预训练笔记 (CS224N-8)
子词模型
前置知识
(1)词法知识介绍
-
语音学是音流无争议的物理学
语音体系假定了一组或多组独特的、分类的单元(音素) -
传统上,词素是最小的语义单位(例如\(ate,ly,able\)这种),但如今我们需要讨论比单词粒度更细的模型以处理大量的开放词汇(巨大的、无限的单词空间)
例如:ooooooooooops!、imma go等非正式的拼写(这种情况在其他语言中更甚)
(2)字符级模型:词嵌入可以由字符嵌入组成,所有的语言处理均建立在字符序列上,不考虑word-level
子词模型
(1)NLP中的子词模型包含了一系列关于单词级别以下结构的推理方法(单词、字符、字节的组成部分)
(在训练和测试时,每个单词被分成一系列已知的子单词)
(2)子词模型的两种趋势
①与Word级模型相同的架构,但使用更小的单元:word pieces
②混合架构:主模型使用单词,其他使用字符级
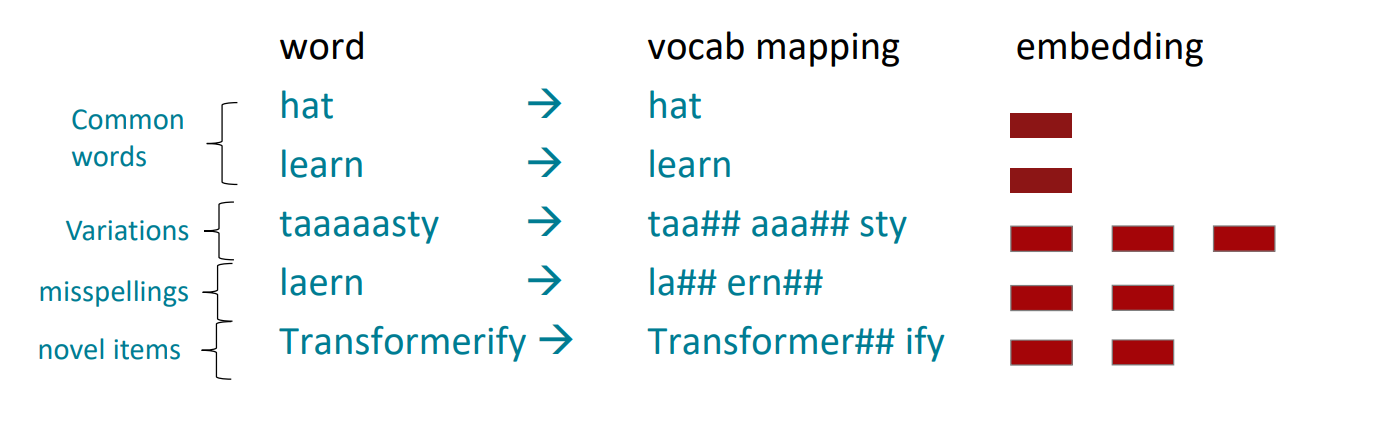
(3)字节对编码(BPE)
- 最初是一个压缩算法:最频繁的字节-->一个新的字节
- 字节对编码是定义子单词词汇表的一种简单有效的策略
①从只包含字符和“词尾”符号的词汇表开始。
②使用文本语料库,找出最常见的相邻字符“a,b”;添加“ab”作为一个子词。
③用新的子字替换字符对的实例,重复,直到达到所需的人声大小。 - 最初用于NLP中的机器翻译,现在在预训练的模型中使用了类似的方法
(4)普通单词最终成为子单词词汇的一部分,而稀有单词则被划分为组成部分(在最坏的情况下,单词被拆分为与字符一样多的子单词)
预训练
预训练解读
(1)有一个问题,我们网络中的大多数参数都是随机初始化的,这样会导致模型训练效果不好、容易过拟合等各种问题
(2)“预训练”的做法一般是将大量低成本收集的训练数据放在一起,经过某种预训练方法去学习其中的共性,然后将其中的共性“移植”到特定任务的模型中,再使用相关特定领域的少量标注数据进行“微调”,这样的话,模型只需要从”共性“出发,去“学习”该特定任务的“特殊”部分即可。
其实word2vec就是一个专注于词嵌入的预训练模型
(3)预训练&微调范式
①第一阶段:预训练,需要大量文本,学习共性
②第二阶段:微调,不需要太多标签,适应我们的任务
预训练架构
(1)Encoder:例如BERT
(2)Decoder:例如GPT
预训练模型
ELMO
(1)概念
- Contextualized Word Embedding(情境化Embedding):同一个word在不同的位置会视作不同的token
- ELMO(Embedding from Language Model):使用RNN-based语言模型来训练,预测下一个token或上一个token,拿在正向和反向RNN的隐含层拼接作为Contextualized Embedding(不需要label)
BERT
(1)概念
- Bidirectional Encoder Representations from Transformers:即为Transformer的Encoder架构(不需要label)
- BERT在做什么事情:输入一个句子进去,输出每一个词的embedding
- BERT的IDEA: 传统的语言模型就是单向的信息,而ELMO是正向+反向(参数量变成了之前单向的两倍,也是直接考虑双向的两倍,而且对于某些任务例如QA不合理)这比直接考虑双向模型更差,因为双向模型能够在同一个layer中直接考虑左边和右边的context。所以BERT直接考虑双向。
(2)过程
BERT主要由两个阶段组成,分别是Pre-training以及Fine-Tuning
-
Pre-Training:
①MLM:输入的句子有随机15%的概率被置换成[MASK],BERT需要做的是猜测[MASK]应该是哪些词汇(把MASK的部分输出的Embedding输入到一个线性的多分类器中来预测单词)
(但是mask wordpiece的做法也被后来(ERNIE以及SpanBERT等)证明是不合理的,没有将字的知识考虑进去,会降低精度,于是google提出了Whole Word Masking(WWM)的模型)
②NSP:给BERT两个句子,BERT来判断这两个句子是否应该被接在一起([SEP]用来隔开两个句子,[CLS]用来表示需要输出到线性二分类器的位置)
(注意两个方法需要同时使用)
-
Fine-Tuning:相似度任务、推理任务、QA任务、文本分类
①BERT的每一个Layer对应着一个任务,越靠近输入的Layer做越简单的任务,越靠近输出的Layer做越困难的任务。
②使用BERT做后续任务时,可以学习每一层得到的Embedding哪个更有用
GPT
(1)Generative Pre-Training:规模巨大,就是Transformer的Decoder
(2)力大飞砖,数据巨大、模型巨大,从而产生了很多奇迹的效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号