"Effective log parsing in log streams using fixed depth forest" 论文笔记
挑战
主要讲的是 Drain 的一些问题:
① 对于变量开头的日志会存在解析错误
② 常量在变量之前发生变化的日志也会导致解析错误
框架
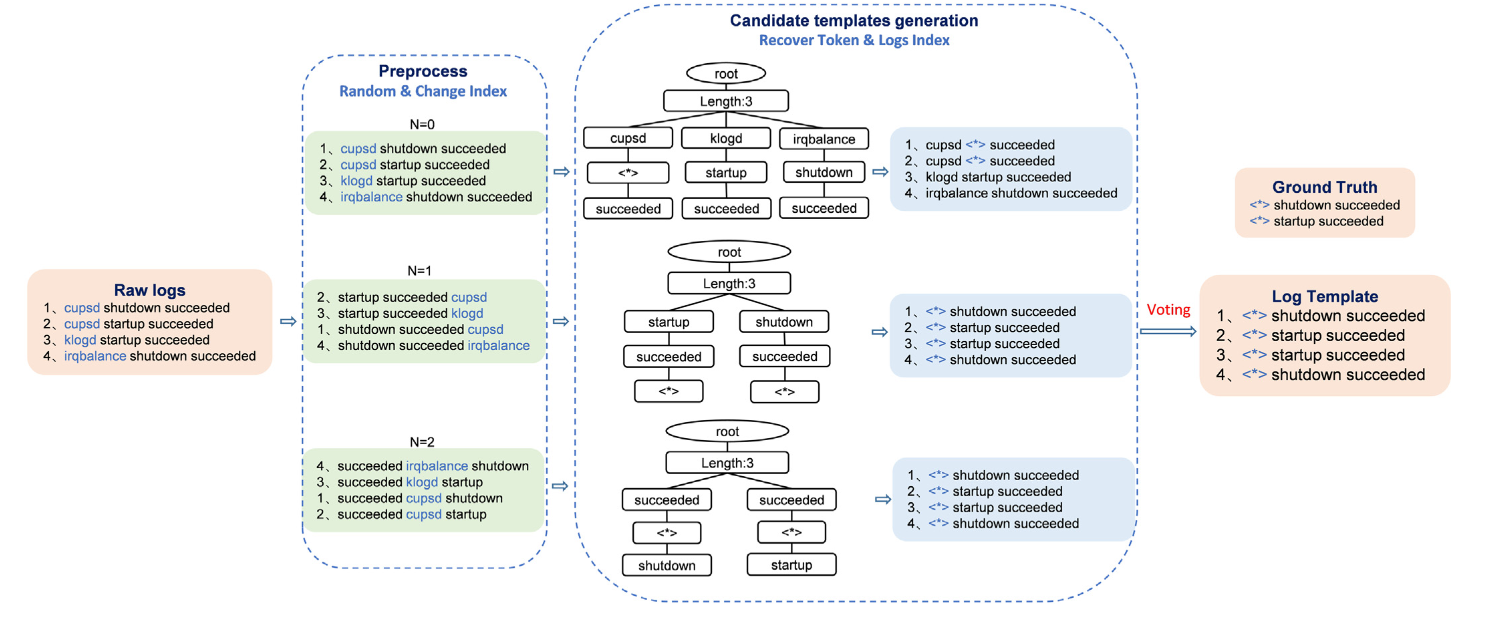
预处理
对于源日志,采用随机修改 token 的下标(即顺序)分成几个子日志,相当于数据增强
候选模版生成
这里采用的就是 Drain 的解析过程,为子日志生成候选模版,子日志得到一次候选模版相当于为该候选模版投一次票
模版选择
从投票最多的候选模版中,比较各自的变量数,筛掉变量数不同的模版,然后进行 OOV 检查(这里的假设是:开源词汇表之外的词更有可能是变量),最后对指定为变量的标记进行交叉比较
总结
这篇工作就是针对 Drain 的问题作出改进,使问题得到解决

 浙公网安备 33010602011771号
浙公网安备 33010602011771号