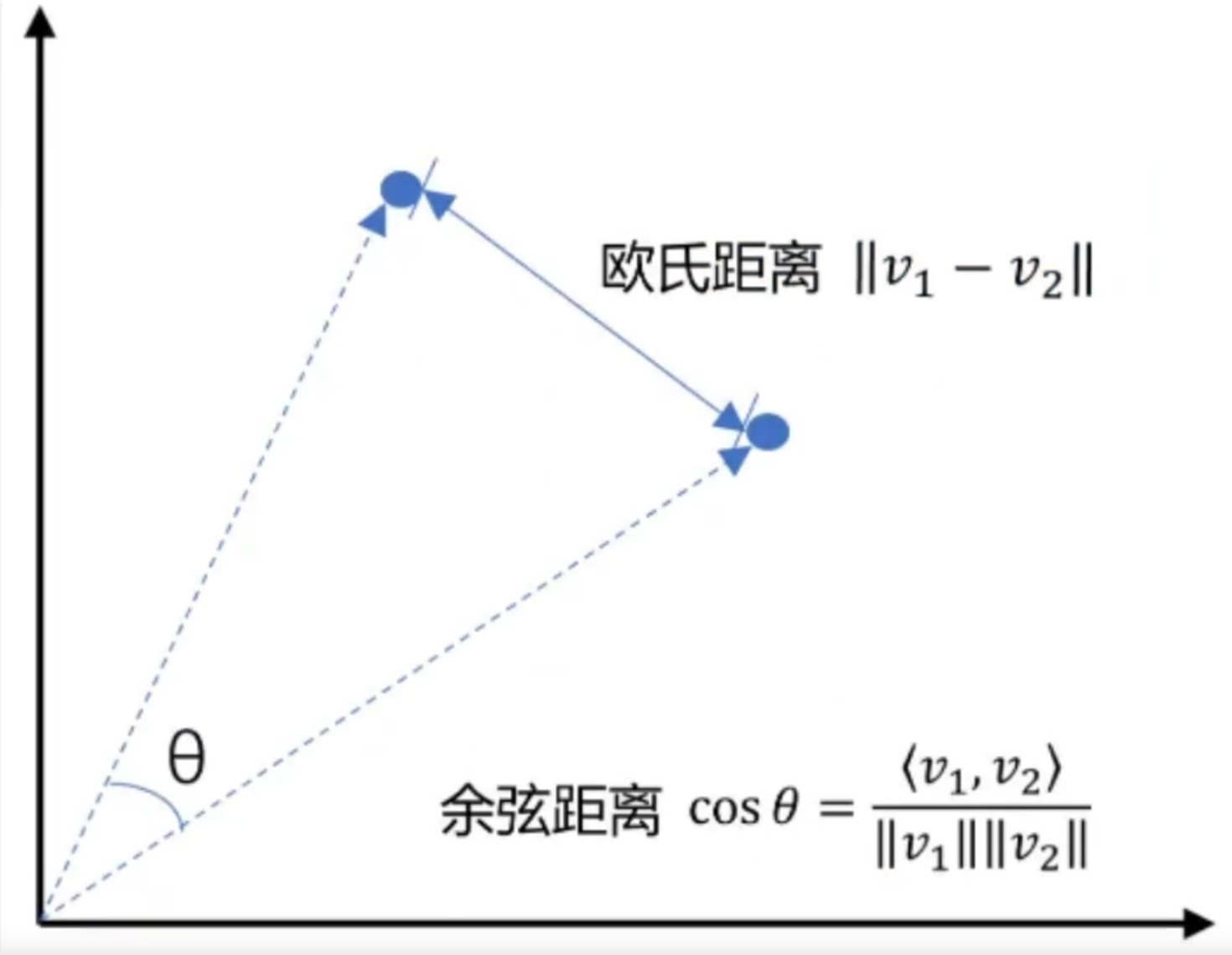
欧氏距离:越小越相似
余弦距离:越大越相似
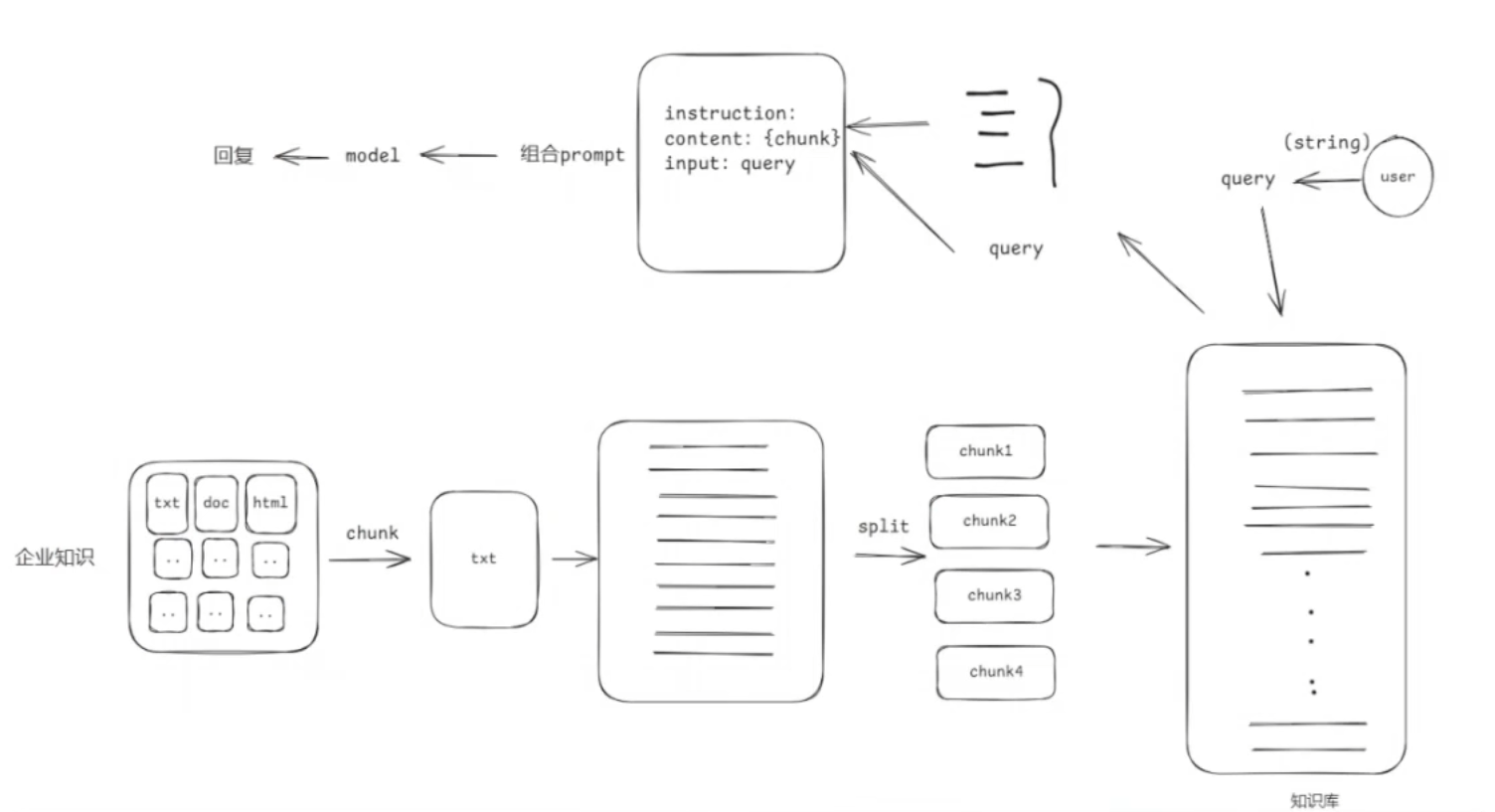
文档的加载和分割
-
基于文档的LLM回复系统搭建
![]()
-
把文本切分成chunks
我们把文本切分成chunks的方式有很多种:
- 按照句子来切分
- 按照字符数来切分
- 按固定字符数结合overlapping window
- 递归方法 RecursiveCharacterTextSplitter
向量检索
检索的方式有哪些?列举两种:
-
关键字搜索:通过用户输入的关键字来查找文本数据。
我们需要把相关的信息存储在Redis中。我们需要先按照一个Redis。在提供的资料中有。直接解压缩。然后cmd进入到对应的目录。然后输入
-
语义搜索:不仅考虑关键词的匹配,还考虑词汇之间的语义关系,以提供更准确的搜索结果。
向量数据库
在人工智能时代,向量数据库已成为数据管理和AI模型不可或缺的一部分。向量数据库是一种专门设计用来存储和查询向量嵌入数据的数据库。这些向量嵌入是AI模型用于识别模式、关联和潜在结构的关键数据表示。
随着AI和机器学习应用的普及,这些模型生成的嵌入包含大量属性或特征,使得它们的表示难以管理。这就是为什么数据从业者需要一种专门为处理这种数据而开发的数据库,这就是向量数据库的用武之地。
Pinecone
Pinecone: http://www.pinecone.io/
Pinecone的关键特性包括:
- 重复检测:帮助用户识别和删除重复的数据
- 排名跟踪:跟踪数据在搜索结果中的排名,有助于优化和调整搜索策略
