"CloudRCA: A Root Cause Analysis Framework for Cloud Computing Platforms" 论文笔记
主要框架
数据源:metric、log、cmdb
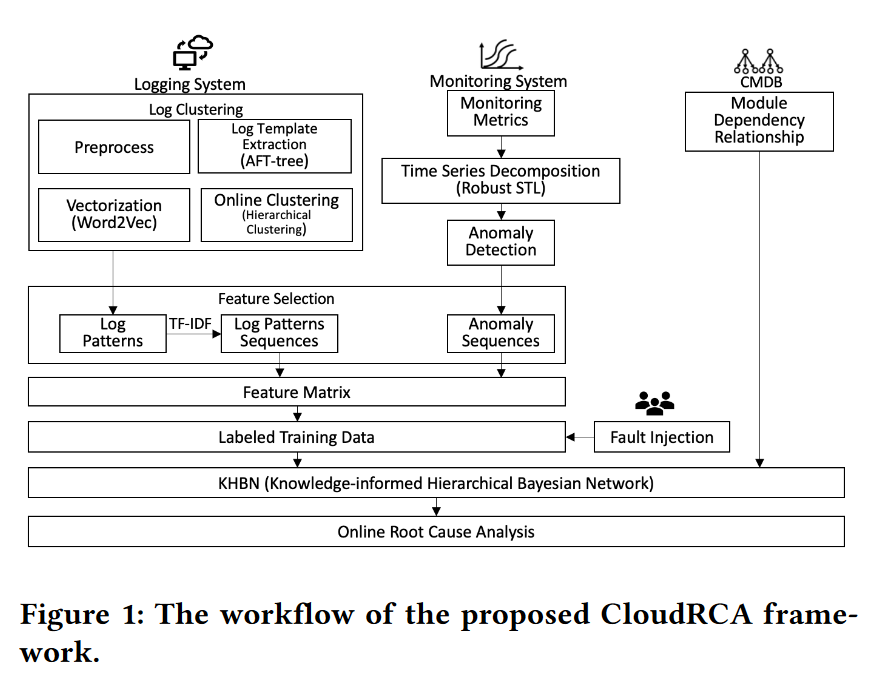
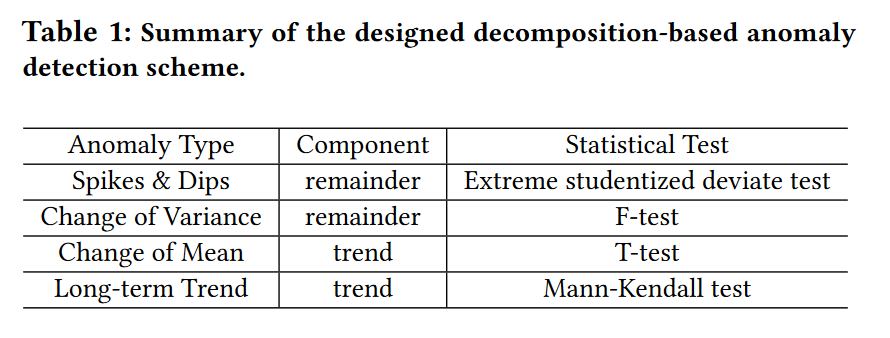
指标异常检测
因为流处理中的指标通常具有周期性,首先通过wavelet隔离周期,然后通过自相关函数的峰值来识别周期。
接下来需要将时间序列分解成周期、季节项和残差。由于传统STL时间序列分解表现不好,这里通过 RobustSTL来 对时间序列进行分解。
