Agent概念、组成、决策
Agents是什么
1.Agents概念
大语言模型可以接受输入,可以分析&推理、可以输出文字、代码、媒体。然后其无法像人类一样,拥有规划思考能力、运用各种工具与物理世界互动,以及拥有人类的记忆能力
AI Agents是基于LLM的能够自主理解、自主规划决策、执行复杂任务的智能体
Agents的设计目的是为了处理那些简单的语言模型可能无法直接解决的问题,尤其是当这些任务涉及到多个步骤或者需要外部数据源的情况
- LLM:接受输入、思考、输出
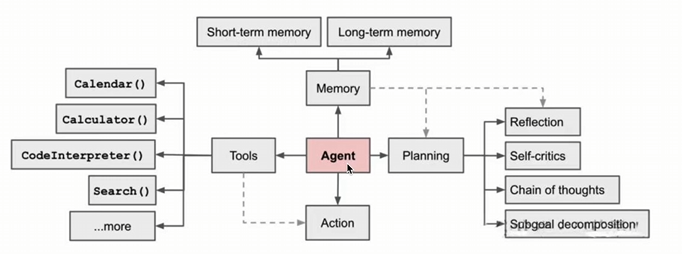
- 人类:LLM+记忆+工具+规划------>Agents
2.Agents流程图
-
规划(Planning):智能体会把大模型任务分解为子任务,并规划执行任务的流程;智能体会对任务执行的过程进行思考和反思,从而决定是继续执行任务,或判断任务完结并且终止运行
- 短期记忆:编程存到容器里面,再次调用接口会清空掉
- 长期记忆:用户服务,会把记忆持久化存到内存中,并给予一个Session Id,当用户再次使用产品时,会从内存中读取之前的记忆,从而知道前面聊了些什么东西
常见框架:Reflection、Self-critics、Chain of thoughts、Sabgoal decomposition
-
记忆(Memory):短期记忆,是指在执行任务的过程中上下文,会在子任务的执行过程产生和暂存,在任务完结后被清空,长期记忆是长时间保留的信息,一般是指外部知识库,通常用向量数据库来存储和检索
-
工具使用(Tools):为智能体配备工具API,比如:计算器、搜索工具、代码执行器、数据库查询工具等,有了这些工具API,智能体就可以是物理世界交互,解决实际问题。
-
执行(Action):根据规划和记忆来实施具体行动,这可能会涉及到与外部世界的互动或通过工具来完成任务
3.Agents决策流程图
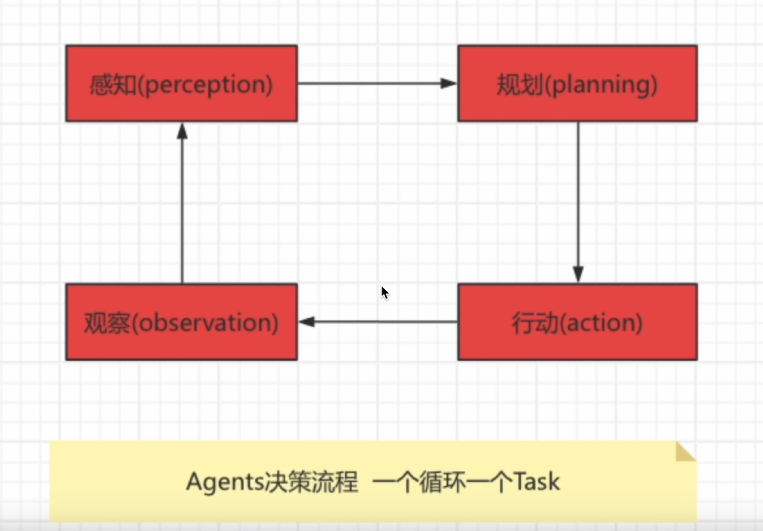
场景
假设我们有一个智能家居系统,它的任务是根据家庭成员的需求调节室内环境,比如灯光和温度
- 感知(Perception)
- 家庭成员通过语音助手说:我感觉有点冷,能把温度调高一些吗?
