"LILAC: Log Parsing using LLMs with Adaptive Parsing Cache" 论文笔记
挑战
① LLM 用于日志解析的专业能力不足
② LLM 的输出不稳定,可能会为具有相同模板的日志消息输出不同的模板
③ LLM 的巨大开销
框架
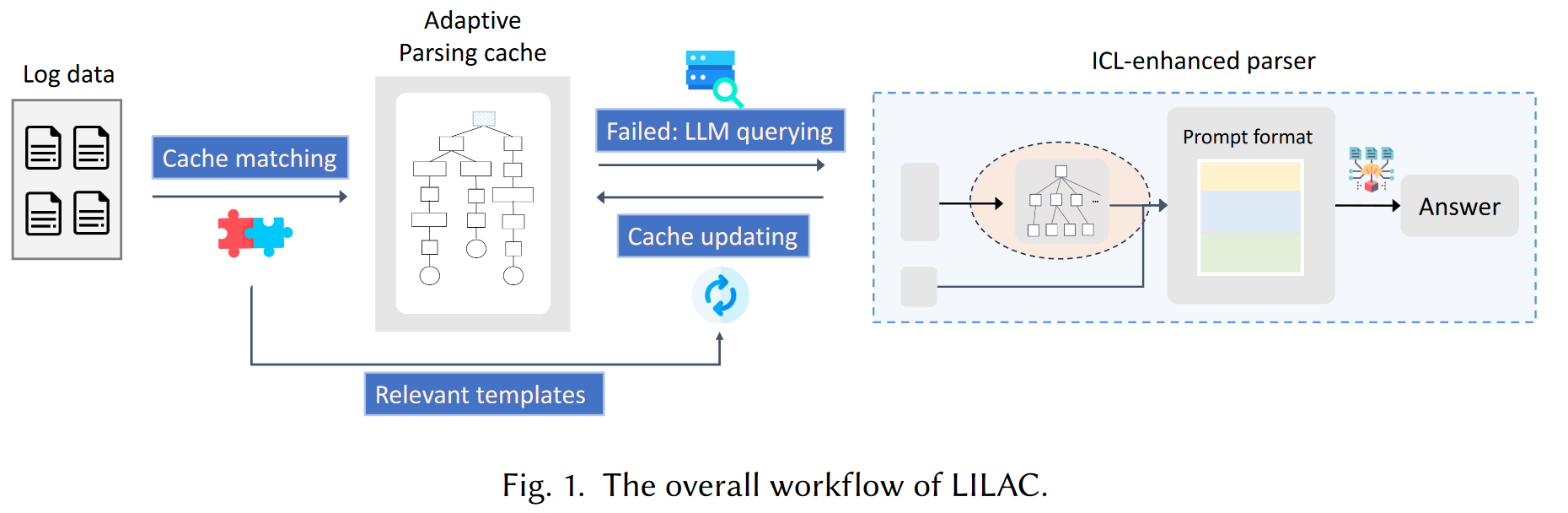
ICL 增强解析器
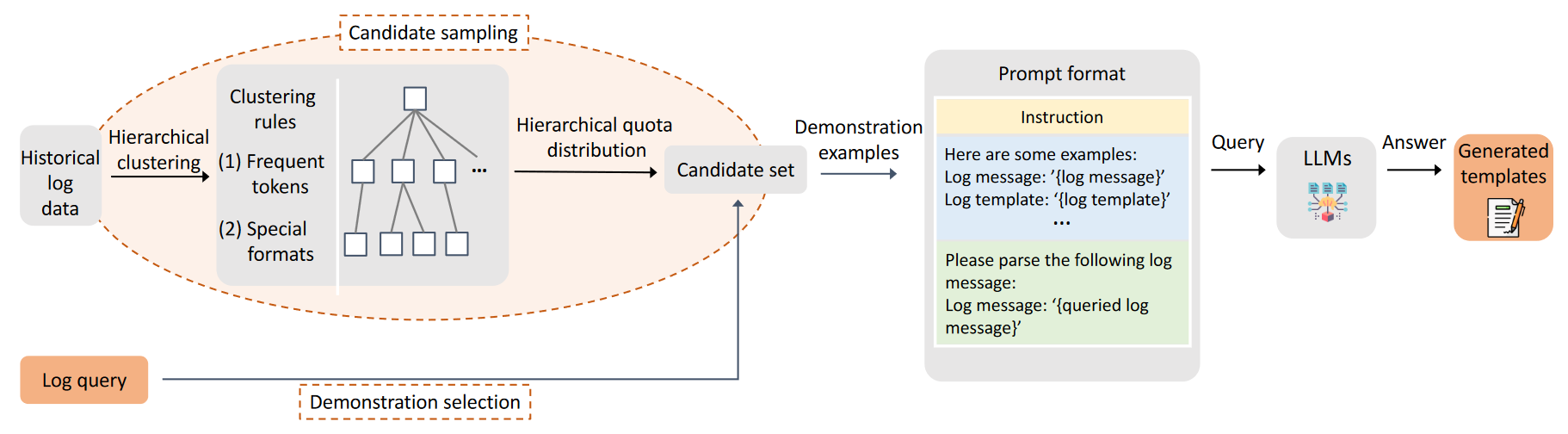
首先执行分层候选采样算法来采样一小组多样化且具有代表性的候选日志消息。在线解析过程中,对于每个查询的日志,LILAC 利用基于 KNN 的示范选择算法来选择相似的示范示例。