Redis Cluster(Redis 集群)详解
一、基础概念及原理说明:
1.1、Redis常见几种集群简介
Redis组建集群共有三种方式,每种方法都有自己的有缺点,下面对每种方法进行概述:
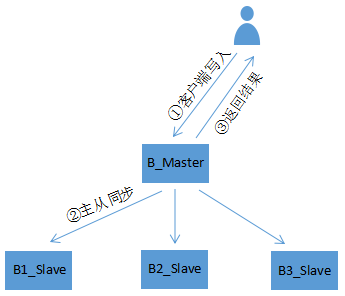
第一种:Redis主从模式,搭建该集群有点就是非常简单并且每个数据保存在多个Redis中,这样保障Redis中的数据安全,缺点是当集群中的主服务器(Master)宕机后从服务器(Slave)不会自动接管主服务器的工作,需要人工干预
第二种:Redis哨兵模式,Redis哨兵主要采用单独开一个进程进行监控Redis集群运行状态,在Redis编译安装完成后,源文件可以看到一个sentinel.conf文件这个就是哨兵的配置文件,Redis哨兵也类似于Redis主从,在集群中选举一个主服务器(Master),所有写入的数据由主服务器接收,然后同步到集群中的从服务器(Slave)上,但是哨兵比Redis主从更加智能的,在哨兵集群中,当主服务器(Master)出现故障,集群会自动重新选举一台主服务器,这样不需要人工干预,系统运行更加稳定
第三种:Redis
cluster,这个是本文主要讲解的类型,无论是Redis主从或者Redis哨兵,他们都有一个共同的问题,就是所有请求都是由一台服务器进行响应,既:主服务器(Master),如果请求/并发量太大,这台服务器将会成为瓶颈。而Redis
3.0以后提供了一个Redis cluster模式,它使用哈希槽分片,将所有数据分布在不同的服务器上。
1.2、Redis Cluster原理说明
1.2.1、Redis集群基础说明
在Redis 3.0版本以后,Redis发布了Redis Cluster。该集群主要支持搞并发和海量数据处理等优势,具体:①、自动分割数据到不同的节点上,②整个集群的部分节点失败或者不可达的情况下能够继续处理命令。具体解释如下:
Redis没有使用一致性hash,而是引入哈希槽的概念。Redis集群由16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置那个槽,集群的每个节点负责一部分hash槽,也就是说数据存放在hash槽里,而每个节点只负责部分hash槽(这样数据就存放在不同的节点)。
例如:A、B、C三个节点,
A节点负责0到5500号hash槽,
B节点负责5501到11000号hash槽,
C节点负责11001到16384号hash槽
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上.
如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可.
由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态
1.2.2、Redis 集群的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
不过当B和B1 都失败后,集群是不可用的.
1.2.3、关于Redis数据一致性(异步写)
Redis集群不能保证数据的强一致性。原因:
①、Redis集群采用异步写的方法,既:当客户端向Master写入一条数据后,Master给客户端返回一个执行结果,然后在操作Master和Slave之间的数据同步,这样当客户端完成写入并拿到Master返回的结果时(但Master还未来得及执行主从同步),Master出现宕机或网络不可达,就出现了数据不一致的情况。这也就是Redis的异步写。但是如果Redis集群采用同步写,那么整个集群的性能将大大下降(既:客户端写入数据后,Master先执行主从同步,然后在返回给客户端写入结果)

异步写 同步写
②、Redis集群出现网络脑裂,举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点,其中 A
、B 、C 为主节点, A1 、B1
、C1为A,B,C的从节点,还有一个客户端Z1假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点A 、C 、A1 、B1和
C1,小部分的一方则包含节点B和客户端 Z1,Z1仍然能够向主节点B中写入,
如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了(注意:在网络分裂出现期间,客户端Z1可以向主节点B发送写命令的最大时间是有限制的,这一时间限制称为节点超时时间(node
timeout),是Redis集群的一个重要的配置选项)
二、Redis Cluster搭建
2.1、基础环境介绍
Redis版本:3.2.8
Redis应用:在一台服务器上开启六个Redis实例,每个实例对应一个端口分别是:11000 12000 13000 14000 15000 16000,其中11000 12000 13000作为主服务器,14000 15000 16000作为从服务器
Redis关系架构图:

2.2、编译安装Redis 3.2.8
mkdir /app/src cd /app/src wget http://download.redis.io/releases/redis-3.2.8.tar.gz tar xf redis-3.2.8.tar.gz && cd redis-3.2.8 make && make install mkdir -p /usr/local/redis/bin mkdir -p /usr/local/redis/etc cp -rf /usr/local/bin/redis-* /usr/local/redis/bin/ find ./src/* -perm 775 | xargs -I '{}' cp {} /usr/local/redis/bin/ #拷贝相关命令到redis的bin目录 cp redis.conf /usr/local/redis/etc/11000.conf mkdir -p /app/redis/11000
