
Python爬取疫情历史数据
| 每日日报24 | 3月24日 |
| 所花时间(包括上课) | 7小时 |
| 代码量(行) | 139 |
| 博客量(篇) | 2 |
| 了解到的知识点 | Python爬取疫情历史数据 |
效果图如下:
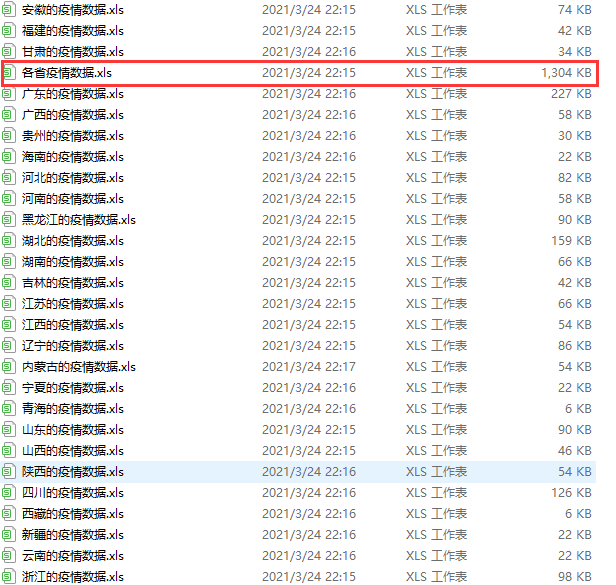
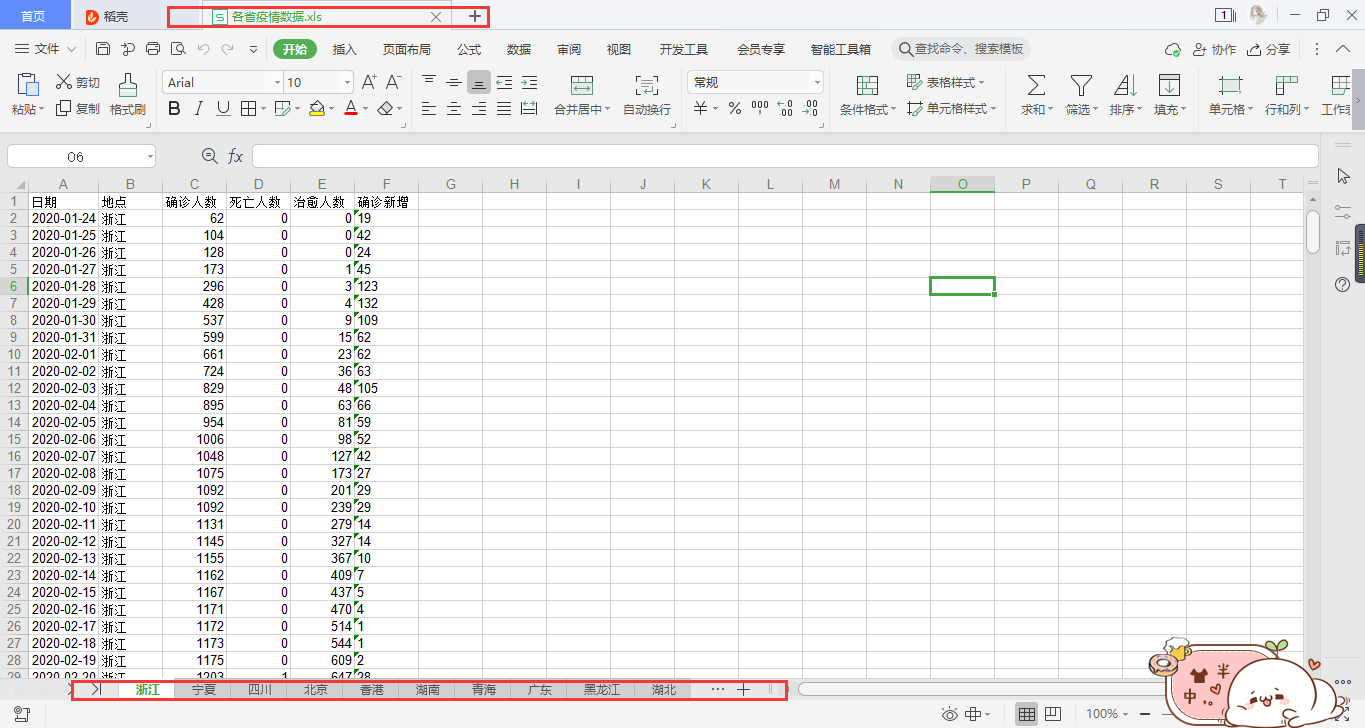
其中“各省疫情数据.xls”文件中为各个省的疫情历史数据:
其余文件为各个省所对应的市的疫情历史数据,以“安徽”为例子: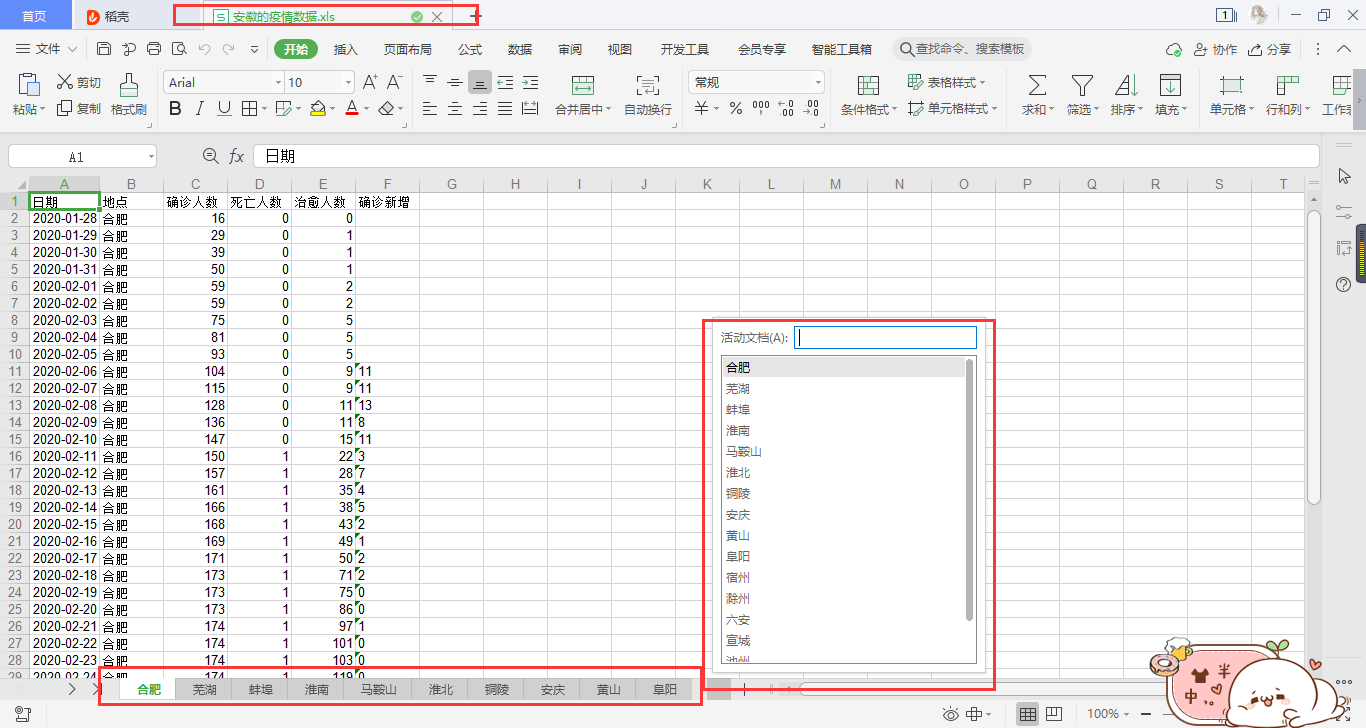
代码如下:
1 import sys 2 import datetime 3 import requests 4 import xlwt 5 6 def getURLContent(url): 7 headers = { 8 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36' 9 } 10 response = requests.post(url, headers=headers) 11 return response.status_code, response 12 13 def getCountry(workbook,province, city): 14 worksheet=workbook.add_sheet(city) 15 print("开始爬取 %s 的 %s的疫情数据... ... " % (province,city)) 16 url = 'https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=%s&city=%s' % (province,city) 17 status_code, data = getURLContent(url) 18 if status_code != 200: 19 print("%s数据爬取失败,状态码%d" % (province, status_code)) 20 sys.exit() 21 data = data.json()["data"] 22 if data == None: 23 print("%s数据爬取数据为空" % province) 24 25 worksheet.col(0).width = 128 * 20 # 设置excel中第A列的宽度(方便日期数据展示) 26 27 current_row_index = 0 # 记录当前所写入数据的行号 28 29 # 将列标题写入excel 30 for i, str_col in enumerate(['日期', '地点', '确诊人数', '死亡人数', '治愈人数', '确诊新增']): 31 worksheet.write(current_row_index, i, str_col) # 参数对应 行, 列, 值 32 current_row_index += 1 33 34 # 往excel中写入日期格式 35 style = xlwt.XFStyle() 36 style.num_format_str = 'YYYY-MM-DD' 37 38 # 将抓取到的疫情数据写入excel 39 for data_i in data: 40 worksheet.write(current_row_index, 0, datetime.datetime.strptime('2020.' + data_i['date'], "%Y.