Java Core(第 11 版)笔记
Java Core[1][2]
第1章 Java程序设计概述
第2章 Java程序设计环境
第3章 Java的基本程序设计结构
3.1.一个简单的Java应用程序
- 在Java1.4及以后版本,main方法必须为public。
- 如果希望在终止程序时返回其它的退出码,使用
System.exit。
3.2.注释
3.3.数据类型
- Java的8种基本类型:int、short、long、byte、float、double、char、boolean。无任何unsigned形式,要使用unsigned byte可使用
Byte.toUnsingedInt(b),得到0-255的int值,处理完后在转换为byte。 - 在十六进制中,使用p来表示指数。
Double.POSITIVE_INFINITY、Double.NEGATIVE_INFINITY、Double.NaN分别表示正无穷大、负无穷大、NaN。正数/0为Double.POSITIVE_INFINITY,0/0或者负数平方根为NaN。非数值的值都认为是不相同的,因此不要使用x == Double.NaN而使用Double.isNaN(x)。- 在Java中,char类型描述了UTF-16编码中的一个代码单元。
3.4.变量与常量
-
声明一个变量后,必须使用赋值语句对其显示初始化。使用未初始化的变量的值被Java编译器认为是错误的。
-
在 Java 中不区分变量的定义与声明。
-
const是Java的保留字,但目前并没有使用。在Java中,必须使用final定义常量。
3.5.运算符
-
整数被0除将会得到一个异常,而浮点数被0除将会得到无穷大或NaN的结果。
-
使用strictfp关键字标记的方法必须使用严格的浮点运算来生成可再生的结果。
-
n % 2中,n(int类型)为负,这个表达式则为-1。 -
如果一个计算溢出,数学运算符只是悄悄地返回错误结果而不做任何提醒。如
1_000_000_000 * 3返回-1294867296。使用Math.multiplyExact(1_000_000_000, 3)可抛出异常。 -
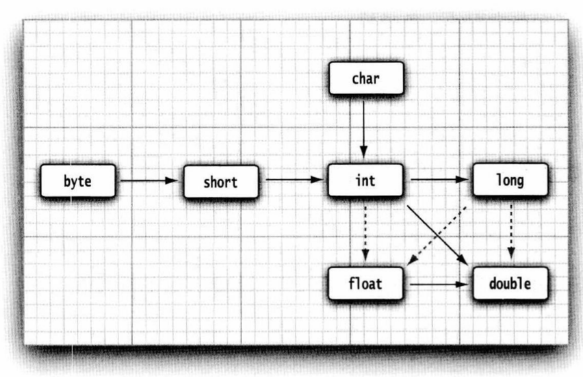
数值之间的合法转换:
![]()
虚线箭头表示可能有精度损失。
-
对浮点数舍入运算使用
Math.round(x)方法:int nx = (int) Math.round(9.997)。round方法返回long类型。 -
>>>运算符使用0填充高位,>>使用符号位填充高位,不存在<<<运算符。移位运算符的右操作符要完成模32(long为64)的运算。如1 << 35等同于1 << 3。
3.6.字符串
-
如果需要把多个字符串放在一起,用一个界定符分隔,使用join方法。如
String all = String.join(" / ", "S", "M", "L", "XL");。 -
Java11提供repeat方法:
String repeated = "Java".repeat(3);。 -
一定不要使用
==检测两个字符串是否相等。只有字符串字面量是共享的,而+或substring等操作得到的字符串不共享。 -
Java字符串由char值序列组成。
虚拟机不一定把字符串实现为代码单元序列。在Java9中,只包含单字节代码单元的字符串使用byte数组实现,其它字符串使用char数组。
-
StringBuffer运行多线程的方式添加或删除字符。如果所有字符串编辑操作都在单个线程中进行,使用StringBuilder。
3.7.输入与输出
- 当使用类不是定义在基本java.lang包中时,一定要使用import指令导入相应的包。
- 将对象转换为字符串,对于实现了Formattable接口的任意对象,将调用这个对象的formatTo方法,否则调用toString方法。
- 读取文本文件时,省略字符编码会使用运行这个Java程序的机器的默认编码。当指定一个相对文件名时,文件位于相对于Java虚拟机启动目录的位置。
3.8.控制流程
- 编译代码时,添加
-Xlint:fallthrough可对于switch分支缺少break语句时编译器会发出警告信息,使用@SuppressWarning("fallthrough")的除外。 - 当在switch语句中使用枚举常量时,不必再每个标签中指明枚举名。
3.9.大数
- BigInteger和BigDecimal实现任意精度的整数运算和浮点数运算。但不能使用算术运算符处理大数,而使用大数类中的方法。
- Java并没有提供运算符重载功能,但他重载了字符串的+运算符。
3.10.数组
-
长度为0的数组与null并不相同。
-
创建一个数组时,所有元素都被初始化为0/false/null。获得数组长度可使用
array.length。 -
for each循环可适用于一个数组或是实现了Iterable接口的类对象。
-
数组拷贝可使用Arrays类的copyof方法。
-
在Java应用程序的main方法中,程序名并未存储在args数组中。
-
Arrays的sort方法使用了优化的快速排序算法。
-
想要快速打印一个二维数组的数据元素列表,可使用
System.out.println(Arrays.deepToString(a));。 -
Java中,
double [][] balances = new double[10][6];相当于C++的:double** balances = new double*[10]; for (i = 0; i < 10; i++) { balances[i] = new double[6]; }对于不规则数组,只能单独地分配行数组。
第4章 对象与类
4.1.面向对象程序设计概述
4.2.使用预定义类
- 可以把Java中的对象变量看作类似于C++的对象指针。
- 在Java中,必须使用clone方法获得对象的完整副本。
- 标准Java类库分别包含了几个时间相关类:表示时间点的Date类、日历表示法表示日期的LocalDate类和GregorianCalendar类。不要使用构造器来构造LocalDate类对象,应当使用静态工厂方法,他会代表你使用构造器。LocalDate的plusDays方法返回新类,GregorianCalendar的add是一个更改器方法。
4.3.用户自定义类
-
源文件名必须与public类的名字相匹配,一个源文件只能有一个公共类,但可以有任意数目的非公共类。
-
不要在构造器中定义与实列字段同名的局部变量。
-
不要对数值类型使用var。var关键字只能用于方法中的局部变量,参数和字段的类型必须声明。
-
if (n == null) name = "unknown"; else name = n;可使用name = Objects.requireNonNullElse(n, "unknown");代替。而requireNonNull方法则会直接拒绝null参数。 -
Java中的所有方法必须在类中定义,是否为内联方法是Java虚拟机的任务。
-
不要编写返回可变对象引用的访问器方法。如果需要返回一个可变对象的引用,首先应该对它进行clone。
class Employee { ... public Date getHireDay() { return (Date) hireDay.clone(); } ... } -
对于以下方法是可行的:
class Employee { ... public boolean equals(Employee other) { return name.equals(other.name); } ... }对于
harry.equals(boss)中,方法访问harry的私有字段肯定是可以的,而对于boss的私有字段,由于boss是Employee类型的对象,equals是Employee的方法,所以访问boss的私有字段也是可以的。 -
final关键字只是表示在变量中的对象引用不会再指示另一个不同的对象,但该对象仍然可以修改。
4.4.静态字段与静态方法
- System的setOut是一个原生方法(native),原生方法可以绕过Java语言的访问控制机制,所以它可修改被初始化为null的out(
public static final PrintStream out = null;)。
4.5.方法参数
- Java总是采用按值调用。对象引用是按值传递的。
4.6.对象构造
- 如果在构造器中没有显示地为字段设置初值,那么就会被自动地赋为默认值0/false/null。
C++中,一个构造器不能调用另一个构造器。
4.7.包
- Java中的package和import语句类似于C++中的namespace和using指令。
- 从1.2版开始,JDK的实现者修改了类加载器,明确地禁止加载包名以“java.”开头地用户自定义地类。
4.8.JAR文件
4.9.文档注释
4.10.类设计技巧
第5章 继承
5.1.类、超类和子类
-
Java中所有继承都是公共继承。
-
super不是一个对象的引用,例如不能将其赋给另一个变量。它只是一个指示编译器调用超类方法的特殊关键字。
-
如果子类构造器没有显式调用超类构造器,将自动地调用超类地无参构造器。
-
Java中动态绑定是默认行为,如果不希望让某一个方法是virtual,可以将其标记为final。
-
允许子类将覆盖方法地返回类型改为原返回类型地子类型,被称为有可协变的返回类型。
-
如果方法是private、static、final或者构造器,那么编译器将可以准确地知道应该调用那个方法,这称为静态绑定。
-
在覆盖一个方法时,子类方法不能低于超类方法地可见性。
-
final类中的所有方法自动称为final方法,不包括字段。
-
Java中的
Manager boss = (Manager) staff[1];类似C++的Manager* boss = dynamic<Manager*>(staff[1]);,前者强制类型转换失败时会抛出异常,后者则是返回null,可以用以下方式来完成类型测试与类型转换:if (staff[1] instanceof Manager) { Manager boss = (Manager) staff[1]; ... }Manager* boss = dynamic<Manager*>(staff[1]); if (boss != nullptr) { ... } -
包含抽象方法的类本身必须被声明为抽象的。即是不含抽象方法,也可将类声明为抽象类。抽象类不能实例化。
5.2.Object:所有类的超类
-
在Java中,只有基本类型不是对象。所有数组类型都扩展了Object类。
-
比较两个对象时,防止出现null,可使用
Objects.equals方法。 -
Java语言规范要求equals方法具有下面的特征:
- 自反性:对于任何非空引用x,
x.equals(x)应该返回true。 - 对称性:对于任何引用x和y,当且仅当
y.equals(x)返回true时,x.equals(y)返回true。 - 传递性:对于任何引用x、y和z,如果
x.equals(y)返回true、y.equals(z)返回true,那么x.equals(z)也应该返回true。 - 一致性:如果x和y引用对象没有发生变化,反复调用
x.equals(y)应该返回相同的结果。 - 对于任何非空引用x,
x.equals(null)应该返回false。
如果子类可以有自己相等性的概念,那么对称性需求将强制使用getClass检测。如果超类决定相等性概念,那么就可以使用instanceof检测,这样可以在不同子类的对象之间进行比较。
以下给出编写一个完美equals方法的建议:
-
显式参数命名为otherObject(Object类),稍后需要将其强制转换为另一个名为other的变量。
-
if (this == otherObject) return false; -
if (otherObject == null) return false; -
如果equals语义可以在子类中改变,使用
if (getClass() != otherObject.getClass()) return false;,如果所有子类都具有相同的相等性语言,使用if (!(otherObject instanceof ClassName)) return false; -
ClassName other = (ClassName) otherObject;。 -
根据相等性概念的要求来比较字段,使用
==比较基本类型字段,使用Objects.equals比较对象字段。return field1 == other.field1 && Objects.equals(field2, other.field2) && ...;
- 自反性:对于任何非空引用x,
-
字符串的散列码是由内容导出的,对象是由对象的存储地址导出的。