2.3、修改redis相关配置文件
为了方便起见,Redis所有配置文件都是安装实例端口命名,数据目录也是以端口数为目录,例如:端口为11000的实例,配置文件为:11000.conf,数据目录:/app/redis/11000
vim /usr/local/redis/etc/11000.conf #由于配置文件内容比较多,所以本文只显示几个被修改了的参数 bind 127.0.0.1 #监听的IP地址,在实际生产环境中建议采用防火墙配置指定IP访问,或者修改Redis默认端口,因为Redis很容易被“挖矿” port 11000 #Redis使用端口,默认是6379 pidfile /app/redis/11000/11000.pid #Redis PID文件存放位置 loglevel notice #Redis 日志级别 logfile "/app/redis/11000/11000.log" #Redis 日志文件位置及日志文件名 #save 900 1 #禁用Redis 的rdb持久化改而使用aof持久化 #save 300 10 #save 60 10000 cluster-enabled yes #开启Redis集群,默认禁用 cluster-config-file nodes-11000.conf #Redis集群配置文件名,默认是没有的,在配置好集群后会自动创建,该文件位于数据目录下 cluster-node-timeout 5000 #这个就是上面基础部分介绍中提到的Redis集群中判断某个节点不可用的超时时间 appendonly yes #启用aof持久化方式,Redis默认支持两种持久化分别为:rdb、aof appendfilename "appendonly.aof" #aof持久化文件名
其他实例配置请参照上述配置文件,修改对应的数据
2.4、启动Redis实例
改完所以配置文件后,就可以启动相关Redis实例。命令如下:
/usr/local/redis/bin/redis-server /usr/local/redis/etc/11000.conf /usr/local/redis/bin/redis-server /usr/local/redis/etc/12000.conf /usr/local/redis/bin/redis-server /usr/local/redis/etc/13000.conf /usr/local/redis/bin/redis-server /usr/local/redis/etc/14000.conf /usr/local/redis/bin/redis-server /usr/local/redis/etc/15000.conf /usr/local/redis/bin/redis-server /usr/local/redis/etc/16000.conf
查看redis运行情况
ps aux | grep redis root 7473 0.0 0.0 133540 7572 ? Ssl 17:11 0:00 /usr/local/redis/bin/redis-server 127.0.0.1:11000 [cluster] root 7477 0.0 0.0 133540 7568 ? Ssl 17:11 0:00 /usr/local/redis/bin/redis-server 127.0.0.1:12000 [cluster] root 7481 0.0 0.0 133540 7568 ? Ssl 17:11 0:00 /usr/local/redis/bin/redis-server 127.0.0.1:13000 [cluster] root 7485 0.0 0.0 133540 7572 ? Ssl 17:11 0:00 /usr/local/redis/bin/redis-server 127.0.0.1:14000 [cluster] root 7489 0.0 0.0 133540 7572 ? Ssl 17:12 0:00 /usr/local/redis/bin/redis-server 127.0.0.1:15000 [cluster] root 7493 0.0 0.0 133540 7568 ? Ssl 17:12 0:00 /usr/local/redis/bin/redis-server 127.0.0.1:16000 [cluster] root 7497 0.0 0.0 103264 880 pts/0 S+ 17:13 0:00 grep redis
参考Redis日志
cat /app/redis/11000/11000.log 7473:M 13 Nov 17:11:41.435 * No cluster configuration found, I'm c53d065ad1ea2be86dcf6cd44cbff7e7d4b480b4 #实例打印的日志显示,因为nodes.conf文件不存在,所以每个节点都为它自身指定了一个新的ID,实例会一直使用同一个ID,从而在集群中保持一个独一无二(unique)的名字。
2.5、初始化Redis Cluster