- 智能家庭系统通过语音识别和情感分析技术“感知“到用户觉得房间温度太低,需要提高温度
- 规划(Planning)
- 系统根据用户的需求,规划出下一步的行动,决定如何调节房间温度
- 系统可能会制定以下计划
- 检查当前的室内温度
- 根据用户的偏好和当前温度决定升高几度合适
- 调整温度设置,并告知用户
- 行动(Action)
- 系统执行计划的行动,首先检测当前温度,例如发现室内是20度
- 根据用户的偏好,将温度调高至23度,并通过语言助手反馈给用户:“我已经将温度调高至23度”
- 观察(Observation)
- 系统观察房间温度的变化,以及用户的反馈。如果用户在几分钟后再次说“现在温度刚刚好”,系统会感知到环境调节成功。
- 如果用户还觉得冷,系统可能会调整计划,进一步调高温度
循环:
- 在每个阶段,智能家居系统都可能根据环境变化和用户反馈调整操作。例如,如果调高温度后用户依然觉得冷,系统会重新规划,进一步调整温度设置。
4.详解流程
4.1规划(Planing)
- 首先会思考怎么完成这个任务
- 然后会甚是手头上拥有的工具,以及如何使用这些工具高效地达成目的
- 再会把任务拆分成子任务(思维导图)
- 在执行任务的时候,我们会对执行过程进行反思和完善,吸取教训以完善未来的步骤
- 执行过程中思考任务何时可以终止
4.2 子任务分解
-
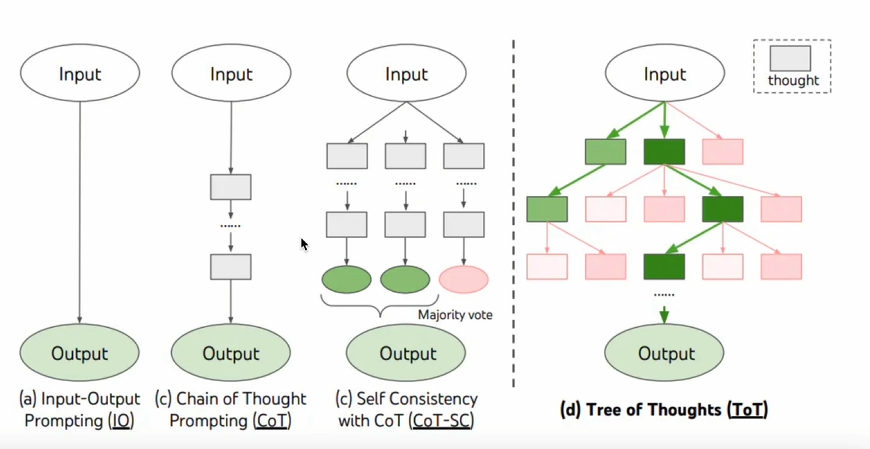
思维链
思维链已经是一种比较标准的提示技术,能显著提示LLM完成复杂任务的效果。当我们对LLM这样要求[think step by step],会发现LLM会把问题分解成多个步骤,一步一步思考和解决,能使得输出的结果更加准确,这是一种线性思维方式
-
思维树
-
“对 CoT 的进一步扩展,在思维链的每一步,推理出多个分支,拓扑展开成一棵思维树。使用启发式方法评估每个推理分支对问题解决的贡献。选择搜索算法,使用广度优先搜索(BFS)或深度优先搜索(DFS等算法来探索思维树,并进行前瞻和回溯
反思与改进
Agent对过去的行动进行自我批评和反思,从错误学习并改进未来的步骤,从而提高最终结果的质量
在实际任务中,试错是不可避免的,而自我反思在这个过程中起着至关重要的作用。它允许 Agent 通过改进过去的行动决策和纠正以前的错误来进行迭代改进。
反思是 Agent 对事情进行更高层次、更抽象思考的结果。反思是周期性生成的,当 Agent 感知到的最新事件的重要性评分之和超过一定阈值时,就会生成反思。这可以类比为我们常用的成语“三思而后行”,做重大决策的时候,我们会反思自己先前的决策
