"Diagnosing root causes of intermittent slow queries in cloud databases" 论文笔记
背景
[VLDB 2020] 随着云数据库市场的不断增长,仔细检测并消除慢查询对于服务稳定性至关重要。以前的研究重点是优化由于内部原因(例如,写得不好的 SQL)而导致的慢查询。在这项工作中,我们发现了一组不同的慢速查询,它们对数据库用户来说可能比其他慢速查询更危险。我们将此类查询命名为间歇性慢速查询 (iSQ),因为它们通常是由外部间歇性性能问题(例如,在数据库或机器级别)引起的。诊断 iSQ 的根本原因是一项艰巨但非常有价值的任务
贡献
- 我们识别了云数据库中iSQ的问题,并设计了一个名为 iSQUAD 的可扩展框架,该框架提供准确、高效的 iSQ 根本原因诊断
- 我们应用 KPI 异常提取代替异常检测来区分异常类型
- 我们是第一个通过贝叶斯案例模型在数据库领域应用和集成基于案例的推理,并将案例子空间表示提供给DBA 进行标记
- 我们对 iSQUAD 的评估进行了广泛的实验,并证明我们的方法的平均 F1 分数为 80.4%,即比之前的技术高出 49.2%。此外,我们还在现实世界的云数据库服务中部署了 iSQUAD 原型
任务
本文提出了 iSQUAD(间歇性慢速查询异常诊断器),这是一个可以诊断 iSQ 根本原因的框架,且无需人工干预
数据
Alibaba OLTP数据库
模型
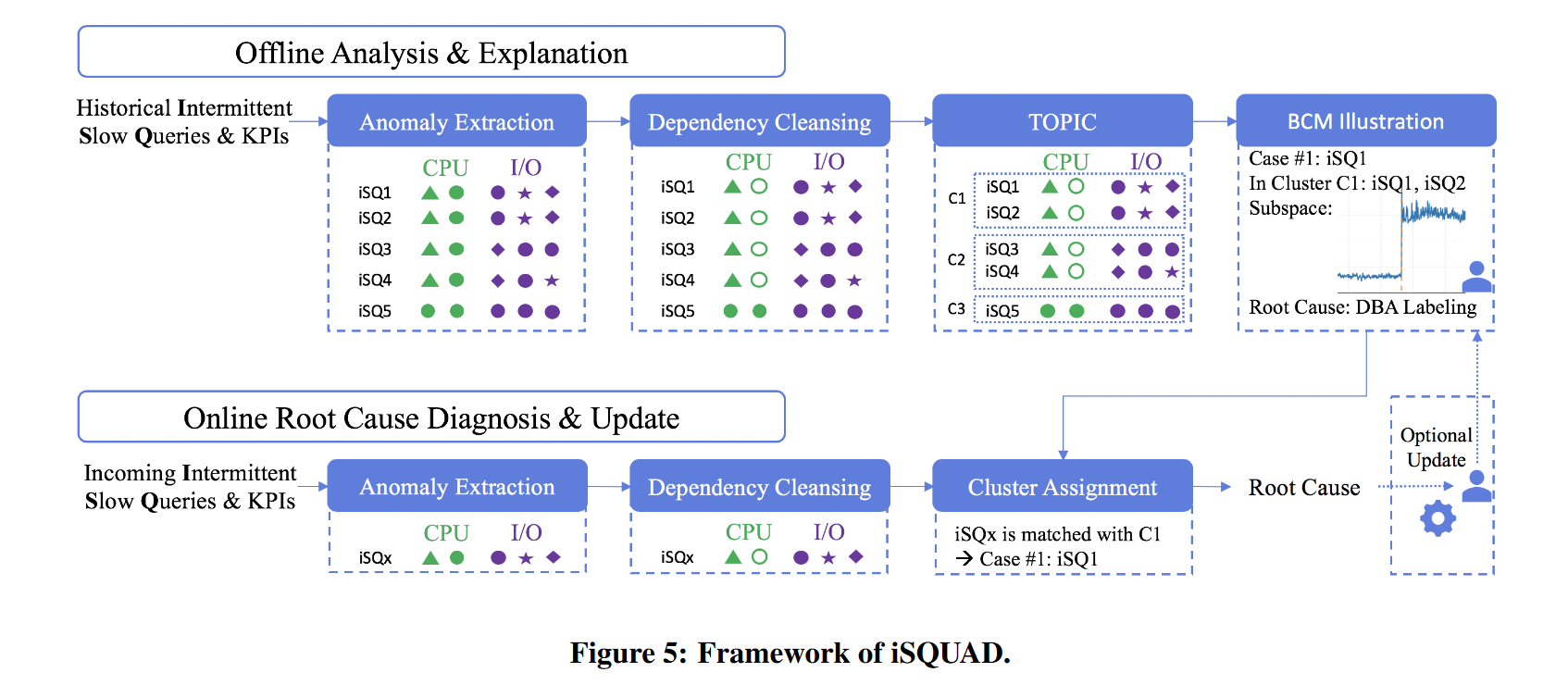
