RAG介绍
LLM的缺陷:
- LLM的知识不是实时的,不具备知识更新。
- LLM可能不知道你私有的领域/业务知识。
- LLM有时会在回答中生成看似合理但实际上是错误的信息。
为什么会用到RAG:
- 提高准确性:通过检索相关的信息,RAG可以提高生成文本的准确性。
- 减少训练成本:与需要大量数据来训练的大型生成模型相比,RAG可以通过检索机制来减少所需的训练数据量,从而降低训练成本。
- 适应性强:RAG模型可以通过新的或不断变化的数据。由于它们能够检索最新的信息,因此在新数据和事件出现时,它们能够快速适应并生成相关的文本。
RAG概念:
- RAG(Retrieval Augmented Generation)通过检索外部数据,增强大模型的生成效果。
- RAG为LLM提供了从某些数据源检索到的信息,并基于此修正生成的答案。
- RAG基本上是Search + LLM提示,可以通过大模型回答查询,并将搜索算法所找到的信息作为大模型的上文。查询和检索到的上下文都会被注入到发送到LLM的提示语中。
RAG vs Fine-tuning
RAG(检索增强生成)是把内部的文档数据先进行embedding,借助检索先获得大致的知识范围答案,再结合prompt给到LLM,让LLM生成最终的答案。
Fine-tuning(微调)是用一定量的数据集对LLM进行局部参数的调整,以期望LLM更加理解我们的业务逻辑,有更好的zero-shot能力。
RAG工作流程
RAG论文:https://arxiv.org/pdf/2312.10997
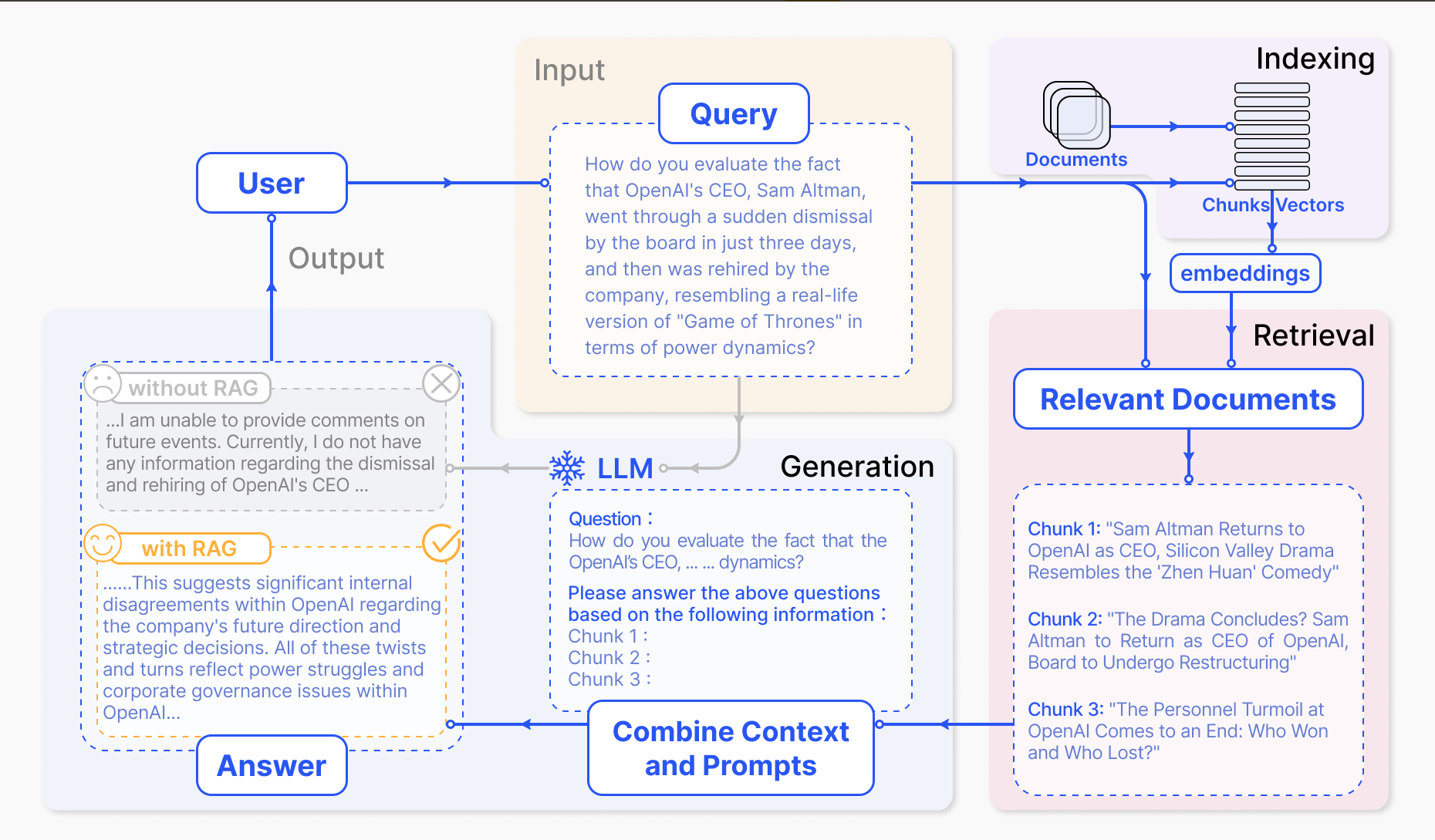
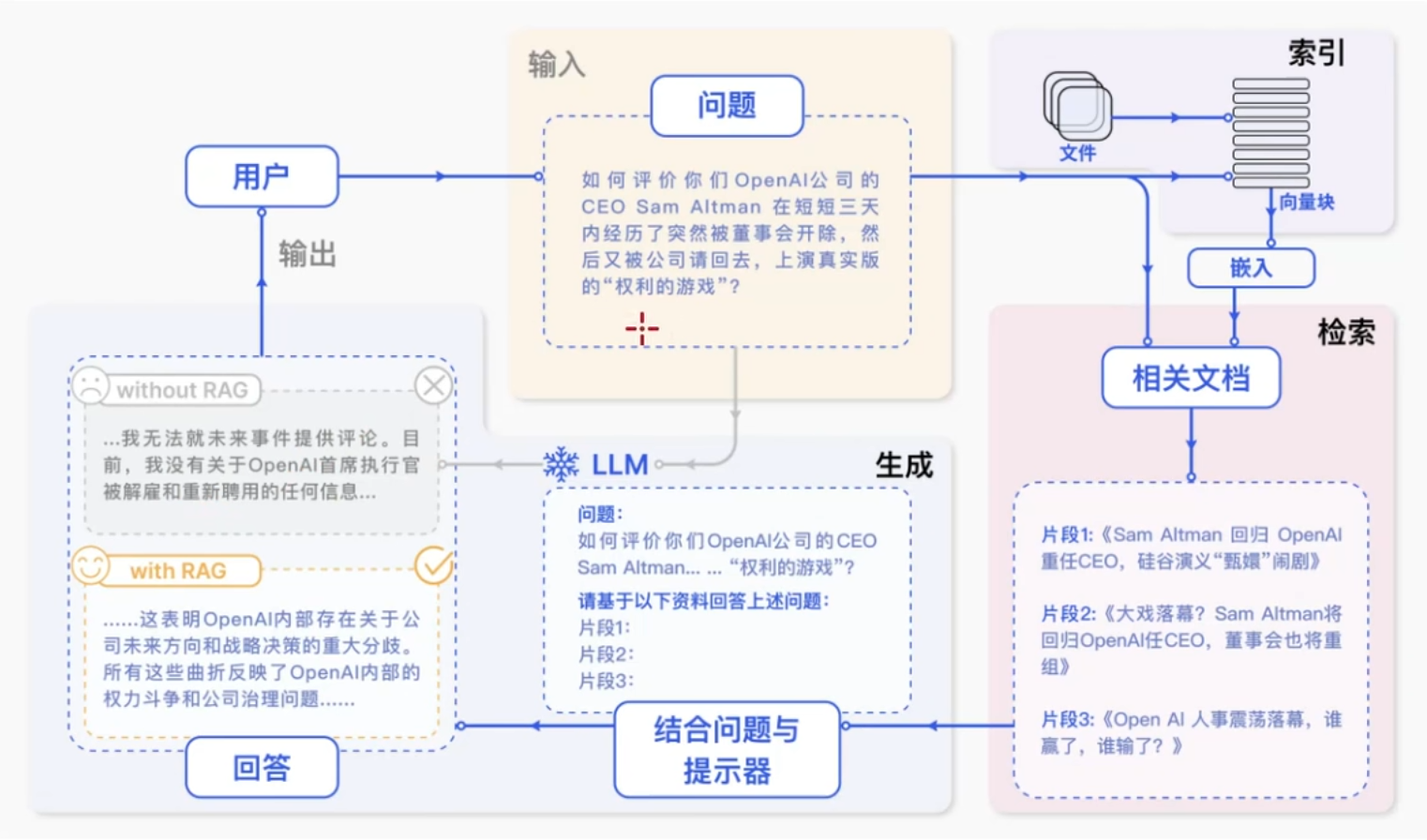
翻译
RAG系统搭建流程