-
计算hash时,最好使用null安全的
Objects.hashCode(x)而不是x.hash()。 -
equals与hashCode的定义必须相容。
-
Arrays.hashCode方法计算数组的散列码是用数组元素。
5.3.泛型数组列表
- 使用ArrayList类,在填充数组前可使用ensureCapacity方法来确保数组长度,以免填充数组时带来的数组copy开销。一旦确认数组列表大小将保持恒定,不在发生变化,就可调用trimToSize方法。
- **将原始ArrayList赋给类型化ArrayList会得到警告,即使使用强制类型转化。出于兼容性考虑,编译器检查到没有发现违反规则的现象后,所有类型化数组列表转换成原始ArrayList对象,程序运行时,虚拟机中没有类型参数,所以ArrayList与ArrayList<...>执行相同的运行时检查。 **
5.4.对象包装器与自动装箱
-
自动装箱规范要求boolean、byte、小于127的char、-128到127之间的short和int被包装到固定的对象中。所以使用
==不一定相等,使用equals更好。 -
装箱、拆箱是编译器的工作而不是虚拟机。
-
Integer对象是不可变的。要想修改数值可使用持有者类型,如IntHolder、BooleanHoulder等(位于org.omg.CORBA包,在JDK11已被移除),如:
public static void triple(IntHolder x) { x.value = 3 * x.value; }
5.5.参数数量可变的方法
5.6.枚举类
- 枚举类的构造器总是私有的,可以省略private修饰符。所有的枚举类型都是Enum的子类。
5.7.反射
-
T.class中T可以是void关键字。 -
Class对象实际上表示的一个类型,可能是类也可能不是,如int不是类,但int.class是一个Class对象。
-
Class其实是泛型类。
-
鉴于历史原因,Class的getName方法作用数组会返回奇怪的名字,如
[Ljava.lang.Double;。 -
虚拟机为每一个类型管理唯一的一个Class对象,因此可以使用
==比较。 -
Class类似于C++的type_info类,但功能更全面,getClass方法等价于C++的typeid运算符。
-
Class类中的getFields、getMethods、getConstructors方法将分别返回这个类支持的公共字段、方法和构造器数组,包括超类的。Class类中的getDeclareFields、getDeclareMethods、getDeclareConstructors方法返回类中的所有字段、方法和构造器数组,不包括超类的。
-
反射机制的默认行为受限于Java的访问控制,不过可使用setAccessible方法覆盖Java的访问控制。如果不允许访问(访问可以被模块系统或安全管理器拒绝),setAccessible调用会抛出异常。
-
一个copy数组的函数:
public static Object goodCopyOf(Object a, int newLength) { Class cl = a.getClass(); if (!cl.isArray()) return null; Class componentType = cl.getComponentType(); int length = Array.getLength(a); Object newArray = Array.newInstance(componentType, newLength); System.arraycopy(a, 0, newArray, 0, Math.min(length, newLength)); return newArray; }首先这里数组参数为Object,而不是Object[],因为基本数据类型数组可以转换为Object而不能转换为Object[]。其次,新数组中存储类型为原本数组中存储的类型而不是Object,为了返回数组后能够成功强制类型转换。
-
invoke方法:
Object invoke(Object obj, Object... args),第一个参数是隐式参数,其余的对象提供了显式参数,对于静态方法第一个参数可设为null。 -
反射程序示例:
package reflection; import java.util.*; import java.lang.reflect.*; public class ReflectionTest { public static void main(String[] args) throws ClassNotFoundException { String name; if (args.length > 0) { name = args[0]; } else { Scanner in = new Scanner(System.in); System.out.println("Enter class name (e.g. java.util.Date): "); name = in.next(); } Class cl = Class.forName(name); Class supercl = cl.getSuperclass(); String modifiers = Modifier.toString(cl.getModifiers()); if (modifiers.length() > 0) { System.out.print(modifiers + " "); } System.out.printf("class " + name); if (supercl != null && supercl != Object.class) { System.out.printf(" extends " + supercl.getName()); } System.out.printf("\n{\n"); printConstructors(cl); System.out.println(); printMethods(cl); System.out.println(); printFields(cl); System.out.println("}"); } public static void printConstructors(Class cl) { Constructor[] constructors = cl.getConstructors(); for (Constructor c : constructors) { String name = c.getName(); System.out.printf(" "); String modifiers = Modifier.toString(c.getModifiers()); if (modifiers.length() > 0) { System.out.print(modifiers + " "); } System.out.print(name + "("); Class[] paramTypes = c.getParameterTypes(); for (int j = 0; j < paramTypes.length; j++) { if (j > 0) { System.out.print(", "); } System.out.print(paramTypes[j].getName()); } System.out.println(");"); } } public static void printMethods(Class cl) { Method[] methods = cl.getDeclaredMethods(); for (Method m : methods) { Class retType = m.getReturnType(); String name = m.getName(); System.out.print(" "); String modifiers = Modifier.toString(m.getModifiers()); if (modifiers.length() > 0) { System.out.print(modifiers + " "); } System.out.print(retType.getName() + " " + name + "("); Class[] paramTypes = m.getParameterTypes(); for (int j = 0; j < paramTypes.length; j++) { if (j > 0) { System.out.print(", "); } System.out.print(paramTypes[j].getName()); } System.out.println(");"); } } public static void printFields(Class cl) { Field[] fields = cl.getDeclaredFields(); for (Field f : fields) { Class type = f.getType(); String name = f.getName(); System.out.print(" "); String modifiers = Modifier.toString(f.getModifiers()); if (modifiers.length() > 0) { System.out.print(modifiers + " "); } System.out.println(type.getName() + " " + name + ";"); } } }
5.8.继承的设计技巧
第6章 接口、lambda表达式和内部类
6.1.接口
-
Java5的Comparable接口已经提升为一个泛型类型,仍然可以使用不带类型参数的Comparable接口,这样的话类型参数为Object。
-
接口中所有的方法都自动是public的。在实现接口时,需要把方法声明为public。接口可以定义字段,且自动为public static final。没必要在接口中添加这些自动的关键字。
-
Comparable接口的文档建议compareTo方法应当与equals方法兼容,Java API中大多遵循了这个建议。有一个重要例外为BigDecimal,
new BigDecimal("1.0")与new BigDecimal("1.00")由于精度不同,equals为false,但compareTo为0。 -
Arrays的sort方法除基本类型数组外被定义为接受Object[]数组,对于该数组会被强制类型转换为Comparable,并调用compareTo方法。所以没有实现Comparable接口会在虚拟机时抛出异常而不是编译器。
-
Java8中,允许在接口中添加静态方法。Java9中,接口的方法可以是private。
-
对于默认方法的冲突,遵循超类优先,即超类有该方法则接口的默认方法被忽略。如果多个接口提供了相同方法,且至少有一个提供了默认方法实现,那么实现类必须覆盖这个方法来解决冲突。覆盖时可以选择冲突方法之一,如:
interface Person { default String getName() { return ""; } } interface Named { default String getName() { return getClass().getName() + "_" + hashCode(); } } class Student implements Person, Named { @Override public String getName() { return Person.super.getName(); } } -
Object的clone方法是一个protected native的方法,是浅拷贝(因为是原生实现,不要纠结父类是怎么知道子类有哪些字段并拷贝的,其实我也不知道是怎么实现的,JDK11闭源)。之所以是protected,目的是拒绝直接调用Object的clone方法(除子类重写clone方法或子类其它方法要使用父类clone),而让子类自己重写为public方法并实现自己的定义(可将其实现为深拷贝,可指定哪些引用类型深拷贝,Object是不知道子类有哪些引用类型所以没法指定哪些字段深拷贝)。在含调用Object的clone方法的类中,必须实现Cloneable标记接口,否则会生成CloneNotSupportedException异常。
-
重写Object的clone的子类,除非是final,否则对于CloneNotSupportedException异常最好是throws而不是try-catch。
-
Java1.4之前,clone方法返回类型为Object,之后可以为覆盖的clone方法指定正确的返回类型(协变)。