前导发现
- KPI 对于查找 iSQ 的根本原因非常重要
- 需要注意的KPI异常类型:spike、level shift up、level shift down和void(KPI值为零或缺失)
- KPI异常之间是高度相关的
- 相似的 KPI 模式与相同的根本原因相关
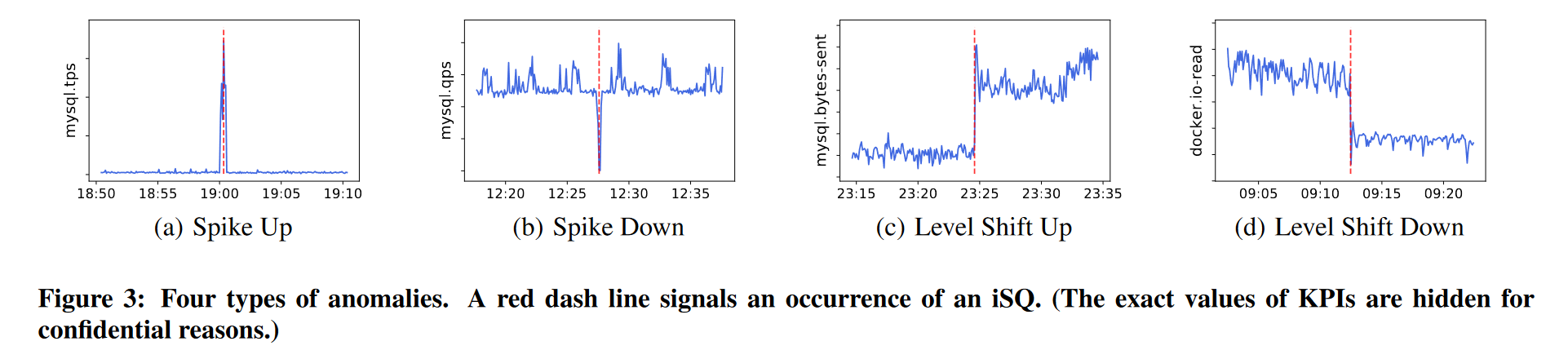
异常提取
给定 iSQ 的发生时间戳,我们可以从数据仓库中收集相关的 KPI 片段。
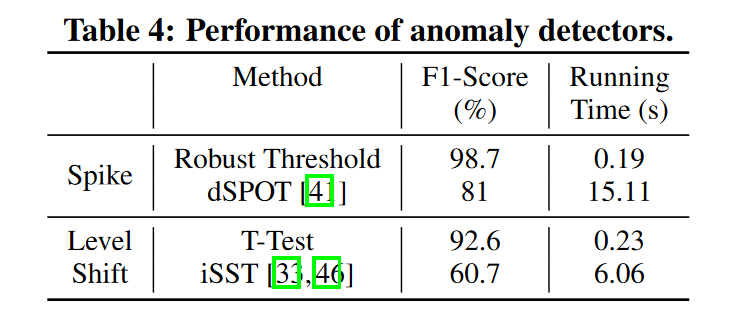
- 识别 spike:Robust Threshold(其中使用中位数和中位数绝对差来决定分布,使用柯西分布代替正态分布,阈值根据经验设置)超过Robust Threshold即发生spike。
- 识别 level shift:给定特定时间戳,我们在该点分割 KPI 时间线并生成两个窗口。接下来,检查两条时间线的分布是否相似。如果存在显着差异并通过 T 检验(用于测试两组平均差异的推论统计,t 值阈值根据经验设置),iSQUAD 将确定发生level shift。
依赖清理
需要确保选择考虑的所有 KPI 彼此独立,以便 KPI 的相关性或过度代表性不会影响我们的结果。这里基于两个KPI之间的关联规则学习的置信度来确定两个KPI是否具有相关性。
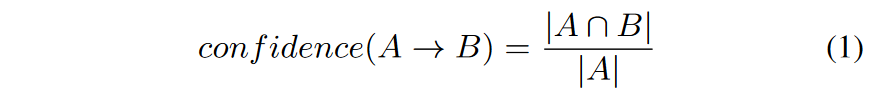