最后通过不同的统计测试方法对分解项来检测不同类型的异常点。主要的异常类型及其对应的检测方法和统计测试方法如下:
日志模版提取和聚类
日志预处理
通过删除诸如IP地址,表名称,接口ID等不重要的变量来从消息内容中提取模板
日志模板提取
提出了一种基于FT-Tree的渐进式训练算法,称为自适应频繁模板树(AFT-Tree)。
AFT-Tree的改进点,包括:(1)采用字典保存孩子节点,避免重复插入节点 (2)使用节点的叶子节点数用于剪枝。
日志模板聚类
离线模式下,对于提取的日志模板,采用 word2vec + hierarchical clustering 方法进行聚类,以将日志汇总到不同的簇中,这些簇称之为日志模式。
根据集群中的每个日志与同一集群中其他日志的平均距离来计算得分(由下式可知,越靠近簇的中心,得分就越高)
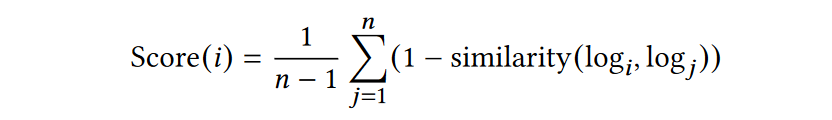
这里会选择得分最小的日志内容作为代表。然后在在线模式下,新日志与提取的代表聚集在一起,它们要么分布到现有的集群中,要么自己形成新的集群。更具体地说,当新的日志 s 出现时,计算输入日志 s 与现有集群的代表的相似度。如果相似度高于阈值 θ ,我们将输入日志消息分配给相似度最大的簇;否则我们为 s 创建一个新的簇,以 s 本身为代表。阈值计算公式见下:(m是簇总数)