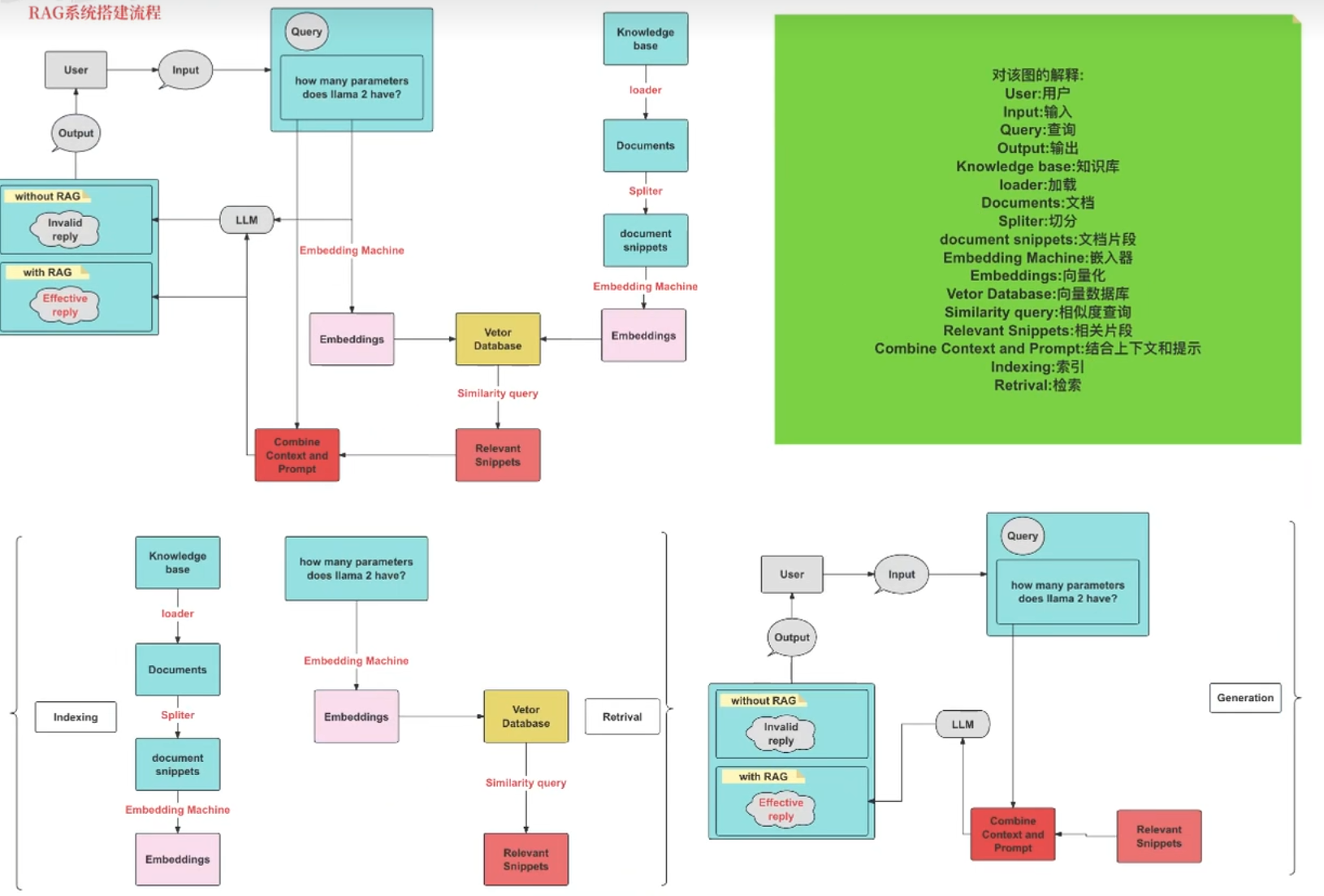
索引(Indexing):索引首先清理和提取各种格式的原始数据,如PDF、HTML、Word和Markdown,然后将其转换为统一的纯文本格式。为了适应语言模型的上下文限制,文本被分割成更小的、可消化的块(chunk)。然后使用嵌入模型将块编码成向量表示,并存储在向量数据库中。这一步对于在随后的检索阶段实现高效的相似性搜索至关重要。知识库分割成chunks,并将chunks向量化至向量库中。
检索(Retrieval):在收到用户查询(Query)后,RAG系统采用与索引阶段相同的编码模型将查询转换为向量表示,然后计算索引语料库中查询向量与块向量的相似性得分。该系统优先级和检索最高k(Top-k)块,显示最大的相似性查询。
例如,二维空间中的向量可以表示为(x,y),表示从原点(0,0)到点(x,y)的有向线段。
