1.字符
| 表达式 | 释义 |
|---|
| x |
字符 x |
| \\ |
反斜线字符 |
| \0n |
带有八进制值 0 的字符 n (0 <= n <= 7) |
| \0nn |
带有八进制值 0 的字符 nn (0 <= n <= 7) |
| \0mnn |
带有八进制值 0 的字符 mnn(0 <= m <= 3、0 <= n <= 7) |
| \xhh |
带有十六进制值 0x 的字符 hh |
| \uhhhh |
带有十六进制值 0x 的字符 hhhh |
| \t |
制表符 ('\u0009') |
| \n |
新行(换行)符 ('\u000A') |
| \r |
回车符 ('\u000D') |
| \f |
换页符 ('\u000C') |
| \a |
| \e |
转义符 ('\u001B') |
| \cx |
对应于 x 的控制符 |
2.字符类
| 表达式 | 释义 |
|---|
| [abc] |
a、b 或 c(简单类) |
| [^abc] |
任何字符,除了 a、b 或 c(否定) |
| [a-zA-Z] |
a 到 z 或 A 到 Z,两头的字母包括在内(范围) |
| [a-d[m-p]] |
a 到 d 或 m 到 p:[a-dm-p](并集) |
| [a-z&&[def]] |
d、e 或 f(交集) |
| [a-z&&[^bc]] |
a 到 z,除了 b 和 c:[ad-z](减去) |
| [a-z&&[^m-p]] |
a 到 z,而非 m 到 p:[a-lq-z](减去) |
自符类,可以表示任意一个字符,注意是"一个字符"例如 [abc] ,匹配的是 a或b或c, 并不是匹配abc这样的字符串。如需匹配字符组可使用(abc)的方式去实现,或者更笨一些[a][b][c]。你可以在字符类中使用 -表示识范围 &&表示and ^ 不包括
p("abc".matches("[abc]")); // false p方法只是打印结果
p("a".matches("[abc]")); //true
p("abc".matches("(abc)")); //true
p("abc".matches("[a][b][c]")); //true
3.预定义字符类
| 表达式 | 释义 |
|---|
| . |
任何字符(与行结束符可能匹配也可能不匹配) |
| \d |
数字:[0-9] |
| \D |
非数字: [^0-9] |
| \s |
空白字符:[ \t\n\x0B\f\r] |
| \S |
非空白字符:[^\s] |
| \w |
单词字符:[a-zA-Z_0-9] |
| \W |
非单词字符:[^\w] |
4.特殊字符类(不推荐使用)
1)java.lang.Character 类(简单的 java 字符类型)
| 表达式 | 释义 |
|---|
| \p{javaLowerCase} |
等效于 java.lang.Character.isLowerCase() |
| \p{javaUpperCase} |
等效于 java.lang.Character.isUpperCase() |
| \p{javaWhitespace} |
等效于 java.lang.Character.isWhitespace() |
| \p{javaMirrored} |
等效于 java.lang.Character.isMirrored() |
2)Unicode 块和类别的类
p("abcd".matches("\\p{javaLowerCase}")); //false
p("abcd".matches("\\p{javaLowerCase}+")); //true
p("a".matches("\\p{javaLowerCase}+")); //true
p("$".matches("\\p{Sc}+")); //true
p("¥".matches("\\p{Sc}+")); //true
p("$10.12".matches("\\p{Sc}\\d+\\.[0-9]{0,2}")); //true
3)POSIX 字符类(仅 US-ASCII)
详细参照:jdk中文文档:java.util.regex.Pattern类
5.数量词
| Greedy(贪婪型) | Reluctant(勉强型) | Possessive(占有型) | 释义 |
|---|
| X? |
X?? |
X?+ |
一次或一次也没有 |
| X* |
X*? |
X*+ |
零次或多次 |
| X+ |
X+? |
X++ |
一次或多次 |
| X{n} |
X{n}? |
X{n}+ |
恰好 n 次 |
| X{n,} |
X{n,}? |
X{n,}+ |
至少 n 次 |
| X{n,m} |
X{n,m}? |
X{n,m}+ |
至少 n 次,但是不超过 m 次 |
