SqlServer数据库《基本》
- 数据库简单说就是行、列组成的二维表
- 把列称为字段、每一行数据成为记录,能标识每一行的唯一字段称为主键
- 查询数据表时,索引可以提高查询速度,但是索引同时会降低新增和更新数据时的速度,应为还要更新索引。
- 创建部门表DepMent
create table Depment(id nvarchar(20),depname varchar(20) not null,primary key(id))
-
- 创建员工表Person,并与Depment表建立外键关系
create table Person(ID int identity(1,1),Name varchar(20),Age int,DepID nvarchar(20),primary key(id),foreign key(DepID) references DepMent(id))
-
- 在部门表和员工表新增记录
insert into Depment(id,depname) values('001','技术部') insert into Person(Name,Age,DepID) values('王某某',18,'001')
-
- 由于Person表ID为自增长所以新增时不用主动写入,而且需注意外键关联字段,如果部门表‘002’不存在,则不能关联‘002’值
- 同时关联表删除时,需要先删除外键关联表,也就是Person表,在删除Depment表,因为Depment表被依赖,所以不能直接删除
- 创建表时设置字段默认值
-
create table Student(Name varchar(20),EnterSchoolData datetime default '2019-03-29')
default定义默认值
- 定义联合主键
-
create table ComputerInfo ( ID varchar(20),Name varchar(20),TypeInfo varchar(20),primary key(ID,Name) --直接写联合主键字段 )
联合主键数据执行效率会降低,不利于主外键关联关系的建立,一般不建议用。
- 新增字段
-
alter table computerinfo Add DTime datetime
-
- 删除已有字段
alter table ComputerInfo drop column typeinfo
-
- 完全删除数据表
-
drop table Student
-
如果建立了外键关系,比如A表指向B表,建立外键关系,直接删除B表是错误的,需要先删除A表,再删除B表
- 插入语句
-
insert into ComputerInfo(ID,Name,DTime) values('1','Jon','2019-03-26') insert into ComputerInfo values('2','Tomm','2019-03-27')
--批量插入数据
insert into 表明(字段,,,,)
select 1,2,3,4,
union all
select 1,2,3,4
...... -
两种写法都可以,第一种可读性更高。
- 修改语句
-
update ComputerInfo set Name = 'Slion'
-
删除语句
-
delete from ComputerInfo
-
备注:所有新增、修改、删除,如果有外键关系,必须先解除依赖,或者外键必须存在情况下才能进行,否则就报错。
-
查询检索数据表
-
设置别名 select Name as 姓名 from 表名
-
对于不需要的查询的字段,尽量减少用*全部查询
-
where条件查询,and、or
- 聚合函数:
-
-
max(字段) 求最大值 min(字段) 求最小值 count(字段)或count(*) 求有多少条数据 avg(字段) 求平均值 sum(字段) 求总和
-
- 注意:count(字段)如果字段为空,则不统计;count(*)仍然要统计为空的字段
-
-
- 排序
-
select * from ComputerInfo order by Name asc,DTime desc --先按Name升序,再按DTime降序
--升序asc默认可以不写,不写默认为升序 -
数据过滤
-
单字符匹配:用下划线__代表前两个字符为任意字符,第三个字符为n的Name
-
select * from ComputerInfo where Name like '__n'
- 多字符匹配:查询任意长度,最后一个字符为n的Name
-
select * from ComputerInfo where Name like '%n'
-
结合使用:查询任意长度,但倒数第二个字符为m,最后一个为任意字符的Name
-
select * from ComputerInfo where Name like '%m_'
-
- 集合匹配,注意,集合匹配原则是全表扫描,效率会降低
select * from dbo.Depment where depname like '[ab]%' --[]里面或关系,标识第一个字符是a或b时长度不限的匹配条件 select * from dbo.Depment where depname like '[^ab]%' --[]里面或关系,标识第一个字符不是是a或不是b时长度不限的匹配条件
-
- 空值问题
-
--查询Name为null的 select * from Person where Name is null --查询Name不为null的 select * from Person where Name is not null
非运算:可以用Not,也可以用! <>
-
--非运算查询:查年龄不等于17的所有结果 select * from Person where Not(Age = 17)
in关键字查询
-
--in 或关系,只要匹配的就都查出来 select * from Person where Age in(17,18)
区间检测:优先使用Between And 因为比直接写等号效率要高
-
--查询年龄>= 17 and <= 20的数据,包含两边值本身 select * from Person where Age between 17 and 20
分组Group By
- 分组语句必须在where条件后使用,分组语句可以有多个,但是要和查询语句查询字段进行结合,对于分组语句中没有的,还必须和聚合函数结合使用
-
select DepID as '部门', MAX(age) as '年龄' from Person where not(Age=16) group by DepID,Age order by Age desc