(其中 A 和 B 代表两个任意 KPI。具体来说,从A到B的置信度是A的异常和B的异常同时出现的次数除以A的异常出现的次数)
置信度值范围为 0 到 1,这里做一个二分类,在0和1之间设置了一个阈值,高于该阈值的两个 KPI 被认为是相互依赖的。例如,实例的CPU利用率异常通常会伴随实例物理机的异常。如果我们计算置信度,我们可能会得到结果“1”,这表明两个 KPI 是相关的。因此这里便会丢弃物理机 CPU 利用率的所有异常,并保留实例 CPU 利用率的异常。
模式集成聚类
定义两个 iSQ i 和 j 的相似度 Sij 如下:
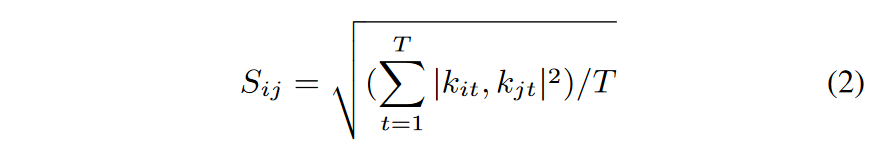
(其中 t 是 KPI 类型的数量,T 表示所有 t 的总和。 \(k_{it}\)和 \(k_{jt}\) 分别是 iSQ i 和 j 的 KPI 类型 t 中的异常状态)
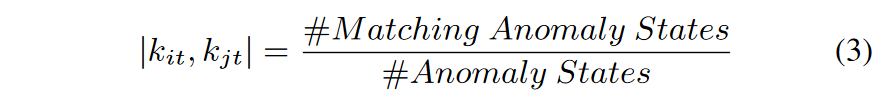
(\(k_{it}\)和 \(k_{jt}\) 之间的计算是简单匹配系数SMC:匹配的异常状态数量/异常状态总数)
从理论上讲,“CPU”的高相似性很容易被“I/O”的弱相似性所抵消。为了解决这个问题,可以看到这里是计算每个 KPI 类型的单独简单匹配系数,通过取所有 KPI 的相似度的二次平均值来获得区间 [0, 1] 中的值。这里也是做一个二分类,在0和1之间设置了一个阈值,高于该阈值则认为相似。
聚类算法伪代码如下:

算法分析:转换为字典的数据集 S 是包含 iSQ 及其通过异常提取和依赖清理所得到的模式(论文中没提到具体格式)。所需的输入(即阈值 σ)用于确定两个 iSQ 应该有多相似才能变得同质。首先,我们将字典 S 反转为字典 D:D 的索引和值分别是 S 的值(模式)和聚类索引(iSQ)(算法 1 中的第 2 行到第 3 行)。对于KPI 状态全部正常的模式(all-zero pattern),我们从 D 中消除它及其对应的 iSQ,并将它们放入聚类字典 C 中(第 4 行到第 6 行)。此先决条件检查保证all-zero pattern的 iSQ 可以合理地聚集在一起。为了基于模式对 iSQ 进行聚类,我们首先将 D 的模式存储到 KD 树中,这是在聚类中搜索最近元素的一种非常常见的方法(第 9 行)。对于 D 中的每个模式 i,该函数找到其最接近的模式 j,如果 i 和 j 仍在 D 内并且它们的模式相似,则该函数将两个模式合并为一个新模式(编号较大的模式被保留,而编号较小的模式被删除,并将其相应的 iSQ 添加到前一个模式的对应 iSQ 中)当 D 的大小不再改变时迭代终止(第 15 至 16 行)。
贝叶斯案例模型
BCM 是一个优秀的框架,用于提取典型案例并生成相应的特征子空间。我们需要首先对 iSQ 进行聚类,然后将它们提供给 BCM,满足了 BCM 的应用要求,因此可以应用它来生成集群的案例和特征子空间。
简而言之,我们满足了 BCM 的应用要求,因此可以应用它来生成集群的案例和特征子空间。借助这些信息,我们能够更好地理解集群的结果,从而为DBA提供更多提示性信息。