贪婪型:不做特殊设置时,两次是贪婪的,例如X{n,m},贪婪模式会尽可能多的进行匹配,如下例中所示,匹配数字3到6个之间,如果量词是贪婪的,那么当它匹配到第一次出现3个数字的时候并不会停止,而是继续向后匹配,知道匹配到第6个字符,此时第一次匹配完成,从第6个字符后开始第二次匹配,这就是贪婪模式,尽可能多吃。
Pattern p = Pattern.compile("\\d{3,6}");
Matcher matcher = p.matcher("123423 a3b 235");
while (matcher.find()){
p("Greedy(贪婪模式) start="+matcher.start()+" end="+matcher.end());
}
//Greedy(贪婪模式) start=0 end=6
//Greedy(贪婪模式) start=11 end=14
勉强型: 例如X{n,m}?,勉强模式会尽可能少匹配,如下例中所示,匹配数字3到6个之间,如果量词是勉强的,那么当它匹配到第一次出现3个数字的时候就完成了第一次匹配完成,从第3个字符到第6个字符开始第二次匹配,这就是勉强模式,尽可能少吃。
Pattern p = Pattern.compile("\\d{3,6}?");
Matcher matcher = p.matcher("123423 a3b 235");
while (matcher.find()){
p("Greedy(勉强模式) start="+matcher.start()+" end="+matcher.end());
}
//Greedy(勉强模式) start=0 end=3
//Greedy(勉强模式) start=3 end=6
//Greedy(勉强模式) start=11 end=14
占用型,只有java语言可以使用,因此这里不做探讨
6.边界表达式
| 表达式 | 释义 |
|---|
| ^ |
行的开头 |
| $ |
行的结尾 |
| \b |
单词边界 |
| \B |
非单词边界 |
| \A |
输入的开头 |
| \Z |
输入的结尾,仅用于最后的结束符(如果有的话) |
| \z |
输入的结尾 |
| \G |
上一个匹配的结尾 |
public static void pRex(String str, Pattern pattern){
Matcher matcher = pattern.matcher(str);
System.err.println("---------------"+matcher.pattern().toString()+"-----------------------");
while (matcher.find()){
System.err.println("【"+matcher.start()+","+matcher.end()+"】-->"+matcher.group());
}
}
String mulStr = "my name is jack\nI am 200 years old\nmy school jack\n";
Pattern p1 = Pattern.compile("^m");
Pattern p2 = Pattern.compile("^m",Pattern.MULTILINE);
Pattern p3 = Pattern.compile("\\A^m",Pattern.MULTILINE);
// 默认模式为单行模式,把多行文本看成一个字符串,因此匹配开头第一个m
pRex(mulStr,p1);
// p2使用Pattern.MULTILINE开启多行模式,每一行相当与一个字符串,因此匹配到第一行的m第三行的m
//-->m
//-->m
pRex(mulStr,p2);
//-->m 在多行模式 在^的前面使用\A则会匹配第一行,第一个m
pRex(mulStr,p3);
//$匹配最后的字符,原理同^,只演示多行情况 \\z和\\Z区别:\\Z匹配的时候在输入的结尾处有和没有终止子都能匹配
Pattern p4 = Pattern.compile("k$\\Z",Pattern.MULTILINE);
pRex(mulStr,p4);
mulStr= "my name is jack\nI am 200 years old\nmy school jack\n";
Pattern p5 = Pattern.compile("k$\\z",Pattern.MULTILINE);
pRex(mulStr,p5);
mulStr = "a a abanan aca a@cb a_a!";
//\b 字符的旁边不能是\w \B就是字符旁边只能是\w \w <==> [a-zA-Z_0-9]
Pattern p6 = Pattern.compile("a\\B");
pRex(mulStr,p6);
Pattern p7 = Pattern.compile("a\\b");