-
所有数组都有一个public的clone方法。
6.2.lambda表达式
-
在Java中,对lambda表达式所能做的也只是转换为函数式接口。
-
java.util.function包中BiFunction<T, U, R>接口描述了参数类型为T、U而且返回R类型的函数。 -
ArrayList的removeIf方法,参数为Predicate函数式接口。
-
java.util.function包中Supplier<T>接口用于懒计算。如以下示例,预计day很少为空,requireNonNullElseGet只在需要值时才调用Supplier,也就是创建LocalDate对象。LocalDate hireDay1 = Objects.requireNonNullElse(day, LocalDate.of(1920, 1, 1)); LocalDate hireDay2 = Objects.requireNonNullElseGet(day, () -> LocalDate.of(1920, 1, 1)); -
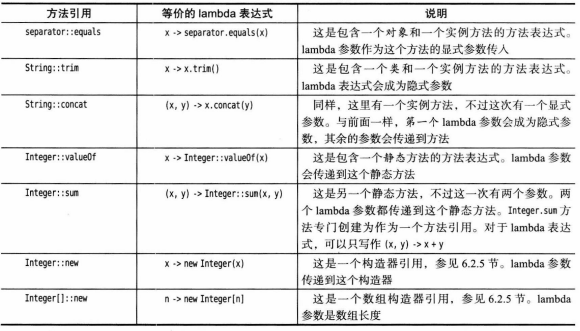
方法引用的三种形式:
object::instanceMethod:等价于向方法传递参数的lambda表达式。如Syatem.out::println等价于x -> System.out.println(x)。Class::instanceMethod:第一个参数会成为方法的隐式参数。如String::compareToIgnoreCase等价于(x, y) -> x.compareToIgnoreCase(y)。Class::staticMethod:所有参数都传递到静态方法。如Math::pow等价于(x, y) -> Math.pow(x, y)。
示例及说明:
![]()
-
只有当lambda表达式的体只调用一个方法而不做其它操作时,才能把lambda表达式重写为方法引用。如
s -> s.length() == 0就不能重写为方法引用。 -
类似于lambda表达式,方法引用不能独立存在,总是会转换为函数式接口的实例。
-
包含对象的方法引用与等价的lambda表达式有一个细微区别,如当separator对象为null时,
separator::equals在构造时就会抛出NullPointerException异常,而x -> separator.equals(x)只在调用时抛出NullPointerException异常。 -
可以在方法引用中使用this、super参数,如
super::great。 -
在lambda表达式中,只能引用值不会改变的变量。lambda捕获的变量必须实际上是事实最终变量,即这个变量初始化后就不会再为它赋新值。对于该自由变量,lambda转换为对象时,会将其复制到这个对象的实例变量中。如以下示例,调用
repeatMessage("Hello,", 1000),lambda可能在调用返回很久后才执行,对于text参数已不存在,而lambda转换为对象会把该变量保存在对象中:public static void repeatMessage(String text, int delay) { ActionListener listener = event -> { System.out.printf(text); Toolkit.getDefaultToolkit().beep(); }; new Timer(delay, listener).start(); } -
在lambda表达式中使用this关键字,指的是创建这个lambda表达式的方法的this参数。但在lambda表达式中,this的使用并没有任何特殊之处。
-
使用lambda表达式的重点是延迟执行。
-
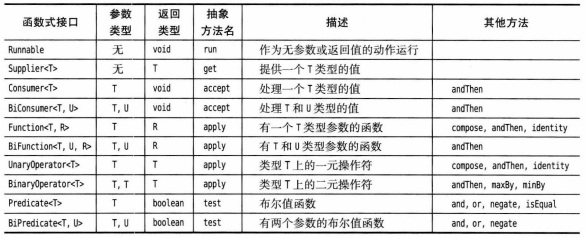
常用函数式接口:
![]()
-
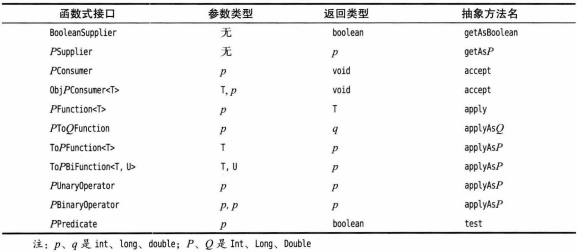
基本类型int、long、double的34个可用的特殊化接口:
![]()
-
大多标准函数式接口都提供了非抽象方法生成或合并函数。如
Predicate.isEqual(a)等同于a::equals不过a为null也能工作。已经提供了默认方法and、or和negate来合并谓词,如Predicate.isEqual(a).or(Predicate.isEqual(b))等同于x -> a.equals(x) || b.equals(x)。 -
如果设计自己的函数时接口,可添加
@FunctionalInterface注解。 -
Comparator接口包含很多方便的静态方法来创建比较器,这些方法可用于lambda表达式或方法引用。
// TODO 2023/11/6 meyok: 254页 Arrays.sort(people, Comparator.comparing(Person::getName)); Arrays.sort(people, Comparator.comparing(Person::getLastName).thenComparing(Person::getFirstName)); Arrays.sort(people, Comparator.comparing(Person::getName, (s, t) -> Integer.compare(s.length(), t.length()))); Arrays.sort(people, Comparator.comparingInt(p -> p.getName().length())); ...
6.3.内部类
-
内部类的实现主要有两个原因:
- 内部类可以对同一个包中的其他类隐藏。
- 内部类方法可以访问定义这个类的作用域中的数据,包括原本私有的数据。
-
考虑到以下类:
package innerClass; import javax.swing.*; import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.time.Instant; public class InnerClassTest { public static void main(String[] args) { TalkingClock clock = new TalkingClock(1000, true); clock.start(); JOptionPane.showMessageDialog(null, "Quit program?"); System.exit(0); } } class TalkingClock { private int interval; private boolean beep; public TalkingClock(int interval, boolean beep) { this.interval = interval; this.beep = beep; } public void start() { TimePrinter listener = new TimePrinter(); Timer timer = new Timer(interval, listener); timer.start(); } public class TimePrinter implements ActionListener { @Override public void actionPerformed(ActionEvent e) { System.out.println("At the tone, the time is " + Instant.ofEpochSecond(e.getWhen())); if (beep) { Toolkit.getDefaultToolkit().beep(); } } } }-
创建外部类并不意味着有内部类实例字段。上述示例中内部类是外部类的
start方法创建的。 -
Java内部类的对象会有一个隐式引用,指向实例化这个对象的外部类对象,通过该指针可访问外部对象的全部状态。但Java静态内部类没有这个附加的指针,所以Java静态内部类相当于C++嵌套类。上述示例中,其实编译器会修改所有内部类的构造器,添加一个对应外围类的引用参数:、
public TimePrinter(TalkingClock clock) { ... }上述外围类
start方法中new TimePrinter()时会将外围类对象引用this传递给修改后的内部类构造器:TimePrinter listener = new TimePrinter(this);也可使用指定的外围类对象创建内部类,使得内部类有引用指定外围类对象的引用而不是执行该动作的对象:
TalkingClock.TimePrinter listener = new TalkingClock(1000, true).new TimePrinter();由于内部类引用有外部类对象的引用,可以访问外围类对象的字段。如上述内部类方法
actionPerformed访问了外围类对象的beep字段,实际上更正规引用(编译器编译后的写法也是这个)为TalingClock.this.beep。 -
内部类是一个编译器现象,与虚拟机无关。编译器会把内部类转换为常规的类文件,用
$分隔外部类名与内部类名,而虚拟机对此一无所知。使用javap解析内部类的作用,可看到编译器实际生成了this$0引用外部类:javap -private innerClass.TalkingClock\$TimePrinterpublic class innerClass.TalkingClock$TimePrinter implements java.awt.event.ActionListener { final innerClass.TalkingClock this$0; public innerClass.TalkingClock$TimePrinter(innerClass.TalkingClock); public void actionPerformed(java.awt.event.ActionEvent); }而该内部类之所以可通过
this$0引用访问该对象的私有字段,实际上是因为外部类生成了一个根据引用访问字段的方法,编译器实际是调用该方法。如内部类访问beep,编译器实际添加了一个方法access$0:class innerClass.TalkingClock { private int interval; private boolean beep; static boolean access$0(TalkingClock); public void start(); public innerClass.TalkingClock(int, boolean); }而内部类使用
beep实际是TalingClock.access$0(this$0)。生成的access$0方法可能被黑客用来攻击。
-
-
可以把内部类声明为私有,这样只有外围类可构造内部类对象,但只有内部类可以是私有的。如果将上述示例中内部类声明为
private,编译器将内部类转换为基本类,但虚拟机中不存在私有类,所以编译器将私有内部类转换为具有包可见性的基本类,并具有以下构造器:private TalkingClock$TimePrinter(TalkingClock); TalkingClock$TimePrinter(TalkingClock, TalkingClock$1);第一个构造器外部无法调用。第二个构造器将调用第一个构造器,还有一个合成的
TalkingClock$1类型作为参数以区分这两个构造器。上述外部类start方法实际上是调用:new TalkingClock$TimePrinter(this, null); -
内部类声明的所有静态字段都必须是final,并初始化为一个编译时常量。
-
内部类不能有static方法,Java语言规范没有对该限制做任何解释。也允许有静态方法(static内部类中),但只能访问外围类的静态字段和方法。
-
可将内部类声明在方法中,被称为局部内部类。如:
public void start(int interval, boolean beep) { class TimePrinter implements ActionListener { @Override public void actionPerformed(ActionEvent e) { System.out.println("At the tone, the time is " + Instant.ofEpochSecond(e.getWhen())); if (beep) { Toolkit.getDefaultToolkit().beep(); } } } TimePrinter listener = new TimePrinter(); Timer timer = new Timer(interval, listener); timer.start(); }局部内部类不能有访问说明符,其作用域被限定在声明这个局部类的块中。