- 数据搜索:快速搜索数据库中的数据,支持复杂的搜索条件
- 分类:对数据进行分类,便于管理和检索
- 去重:自动识别和删除重复数据,保持数据集的纯净和一致性
Milvus
Milvus: milvus.io/
Milvus的关键特性包括:
- 毫秒级搜索万亿级向量数据集
- 简单管理非结构化数据
- 可靠的向量数据库,始终可用
- 高度可扩展和适应性强
- 混合搜索
- 统一的Lambda结构
- 受到社区支持,得到行业认可
Chroma
Chrome: http://www.try-chroma.com/
Chroma的关键特性包括:
- 功能丰富:支持查询、过滤、密度估计等多种功能
- 即将添加的语言链(LangChain)、Liamainindex等更多功能
- 相同的API可以在Python笔记本中运行,也可以扩展到集群,用于开发、测试和生产
如何选型向量数据库
在选择适合项目的向量数据库时,需要根据项目的具体需求、团队的技术背景和资源情况来综合评估。以下是一些建议和注意事项:
向量嵌入的生成
-
如果已经有了自己的向量嵌入生成模型,那么需要的是一个能够高效存储和查询这些向量的数据库
-
如果需要数据库服务来生成向量嵌入,那么应该选择提供这类功能的产品
延迟要求
-
对于需要实时响应的应用程序,低延迟是关键。需要选择能够提供快速查询响应的数据库
-
如果应用程序允许批量处理,那么可以选择那些优化了大批量数据处理的数据库
开发人员的经验
- 根据团队的技术栈和经验,选择一个易于集成和使用的数据库
- 如果团队成员对某些技术或框架更熟悉,那么选择一个能够与之无缝集成的数据库会更有利

 浙公网安备 33010602011771号
浙公网安备 33010602011771号