pRex(mulStr,p7);
结果:
---------------^m-----------------------
【0,1】-->m
---------------^m-----------------------
【0,1】-->m
【35,36】-->m
---------------\A^m-----------------------
【0,1】-->m
---------------k$\Z-----------------------
【48,49】-->k
---------------k$\z-----------------------
---------------a\B-----------------------
【4,5】-->a
【6,7】-->a
【8,9】-->a
【11,12】-->a
【20,21】-->a
---------------a\b-----------------------
【0,1】-->a
【2,3】-->a
【13,14】-->a
【15,16】-->a
【22,23】-->a
捕获组及反向引用
//捕获组/反向引用 捕获可以看作一个字符串类 当捕获组很复杂的时候,反向引用的标号以左括号为准
mulStr = "gogo toto todo goto";
Pattern p8 = Pattern.compile("([a-z]){2}");
pRex(mulStr,p8);
//([a-z]{2})\1� <==> [a-z]{2}[a-z]{2}�
Pattern p9 = Pattern.compile("([a-z]{2})\\1");
pRex(mulStr,p9);
结果:
---------------([a-z]){2}-----------------------
【0,2】-->go
【2,4】-->go
【5,7】-->to
【7,9】-->to
【10,12】-->to
【12,14】-->do
【15,17】-->go
【17,19】-->to
---------------([a-z]{2})\1-----------------------
【0,4】-->gogo
【5,9】-->toto
捕获组编号选取
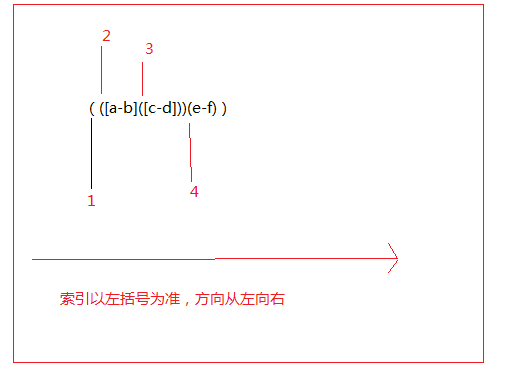
注意:使用捕获组,捕获组会把捕获的字符串加载到内存当中,有些情况不得不使用捕获组,也不需要捕获的字符串,那么这时候就需使用非捕获组来减少内存的开销。非捕获组表达式:(?:)
7.预搜索(零竞断言)
-只进行子表达式的匹配,匹配内容不计入最终的匹配结果,是零宽度 --引自:尚学堂
-这个位置应该符合某个条件?判断当前位置的前后字符,是否符合指定的条件,但不匹配前后的字符.是对位置的匹配。--引自:尚学堂
-正则表达式匹配过程中,如果子表达配到的是字符内容,而非位置,并被 保存至撮终的匹配结果中,那么这个子表达式是占有字符的;如果子表达式匹配的仅仅是位置,或者匹配内容并不保存到最终匹配结果中,那么就认为这个子表达式是零宽度的。占有字符还是零宽度,是针对匹配的 内容是否保存到最终的匹配结果中而言的 --引自:尚学堂
| (?=exp) |
断言自身出现的位置的后面能匹配表达式exp |
| (?<=exp) |
断言自身出现的位置的前面能匹配表达式exp |
| (?!exp) |
断言自身出现的位置的后面不能匹配表达式exp |
| (?<!exp) |
断言自身出现的位置的前面不能匹配表达式exp |
mulStr = "123a abcd abcd1234 123abcd a123gfh";
Pattern p10 = Pattern.compile("[\\w\\S]+(?=\\d)");
pRex(mulStr,p10);
Pattern p11 = Pattern.compile("[a-z]+(?=\\d)");
pRex(mulStr,p11);
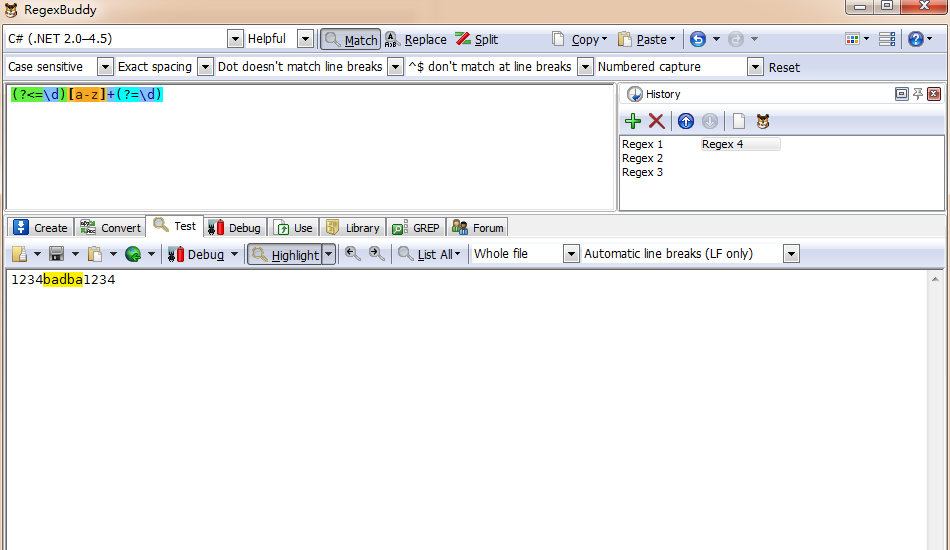
Pattern p12 = Pattern.compile("[a-z]+(?<=\\d)"); // 需要放置[a-z]+前面,
pRex(mulStr,p12);
Pattern p13 = Pattern.compile("(?<=\\d)[a-z]+"); // 需要放置[a-z]+前面,
pRex(mulStr,p13);
结果:
---------------[a-z]+(?<=\d)-----------------------
---------------(?<=\d)[a-z]+-----------------------
【3,4】-->a
【22,26】-->abcd
【31,34】-->gfh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号