

python3笔记二十三:正则表达式之其他函数
一:学习内容
- re.split函数
- re.finditer函数
- re.sub函数
- group()分组
- re.compile函数
二:字符串切割---re.split函数
需要导入包:import re
1.格式:re.split(pattern,string,flags=0)
2.功能:字符串切割
3.参数说明:
pattern:匹配的正则表达式
string:要匹配的字符串
flags:标识位,用于控制正则表达式的匹配方式
4.举例:
str1 = "test is a good girl"
print(str1.split(" "))
print(re.split(r" +",str1)) #可以看到一次性将所有空格都分隔掉了

三:re.finditer函数
需要导入包:import re
1.格式:re.finditer(pattern,string,flags=0)
2.功能:与findall类似,扫描整个字符串,返回的是一个迭代器
3.参数说明:
pattern:匹配的正则表达式
string:要匹配的字符串
flags:标识位,用于控制正则表达式的匹配方式
4.举例:
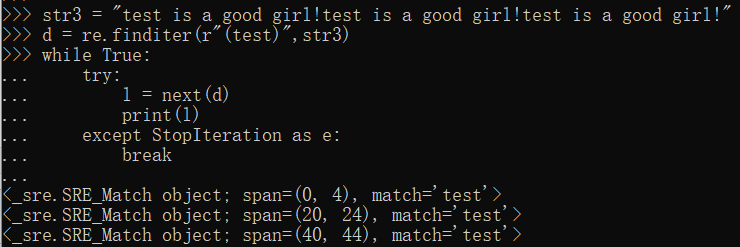
str3 = "test is a good girl!test is a good girl!test is a good girl!"
d = re.finditer(r"(test)",str3)
while True:
try:
l = next(d)
print(l)
except StopIteration as e:
break
四:字符串的替换和修改---re.sub函数和re.subn函数
需要导入包:import re
1.格式:sub(pattern, repl, string, count=0, flags=0) 和 subn(pattern, repl, string, count=0, flags=0)
2.功能:在目标字符串中以正则表达式的规则匹配字符串,可以指定替换的次数,如果不指定,替换所有的匹配字符串
3.参数说明:
pattern:正则表达式(规则)
repl:指定的用来替换的字符串
string:目标字符串
count:最多替换次数
4.sub和subn区别:sub()返回一个被替换的字符串,subn()返回一个元组(第一个元素是被替换的字符串,第二个元素表示被替换的次数)
5.举例:
str5 = "test is a good good good girl"
print(re.sub("(good)","nice",str5))
print(re.sub("(good)","nice",str5,count=2))
print(type(re.sub("(good)","nice",str5)))

print(re.subn("(good)","nice",str5))
print(re.subn("(good)","nice",str5,count=2))
print(type(re.subn("(good)","nice",str5)))

五:分组-group()
需要导入包:import re
1.概念:具有提取子串的功能,用()表示的就是分组
2.举例:
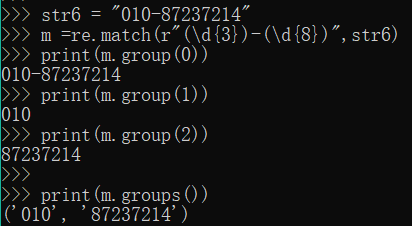
str6 = "010-87237214"
m =re.match(r"(\d{3})-(\d{8})",str6)
#使用序号获取对应组的信息,group(0)一直代表的原始字符串
print(m.group(0))
print(m.group(1))
print(m.group(2))
#查看匹配的各组的情况
print(m.groups())
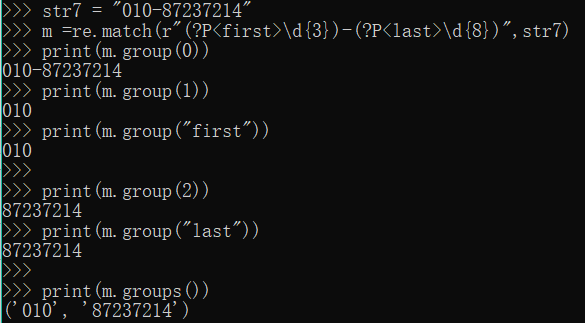
3.?P<组名> 给组起名字
str7 = "010-87237214"
m =re.match(r"(?P<first>\d{3})-(?P<last>\d{8})",str7)
print(m.group(0))
print(m.group(1))
print(m.group("first"))
print(m.group(2))
print(m.group("last"))
#查看匹配的各组的情况
print(m.groups())
六:编译-compile()
需要导入包:import re
1.概念:当我们使用正则表达式时,re模块会干两件事:1、编译正则表达式,如果正则表达式本身不合法,会报错;2、用编译后的正则表达式去匹配
2.格式:re.compile(pattern,flags=0)
3.参数说明:
pattern:匹配的正则表达式
flags:标识位,用于控制正则表达式的匹配方式,它的值有:
re.I 忽略大小写
re.L 做本地化识别
re.M 多行匹配,影响^和$
re.S 使.匹配包括换行符在内的所有字符
re.U 根据Unicode字符集解析字符,影响\w \W \b \B
re.X 使我们以更灵活的格式理解正则表达式
4.举例:
pat = r"1[3456789]\d{9}"
re_tele = re.compile(pat)
str = "手机号码19966662112,fldsafdls18877221999lfalalsfdk13988218921dfsa"
re_tele.findall(str)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号