主题模型TopicModel:主题模型LDA的应用
http://blog.csdn.net/pipisorry/article/details/45665779
主题模型LDA的应用
拿到这些topic后继续后面的这些应用怎么做呢:
除了推断出这些主题,LDA还可以推断每篇文章在主题上的分布。例如,X文章大概有60%在讨论“空间探索”,30%关于“电脑”,10%关于其他主题。
这些主题分布可以有多种用途:
聚类: 主题是聚类中心,文章和多个类簇(主题)关联。聚类对整理和总结文章集合很有帮助。参看Blei教授和Lafferty教授对于Science杂志的文章生成的总结。点击一个主题,看到该主题下一系列文章。
特征生成:LDA可以生成特征供其他机器学习算法使用。如前所述,LDA为每一篇文章推断一个主题分布;K个主题即是K个数值特征。这些特征可以被用在像逻辑回归或者决策树这样的算法中用于预测任务。
降维:每篇文章在主题上的分布提供了一个文章的简洁总结。在这个降维了的特征空间中进行文章比较,比在原始的词汇的特征空间中更有意义。
排序:The very best ways to sort large databases of unstructured text is to use a technique called Latent Dirichlet allocation (LDA).
应用于推荐系统
在使用LDA(Latent Dirichlet Allocation)计算物品的内容相似度时,我们可以先计算出物品在话题上的分布,然后利用两个物品的话题分布计算物品的相似度。比如,如果两个物品的话题分布相似,则认为两个物品具有较高的相似度,反之则认为两个物品的相似度较低。计算分布的相似度可以利用KL散度来计算:
DKL(p||q)=∑i∈Xp(i)ln(p(i)/q(i),其中p和q是两个分布,KL散度越大说明分布的相似度越低。
隐语义模型LFM和LSI,LDA,Topic Model其实都属于隐含语义分析技术,是一类概念,他们在本质上是相通的,都是找出潜在的主题或分类。这些技术一开始都是在文本挖掘领域中提出来的,近些年它们也被不断应用到其他领域中,并得到了不错的应用效果。比如,在推荐系统中它能够基于用户的行为对item进行自动聚类,也就是把item划分到不同类别/主题,这些主题/类别可以理解为用户的兴趣。
对于一个用户来说,他们可能有不同的兴趣。就以作者举的豆瓣书单的例子来说,用户A会关注数学,历史,计算机方面的书,用户B喜欢机器学习,编程语言,离散数学方面的书, 用户C喜欢大师Knuth, Jiawei Han等人的著作。那我们在推荐的时候,肯定是向用户推荐他感兴趣的类别下的图书。那么前提是我们要对所有item(图书)进行分类。那如何分呢?大家注意到没有,分类标准这个东西是因人而异的,每个用户的想法都不一样。拿B用户来说,他喜欢的三个类别其实都可以算作是计算机方面的书籍,也就是说B的分类粒度要比A小;拿离散数学来讲,他既可以算作数学,也可当做计算机方面的类别,也就是说有些item不能简单的将其划归到确定的单一类别;拿C用户来说,他倾向的是书的作者,只看某几个特定作者的书,那么跟A,B相比它的分类角度就完全不同了。
显然我们不能靠由单个人(编辑)或team的主观想法建立起来的分类标准对整个平台用户喜好进行标准化。
此外我们还需要注意的两个问题:
- 我们在可见的用户书单中归结出3个类别,不等于该用户就只喜欢这3类,对其他类别的书就一点兴趣也没有。也就是说,我们需要了解用户对于所有类别的兴趣度。
- 对于一个给定的类来说,我们需要确定这个类中每本书属于该类别的权重。权重有助于我们确定该推荐哪些书给用户。
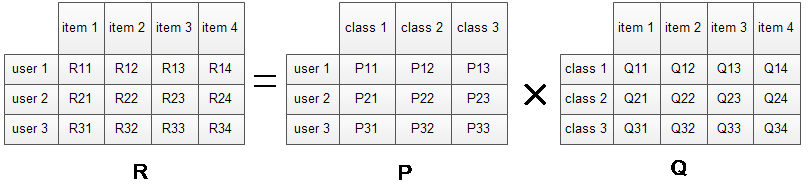
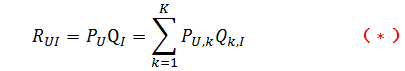
- 我们不需要关心分类的角度,结果都是基于用户行为统计自动聚类的,全凭数据自己说了算。
- 不需要关心分类粒度的问题,通过设置LFM的最终分类数就可控制粒度,分类数越大,粒度约细。
- 对于一个item,并不是明确的划分到某一类,而是计算其属于每一类的概率,是一种标准的软分类。
- 对于一个user,我们可以得到他对于每一类的兴趣度,而不是只关心可见列表中的那几个类。
- 对于每一个class,我们可以得到类中每个item的权重,越能代表这个类的item,权重越高。