局部内部类不仅能访问外部类的字段,也可以访问局部变量,不过该局部变量必须是事实最终变量。实际上编译器会在生成一个用于保存该变量的字段,创建局部内部类时,会将该变量传递给构造器(构造器也做了相应修改),并存储在该字段中。如上述示例中
beep被修改为start的参数而不是外部类的字段,局部类可访问该事实最终变量,该变量会被赋值一份保存在val$beep中:class TalkingClock$TimePrinter { final TalkingClock this$0; final boolean val$beep; public TalkingClock$TimePrinter(TalkingClock, boolean); public void actionPerformed(java.awt.event.ActionEvent); } -
创建一个类的对象,甚至可以不为该类指定名字,这样一个类被称为匿名内部类。如:
var listener = new ActionListener() { @Override public void actionPerformed(ActionEvent e) { System.out.println("At the tone, the time is " + Instant.ofEpochSecond(e.getWhen())); if (beep) { Toolkit.getDefaultToolkit().beep(); } } };实际上是创建了一个新的内部类,该类实现了对应接口(也可以是拓展了某个类,成为该类的子类),并使用该新的内部类创建了对象。
由于该新的内部类匿名,所以该内部类不存在构造器。实际上,构造参数被传递给超类构造器,若为接口就不能有构造参数。
匿名内部类可提供一个对象初始化块,如:
new ArrayList<String>() { { add("Harry"); add("Tony"); } }对匿名子类重写
equals方法,如果使用if (getClass() != other.getClass()) { return false; }可能会失败。静态方法使用
getClass()不奏效(因为实际调用this.getClass(),静态方法没有this),可使用new Object() {}.getClass().getEnclosingClass()。 -
将内部类声明为
static为静态内部类(又被称为嵌套类)。静态内部类可以有静态字段和静态方法。 -
接口中声明的内部类自动是
static和public。
6.4.服务加载器
6.5.代理
-
只有在编译时期无法确定需要实现哪个接口时才有必要使用代理。
-
构造一个具体的类可使用
newInstance方法或使用反射找出构造器,但不能实例化接口,需要在运行的程序中给定一个新类。利用代理可以在运行时创建实现了一组给定接口的新类。 -
代理类包含以下方法:
- 指定接口所需要的全部方法。
- Object类中的全部方法,例如
toString、equals等。
不过不能再运行时为这些方法定义新代码。
-
创建代理对象需要一个类加载器、一个Class对象数组(元素为需要实现的各个接口)、一个调用处理器。
调用处理器是实现了
InvocationHandler接口的类的对象,该接口只包含一个invoke方法:public interface InvocationHandler { public Object invoke(Object proxy, Method method, Object[] args) throws Throwable; }调用代理对象的方法时,调用处理器的invoke方法会被调用,向其传递Method对象和原调用的参数。
-
代理类是再程序运行时动态创建的,一旦被创建,它与虚拟机中的其他类没有任何区别。
-
所有代理类都扩展Proxy类。一个代理类只有一个实例字段——调用处理器,他在Proxy超类中定义。完成代理对象任务所需要的任何额外数据都必须存储再调用处理器中。
-
没有定义代理类的名字,Oracle虚拟机中的Proxy类将生成一个以字符串
$Proxy开头的类名。 -
对于一个特定的类加载器和预设的一组接口来说,只能有一个代理类。
-
代理类总是
public final。如果代理类实现的所有接口都是public,这个代理类就不属于任何特定的包;否则,所有非公共接口必须属于同一个包,代理类也就属于这个包。 -
使用
Proxy.getProxyClass(null, interfaces)获取对应代理类的Class。 -
使用
Proxy的isProxyClass方法检测一个特定的Class对象是否表示一个代理类。 -
代理类示例:
package proxy; import java.lang.reflect.InvocationHandler; import java.lang.reflect.Method; import java.lang.reflect.Proxy; import java.util.Arrays; import java.util.Random; public class ProxyTest { public static void main(String[] args) { Object[] elements = new Object[1000]; for (int i = 0; i < elements.length; i++) { Integer value = i + 1; TraceHandler handler = new TraceHandler(value); Object proxy = Proxy.newProxyInstance( ClassLoader.getSystemClassLoader(), new Class[] {Comparable.class}, handler ); elements[i] = proxy; } Integer key = new Random().nextInt(elements.length) + 1; int result = Arrays.binarySearch(elements, key); if (result > 0) { System.out.println(elements[result]); } } } class TraceHandler implements InvocationHandler { private Object target; public TraceHandler(Object target) { this.target = target; } @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { System.out.print(target); System.out.print("." + method.getName() + "("); if (args != null) { for (int i = 0; i < args.length; i++) { System.out.println(args[i]); if (i < args.length - 1) { System.out.println(", "); } } } System.out.println(")"); return method.invoke(target, args); } }Integer类实际实现了Comparable
,但运行时所有的泛型被取消,会用对应原始Comparable类的类对象构造代理。 尽管toString不属于Comparable,但仍然被代理。
第7章 异常、断言和日志
7.1.处理错误
-
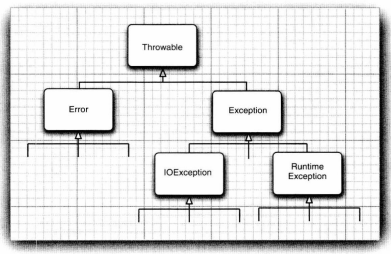
异常可被分为以下类别:
![]()
异常对象都是派生于Throwable类的一个类实例。
Error类层次结构描述了Java运行时系统的内部错误和资源耗尽错误。应用程序不应该抛出这种类型的对象,出现这样的错误,除了通知用户并经理妥善地终止程序之外几乎无能为力。
由编程错误导致的异常属于RuntimeException。Exception的另一个分支包含其它异常。
Java语言规范将派生于Error类或RuntimeException类的所有异常称为非检查型异常,所有其他的异常称为检查型异常。一个方法必须声明所有可能抛出的检查型异常,而非检查型异常要么在控制之外(Error),要么是由一开始就应该避免的情况所导致的(RuntimeException)。
C++标准类库中的异常层次结果,logic_error类似于Java中的RuntimeException,runtime_error类相当于Java中非RuntimeException类型的异常。
-
如果在子类中覆盖了超类的一个方法,子类方法中声明的检查型异常不能比超类方法中声明的异常更通用(子类可抛出更特定的异常或不抛出任何异常)。超类方法没有抛出任何检查型异常,子类重写也不能抛出任何异常。
-
如果类中的一个方法声明它会抛出一个异常,而这个异常时某个特定类的实例,那么这个方法抛出的异常可能属于这个类,也可能属于这个类的任意一个子类。
-
C++中,throw说明符在运行时执行而不是编译时,也就是说C++编译器不处理任何异常规范。但是如果函数抛出的异常没有在throw列表中,就会调用unexcepted函数,默认情况下程序会终止。
C++中,没有throw说明,函数可能抛出任何异常,但在Java中,没有throws说明符的方法根本不能抛出任何检查型异常。
Java中,只能抛出Throwable子类的对象,但C++可抛出任何类型的值。
-
一旦方法抛出了异常,这个方法就不会返回到调用者。
7.2.捕获异常
-
如果方法中的任何代码抛出了catch子句中没有声明的一个异常类型,那么这个方法就会立即退出(希望它的调用者为这种类型的异常提供了catch子句)。
-
一般经验是,捕获知道如何处理的异常,继续传播不知道如何处理的异常。有个例外是,子类覆盖超类方法,但超类方法没有抛出异常,子类方法必须处理可能出现的检查型异常。
-
Java中没有与C++中
catch(...)对应的东西。但这在Java中并不需要,因为所有异常类都派生于一个公共的超类。 -
只有当捕获的异常类型彼此之间不存在子类关系时才可以合并catch子句。捕获多个异常时,异常变量隐含为final变量,如
catch (FileNotFoundException | UnknownHostException e)在同时捕获FileNotFoundException和UnknownHostException时。 -
可以在catch子句中抛出一个异常,通常在希望改变异常类型时这样做。如以下示例在子系统抛出高层异常,而且不会丢失原始异常的细节:
try { access the database } catch (SQLException original) { var e = new ServletException("database error"); e.initCause(original); throw e; }对于不允许抛出检查型异常的方法,catch检查型异常可将其包装成一个运行时异常。
对于以下代码:
public void updateRecord() throws SQLException { try {...} catch(Exception e) { ... throw e; } }Java7之前编译器检查e类型为Exception,可抛出任何Exception而不只是SQLException。但现在已解决,编译器会跟踪e来自try块,假设这个try块中仅有的检查型异常是SQLException实例,另外e在catch中未改变,那么外围方法声明
throws SQLException就是合法的。 -
考虑到以下示例:
var in = new FileInputStream(...); try { // 1 ... // code that might throw exception // 2 } catch (IOException e) { // 3 ... // show error message // 4 } finally { // 5 in.close(); } // 6- 代码没有任何异常,执行1、2、5、6。
- 代码抛出一个异常并在catch中捕获。如果catch子句没有抛出异常,执行1、3、4、5、6,否则执行1、3、5,并异常将被抛回方法调用者。
- 代码抛出一个异常但没有在catch中捕获,执行1、5,并异常将被抛回方法调用者。
-
