day 10总结(字符编码、Python2和3字符编码的区别、文件的三种打开模式、with管理文件)
一、字符编码
1.计算机基础
- cpu: 控制程序的运行(从外存中取出文本编辑器的数据读入内存)。
- 内存: 运行程序(经cpu操作后,内存中含有文本编辑器的数据)。
- 硬盘: 存储数据(文本编辑器)。
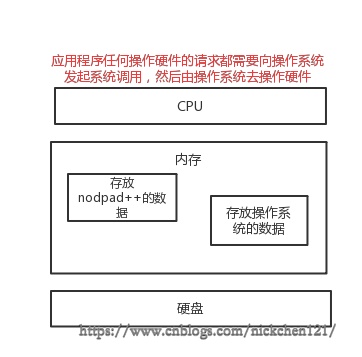
2.文本编辑器存取文件的原理
- 打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都是存放与内存中的,断电后数据丢失。
- 要想永久保存,需要点击保存按钮:编辑器把内存的数据刷到了硬盘上。
- 在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
3.Python解释器执行test.py文件的原理
- 第一阶段:Python解释器启动,此时就相当于启动了一个文本编辑器
- 第二阶段:Python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名)。
- 第三阶段:Python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即真正执行代码时,才会识别Python的语法,执行文件内代码,当执行到name="egon"时,会开辟内存空间存放字符串"egon")。
4.Python解释器与文本编辑器的异同
- 相同点:Python解释器是解释执行文件内容的,因而Python解释器具备读py文件的功能,这一点与文本编辑器一样。
- 不同点:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会Python的语法,而Python解释器将文件内容读入内存后,可不是为了给你瞅一眼Python代码写的啥,而是为了执行Python代码、会识别Python语法。
5.字符编码介绍
5.1什么是字符编码?
- 起因:计算机只认识0和1
- 人机交流的过程:字符----->翻译过程------->数字
- 总而言之,字符编码是将人类的字符编码成计算机能识别的数字,这种转换必须遵循一套固定的标准,该标准无非是人类字符与数字的对应关系,称之为字符编码表。
5.2涉及到字符编码的两个场景
- 一个Python文件中的内容是由一堆字符组成的,存取均涉及到字符编码问题(Python文件并未执行,前两个阶段均属于该范畴)。
- Python中的数据类型字符串是由一串字符组成的(Python文件执行时,即第三个阶段)。
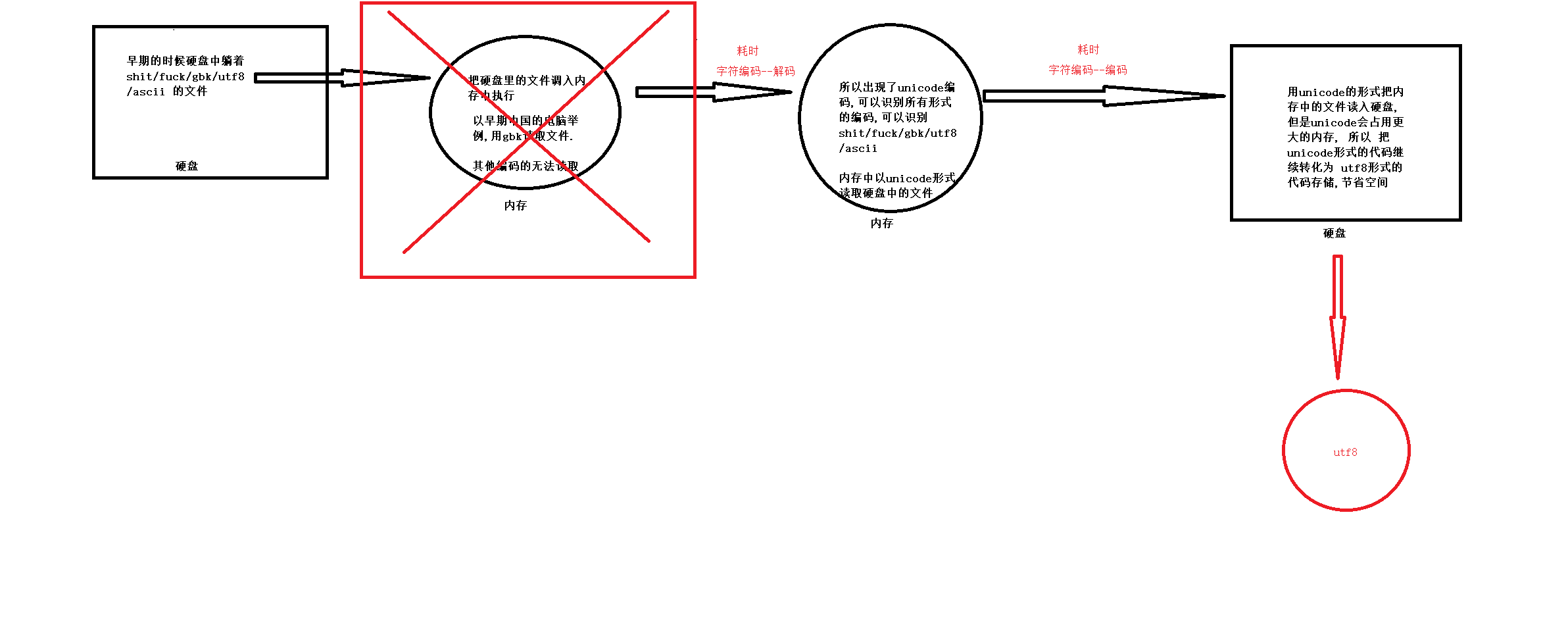
5.3乱码分析
首先明确概念
- 文件从内存刷到硬盘的操作简称存文件
- 文件从硬盘读到内存的操作简称读文件
乱码的两种情况:
- 乱码一:存文件时就已经乱码
存文件时,由于文件内有各个国家的文字,我们单以shift_jis去存,
本质上其他国家的文字由于在shift_jis中没有找到对应关系而导致存储失败。但当我们硬要存的时候,编辑并不会报错,但毫无疑问,不能存而硬存,肯定是乱存了,即存文件阶段就已经发生乱码,而当我们用shift_jis打开文件时,日文可以正常显示,而中文则乱码了。
- 乱码二:存文件时不乱码而读文件时乱码
存文件时用utf-8编码,保证兼容万国,不会乱码,而读文件时选择了错误的解码方式,比如gbk,则在读阶段发生乱码,读阶段发生乱码是可以解决的,选对正确的解码方式就可以了。
6.总结
- 保证不乱码的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码。
- 在内存中写的所有字符,一视同仁,都是Unicode编码,比如我们打开编辑器,输入一个“你”,我们并不能说“你”就是一个汉字,此时它仅仅只是一个符号,该符号可能很多国家都在使用,根据我们使用的输入法不同这个字的样式可能也不太一样。只有在我们往硬盘保存或者基于网络传输时,才能确定”你“到底是一个汉字,还是一个日本字,这就是Unicode转换成其他编码格式的过程了。简而言之,就是内存中固定使用的就是Uncidoe编码,我们唯一能改变的就是存储到硬盘时使用的编码。
- Unicode----->encode(编码)-------->gbk
- Unicode<--------decode(解码)<----------gbk

具体流程:
二、Python2与Python3字符编码的区别(了解)
1.python解释器运行代码的流程
- 启动python解释器(相当于文本编辑器)
- 打开文件,显示这个字符并检查语法(涉及字符编码, a=1只是一个很普通的字符)
- 解释字符 (涉及字符编码,再去内存空间 生成一个a=1的变量)
2.区别:
| 代码详情 | Python2执行情况 | Python3执行情况 |
|---|---|---|
