"Out of Sight, Out of Mind: Better Automatic Vulnerability Repair by Broadening Input Ranges and Sources" 论文笔记
介绍
(1) 发表
2024-04 ICSE'24
(2) 挑战
-
输入长度的限制:现有方法基本都是基于 Transformer 结构,不可避免的限制了输入代码的长度,然后现实世界中的 buggy 代码往往会超过其 token 限制
-
代码结构的忽略:自然语言具有松散结构的性质,使单词能够以不同的顺序排列,同时保持语法的正确性。相比之下,编程语言表现出更高级别的结构。忽略代码结构可以降低现有方法中有效解决漏洞的可能性
-
专业知识的利用:软件漏洞不是孤立存在的,CWE 系统提供了常见软件弱点类型的全面目录。当前方法对 CWE 知识利用仍然不够全面
(3) 贡献
-
提出了 VulMaster,第一个将 FiD 框架运用到软件工程领域中,给出了如何利用它减轻长度限制,并与其他辅助信息集成的方案
-
发现了更多样化和有价值的信息,例如 CWES 的 buggy 代码结构和专家知识
-
进一步识别并解决了先前工作中使用的数据集中隐藏的标签泄露问题
方法
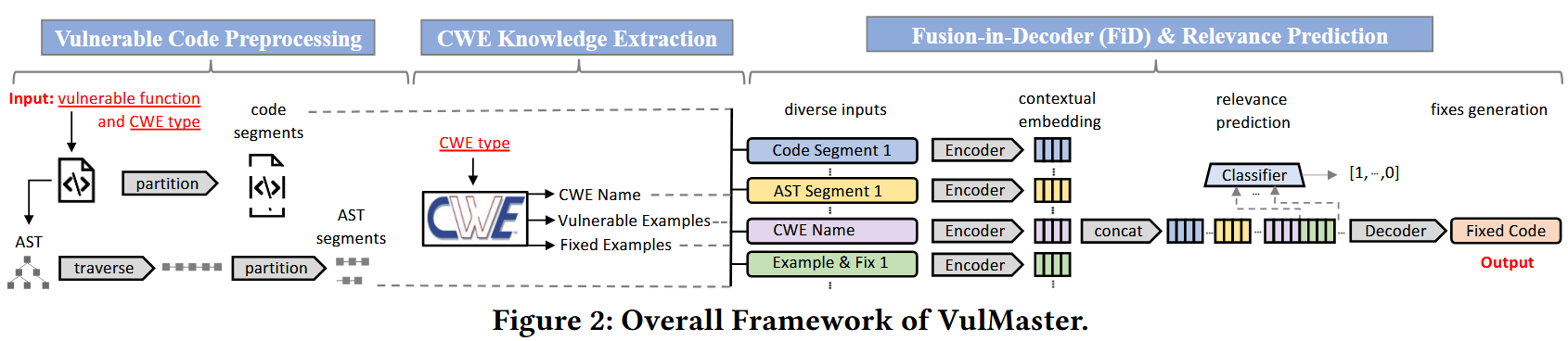
(1) 数据预处理
使用 CodeT5 的默认 Tokenizer,然后对 token 序列进行分区,确保每个分区不超过 512 token
(2) CWE 知识库提取
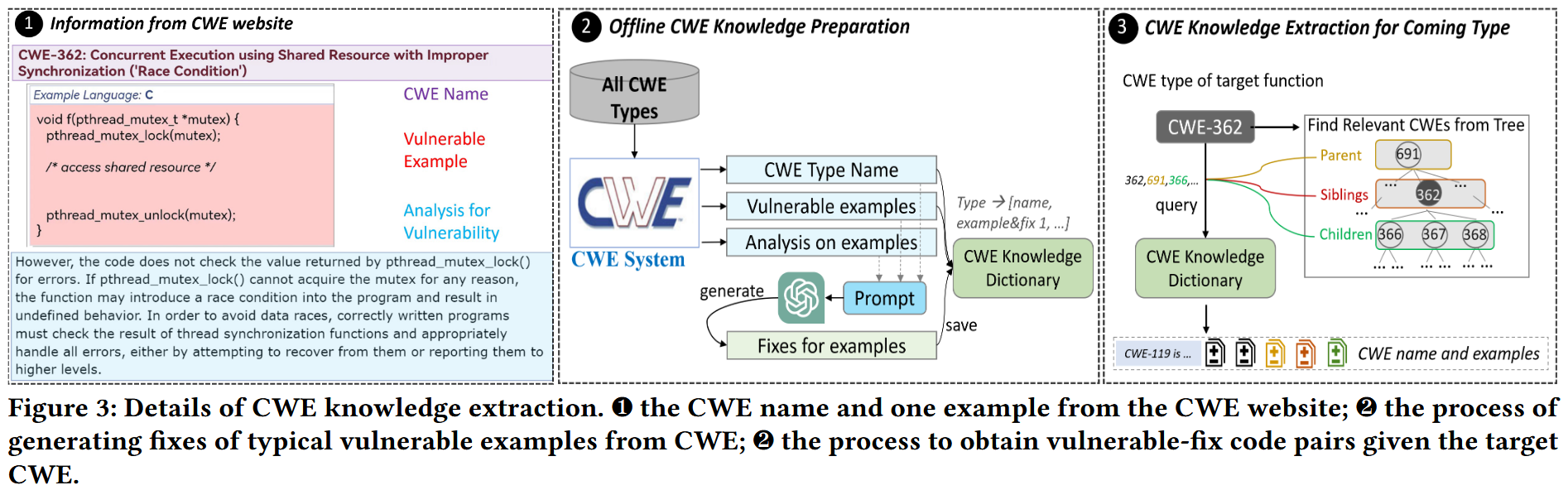
以离线方式构建 CWE 知识字典,key 是 CWE 类型,value 是相应的 CWE 知识列表(包括名称、示例和专家撰写的示例分析),然后 prompt 给 chatgpt 构建修复代码,最后组成相应的知识库
(3) FiD 和相关性预测
-
预训练模型的 AST 理解适应:基准模型 CodeT5 对 AST 节点序列结构不熟悉,先前的研究表明预训练期间缺乏的软件信息可能导致次优的预训练模型。遵循这个想法,我们引入了一个附加的预训练步骤,这里选择使用了一个错误代码修复语料库来增强基准模型对 AST 结构的理解
-
上下文嵌入:将 ① 完整的脆弱函数 ② AST节点序列 ③ CWE类型名称 ④ 示例和 CWE类型和相关 CWE 类型的示例和相应的修复串成一个序列,送到 adapted-CodeT5 以生成上下文嵌入
-
关联预测:相关预测模块的目的是帮助 Vulmaster 识别和突出 CWE 网页中最相关的缺陷修复代码对,同时也将不太相关的对作为上下文信息。这里用一个二分类器实现错误修复代码对的关联预测
-
最后使用 FiD 网络进行多任务学习,先前的研究表明,多任务学习有助于增强代码完成,代码生成和代码理解等任务中基于学习模型的性能。实现方式为 \(L=L_{relavance}+L_{repair}\)
总结
核心思想还是将 FiD 运用到 APR 领域来解决输入长度限制的问题,此外还使用了 AST 适应和多任务学习,较大的提升了 APR 的能力

 浙公网安备 33010602011771号
浙公网安备 33010602011771号