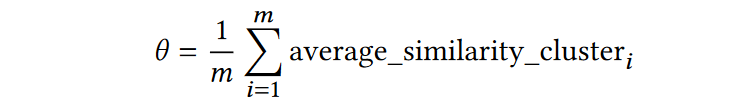
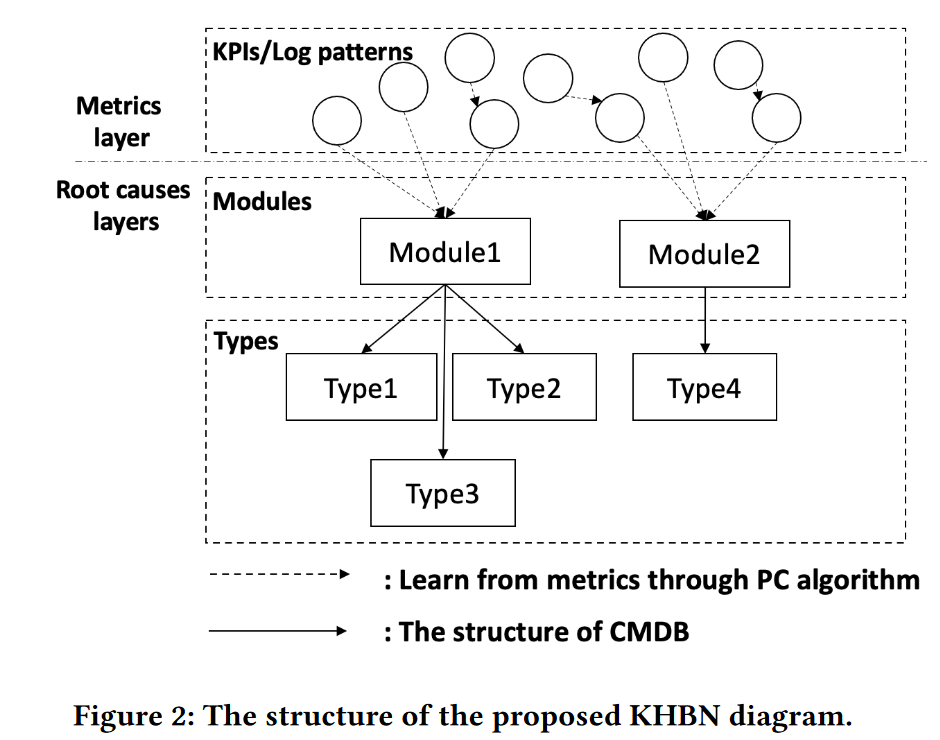
层次贝叶斯网络(KHBN)
我们分为两个阶段建立网络结构,分配阶段和因果学习阶段。
在分配阶段,我们使用CMDB的拓扑信息来生成节点之间的初始边。在因果学习阶段,代表节点之间因果关系的有向边是根据从正常和异常时期收集的系统指标构建的(这里用到了PC算法)
然后再通过历史数据训练模型
数据集
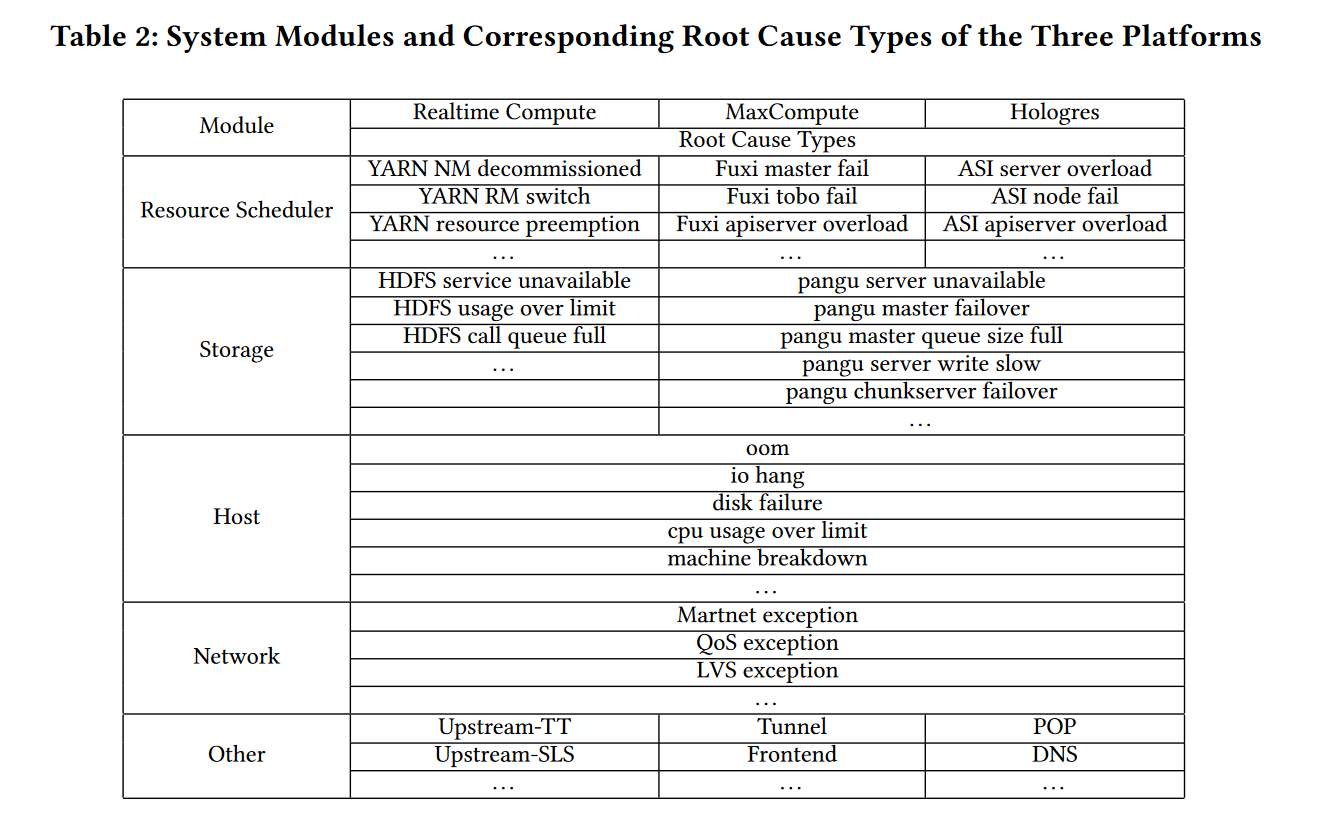
(1)阿里的三个云计算平台以及对应的根因类型如下
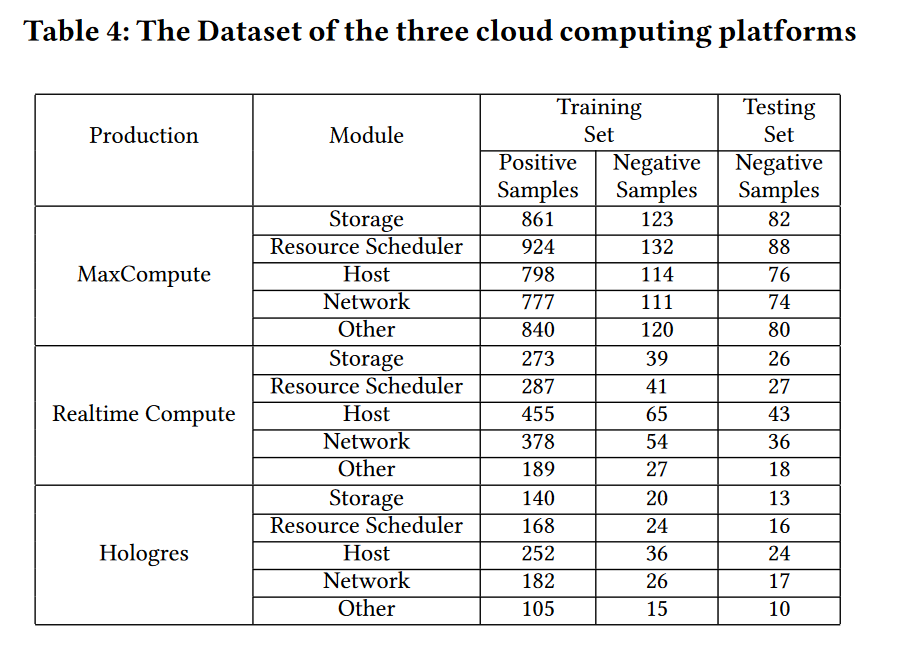