%m.%d"),style) 41 worksheet.write(current_row_index, 1, data_i['city']) 42 worksheet.write(current_row_index, 2, data_i['confirm']) 43 worksheet.write(current_row_index, 3, data_i['dead']) 44 worksheet.write(current_row_index, 4, data_i['heal']) 45 worksheet.write(current_row_index, 5, data_i['confirm_add']) 46 current_row_index += 1 47 workbook.save('E:\人数采集3.0\%s的疫情数据.xls' % province) 48 49 def getProvince(workbook,province): 50 worksheet = workbook.add_sheet(province) 51 print("开始爬取 %s 疫情数据... ... " % province) 52 url = 'https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=%s' % province 53 status_code, data = getURLContent(url) 54 55 if status_code != 200: 56 print("%s数据爬取失败,状态码%d" % (province, status_code)) 57 sys.exit() 58 data = data.json()["data"] 59 if data == None: 60 print("%s数据爬取数据为空" % province) 61 62 worksheet.col(0).width = 128 * 20 # 设置excel中第A列的宽度(方便日期数据展示) 63 64 current_row_index = 0 # 记录当前所写入数据的行号 65 66 # 将列标题写入excel 67 for i, str_col in enumerate(['日期', '地点', '确诊人数', '死亡人数', '治愈人数', '确诊新增']): 68 worksheet.write(current_row_index, i, str_col) # 参数对应 行, 列, 值 69 current_row_index += 1 70 71 # 往excel中写入日期格式 72 style = xlwt.XFStyle() 73 style.num_format_str = 'YYYY-MM-DD' 74 75 # 将抓取到的疫情数据写入excel 76 for data_i in data: 77 worksheet.write(current_row_index, 0, datetime.datetime.strptime('2020.' + data_i['date'], "%Y.%m.