try语句可以只有finally子句而没有catch,这样无论try中是否遇到异常finally子句都会执行。
-
当try中包含return语句时,finally先于return语句执行。如果finally中也包含return语句,那么try中的return不会执行,甚至try出现异常时,finally中的return会“吞掉“该异常。所以finally子句用于清理资源,不要把改变控制流的语句(return、throw、break、continue)放在finally子句中。
-
在Java7中,对于实现了AutoCloseable接口(和它的子接口Closeable)的类,可使用try-with-resources语句。如以下示例,Scanner、PrintWriter实现了Closeable接口,在try块退出时,会自动调用
in.close()、out.close()。try ( var in = new Scanner( new FileInputStream("words"), StandardCharsets.UTF_8 ); var out = new PrintWriter( "out.txt", StandardCharsets.UTF_8 ) ) { while (in.hasNext()) { System.out.println(in.next()); } }如果try块抛出一个异常,close方法也被抛出,那么try-with-resources语句会将原来的异常重新抛出,close方法抛出的异常会被抑制,并由addSuppressed方法增加到原来的异常。使用getSuppressed方法会生成从close方法抛出并被抑制的异常数组。
try-with-resources语句自身也可包含catch、finally子句。
-
Java9中可在try首部声明事实最终变量。比如以下示例:
try (out) { // effectively final variable for (String line: lines) { out.println(line); } } // out.close() called here
7.3.使用异常的技巧
- 异常处理不能代替简单的测试。如
catch EmptyStackException e的时间大大超过s.empty()。 - 不要过分地细化异常。
- 充分利用异常层次结构。
- 不要只抛出RuntimeException异常,而应该寻找一个合适的子类或自己创建的异常类。
- 不要只捕获Throwable异常,否则代码更难读、难维护。
- 检查型异常本来就很大,不要为逻辑错误抛出这些异常。
- 如果能将一种异常转换为另一种更合适的异常,不要犹豫。
- 不要压制异常。
- 在检查错误时。”苛刻“要比放任好。
- 不要羞于传递异常。
规则5、6可以归纳为”早抛出,晚捕获“。
7.4.使用断言
-
断言机制允许在测试期间向代码中插入一些检查,而在生产代码中会自动删除这些检查。
-
assert关键字的两种形式:assert condition; assert condition : expression;condition为false会抛出Assertion异常。后者expression会传入AssertionError对象的构造器,并转换成一个消息字符串。该expression唯一目的是产生一个消息字符串,AssertionError并不存储该expression,所以以后无法得到这个表达式值。
C语言中的assert宏将condition转换为一个字符串。
-
默认情况下,断言是禁用的。可以在运行时添加
-enableassertions或-ea参数启动断言。不必重新编译程序来启动/禁用断言,启动/禁用断言是类加载器的功能。可以在某个类或者包启动/禁用(-disableassertions或-da参数)断言。java -enableassertions MyApp java -ea:MyClass -ea:com.mycompany.mylib MyApp java -ea:... -da:MyClass MyApp有些类不是类加载器加载而是直接由虚拟机加载的,可以使用这些开关有选择地启动或禁用那些类中的断言。不过启动/禁用所有断言的
-ea和-da开关不能应用到那些没有类加载器的“系统类”上,对于这些系统类,需要使用-enablesystemassertions/-esa开关启动断言。 -
断言只应该用于在测试阶段确定程序内部错误的位置。比如说,某个方法对于参数有相关说明:
/** * @param a the array to be sorted (must not be null). */ static void sort(int[] a, int fromIndex, int toIndex);那么在这个方法体中开头可添加
assert a != null。事实上,由于有这个断言,当方法被非法调用时,它的行为难以预测,有可能抛出断言错误,有可能产生null指针异常,这取决于类加载的配置。再比如说,断言可用于以下防止
i为负数而余数为-1或-2的情况:assert i >= 0; if (i % 3 == 0) {...} else if (i % 3 == 1) {...} else { // assert i % 3 == 2; ... }
7.5.日志
-
除了Java标准日志框架,还有可以使用其他日志框架,如Log4J 2、Logback,不过这些框架API稍有区别,可使用SLF4J或Commons Logging等日志门面来统一API。不过有混乱的是,Log4J 2也可以是使用了SLF4J组件的门面。
Java9中有个单独的轻量级日志系统,它不依赖于
java.logging模块(该模块包含标准Java日志框架),这个系统只用于Java API。如果java.logging模块,日志消息会自动地转发给它。 -
获取全局日志记录器并调用其方法:
Logger.getGlobal().info("File->Open menu item selected"); Logger.getGlobal().setLevel(Level.OFF);自定义自己的日志记录器而不是用全局日志记录器:
private static final Logger myLogger = Logger.getLogger("com.mycompany.myapp");未被任何变量引用地日志记录器可能会被垃圾回收,为防止这种情况发生,用静态变量存储日志记录器的引用。
-
日志记录器名具有层次结构,且比包更强。包与父包没有语义关系,但日志记录器的父与子之间共享某些属性。如对日志记录器“com.mycompany”设置了日志级别,它的子记录器也会继承这个级别。
-
通常有7个日志级别:SEVERE、WARNING、INFO、CONFIG、FINE、FINER、FINEST。默认情况下,只记录前三个级别。如果记录级别设置为比INFO更低的级别,还需要修改日志处理器的配置。
-
默认的日志记录将显式根据调用堆栈得出的包含日志调用的类名和方法名。不过,如果虚拟机对执行过程进行优化,就得不到准确的调用信息,可以使用
logp方法获得调用类和方法的确切位置,这个方法的签名为:void logp(Level l, String className, String methodName, String message)有一些用来跟踪执行流的便利方法
entering、exiting,这两个方法将产生FINER级别且分别以字符串ENTRY、RETRUN开头的日志记录。如:int read(String file, String pattern) { logger.entering("com.mycompany.mylib.Reader", "read", new Object[] {file, pattern}); ... logger.exiting("com.mycompany.mylib.Reader", "read", count); return count; }throwing方法记录一条FINER级别且以THROW开头的日志,用于在日志中记录异常。如:try { ... } catch (IOException e) { logger.throwing("com.mycompany.mylib.Reader", "read", e); } -
日志管理器的配置文件位于
conf/logging.properties(Java9之前位于jre/lib/logging.properties)。要想使用另一个配置文件需要启动应用程序时设置java.util.logging.config.file属性。如java -Djava.util.logging.config.file=configFile mainClass对于配置文件:
.level = INFO # 修改默认日志记录器级别 com.mycompany.myapp.level = FINE # 修改某个日志记录器级别 java.util.logging.ConsoleHandler.level = FINE # 修改日志处理器的日志级别日志记录器将消息发给日志处理器,日志处理器发送到控制台,所以要在控制台上看到FINE级别消息两者都要修改。
日志管理器中的配置不是系统属性,所以在命令行使用
-Dcom.mycompany.myapp.level=FINE不会对日志记录器产生影响。 -
日志管理器在虚拟机启动时初始化。如果没有使用
-Djava.util.logging.config.file设置,可在程序中使用以下代码重新设置配置文件并重新初始化日志管理器:System.setProperty("java.util.logging.config.file", file); LogManager.getLogManager().readConfiguration(); -
Java9中,可通过调用以下方法更新日志配置:
LogManager.getLogManager().updateConfiguration(mapper);// TODO 2023/11/8 meyok
-
在默认情况下,日志记录器会把记录发送到父处理器,而最终的祖先处理器(名为
"")有一个ConsoleHandler,ConsoleHandler会将记录输出到System.err流。除了修改默认日志记录器级别和处理器级别,还可以绕过配置文件,安装自己的处理器:
Logger logger = Logger.getLogger("com.mycompany.myapp"); logger.setLevel(Level.FINE); logger.setUseParentHandlers(false); // 避免""处理器打印信息,导致终端有两次INFO级别信息。 var handler = new ConsoleHandler(); handler.setLevel(Level.FINE); logger.addHandler(handler); -
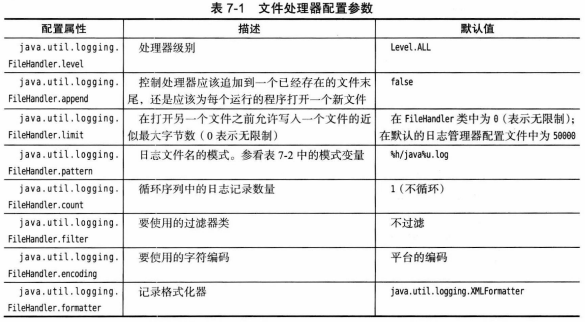
日志API提供了FileHandler、SocketHandler处理器,分别将记录发送到文件、指定主机及端口。
-
将日志发送到默认的文件处理器:
var handler = new FileHandler(); logger.addHandler(handler);默认情况下,记录会格式化为XML。
可以设置日志管理器配置文件中相关参数来修改文件处理器的行为:
![]()
![]()
-
可以扩展Handler类或StreamHandler类自定义处理器。
StreamHandler类会缓存记录,自定义处理器时记得覆盖publish方法,刷新输出缓冲区。
如果希望编写更复杂的流处理器,就应该扩展Handler类,并定义publish、flush、close方法。
-
在默认情况下,会根据日志记录的级别进行过滤。每个日志记录器和处理器都有一个可选的过滤器来完成附加的过滤。要定义一个过滤器,需要实现Filter接口并定义以下方法:
boolean isLoggable(LogRecord record)通过
setFilter方法安装过滤器,同一时刻最多只能有一个过滤器。 -
ConsoleHanlder类和FileHandler类可以生成文本和XML格式的日志记录。不过可以自定义格式,这需要扩展Formatter类并覆盖下面这个方法:
String format(LogRecord record)

7.6.调试技巧
Thread.dumpStack()可获得堆栈痕迹。
第8章 泛型程序设计
8.1.为什么要使用泛型程序设计
- Java增加泛型类之前,泛型程序设计都是用继承实现的。
8.2.定义简单泛型类
- Java库使用变量E表示集合的元素类型,K和V分别表示表的键和值的类型,T(必要时还可以用U、S)表示任意类型。
8.3.泛型方法
-