(2)所使用的数据集样本情况
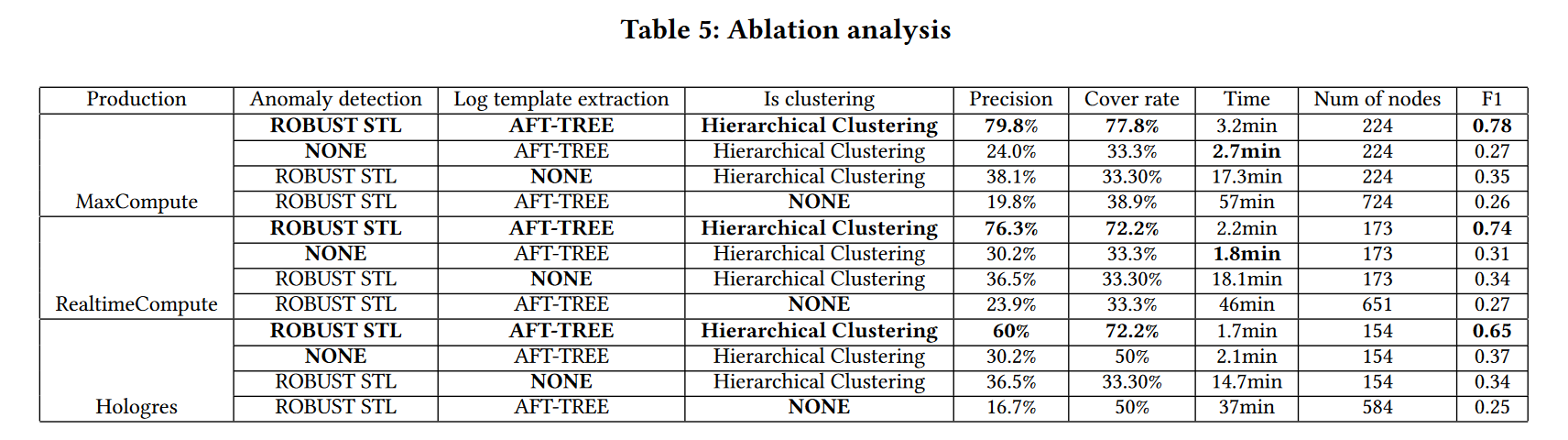
消融实验
在阿里三个云计算平台中的性能表现(与其他根因定位算法比较)
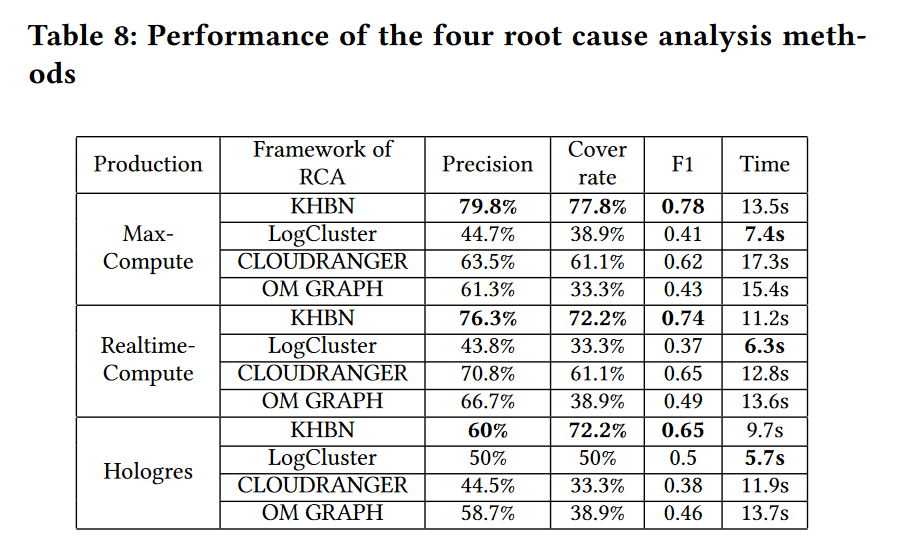
跨平台转移
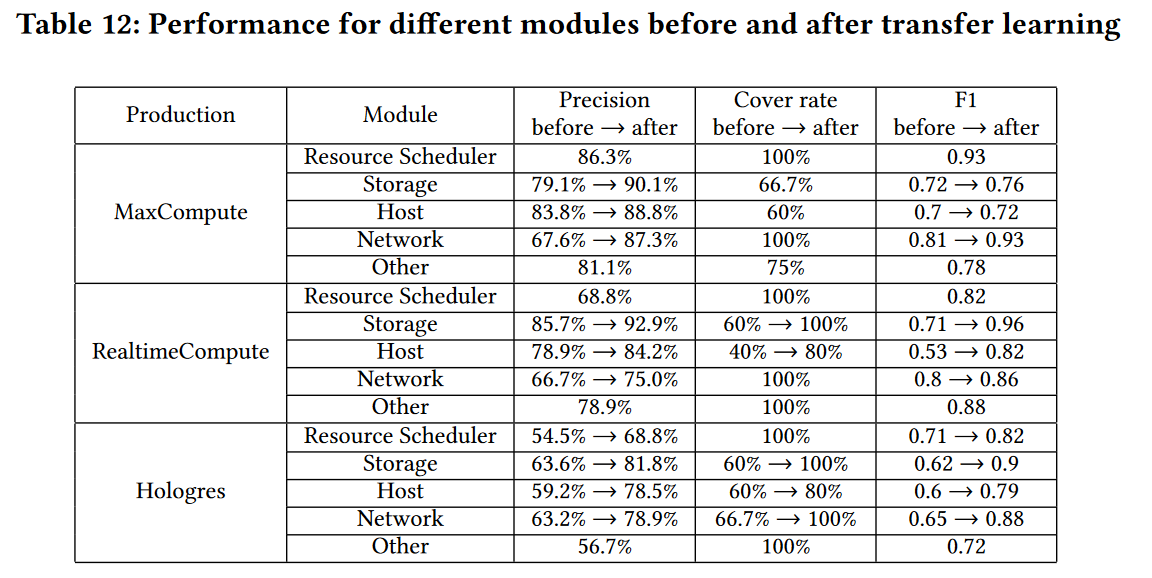
设计了一个跨平台转移学习机制,该机制结合了来自三个不同的大数据云计算平台的相同模块的样本,以丰富训练集,其对性能的提升如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号