%d"), 78 style) 79 worksheet.write(current_row_index, 1, data_i['province']) 80 worksheet.write(current_row_index, 2, data_i['confirm']) 81 worksheet.write(current_row_index, 3, data_i['dead']) 82 worksheet.write(current_row_index, 4, data_i['heal']) 83 worksheet.write(current_row_index, 5, data_i['confirm_add']) 84 current_row_index += 1 85 workbook.save('E:\人数采集3.0\各省疫情数据.xls') 86 87 if __name__ == "__main__": 88 89 # 创建一个workbook 设置编码 90 workbook = xlwt.Workbook(encoding='utf-8') 91 country = {"北京", "天津", "上海", "重庆", "河北", "山西", "辽宁", "吉林", "黑龙江", "江苏", "浙江", "安徽", "福建", "江西", "山东", "河南", "湖北", "湖南", "广东", "海南", "四川", "贵州", "云南", "陕西", "甘肃", "青海", "台湾", "新疆", "宁夏", "西藏", "广西", "内蒙古", "香港", "澳门"} 92 for count in country: 93 getProvince(workbook,count) 94 print(count) 95 96 # 添加要爬取疫情数据的国家 97 d = { 98 '河北': ["石家庄", "唐山", "秦皇岛", "邯郸", "邢台", "保定", "张家口", "承德", "沧州", "廊坊", "衡水"], 99 '山西': ["太原", "大同", "阳泉", "长治", "晋城", "朔州", "忻州", "吕梁", "晋中", "临汾", "运城"], 100 '辽宁': ["沈阳", "大连", "鞍山", "抚顺", "本溪", "丹东", "锦州", "营口", "阜新", "辽阳", "盘锦", "铁岭", "葫芦岛"], 101 '吉林': ["长春", "吉林", "四平", "辽源", "通化", "白城", "松原"], 102 '黑龙江': ["哈尔滨", "齐齐哈尔", "牡丹江", "佳木斯", "大庆", "伊春", "鸡西", "鹤岗", "双鸭山", "七台河", "绥化", "黑河"], 103 '江苏': ["南京", "无锡", "徐州", "常州", "苏州", "南通", "连云港", "淮安", "盐城", "扬州", "镇江", "泰州", "宿迁"], 104 '浙江': ["杭州", "宁波", "温州", "绍兴", "湖州", "嘉兴", "金华", "衢州", "台州", "丽水", "舟山"], 105 '安徽': ["合肥", "芜湖", "蚌埠", "淮南", "马鞍山", "淮北", "铜陵", "安庆", "黄山", "阜阳", "宿州", "滁州", "六安", "宣城", "池州", "亳州"], 106 '福建': ["福州", "莆田", "泉州", "厦门", "漳州", "龙岩", "三明", "南平", "宁德"], 107 '江西': ["南昌", "赣州", "宜春", "吉安", "上饶", "抚州", "九江", "景德镇", "萍乡", "新余", "鹰潭"], 108 '山东': ["济南", "青岛", "淄博", "枣庄", "烟台", "潍坊", "济宁", "泰安", "威海", "日照", "滨州", "德州", "聊城", "临沂", "菏泽"], 109 '河南': ["郑州", "开封", "洛阳", "平顶山", "安阳", "鹤壁", "新乡", "焦作", "濮阳", "许昌", "漯河", "三门峡", "商丘", "周口", "驻马店", "南阳", "信阳"], 110 '湖北': ["武汉", "黄石", "十堰", "荆州", "宜昌", "襄阳", "鄂州", "荆门", "黄冈", "孝感", "咸宁", "随州"], 111 '湖南': ["长沙", "株洲", "湘潭", "衡阳", "邵阳", "岳阳", "张家界", "益阳", "常德", "娄底", "郴州", "永州", "怀化"], 112 '广东': ["广州", "深圳", "珠海", "汕头", "佛山", "韶关", "湛江", "肇庆", "江门", "茂名", "惠州", "梅州", "汕尾", "河源", "阳江", "清远", "东莞","中山", "潮州", "揭阳"], 113 '海南': ["海口", "三亚", "儋州"], 114 '四川': ["成都", "绵阳", "自贡", "攀枝花", "泸州", "德阳", "广元", "遂宁", "内江", "乐山", "资阳", "宜宾", "南充", "达州", "雅安", "广安", "巴中","眉山"], 115 '贵州': ["贵阳", "六盘水", "遵义", "铜仁", "毕节", "安顺"], 116 '云南': ["昆明", "曲靖", "玉溪", "普洱", "临沧"], 117 '陕西': ["西安", "铜川", "宝鸡", "咸阳", "渭南", "汉中", "安康", "商洛", "延安", "榆林"], 118 '甘肃': ["兰州", "金昌", "白银", "天水", "张掖", "定西", "陇南", "平凉", "庆阳"], 119 '青海': ["西宁"], 120 '新疆': ["乌鲁木齐", "吐鲁番"], 121 '宁夏': ["银川", "石嘴山", "吴忠", "固原", "中卫"], 122 '西藏': ["拉萨"], 123 '广西': ["南宁", "柳州", "桂林", "梧州", "北海", "来宾", "贺州", "玉林", "百色", "河池", "钦州", "防城港", "贵港"], 124 '内蒙古': ["呼和浩特", "包头", "乌海", "赤峰", "呼伦贝尔", "通辽", "乌兰察布", "鄂尔多斯", "巴彦淖尔"], 125 } 126 127 def itertransfer(d): 128 for k, values in d.items(): 129 for v in values: 130 yield (k, v) 131 132 for name in d.keys(): 133 print(name.title()) 134 # 创建一个workbook 设置编码 135 workbookk = xlwt.Workbook(encoding='utf-8') 136 for k,v in itertransfer(d): 137 if k==name.title(): 138 getCountry(workbookk, k, v) 139 print(k,v)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号