
性能测试学习内容:平均负载
排查思路
有监控的情况下,首先去看看监控大盘,看看有没有异常报警,如果初期还没有监控的情况我会按照下面步骤去看看系统层面有没有异常
1、我首先会去看看系统的平均负载,使用top或者htop命令查看,平均负载体现的是系统的一个整体情况,他应该是cpu、内存、磁盘性能的一个综合,一般是平均负载的值大于机器cpu的核数,这时候说明机器资源已经紧张了
2、平均负载高了以后,接下来就要看看具体是什么资源导致,我首先会在top中看cpu每个核的使用情况,如果占比很高,那瓶颈应该是cpu,接下来就要看看是什么进程导致的
3、如果cpu没有问题,那接下来我会去看内存,首先是用free去查看内存的是用情况,但不直接看他剩余了多少,还要结合看看cache和buffer,然后再看看具体是什么进程占用了过高的内存,我也是是用top去排序
4、内存没有问题的话就要去看磁盘了,磁盘我用iostat去查看,我遇到的磁盘问题比较少
5、还有就是带宽问题,一般会用iftop去查看流量情况,看看流量是否超过的机器给定的带宽
6、涉及到具体应用的话,就要根据具体应用的设定参数来查看,比如连接数是否查过设定值等
7、如果系统层各个指标查下来都没有发现异常,那么就要考虑外部系统了,比如数据库、缓存、存储等
每次发现系统变慢时,可以先输入top、uptime来看一下平均负载
16:04:29 系统当前时间
up 120 days, 21:45, 系统运行时间
4 users, 当前登录的用户数
load average: 0.24, 0.13, 0.16,1分钟、5分钟、15分钟的平均负载
什么是平均负载:
可以打印man uptime看官方解释
平均负载是指单位时间内,系统处于可运行状态或不可中断状态的平均进程数,也就是平均活跃进程数,它和CPU的使用率没有直接关系。
可运行状态:是指正在使用CPU或者是正在等待CPU的进程(处于运行态、就绪态的进程),ps -aux里面的状态展示为R
不可中断状态:处于内核态关键流程中的进程,并且这些流程是不可打断的,例如:等待硬件设备的I\O响应,ps里面的状态展示为D
比如说:一个进程在往磁盘写数据,为了保证数据的一致性,在得到磁盘的回复前,该进程不可以被其他进程或中断打断。如果被打断则会出现,进程数据与磁盘数据不一致。
所以不可中断状态实际上是系统对进程和硬件设备的保护机制
简单理解这个问题就是:平均负载就是平均活跃进程数,平均活跃进程数就是活跃进程数的指数衰减的平均值。可以理解为活跃进程数的平均值
例如:平均负载为2
服务器上有2个CPU,代表所有CPU全部被占用完
服务器上有4个CPU,代表CPU有50%的空闲
服务器上有1个CPU,代表一半的进程竞争不到CPU
查看服务器上有多少个CPU
grep 'model name' /proc/cpuinfo | wc -l
平均负载包括:正在使用的CPU、等待的CPU和等待I\O的进程。
CPU使用率:是单位时间内CPU繁忙情况的统计
CPU密集型:使用大量的CPU是导致平均负载升高,与平均负载成正比
I\O密集型:等待I\O进程会使平均负载升高,但是CPU使用率不一定很高
大量等待CPU的进程调度也会导致平均负载升高,此时的CPU使用率也会比较高
场景一:I\O密集型进程
$ watch -d uptime..., load average: 1.06, 0.58, 0.37
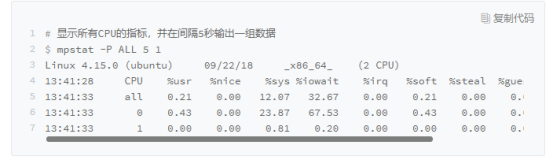
通过mpstat 可以看出其中一个CPU的使用率达到了23.87%,而iowait高达67.53,由此得出平均负载的升高是由io的升高导致
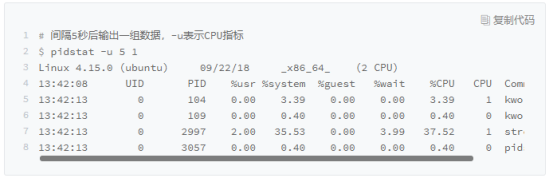
使用pidstat -u 5 1可以具体的看出,是由2997这个进程导致
场景二:大量进程的场景
系统只有2个CPU

通过pidstat查看信息
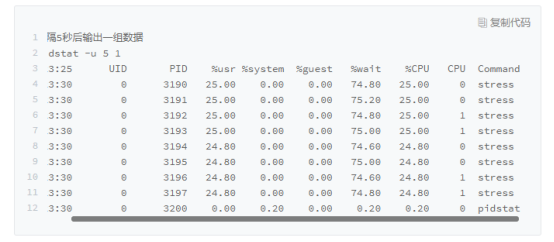
可以看出8个进程再抢2个CPU,平均每个进程的wait时间高达74%,这些超出CPU的计算能力,也是导致高负载的原因
总结一下:平均负载是发现系统整体性能最最速的方法,反应了整体的负载表现。但是无法具体的定位问题。所以再理解平均负载的时候,需要注意:
平均负载高可能是CPU密集型进程导致
平均负载高不一定是CPU使用率高导致,还有可能是I\O更繁忙了
当发现负载搞定时候,可以用,mpstat,pidstat等工具来分析负载的来源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号