/usr/local/redis/bin/redis-trib.rb create --replicas 1 127.0.0.1:11000 127.0.0.1:12000 127.0.0.1:13000 127.0.0.1:14000 127.0.0.1:15000 127.0.0.1:16000 #注意: #1、在执行该命令初始化时,如果报错,请参考本文中的错误解决方案 #2、在Redis集群初始化时,默认会把前一半的实例作为Master(例如:127.0.0.1:11000、127.0.0.1:12000、127.0.0.1:13000)后一半的作为Slave,如果服务器有性能差距,请一定注意该细节 #3、create参数:是创建Redis Cluster #4、--replicas 1参数:是为每个Master配置一个Slave >>> Creating cluster >>> Performing hash slots allocation on 6 nodes... Using 3 masters: #Redis自动配置三个Master节点 127.0.0.1:11000 127.0.0.1:12000 127.0.0.1:13000 Adding replica 127.0.0.1:14000 to 127.0.0.1:11000 #Redis自动配置三个Slave节点 Adding replica 127.0.0.1:15000 to 127.0.0.1:12000 Adding replica 127.0.0.1:16000 to 127.0.0.1:13000 M: c53d065ad1ea2be86dcf6cd44cbff7e7d4b480b4 127.0.0.1:11000 #表示该实例的状态M即Master,S即Slave slots:0-5460 (5461 slots) master M: 195689fe7fc0909170d20d5e9e918dee35694563 127.0.0.1:12000 slots:5461-10922 (5462 slots) master M: 221ab66bb8b03a11ae5abcf85c88adb6a33e2f08 127.0.0.1:13000 slots:10923-16383 (5461 slots) master S: 676c42d75c033ff82d0a14259b752e096c4c349c 127.0.0.1:14000 replicates c53d065ad1ea2be86dcf6cd44cbff7e7d4b480b4 S: 041ce2b79047d0b27242eb6f4cdffe469dd1423f 127.0.0.1:15000 replicates 195689fe7fc0909170d20d5e9e918dee35694563 S: ba58b6e88d258dcdfe3d3e1f4ec63f862a8b9595 127.0.0.1:16000 replicates 221ab66bb8b03a11ae5abcf85c88adb6a33e2f08 Can I set the above configuration? (type 'yes' to accept): yes #确定没有问题输入yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join... #Redis集群配置,同时分配主从节点关系 >>> Performing Cluster Check (using node 127.0.0.1:11000) M: c53d065ad1ea2be86dcf6cd44cbff7e7d4b480b4 127.0.0.1:11000 #本节点是主节点,它的从节点是127.0.0.1:14000,主要通过S(Slave)节点的replicates来确定。另外该主节点分配到的hash槽是0-5460 slots:0-5460 (5461 slots) master 1 additional replica(s) S: ba58b6e88d258dcdfe3d3e1f4ec63f862a8b9595 127.0.0.1:16000 slots: (0 slots) slave replicates 221ab66bb8b03a11ae5abcf85c88adb6a33e2f08 M: 221ab66bb8b03a11ae5abcf85c88adb6a33e2f08 127.0.0.1:13000 slots:10923-16383 (5461 slots) master 1 additional replica(s) S: 041ce2b79047d0b27242eb6f4cdffe469dd1423f 127.0.0.1:15000 slots: (0 slots) slave replicates 195689fe7fc0909170d20d5e9e918dee35694563 M: 195689fe7fc0909170d20d5e9e918dee35694563 127.0.0.1:12000 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: 676c42d75c033ff82d0a14259b752e096c4c349c 127.0.0.1:14000 slots: (0 slots) slave replicates c53d065ad1ea2be86dcf6cd44cbff7e7d4b480b4 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. #Redis Cluster建立完成
在查看Redis cluster中的主从节点关系时,除了上述方法,还可以查看Redis的日志。或者查看在配置文件参考cluster-config-file 的文件中,也可以看到相关信息
