

python3笔记二十二:正则表达式之函数
一:学习内容
- re.match函数
- re.search函数
- re.findall函数
二:re.match函数
需要导入包:import re
1.格式:match(pattern,string,flags = 0)
2.参数
pattern:匹配的正则表达式
string:要匹配的字符串
flags:标识位,用于控制正则表达式的匹配方式,它的值有:
re.I 忽略大小写
re.L 做本地化识别
re.M 多行匹配,影响^和$
re.S 使.匹配包括换行符在内的所有字符
re.U 根据Unicode字符集解析字符,影响\w \W \b \B
re.X 使我们以更灵活的格式理解正则表达式
3.功能:尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,返回None
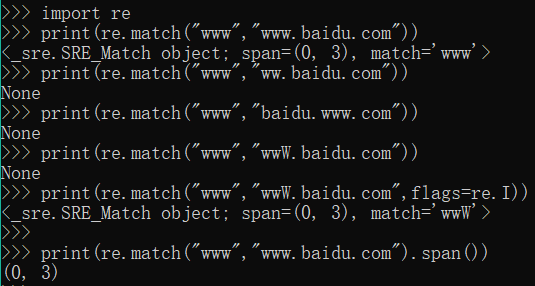
4.举例:
#扫描整个字符串,返回从起始位置成功的匹配
print(re.match("www","www.baidu.com")) #匹配正确
print(re.match("www","ww.baidu.com")) #匹配不到返回None
print(re.match("www","baidu.www.com")) #匹配不到返回None,从起始位置就要能匹配上
print(re.match("www","wwW.baidu.com")) #匹配不到,大写的W
print(re.match("www","wwW.baidu.com",flags=re.I)) #匹配正确,因为忽略大小写了
print(re.match("www","www.baidu.com").span()) #匹配正确,返回匹配的位置
三:re.search函数
需要导入包:import re
1.格式:search(pattern,string,flags = 0)
2.参数:
pattern:匹配的正则表达式
string:要匹配的字符串
flags:标识位,用于控制正则表达式的匹配方式,它的值有:
re.I 忽略大小写
re.L 做本地化识别
re.M 多行匹配,影响^和$
re.S 使.匹配包括换行符在内的所有字符
re.U 根据Unicode字符集解析字符,影响\w \W \b \B
re.X 使我们以更灵活的格式理解正则表达式
3.功能:扫描整个字符串,并返回第一个成功的匹配
4.举例:
print(re.search("tester","she is tester!tester is a good girl!"))

四:re.findall函数
需要导入包:import re
1.格式:findall(pattern,string,flags = 0)
2.参数:
pattern:匹配的正则表达式
string:要匹配的字符串
flags:标识位,用于控制正则表达式的匹配方式,它的值有:
re.I 忽略大小写
re.L 做本地化识别
re.M 多行匹配,影响^和$
re.S 使.匹配包括换行符在内的所有字符
re.U 根据Unicode字符集解析字符,影响\w \W \b \B
re.X 使我们以更灵活的格式理解正则表达式
3.功能:扫描整个字符串,并返回所有匹配成功的数据,返回一个列表
4.举例:
print(re.findall("tester","she is tester!Tester is a good girl!",flags=re.I))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号