"MM-LLMs: Recent Advances in MultiModal Large Language Models" 论文笔记
介绍
这是一篇多模态大模型的综述
MM-LLM面临的核心挑战是如何有效地将LLM与其他模式的模型连接起来以实现协作推理
建立了一个网站(https://mm-llms.github.io)来跟踪MM-LLM的最新进展并方便大家更新
模型架构

冻结部分不可训练,未冻结部分是可训练的
-
Modality Encoder:对不同模态的输入进行编码,获取特征
-
Input Projector:将编码特征与文本特征进行对齐,然后一起送入LLM Backbone。所以这里目标是最小化条件文本生成损失
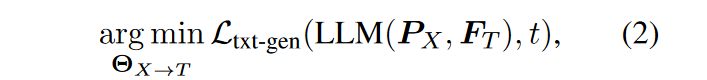
-
LLM Backbone:可以进行 zero-shot、few-shot、CoT 等等,它输出的信息包括文本、其他模态的信号和内容
-
Output Projector:将 LLM 的输出映射到 Modality Generator 可理解的特征 \(H_x\) 中。所以这里目标是最小化 \(H_x\) 与 Modality Generator 的文本表示的距离
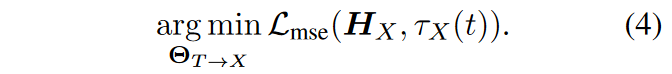
-
Modality Generator:生成不同模态的输出。在训练过程中,groundtruth 首先通过预训练的 VAE 转换为潜在特征,然后使用预训练的 Unet 来计算条件 LDM损失,如下所示
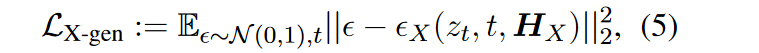
训练过程
分为两个阶段:MM PT 和 MM IT
MM PT
预训练阶段,针对数据集,训练 Input Projector 和 Output Projector,通过优化预定义的目标来实现各个模态数据之间的对齐匹配
MM IT
MM IT 由有监督微调+强化学习组成
使用指令数据集对预先训练的 MM-LLM 进行微调,通过这个过程可以遵循新指令泛化到为见过的任务上,从而具备 zero-shot 的能力
SOTA模型
各个方向的 SOTA 模型汇总图

发展趋势
-
从专门强调 MM 理解发展到特定模态的生成,并进一步发展到任意模态到任意模态的转换(例如 MiniGPT-4 → MiniGPT-5 → NExT-GPT)
-
从 MM PT 到 SFT 再到 RLHF,训练流程不断细化,力求更好地符合人类意图,增强模型的对话交互能力(例如BLIP-2→InstructBLIP→DRESS)
-
拥抱多样化的模态扩展(例如BLIP-2→X-LLM和InstructBLIP→X-InstructBLIP)
-
纳入更高质量的训练数据集(例如LLaVA → LLaVA1.5)
-
采用更高效的模型架构,从 BLIP-2 和 DLP 中复杂的 Q-和 P-Former 输入投影仪模块过渡到 VILA 中更简单但有效的线性投影仪
归纳挑战
-
挑战:更高的图像分辨率可以为模型包含更多的视觉细节,有利于需要细粒度细节的任务。然而,更高的分辨率会导致更长的 token 序列,从而产生额外的训练和推理成本
方法:最近,Monkey(Li et al., 2023l)提出了一种无需重新训练高分辨率视觉编码器,仅利用低分辨率视觉编码器来增强输入图像分辨率的解决方案,支持高达 1300 × 800 的分辨率。为了理解富文本图像、表格和文档内容,DocPedia (Feng et al., 2023) 引入了一种将视觉编码器分辨率提高到 2560 × 2560 的方法,克服了开源 ViT 中低分辨率性能不佳的限制。
-
VILA 揭示了几个关键发现:
①在 LLM Backbone 上执行 PEFT 可以促进深度嵌入对齐,这对于 ICL 至关重要
②交错的图像-文本数据被证明是有益的,而单独的图像文本对并不是最优的
③在SFT期间将纯文本指令数据与图像文本数据重新混合,不仅解决了纯文本任务的退化问题,而且还提高了VL任务的准确性
未来方向
-
更强大的模型:模态扩展、大模型多样化、提升多模态数据集质量、强化多模态生成能力
-
构建一个更具挑战性、更大规模、包含更多模式、使用统一评价标准的基准对于MM-LLM的发展至关重要
-
轻量化部署
-
具身智能
-
持续学习
-
减轻幻觉现象

 浙公网安备 33010602011771号
浙公网安备 33010602011771号