cat /app/redis/11000/11000.log 7473:M 13 Nov 17:43:32.437 # configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH 7473:M 13 Nov 17:43:32.462 # IP address for this node updated to 127.0.0.1 7473:M 13 Nov 17:43:36.669 * Slave 127.0.0.1:14000 asks for synchronization #表示该节点的从节点是127.0.0.1:14000 7473:M 13 Nov 17:43:36.669 * Full resync requested by slave 127.0.0.1:14000 7473:M 13 Nov 17:43:36.669 * Starting BGSAVE for SYNC with target: disk 7473:M 13 Nov 17:43:36.670 * Background saving started by pid 7793 7793:C 13 Nov 17:43:36.679 * DB saved on disk 7793:C 13 Nov 17:43:36.679 * RDB: 6 MB of memory used by copy-on-write 7473:M 13 Nov 17:43:36.770 * Background saving terminated with success 7473:M 13 Nov 17:43:36.770 * Synchronization with slave 127.0.0.1:14000 succeeded #表示主节点向从节点同步数据成功 7473:M 13 Nov 17:43:37.371 # Cluster state changed: ok #Redis集群的状态
2.6、客户工具说明
Redis 集群现阶段的一个问题是客户端实现很少。以下是一些我知道的实现:
redis-rb-cluster:是编写的Ruby实现, 用于作为是对redis-rb的一个简单包装,高效地实现了与集群进行通讯所需的最少语义(semantic)
redis-py-cluster:看上去是一个Python版本,这个项目有一段时间没有更新了,不过可以将这个项目用作学习集群的起点
Predis:曾经对早期的 Redis 集群有过一定的支持,但不确定它对集群的支持是否完整, 也不清楚它是否和最新版本的 Redis 集群兼容(因为新版的Redis集群将槽的数量从4k改为16k了)
Jedis:使用最多的时java客户端,Jedis最近添加了对集群的支持,详细请查看项目README中Jedis Cluster部分
StackExchange.Redis:提供对C#的支持(并且包括大部分.NET下面的语言,比如:VB,C#等等)
thunk-redis:提供对Node.js和io.js的支持
redis-cli:Redis unstable分支中的redis-cli程序实现了非常基本的集群支持,可以使用命令redis-cli -c来启动
2.7、客户端测试
/usr/local/redis/bin/redis-cli -c -p 11000 127.0.0.1:11000> SET name ray -> Redirected to slot [5798] located at 127.0.0.1:12000 #返回的结果,结果包含数据的执行结果、数据存放的槽、数据存放的Master节点 OK 127.0.0.1:12000> GET name "ray" 127.0.0.1:12000> KEYS * 1) "name"
三、Redis Cluster某台主节点故障
3.1、模拟灾难主服务器宕机
由于刚刚写入的数据位于127.0.0.1:12000主节点上,所以本次灾难就模拟127.0.0.1:12000主节点故障
ps aux | grep redis root 7473 0.0 0.1 135588 9776 ? Ssl 17:11 0:02 /usr/local/redis/bin/redis-server 127.0.0.1:11000 [cluster] root 7477 0.0 0.1 135588 9792 ? Ssl 17:11 0:02 /usr/local/redis/bin/redis-server 127.0.0.1:12000 [cluster] root 7481 0.0 0.1 135588 9768 ? Ssl 17:11 0:02 /usr/local/redis/bin/redis-server 127.0.0.1:13000 [cluster] root 7485 0.0 0.0 133540 7748 ? Ssl 17:11 0:03 /usr/local/redis/bin/redis-server 127.0.0.1:14000 [cluster] root 7489 0.0 0.0 133540 7756 ? Ssl 17:12 0:02 /usr/local/redis/bin/redis-server 127.0.0.1:15000 [cluster] root 7493 0.0 0.0 133540 7740 ? Ssl 17:12 0:02 /usr/local/redis/bin/redis-server 127.0.0.1:16000 [cluster] root 7534 0.0 0.0 100960 656 pts/1 S+ 17:33 0:00 tail -f /app/redis/11000/11000.log root 7873 0.0 0.0 100960 660 pts/2 S+ 18:35 0:00 tail -f /app/redis/12000/12000.log root 7893 0.0 0.0 100960 656 pts/3 S+ 18:35 0:00 tail -f /app/redis/15000/15000.log root 7895 0.0 0.0 103264 880 pts/0 S+ 18:35 0:00 grep redis kill -9 7477 #结束127.0.0.1:12000的进程