先按DepID分组,在按年龄分组,然后按年龄倒序排序,得到不同部门的年龄最大值
- Having语句使用
-
select DepID as '部门', MAX(age) as '年龄' from Person where not(Age=16) group by DepID,Age having Age > 18 order by Age desc
在group by子句后执行条件过滤行为,having中用到的关键字必须是grouy by中已经指定的分组关键字,否则报错
- 利用子查询进行分页
-
select * from ( select ROW_NUMBER() over(order by id) as num ,* from Person ) as rowTab where rowTab.num between 2 and 3
去重关键字 distinct :此关键字去重时要针对字段,否则的话对整行去重有一个字段不同就认为不同,然后就不去重了
- 联合字符union:将多个查询集合联合到一起,成为一个集合,union会去重查询,将两个表中完全一样的只保留一个记录
- 联合查询,查询字段必须数量一样
- 列与列对应类型必须一样
-
select id,Name from person union select id,depname from Depmentunion all 完全保留两个查询结果集
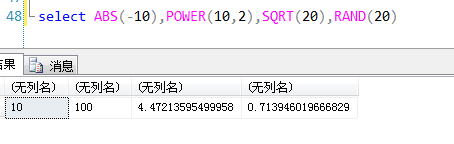
- 数值函数:
- ABS :求绝对值
- Power :求幂次方
- SQRT :求平方根
- RAND :随机生成一个数
![]()
-
CEILING :舍入到临近的最大整数
- FLOOR:舍入到临近的最小整数
- ROUND(m,n):m表示数组,n表示精度
-
select CEILING(2.33) --结果:3 select FLOOR(-3.1) --结果:-4 select ROUND(2.3,1),ROUND(-10.6,0),ROUND(2.6,0),ROUND(37.2,-1) --2.3精度为1,保留一个小数 ---10.6精度为0,保留到整数位 --37.2精度为-1,表示要从十位位置开始四舍五入,结果为40SIN(数值参数):求正弦值
- COS(参数):求余弦值
- ASIN(参数):求反正弦值
- ACOS(参数):求反余弦值
- TAN(参数):求正切值
- COT(参数):求余切值
- select PI()*3 as p :PI()求圆周率PI
- SIGN:求结果符号:select SIGN(10-11):如果结果大于0返回1,小于0返回-1,等于0返回0,可用于对计算结果的判定
- 字符串函数
-
select LEN('abcdefg') --求字符串长度 select LOWER('ABC'),upper('abc') -- 大小写转换 select LTRIM(' ab'),RTRIM('ab ') --截取字符串左边空格,右边空格 select SUBSTRING('abcd123456',2,3) --从第二个位置开始截取长度为3的字符,返回新字符串,注意,索隐从1开始select CHARINDEX('z','abcdefg') --查询参数2是否包括参数1,如果有,返回所在位置,位置从1开始,如果没有返回0 select LEFT('abcdefg',2),RIGHT('abcdefg',3) --从左侧截取2个字符,--从右侧截取3个字符 select REPLACE('hello world','rl','ok') --用参数3替换参数1所包含的参数2的值,得到新值 select ASCII('a') --得到对应ASC||码 select char(98) --得到一个数值对应的ASC||符 select DIFFERENCE(name,SOUNDEX('to')) from Person --soundex()查询相似值,比如姓名发音相似的
-
- 日期时间类型
-
select GETDATE() --获取当前时间:年月日时分秒 select CONVERT(varchar(10),GETDATE(),102) --单独获取年月日 select CONVERT(varchar(10),GETDATE(),108) --单独获取时分秒
select DATEADD(day,-8,getdate()) --当前日期减去8天的日期 select DATEDIFF(day,'2019-03-16',getdate()) --计算两个日期差额,后面日期减去前面日期 select DATENAME(DD,getdate()) --计算日期是星期几,其中第一个参数是显示格式问题,可以留意 select DATENAME(year,getdate()) -- 计算日期的任一部分是多少,第一个参数灵活配置 select DATEPART(dayofyear,getdate()) select DATEPART(DD,getdate()) --也是可以取日期某一部分
-
- 类型转换
select cast('123' as int) --将前面字符转换成数值
select CONVERT(int ,'123') --将字符转换为数值
7.空值处理:
select ID,ISNULL(name,'a') as n,Coalesce(Name,DepID,'b') as nn from Person --判断name是否为空,如果为空则用a替换显示,不为空则返回name,isnull和coalesce道理一样都是控制检查 select nullif(name,depid) from Person --判断两个参数是否等价,相等返回第一个参数类型,否则返回第一个参数值
8.CASE逻辑处理
--case逻辑处理
--用法一
select name,
(case age
when 17 then '十七岁'
when 18 then '十八岁'
else '大于十八岁'
end) as agestr
from Person
--用法二
select name,
(case
when age > 20 then '二十以上'
when Age > 18 then '十八以上'
else '小于十八'
end
)
from Person
请大家指点不足,提出建议,共同分享学习.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号