那么,接下去的问题就是如何计算矩阵P和矩阵Q中参数值。一般做法就是最优化损失函数来求参数。在定义损失函数之前,我们需要准备一下数据集并对兴趣度的取值做一说明。
数据集应该包含所有的user和他们有过行为的(也就是喜欢)的item。所有的这些item构成了一个item全集。对于每个user来说,我们把他有过行为的item称为正样本,规定兴趣度RUI=1,此外我们还需要从item全集中随机抽样,选取与正样本数量相当的样本作为负样本,规定兴趣度为RUI=0。因此,兴趣的取值范围为[0,1]。
采样之后原有的数据集得到扩充,得到一个新的user-item集K={(U,I)},其中如果(U,I)是正样本,则RUI=1,否则RUI=0。损失函数如下所示:
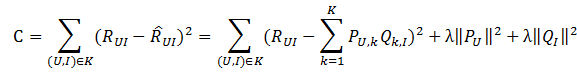
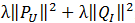 是用来防止过拟合的正则化项,λ需要根据具体应用场景反复实验得到。损失函数的优化使用随机梯度下降算法:
是用来防止过拟合的正则化项,λ需要根据具体应用场景反复实验得到。损失函数的优化使用随机梯度下降算法:- 通过求参数PUK和QKI的偏导确定最快的下降方向;
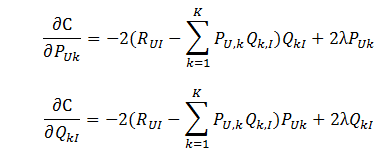
- 迭代计算不断优化参数(迭代次数事先人为设置),直到参数收敛。
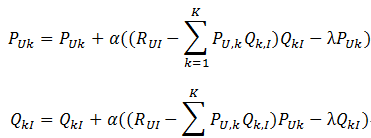
其中,α是学习速率,α越大,迭代下降的越快。α和λ一样,也需要根据实际的应用场景反复实验得到。本书中,作者在MovieLens数据集上进行实验,他取分类数F=100,α=0.02,λ=0.01。
【注意】:书中在上面四个式子中都缺少了
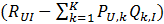
综上所述,执行LFM需要:
- 根据数据集初始化P和Q矩阵(这是我暂时没有弄懂的地方,这个初始化过程到底是怎么样进行的,还恳请各位童鞋予以赐教。)
- 确定4个参数:分类数F,迭代次数N,学习速率α,正则化参数λ。
LFM的伪代码可以表示如下:
- def LFM(user_items, F, N, alpha, lambda):
- #初始化P,Q矩阵
- [P, Q] = InitModel(user_items, F)
- #开始迭代
- For step in range(0, N):
- #从数据集中依次取出user以及该user喜欢的iterms集
- for user, items in user_item.iterms():
- #随机抽样,为user抽取与items数量相当的负样本,并将正负样本合并,用于优化计算
- samples = RandSelectNegativeSamples(items)
- #依次获取item和user对该item的兴趣度
- for item, rui in samples.items():
- #根据当前参数计算误差
- eui = eui - Predict(user, item)
- #优化参数
- for f in range(0, F):
- P[user][f] += alpha * (eui * Q[f][item] - lambda * P[user][f])
- Q[f][item] += alpha * (eui * P[user][f] - lambda * Q[f][item])
- #每次迭代完后,都要降低学习速率。一开始的时候由于离最优值相差甚远,因此快速下降;
- #当优化到一定程度后,就需要放慢学习速率,慢慢的接近最优值。
- alpha *= 0.9
总结来说,LFM具有成熟的理论基础,它是一个纯种的学习算法,通过最优化理论来优化指定的参数,建立最优的模型。
[使用LFM(Latent factor model)隐语义模型进行Top-N推荐]
LDA主题模型用于BUG修复人推荐
[LDA主题模型用于BUG修复人推荐《DRETOM: developer recommendation based on topic models for bug resolution》]
from:http://blog.csdn.net/pipisorry/article/details/45665779
ref:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号