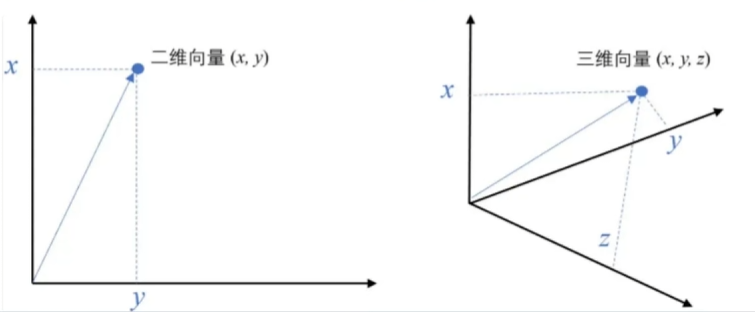
- 将文本转成一组浮点数:每个下标i,对应一个维度
- 整个数组对应一个n维空间的一个点,即文本向量又叫Embeddings
- 向量之间可以计算距离,距离远近对应语义相似度大小
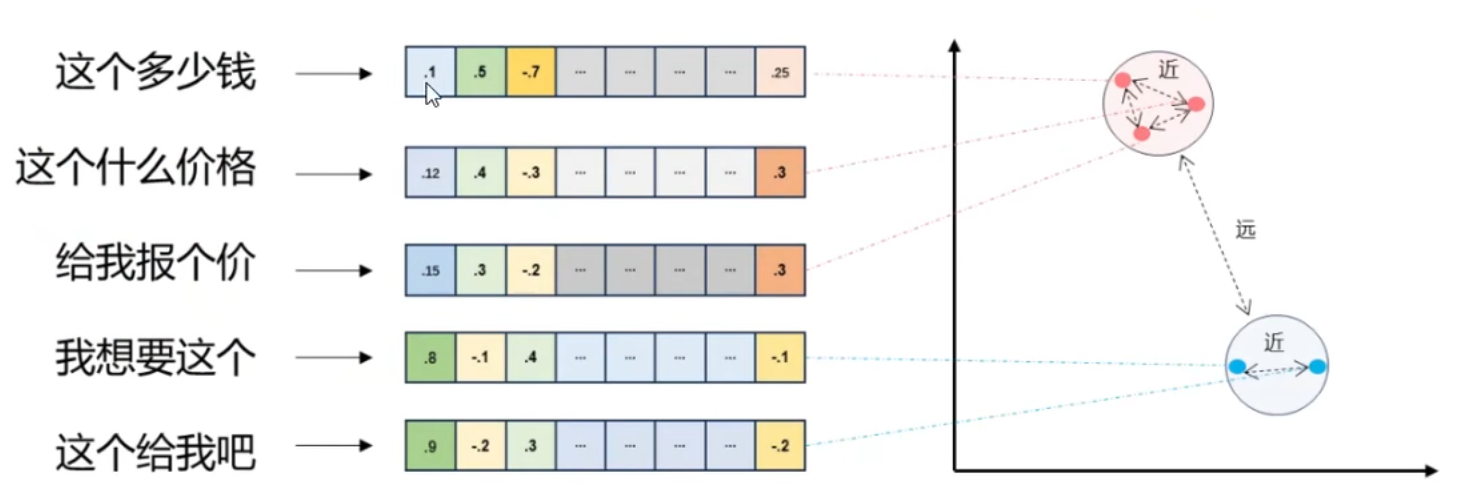
这些块随后被用作 prompt 中的扩展上下文。Query 向量化,匹配向量空间中相近的 chunks。
RAG 具体实现流程:加载文件 => 读取文本 => 文本分割 => 文本向量化 => 在文本向量中匹配出与问题向量最相似的 top k 个 => 匹配出的文本作为上下文和问题一起添加到 prompt 中 => 提交给 LLM 生成回答

 浙公网安备 33010602011771号
浙公网安备 33010602011771号