| # coding:gbk print('中') 终端:utf8 |
乱码 | 不乱码 |
| # coding:utf8 print('中') 终端:utf8 |
不乱码 | 不乱码 |
| # coding:gbk print(u'中') 终端:utf8 |
不乱码 | 不乱码 |
| # coding:utf8 print(u'中') 终端:utf8 |
不乱码 | 不乱码 |
在Python2中如果指定了字符编码,那么内存存取就会按照指定的字符编码去入内存。解释或去执行时就要按照指定了的字符编码去解释,否则就会乱码。 否则可以在定义变量前面加上u,这样变量就会以unicode编码存入内存。
如:
#coding:gbk
name = "爸爸"
但在Python3中就不会有这样的问题,因为无论你指定了什么字符编码,在内存存取时都会使用Unicode编码去入内存,Unicode编码可以和任意的字符编码相互转换,并在读取时按照所需的编码区读取,这样就很好解决了字符编码的问题。
三、文件的三种打开模式
文件操作的基础模式有三种(默认的操作模式为r模式):
- r模式为read
- w模式为write
- a模式为append
文件读写内容的格式有两种(默认的读写内容的模式为b模式):
- t模式为text
- b模式为bytes
需要注意的是:t、b这两种模式均不能单独使用,都需要与r/w/a之一连用。
1.文件打开模式之r模式
r: read,只读模式,只能读不能写,文件不存在时报错。
f = open('32.txt', mode='rt', encoding='utf8')
data = f.read()
print(data)
print(f"type(data): {type(data)}")
f.close()
aaa
bbb
ccc
注意:f.read()读取文件指针会跑到文件的末端,如果再一次读取,读取的将是空格。
由于f.read()一次性读取文件的所有内容,如果文件非常大的话,可能会造成内存爆掉,即电脑卡死。因此可以使用f.readline()/f.readlines()读取文件内容。
# f.readline()/f.readlines()
f = open('32.txt', mode='rt', encoding='utf8')
print(f"f.readable(): {f.readable()}") # 判断文件是否可读
data1 = f.readline()
data2 = f.readlines()
print(f"data1: {data1}")
print(f"data2: {data2}")
f.close()
f.readable(): True
data1: aaa
data2: ['bbb\n', 'ccc\n']
2.文件打开模式之w模式
w: 只能写,不能读,文件存在的时候回清空文件后再写入内容;文件不存在的时候会创建文件后写入内容。
f = open('test.txt', mode='wb')
f.write('My name'.encode('unicode_escape')) # 编码成bytes类型
f.close()
3.文件打开模式之a模式
a: 可以追加。文件存在,则在文件的末端写入内容;文件不存在的时候会创建文件后写入内容。
f = open('test.txt', mode='at', encoding='utf8')
f.write('My name\n') # '\n'是换行符
f.write('tom,bill,frank.')
f.write('aaaa')
f.close()
4.文件打开读取二进制
b模式是通用的模式,因为所有的文件在硬盘中都是以二进制的形式存储的,需要注意的是:b模式读写文件,一定不能加上encoding参数,因为二进制无法再编码。
f = open('test.txt', 'wb')
f.write('666666'.encode('utf8'))
f.close()
四、with管理文件操作上下文
- 之前我们使用open()方法操作文件,但是open打开文件后我们还需要手动释放文件对操作系统的占用。但是其实我们可以更方便的打开文件,即Python提供的上下文管理工具——with open()。
with open('test.txt', 'rt', encoding='utf8') as f:
print(f.read())
My name
- with open()方法不仅提供自动释放操作系统占用的方法,并且with open可以使用逗号分隔,一次性打开多个文件,实现文件的快速拷贝。
with open('test.txt', 'rb') as fr, \
open('test2.txt', 'wb') as fw:
f.write(f.read())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号