在C++中,要将类型参数放在方法名后面(Java放在前面),这有可能会导致解析的二义性。如
g(f<a, b>(c))可以理解为”用f<a, b>(c)结果作为参数“,也可以理解为用f < a和b > (c)这两个布尔值作为参数。
8.4.类型变量的限定
- 一个类型变量或通配符可以有多个限定,如
<T extends Comparable & Serializable>。如果可以有多个接口超类型,但最多只有一个限定是类,且类限定必须放在限定列表中第一个位置。
8.5.泛型代码和虚拟机
-
虚拟机没有泛型类型对象,所有对象都属于普通类。
-
类型变量会被擦涂,替换成其限定类型(限定列表中的第一个)。对于无限定的变量则会替换为Object。
-
在类型擦涂时,编译器在必要时会插入强制类型转换。如
class Interval<T extends Serializable & Comparable>,原始类型会用Serializable替换T,必要时向Comparable插入强制类型转换。所以,为了提高效率,应该将标签接口放在限定列表的末尾。 -
方法的类型擦涂可能会带来两个复杂问题。
-
如:
class DateInterval extends Pair<LocalDate> { public void setSecond(LocalDate second) { if (second.compareTo(getFirst()) >= 0) { super.setSecond(second); } } }经过类型擦涂,
DateInterval类含有public void setSecond(LocalDate second)方法,和从Pair<LocalDate>继承的方法public void setSecond(Object second),但这里的本意是重写父类的setSecond方法。为解决这个问题,编译器会在DateInterval类添加桥方法:public void setSecond(Object second) { setSecond((LocalDate) second); }用该方法覆盖父类的
setSecond方法。通过添加桥方法,使得下面调用可行:var interval = new DateInterval(...); Pair<LocalDate> pair = interval; pair.setSecond(aDate);pair被声明为Pair<LocalDate>变量,它只含有setSecond(Object)方法,而pair引用的是DateInterval类型,所以pair.setSecond(aDate);调用的是DateInterval的setSecond(Object)方法,为支持多态(即调用重写的方法,而不是从父类继承而来方法),需要桥方法。 -
如:
class DateInterval extends Pair<LocalDate> { public LocalDate getSecond() { return (LocalDate) super.getSecond(); } }DateInterval含有以下两个方法,一个本身的,另一个继承而来:LocalDate getSecond() Object getSecond()对于Java代码是不合法的。但在虚拟机中,会由参数类型和返回类型共同指定一个方法。
-
-
桥方法不仅适用于泛型类型,对于有协变的返回类型的方法覆盖时也有。如:
public class Employee implements Cloneable { public Employee clone() throws CloneNotSupportedException {...} }Employee会有以下两个方法:Employee clone() Object clone()这时会合成桥方法,覆盖掉
Object类的clone方法,实现Employee clone()方法调用。
8.6.局限与局限性
-
不能用基本类型替代类型参数。原因在于类型擦涂,无法使用Object存储基本类型值。
-
所有的类型查询值产生原始类型。试图查询一个对象是否属于某个泛型对象时,会得到一个编译器错误(使用
instanceof时)或者一个警告(使用强制类型转换时)。如:if (a instanceof Pair<String>) // ERROR Pair<String> p = (Pair<String>) a // WARNING同样的道理,
getClass()方法总是返回原始类型。 -
不能实例化参数化类型的数组。如:
var table = new Pair<String>[10]; // ERROR原因在于类型擦涂后,可以向数组中添加其他参数化类型的值。如这样操作:
Object[] objarray = table; objarray[0] = new Pair<Employee>();但是可以声明参数化类型的数组,只是不能初始化。如可以声明
Pair<String>[]但不能使用new Pair<String>[10]对其初始化。可以使用声明通配类型的数组,然后进行强制类型转换。但这样是不安全的(如调用方法时可能会有
ClassCastException异常)。如:var table = (Pair<String>[]) new Pair<?>[10]; // allow Object[] objarray = table; objarray[0] = new Pair<Employee>(); objarray[0].getString(); // ClassCastException -
对于 varargs 警告。如以下示例:
public static <T> void addAll(collection<T> coll, T... ts) {...} public static void main(String[]) { Collection<Pair<String> table = ...; Pair<String> pair1 = ...; Pair<String> pair2 = ...; addAll(table, pair1, pair2); }为能成功调用
addAll,虚拟机会创建Pair<String>数组,这违反了之前提到的规则。但对于这种情况规则其实有所放松,只会得到一个警告,而不是错误。可以使用
@SippressWarning("unchecked")或@SafeVarargs抑制这个警告。@SafeVarargs只能用于声明为static、final或(Java9中)private的构造器和方法。所有其他方法都可能被覆盖,使得该注解没意义。可以使用
@SafeVarargs消除创建泛型数组的有关限制。如:@SafeVarargs static <E> E[] array(E... array) { return array; } public static void main(String[]) { Pair<String>[] = array(pair1, pair2); }不过这样隐藏着危险。
-
不能在类似
New T(...)的表达式中使用类型变量。在Java8之后,最好的解决办法是提供一个构造表达式,如(不能使用public Pair() { first = new T(); second = new T(); }而使用:public static <T> Pair<T> makePair(Supplier<T> constr) { return new Pair<>(constr.get(), const.get()); }Pair<String> p = Pair.makePair(String::new);比较传统的方法是通过反射调用
Constructor.newIntance方法,但T.class是不合法的(不能使用first = T.class.getConstructor().newInstance();)。必须适当地设计API以便得到一个Class对象:public static<T> Pair<T> makePair(Class<T> cl) { try { return new Pair<>(cl.getConstructor().newInstance(), cl.getConstructor().newInstance()); } catch (Exception e) { return null; } }Pair<String> p = Pair.makePair(String.class); -
不能构造(并非声明)泛型数组。如:
public static <T extends Comparable> T[] minmax(T... a) { T[] mm = new T[2]; // ERROR ... }如果使用擦涂类型的数组,并在返回的时候强制类型转换,该强制类型转换其实是一个假象。返回时可能得到运行时错误。如:
public static <T extends Comparable> T[] minmax(T... a) { var result = new Comparable[2]; ... return (T[]) result; // complies with warning }T为
Comparable的子类型时,如String,是无法将Comparable转换为String的。在这种情况下,最好提供一个数组构造器表达式:
public static <T extends Comparable> T[] minmax(IntFunction<T[]> constr, T... a) { var result = constr.apply(2); ... }String[] names = ArrayAlg.minmax(String[]::new, "Tom", "Dick", "Harry");比较老式的方法是使用反射:
public static <T extends Comparable> T[] minmax(T... a) { var result = (T[]) Array.newIntance(a.getClass().getComponentType(), 2); ... } -
泛型类的静态上下文中类型变量无效。如:
public class Singleton<T> { private static T singleIntance; // ERROR private static T getSingleIntance() { // ERROR if (singleIntance == null) { // construct new instance of T } return singleIntance; } }如果这样可行,类型擦涂之后只有
Singleton类,仅有一个singleIntance,但对于Singleton<Rondom>和Singleton<JFileChooser>需要分别共享一个Rondom和JFileChooser字段,这样是行不通的。 -
不能抛出或捕获泛型类的实例。实际上,泛型类扩展
Throwable都是不合法的。不过在异常规范中使用类型变量是允许的。如:public static <T extends Throwable> void doWork(Class<T> t) throws { try { // do work } catch (T e) { // ERROR-can't catch type variable ... } catch (Throwable realCause) { t.initCause(realCause); throw t; } } -
可以取消对检擦型异常的检查,方法是将其转换为非检查型异常。如
Runnable中的run方法不允许抛出检查型异常,那么可以这样做:interface Task { void run() throws Exception; @SuppressWarning("unchecked") static <T extends Throwable> void throwAs(Throwable t) throw t { throw (T) t; } static Runnable asRunable(Task task) { return () -> { try { task.run(); } catch (Exception e) { Task.<RuntimeException>throwAs(e); } } } }public class Test { public static void main(String[] args) { var thread = new Thread(Task.asRunnbale( () -> { Thread.sleep(1000); System.out.println("Hello, World!"); throw new Exception("Check this out!"); })); thread.start(); } }new Thread需要Runnable,这里使用Task的asRunnbale方法生成,在该方法中将所有task.run()出现的异常转化为运行时异常。 -