这些演示按照设计的格式集成到提示中。最后,ICL增强解析器将提示输入LLM并获取生成的模板
自适应解析缓存
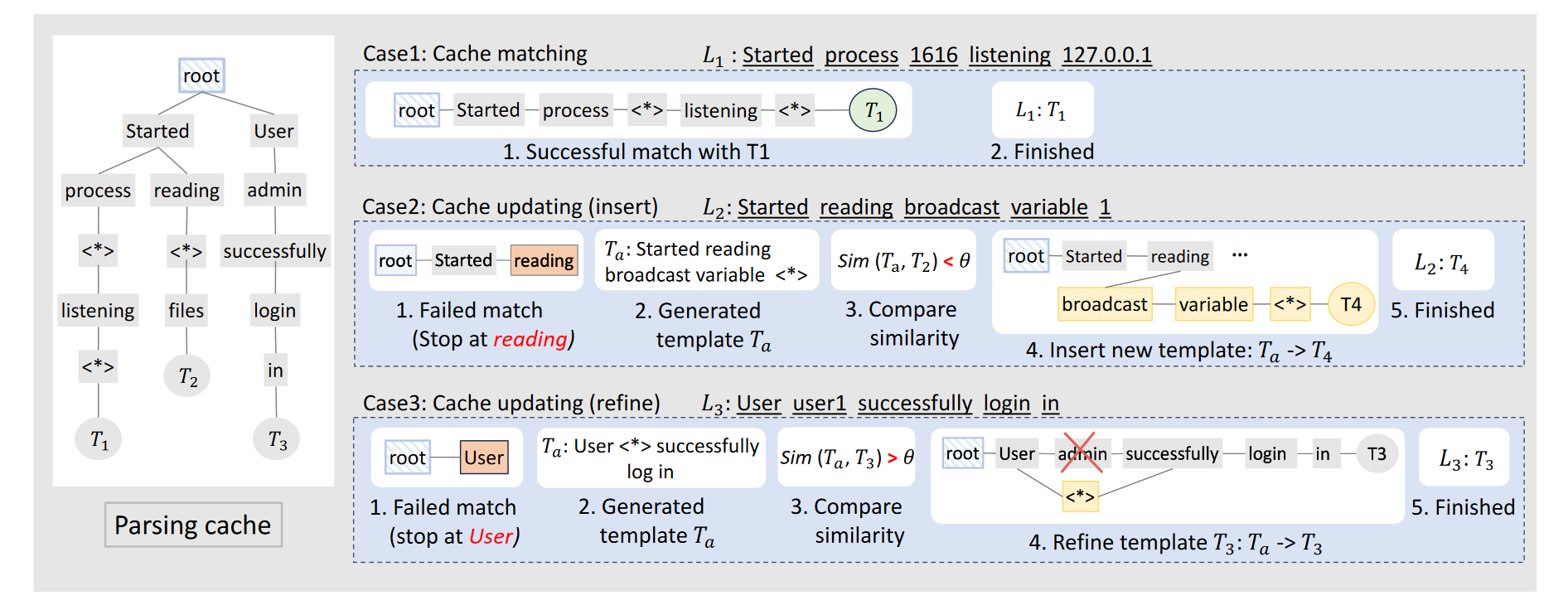
采用树形结构来存储LLM生成的模板,作为解析缓存(类似语法树)。这种树结构允许有效存储和并行检索日志模板,可以直接反映日志模板之间的相似性
总结
创新点在于分层采样和语法树结构的自适应解析缓存,同时提出了缓存更新的策略,是一篇非常有意义的工作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号