(论文中没有提供具体的过程,只是说明了最终的结果可以提供到BCM中进行声测会给你集群案例和特征子空间,为操作人员提供更多的提示信息,增强可解释性)
在线模式
在对新的 iSQ 进行离散化和清理后,iSQUAD 会进行查询,与集群进行匹配以进行诊断。它遍历现有集群的模式,以查找与此传入查询完全相同的模式,或者与此传入模式共享最高相似性得分(高于相似性得分 σ)的模式。如果 iSQUAD 确实找到了一个满足上述要求的集群,那么该集群的根本原因自然可以解释这一新的iSQ。否则,iSQUAD 会为此“基础”查询创建一个新集群,并要求 DBA 诊断该查询及其主要根本原因。最后,添加新的集群以及诊断出的根本原因来完善 iSQUAD。当该框架用于分析未来的 iSQ 时,新集群与其他集群一样,如果它们的模式与该集群的模式足够相似,则可用于随后的查询。
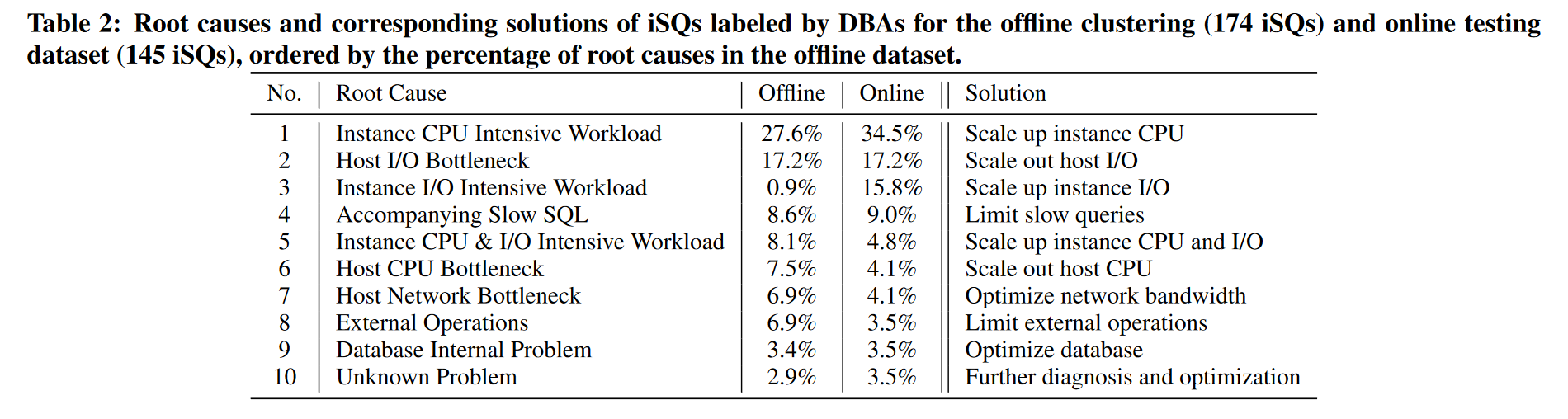
结果
iSQUAD的准确性和效率:(DBsherlock作为baseline)
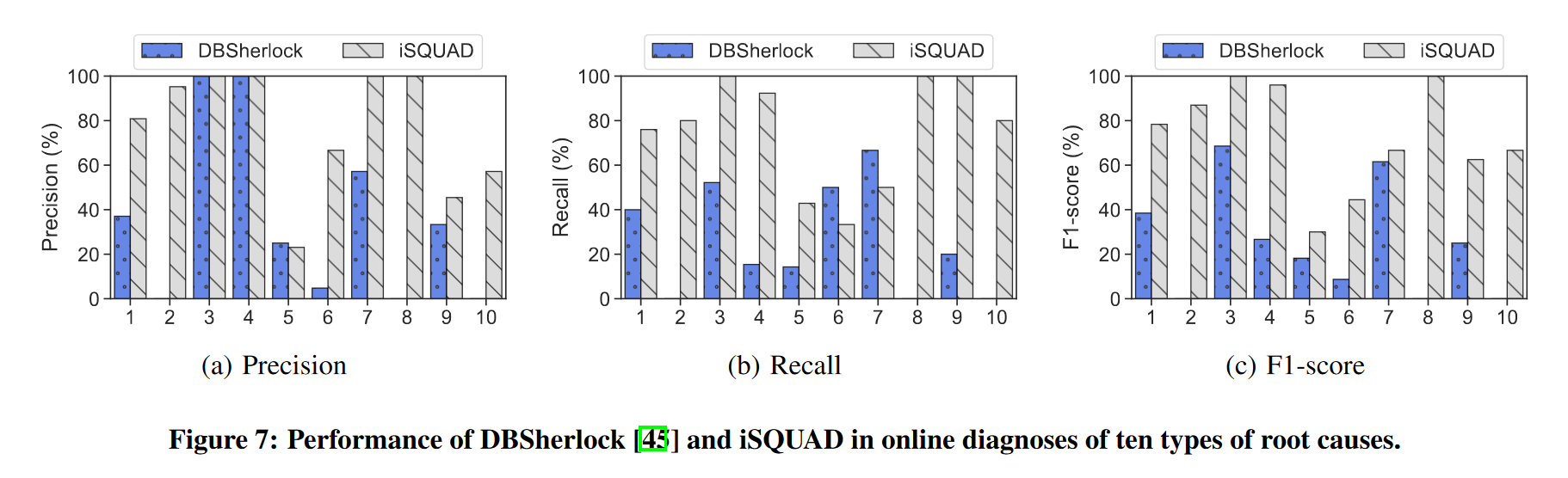
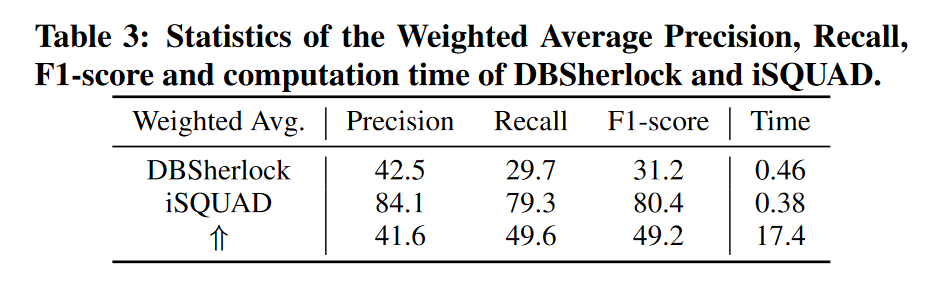
异常提取:
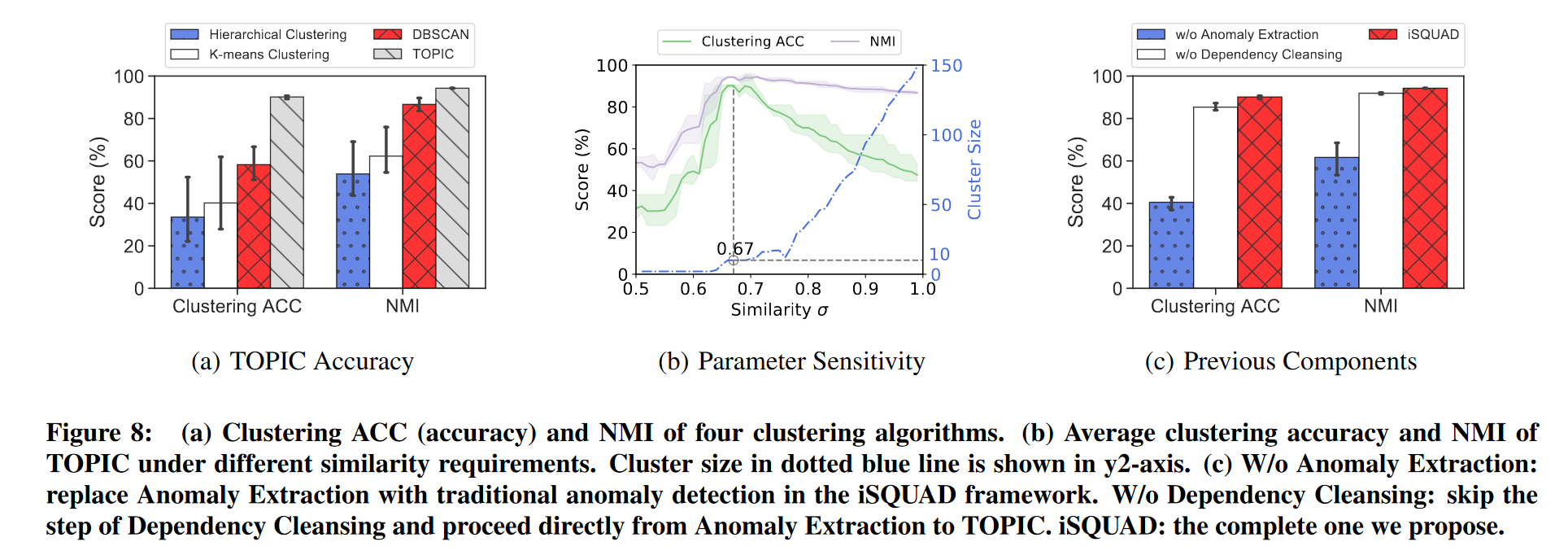
聚类算法:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号