当泛型类型被擦涂后,不允许创建引发冲突的条件。如:
public class Pair<T> { public boolean equals(T value) {...} }经过类型擦涂后,
Pair<Object>的boolean equals(Obejct value)与Object.equals冲突(// TODO 2023/11/12 meyok:重写??)。 -
倘若两个接口类型是同一接口的不同参数化,一个类或类型变量就不能同时作为这两个接口类型的子类。如以下代码非法:
class Employee implements Comparable<Employee> {...} class Manager extends Employee implements Comparable<Manager> {...}但这限制与类型擦涂的关系并不十分明显,如以下非泛型版本是合法的:
class Employee implements Comparable {...} class Manager extends Employee implements Comparable {...}其原因非常微妙,可能与合成的桥方法有关。如:
public int compareTo(Object other) { return compareTo((x) other); }不能对不同的类型
x有两个这样的方法。
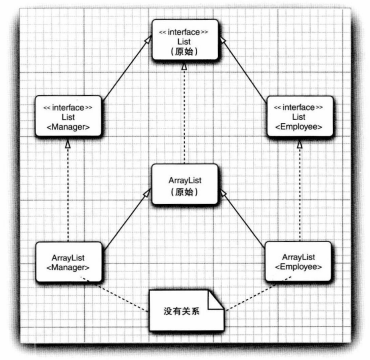
8.7.泛型类型的继承规则
-
无论
S和T有什么关系,通常Pair<S>与Pair<T>没有任何关系。 -
总是可以将参数化类型转换为一个原始类型。但转换为原始类型使用时可能产生错误。
-
泛型类可以扩展或实现其他的泛型类。
-
泛型类型继承规则示例:
![]()
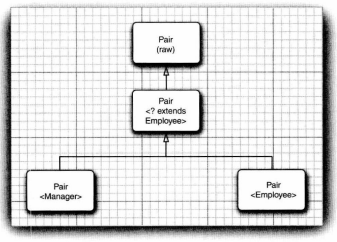
8.8.通配符类型
-
使用通配符的类型的泛型类是其通配符限定列表的泛型类型类的超类。如以下继承规则示例:
![]()
-
使用通配符不会通过
Pair<? extends Employee>的引用破环Pair<manager>。如:var managerBuddies = new Pair<Manager>(ceo, cfo); Pair<? extends Employee> wildcardBuddies = managerBuddies; wildcardBuddies.setFirst(lowlyEmployee); // compile-time error对
setFirst的调用会在编译时出现错误。究其原因,考虑到Pair<? extends Employee>类型的方法:void setFirst(? extends Employee); ? extends Employee getFirst();setFirst的参数是? extends Employee,编译无法确定某个类可以传给继承于Employee类。但对于getFirst就可使用,因为编译器可确定继承于Employee类可传递给某个类(如Employee)。(这里是个人理解,请参考原书349页。) -
通配符可使用超类型限定,其作用与子类型限定相反。如
Pair<? super Employee>有以下方法:void setFirst(? super Employee); ? super Employee getFirst();编译器可以确定某个类(
Employee及其子类)可以传给Employee的超类,它可以使用。但如果调用getFirst,不能保证返回对象的类型,只能将其赋给Object。 -
带有超类型的通配符允许写入一个泛型对象,而带有子类型限定的通配符允许读取一个泛型对象。
-
有这种情况:
LocalDate实现ChronoLocalDate,ChronoLocalDate扩展Comparable<ChronoLocalDate>,在此LocalDate实现的是Comparable<ChronoLocalDate>而不是Comparable<LocalDate>,这种情况下可利用超类解决通配符限定问题:public static <T extends Comparable<? super T>> T min(T[] a) ... -
可以使用根本无限定的通配符。对于
Pair<T>与原始Pair类型的区别在于:? getFirst()只能返回给Object,而void setFirst(?)根本无法使用。 -
通配符不是类型变量,因此不能再编写代码中使用
?作为一种类型。对于以下错误代码:
public static void swap(Pair<?> p) { ? t = p.getFirst(); p.setFirst(p.getSecond()); p.setSecond(t); }可使用辅助函数解决:
public static <T> void swapHelper(Pair<T> p) { T t = p.getFirst(); p.setFirst(p.getSecond()); p.setSecond(t); } public static void swap(Pair<?> p) { swapHelper(p); }这里
T捕获通配符,虽然它不知道通配符指示哪种类型,但是这是一个明确的类型。(// TODO 2023/11/12 meyok)编译器必须能够保证通配符表示单个确定的类型。如,
ArrayList<Pair<T>>中T永远无法捕获``ArrayList<Pair>`中的通配符,数组列表可以保存两个`Pair,其中?`分别有不同的类型。
8.9.反射与泛型
- 擦涂的类型仍然保留原先泛型的微弱记忆。可以重新构造实现者声明的泛型类和方法中所有有关内容,但是你不知道对于特定的对象或方法调用会如何解析类型参数。
第9章 集合
9.1.Java集合框架
-
队列通常有两种实现方式:循环数组、链表。
-
使用接口类型存放集合的引用,这样当需要使用另外一种实现时,便于只在一处修改代码。如:
Queue<Customer> expressLane = new LinkedListQueue<>(); -
以
Abstract开头的类,这些类是为类库实现者而设计的。比如,要实现自己的队列类,扩展AbstractQueue类比实现Queue接口中的所有方法要轻松得多。 -
Java类库中,集合类的基本接口是
Collection接口。 -
如果到达集合的末尾,
Iterator的next方法会抛出NoSuchElementException异常。因此,需要在调用next方法之前,调用hasNext方法检查一下。 -
Iterator的forEach方法需要一个Consumer函数式接口,此方法会对集合中每个元素作为参数调用。其顺序取决于集合类型。如果迭代处理一个ArrayList,将从索引0开始直至末尾,如果迭代处理HashSet,会按照一种基本上随机的顺序,虽然可以确保能够遍历所有,但无法预知顺序。 -
可以认为Java迭代器位于两个元素之间。当调用
next时,迭代器就会越过下一个元素,并返回刚刚越过的那个元素。 -
Iterator接口的remove方法会删除上次调用next方法时返回的元素。这两个方法存在依赖性,remove方法之前没有对应的next方法,可能抛出IllegalStateException异常。 -
AbstractCollection类实现了Collection接口,保持了size和iterator方法仍未抽象,但未其它方法有相关默认实现。
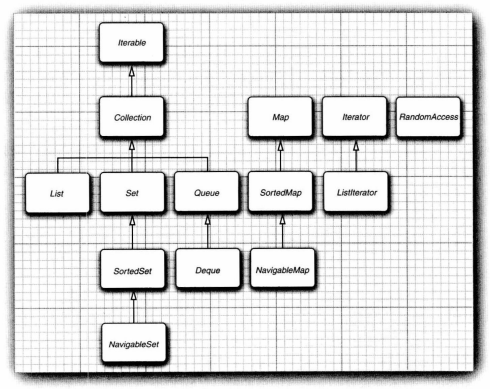
9.2.集合框架中的接口
-
Java集合框架中的接口如图所示:
![]()
-
ListIterator是Iterator接口的一个子接口,它定义了一个用于在当前迭代器位置前面增加一个元素的方法:void add(E element)。 -
为避免对链表完成随机方法操作,Java1.4引入了一个标记接口
RandomAccess,可以使用它来测试一个特定的集合是否支持高效的随机访问:if (c instanceof RandomAccess) { // use random access algorithm } else { // use sequential access algorithm } -
Set接口等同于Colletion接口,不过集的add方法不允许增加重复元素。要适当地定义集(set)的equals方法:只要两个集包含同样地元素就认为它们是相等的,而不要求这些元素有相同的顺序。hashCode方法要保证包含相同元素的两个集合会得到相同的散列码。 -
SortedSet和SortedMap接口会提供用于排序的比较器对象,这两个接口定义了可以得到集合子集视图的方法。 -
Java6引入了接口
NavigableSet和NavigableMap,其中包含一些用于搜索和遍历有序集和映射的方法。
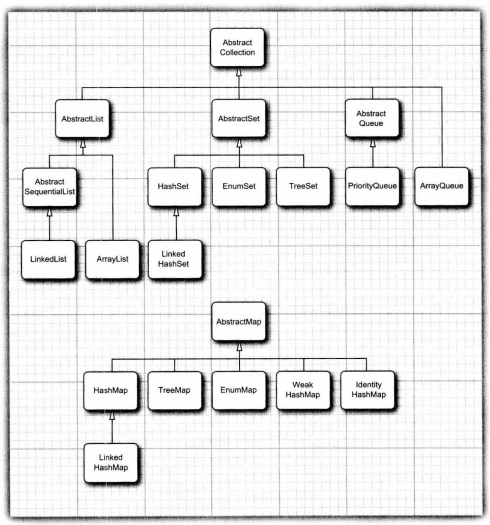
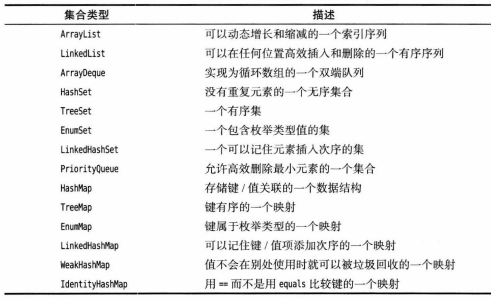
9.3.具体集合
-
带
Map结尾的类实现Map接口,其它类实现Collection接口。Java类库中的集合:![]()
![]()
-
在Java中,所有链表实际上都是双向链表。
-
只有对自然有序的集合使用迭代器添加元素才有实际意义。
-
ListIterator的add方法相比于Iterator的add方法,它没有返回值,它是假定add操作总会改变链表。 -
不能连续调用两次
remove。add方法依赖于迭代器位置,remove方法依赖于迭代器状态。 -
set方法用一个新元素替换调用next或previous方法返回的上一个元素。 -
如果一个迭代器发现它的集合被另一个迭代器修改了,或是被该集合自身的某个方法修改了,就会抛出一个
ConcurrentModificationException异常。集合跟踪更改操作次数,而每个迭代器都会为它自己负责的更改操作维护一个单独的更改操作次数。在每个迭代器方法开始处,会检查两者更改次数是否相等,不一致抛出
ConcurrentModificationException异常。不过,链表只跟踪对列表的结构性修改,例如添加和删除链接。
set方法不被视为结构性修改。 -
绝对不应该使用这个“虚假”的随机访问来遍历链表。下面这段代码效率极低:
for (int i = 0; i < list.size(); i++) { // do something with list.get(i); }每次查找一个元素都要从列表的头部开始重新搜索。
get方法做了一个小优化:如果索引大于等于size() / 2,就从列表尾端开始搜索元素。 -
ListIterator的nextIndex和previousIndex分别返回迭代器位置旁边的下个、上个元素的索引。list.listIterator(n)返回指向索引为n元素前面位置的迭代器。 -
相比较于
ArrayList,Vector类中所有的方法都是同步的。 -
对于散列表,在Java8中,bucket满时,会从链表变为平衡二叉树。
通常将散列表的bucket数设置为预计个数的75%~150%。有研究人员认为,最好将bucket数设置为一个素数,以防止类聚集。标准类库使用的bucket数是2的幂,默认为16(为表大小提供的任何值都将自动地转换为2的下一个幂值)。
如果散列表太满(达到装填因子的比例,默认0.75),就会再散列,新建一个bucket表,大小为原来的2倍,再将所有元素迁移到该新表,丢弃原来的表。
-
在更改集中的元素时要格外小心。如果元素的散列码发生了改变,元素在数据结构中的位置也会发生变化。
-
TreeSet是一个有序集合,可以以任意顺序将元素插入到集合中。在对集合进行遍历时,值将自动地按照排序后的顺序呈现。(当前是用红黑树实现的) -
双端队列允许在头部和尾部都高效地添加、删除元素,不支持在队列中间添加元素。
-
优先队列(prority queue)中的元素可以按照任意的顺序插入,但会按照有序的顺序进行检索。也就是说,无论何时调用
remove方法,总会获得当前优先队列中的最小元素。不过优先队列并没有对所有元素进行排序。优先队列使用了堆。堆是一个可以自组织的二叉树,其添加、删除操作可以将最小的元素移动到根,而不必花时间对元素进行排序。
优先队列的典型用法是任务调度。
9.4.映射
-
散列或比较函数只用于键,与键关联的值不进行散列或比较。
-
如果映射中没有存储与给定键对应的信息,