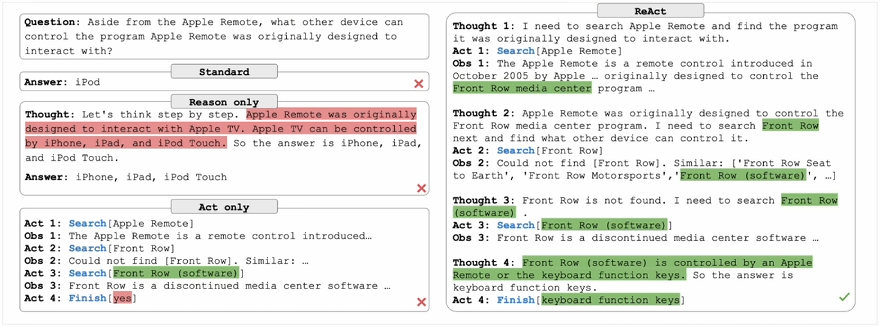
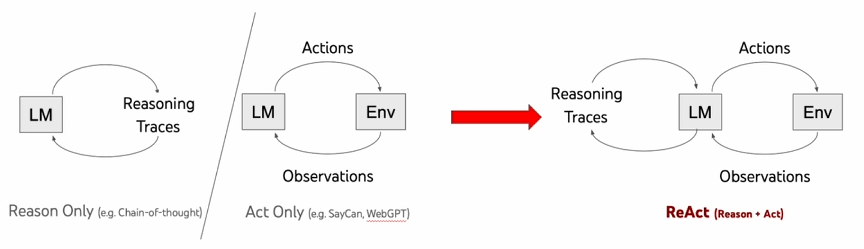
ReAct框架
《ReAct: Synergizing Reasoning and Acting in Language Models》这篇论文提出一种用于增强大型语言模型的方法,它通过结合推理(Reasoning)和行动(Acting)来增强推理和决策的效果
参考: 链接
-
- 标准(Standard): 直接给出错误的答案——iPod,没有提供任何推理过程或外部交互,直接给出答案。 错误的答案:iPod - 仅推理(Reason only): 尝试通过逐步推理来解决问题,但没有与外部环境交互来验证信息。错误地推断出答案是iPhone、iPad iPod Touch。 错误的答案:Phone、iPad、iPod、Touch - 仅行动(Act only): 通过与外部环境(如维基百科)的一系列交互来获取信息,尝试多次搜索(搜索“Apple Remote”,“Front Row”等),但缺乏推理支持,未能综合这些观察结果后得出正确答案。认为需要结果搜索。 错误的决策:结果搜索 - ReAct: 组合推理和行动。首先通过推理确定搜索 Apple Remote(苹果遥控器),并从外部环境中观察结果。随着推理的深入,识别出需要搜索 Front Row(软件)。在几轮交互后,通过进一步推理,准确得出答案“键盘功能键” 正确的答案:键盘功能键
为什么结合推理和行动,就会有效增强 LLM 完成任务的能力?”
-
仅推理(Reasoning Only):LLM 仅仅基于已有的知识进行推理,生成答案回答这个问题。很显然,如果 LLM 本身不具备这些知识,可能会出现幻觉,胡乱回答一遍。
-
仅行动(Acting Only):大模型不加以推理,仅使用工具(比如搜索引擎)搜索这个问题,得出来的将会是海量的资料,不能直接回到这个问题。
-
推理+行动(Reasoning and Acting):LLM 首先会基于已有的知识,并审视拥有的工具。当发现已有的知识不足以回答这个问题,则会调用工具,比如:搜索工具、生成报告等,然后得到新的信息,基于新的信息重复进行推理和行动,直到完成这个任务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号