然后分别查看127.0.0.1:11000和127.0.0.1:15000(127.0.0.1:12000的从节点)的日志
查看127.0.0.1:11000节点日志
cat /app/redis/11000/11000.log 7473:M 13 Nov 18:36:05.795 * FAIL message received from 221ab66bb8b03a11ae5abcf85c88adb6a33e2f08 about 195689fe7fc0909170d20d5e9e918dee35694563 #标识221ab66bb8b03a11ae5abcf85c88adb6a33e2f08节点检查出195689fe7fc0909170d20d5e9e918dee35694563节点故障 7473:M 13 Nov 18:36:05.795 # Cluster state changed: fail #Redis集群失效 7473:M 13 Nov 18:36:06.799 # Failover auth granted to 041ce2b79047d0b27242eb6f4cdffe469dd1423f for epoch 7 #041ce2b79047d0b27242eb6f4cdffe469dd1423f升级为主节点 7473:M 13 Nov 18:36:06.838 # Cluster state changed: ok #Redis集群恢复
看127.0.0.1:15000节点日志
cat /app/redis/15000/15000.log 7489:S 13 Nov 18:35:59.894 # Connection with master lost. #标识主节点丢失/故障断开/不可达 7489:S 13 Nov 18:35:59.894 * Caching the disconnected master state. #判断15000的主节点(既12000)故障断开/不可达 7489:S 13 Nov 18:36:00.482 * Connecting to MASTER 127.0.0.1:12000 #重新尝试多次连接 7489:S 13 Nov 18:36:00.482 * MASTER <-> SLAVE sync started 7489:S 13 Nov 18:36:00.482 # Error condition on socket for SYNC: Connection refused #主从同步失败 7489:S 13 Nov 18:36:01.484 * Connecting to MASTER 127.0.0.1:12000 7489:S 13 Nov 18:36:01.484 * MASTER <-> SLAVE sync started 7489:S 13 Nov 18:36:01.484 # Error condition on socket for SYNC: Connection refused 7489:S 13 Nov 18:36:02.486 * Connecting to MASTER 127.0.0.1:12000 7489:S 13 Nov 18:36:02.486 * MASTER <-> SLAVE sync started 7489:S 13 Nov 18:36:02.486 # Error condition on socket for SYNC: Connection refused 7489:S 13 Nov 18:36:03.488 * Connecting to MASTER 127.0.0.1:12000 7489:S 13 Nov 18:36:03.489 * MASTER <-> SLAVE sync started 7489:S 13 Nov 18:36:03.489 # Error condition on socket for SYNC: Connection refused 7489:S 13 Nov 18:36:04.491 * Connecting to MASTER 127.0.0.1:12000 7489:S 13 Nov 18:36:04.491 * MASTER <-> SLAVE sync started 7489:S 13 Nov 18:36:04.492 # Error condition on socket for SYNC: Connection refused 7489:S 13 Nov 18:36:05.493 * Connecting to MASTER 127.0.0.1:12000 7489:S 13 Nov 18:36:05.493 * MASTER <-> SLAVE sync started 7489:S 13 Nov 18:36:05.494 # Error condition on socket for SYNC: Connection refused 7489:S 13 Nov 18:36:05.794 * FAIL message received from 221ab66bb8b03a11ae5abcf85c88adb6a33e2f08 about 195689fe7fc0909170d20d5e9e918dee35694563 #标识221ab66bb8b03a11ae5abcf85c88adb6a33e2f08节点检查出195689fe7fc0909170d20d5e9e918dee35694563节点故障 7489:S 13 Nov 18:36:05.795 # Cluster state changed: fail 7489:S 13 Nov 18:36:05.895 # Start of election delayed for 819 milliseconds (rank #0, offset 4507). #准备重新选举主节点 7489:S 13 Nov 18:36:06.496 * Connecting to MASTER 127.0.0.1:12000 7489:S 13 Nov 18:36:06.496 * MASTER <-> SLAVE sync started 7489:S 13 Nov 18:36:06.496 # Error condition on socket for SYNC: Connection refused 7489:S 13 Nov 18:36:06.797 # Starting a failover election for epoch 7. #启动故障迁移 7489:S 13 Nov 18:36:06.799 # Failover election won: I'm the new master. #重新选举,本节点(15000原从节点)变为新的主节点 7489:S 13 Nov 18:36:06.799 # configEpoch set to 7 after successful failover #故障迁移 7489:M 13 Nov 18:36:06.799 * Discarding previously cached master state. #放弃原来丢失的数据 7489:M 13 Nov 18:36:06.799 # Cluster state changed: ok #Redis集群恢复
使用redis-cli测试集群
/usr/local/redis/bin/redis-cli -c -p 11000 127.0.0.1:11000> keys * (empty list or set) 127.0.0.1:11000> get name -> Redirected to slot [5798] located at 127.0.0.1:15000 "ray"
首先在查看Redis中所有key时,表示没有key,这是因为我使用redis-cli连接的11000节点,但是使用get获取刚刚存放的name key时,获取成功
如果在配置Redis集群时没有启动从节点,当一个主节点宕机后,整个集群环境将变为不可用
3.2、故障恢复
在完成上述灾难后,我们再次启动12000节点,然后redis-cli -c -p 12000 登陆该节点查看相关信
/usr/local/redis/bin/redis-cli -c -p 12000 ...... # Replication role:slave master_host:127.0.0.1 master_port:15000 master_link_status:up master_last_io_seconds_ago:4 master_sync_in_progress:0 slave_repl_offset:99 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 .....
可以看到该节点已恢复,但是变为了15000的从节点,于之前的主从关系刚好相反,这也是为了Redis集群更加稳定,因为当原来的主节点恢复后如果在重新进行选举,那么Redis集群会反复一段时间不可用
四、错误
错误一:
/usr/bin/env: ruby: No such file or directory
解决方案:
该错误是因为节点没有安装ruby,执行:
yum install -y ruby
错误二:
/usr/local/redis/bin/redis-trib.rb:24:in `require': no such file to load -- rubygems (LoadError) from /usr/local/redis/bin/redis-trib.rb:24
解决方案:
yum install rubygems -y
错误三:
/usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `gem_original_require': no such file to load -- redis (LoadError) from /usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `require' from /usr/local/redis/bin/redis-trib.rb:2
解决方案(redis-3.2.1.gem本地下载):
gem install redis –version 3.0.0 #或: wget https://rubygems.global.ssl.fastly.net/gems/redis-3.2.1.gem gem install -l ./redis-3.2.1.gem
五、说明
至此,Redis整个集群搭建完成,稍后会更新关于Redis Cluster操作方法以及相关节点添加删除
参考链接(致谢):
http://www.redis.cn/topics/cluster-tutorial.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号