get将返回null。null返回值可能并不方便,可以使用一个默认值返回。如:int score = scores.get(id); int score = socres.getOrDefault(id, 0); -
如果对一个键调用两次
put方法,会覆盖。putIfAbsent方法在键原先存在(或者映射到null)时会放入一个值。以下示例,对于统计单词出现数量的三个版本:
counts.put(word, counts.getOrDefault(word, 0) + 1);counts.putIfAbsent(word, 0); counts.put(word, countas.get(word) + 1);counts.merge(word, 1, Integer::sum); -
Set<K> keySet(); Collection<V> values(); Set<Map.Entry<K, V>> entrySet();分别返回映射的三种视图:键集、值集合(不是一个集)、键/值对集。需要说明的是,
keySet不是HashSet或TreeSet,而是实现了Set接口的另外某个类的对象。 -
如果在键集视图上调用迭代器的
remove方法,实际上会从映射中删除这个键和与它相关联的值,不过不能向键集视图中添加元素。映射条目集视图有同样的限制,尽管理论上增加一个新的键/值对好像有意义。 -
垃圾回收器会跟踪活动对象,只要映射对象是活动的,其中的所有桶也是活动的,假定对某个键的最后一个引用已经消失,它们也不能被回收。因此,需要由程序负责从长期存活的映射表中删除那些无用的值。或者,使用
WeakHashMap,当对键的唯一引用来自散列表映射条目时,这个数据结构将与垃圾回收器协同工作一起删除键/值对。WeakHashMap使用弱引用(WeakReference)保存键。WeakReference对象将包含另一个对象的引用,在这里就是一个散列表键。对于这种类型的对象,垃圾回收器采用了一种特有的方法进行处理。正常情况下,垃圾回收器发现某个特定的对象已经没有他人引用了,就将其回收。然而,如果某个对象只能由WeakReference引用,垃圾回收器也会将其回收,但会将引用这个对象的WeakReference放在一个队列。WeakHashMap将周期性地检查队列,以便找出新添加地弱引用。一个弱引用进入队列意味着这个键不再被他人使用,并且已经回收。于是,WeakHashMap将删除相关地映射条目。 -
LinkedHashSet和LinkedHashMap类会记住插入元素项的顺序。 -
LinkedHashMap可以使用访问顺序而不是插入顺序来迭代处理映射条目。每次调用get或put时,受影响的项将从当前位置删除,并放在项列表尾部(只影响项在链表中的位置,而散列表的桶不会受影响。)。 -
EnumSet是一个枚举类型元素集的高效实现。由于枚举类型只有有限个实例,所以EnumSet内部用位序列实现。如果对应的值在集中,则相应的位被置为1。EnumSet没有公共的构造器,要使用静态工厂方法构造这个集。可以使用Set接口的常用方法来修改EnumSet。 -
EnumMap是一个键类型为枚举类型的映射。它可以直接且高效地实现为一个值数组。需要在构造器中指定键类型:var personInCharge = new EnumMap<WeekMap, Employee>(Weekday.class); -
IdentityHashMap有特殊的用途。在这个类中,键的散列值不是用hashCode函数计算的,而是用System.identityHashCode方法计算的。这是Object.hashCode根据对象的内存地址计算散列码时所使用的方法。而且,在对两个对象进行比较时,IdentityHashMap类使用==而不使用equals。也就是说,不同的键对象即使内容相同,也被视为不同的对象。在实现对象遍历算法(如对象串行化)时,这个类非常有用,可以用来跟踪哪些对象已经遍历过。
9.5.视图与包装器
-
视图操作的是原映射。
-
Java9引入了一些静态方法,可以生成给定元素的集或列表,以及给定键/值对的映射。如:
List<String> names = List.of("Peter", "paul", "Mary"); Set<Integer> numbers = Set.of(2, 3, 5); Map<String, Integer> scores = Map.of("Peter", 2, "Paul", 5);Map<String, Integer> scores = Map.ofEntries( Map.entry("Peter", 2), Map.entry("Paul", 3), Map.entry("Mary", 5) );其中元素、键或值不能为
null。List和Set有11个方法,分别有0到10个参数,另外还有一个参数个数可变的of方法。对于Map接口无法提供一个参数可变的版本,不过可用ofEntries方法。这些集合对象是不可修改的。如果需要修改,可将其传入构造器中。如:
var name = new ArrayList<>(List.of("Peter", "paul", "Mary")); -
Collections的nCopies方法会返回实现了List接口的不可变对象。看上去有n个对象,实际上对象只会存储一次。 -
Arrays.asList方法会返回一个可以更改但是大小不可变的列表(即可以使用set,但不能使用add或remove。)。 -
获取子范围视图的方法,如:
List<E> subList(int fromIndex, int toIndex); SortedSet<E> subSet(E from, E to); SortedSet<E> headSet(E to); SortedSet<E> tailSet(E from); SortedMap<K, V> subMap(K from, K to); SortedMap<K, V> headMap(K to); SortedMap<K, V> tailMap(K from);Java6引入的
NavigableSet接口允许更多地控制子范围视图操作。可以指定是否包含边界:NavigableSet<E> subSet(E from, boolean fromInclusive, E to, boolean toInclusive); NavigableSet<E> headSet(E to, boolean toInclusive); NavigableSet<E> tailSet(E from, boolean fromInclusive);可以对子范围应用任何操作,且操作会自动反应到整个列表。
-
可以使用以下方法获取不可更改视图:
Collections.unmodifiableCollection Collections.unmodifiableList Collections.unmodifiableSet Collections.unmodifiableSortedSet Collections.unmodifiableNavigableSet Collections.unmodifiableMap Collections.unmodifiableSortedMap Collections.unmodifiableNavigableMap这些视图对现有集合增加一个运行时检查,如果发现试图对集合进行修改,就会抛出一个异常,集合仍保持不变。所有的更改器方法已被重新定义为抛出
UnsupportedOperationException异常。UnmodifiableCollection的equals方法不调用底层集合的euqals方法,它实际继承Object的equals方法,只检验两个对象是否是同一个对象。而UnmodifiableSet和UnmodifiableMap调用底层集合的equals方法和hashCode方法。 -
视图只是包装了接口而不是具体的集合对象,所以只能访问接口中定义的方法。
-
类库的设计者使用视图机制来确保常规集合是线程安全的,而没有实现线程安全的集合类。如,
Colletions的synchronizedMap方法可将任何一个映射转换为有同步访问方法的Map。 -
检查型视图用来对泛型类型可能出现的问题提供调试支持。如:
var strings = new ArrayList<String>(); ArrayList rawList = strings; rawList.add(new Date()); // now strings contains a Date objectList<String> safeStrings = Collections.checkedList(strings, String.class); List rawList = strings; rawList.add(new Date()); // checked list throws a ClassCastException上边的代码中,错误的
add命令在运行时检测不到,只用在使用get等方法操作Date元素,将其强制转换为String才会出现类强制转换异常。下边的add方法会检查是否属于给定的类,不属于则会立即抛出ClassCastException。检查型视图受限于虚拟机可以完成的运行时检查。如,对于
ArrayList<Pair<String>>无法阻止插入Pair<Date>。
9.6.算法
-
Java的
sort方法,是将所有元素转入一个数组,对数组进行排序,然后再将排序后的序列复制回列表。如Colletions的shuffle,如果提供的列表没有实现RandomAccess接口,则会将元素复制到数组中,打乱顺序,然后复制回列表。 -
集合类库中使用的排序算法比快速排序要慢一些。但是,归并排序有一个主要的特点:归并排序是稳定的,也就是说,它不会改变相等元素的顺序。
-
可以传递给算法的列表,要求是可修改的,但不一定可以改变大小。
如果列表支持
set,则是可修改的。如果列表支持add和remove,则是可改变大小的。 -
Colletions的binarySearch要求集合必须是有序的,否则会返回错误的答案。如果集合没有采用Comparable接口的compareTo方法进行排序。只有采用随机访问,二分查找才有意义。因此如果为binarySearch算法提供了一个链表,它将自动地退化为线性查找。 -
Colletions类中包含几个简单但很有用的算法,如查找集合中的最大元素、将一个列表中的元素复制到另外一个列表中、用一个常量值填充容器、逆置一个列表的元素顺序。 -
为什么不能直接将一个Class对象传递到
toArray方法,原因在于这个方法有双重职责,不仅要填充一个已有数组(如果它足够长),还要创建一个新数组。 -
如果编写自己的算法(实际上,或者是以集合为参数的任何方法),应该尽可能地使用接口,而不要使用具体的实现。
9.7.遗留的集合
-
Hashtable类与HashMap类的作用一样,实际上,接口也基本相同。与Vector类的方法一样,Hashtable方法也是同步的。 -
遗留的集合使用
Enumeration接口遍历元素序列。Enumeration接口有两个方法,即hasMoreEloments和nextElement,这两个方法完全类似于Iterator接口的hasNext方法和next方法。 -
属性映射是一个特殊类型的映射结构。它有下面3个特征:
- 键与值都是字符串。
- 这个映射可以很容易地保持到文件以及从文件加载。
- 有一个二级表存放默认值。
实现属性映射的Java平台类名为
Properties。Properties类实现了Map<Object, Object>。因此可以使用Map接口的get和put方法。不过,get方法返回类型为Object,而put方法允许插入任意的对象。所以最好检查使用处理字符串而不是对象的getProperty和setProperty方法。Properties类有两种提供默认值的机制:-
指定查找某个字符串时,键不存在时的默认值。如:
String filename = settings.getProperty("filename", ""); -
把所有默认值都放在一个二级属性映射中,并在主属性映射的构造器中提供这个二级映射。如:
var defaultSettings = new Properties(); defaultSettings.setProperty("width", "600"); defaultSettings.setProperty("height", "400"); defaultSettings.setProperty("filename", ""); ... var settings = new Properties(defaultSettings);
属性是没有层次结构的简单表格。通常会使用类似
window.main.color、window.main.title等引入一个假象的层次结构。如果要存储复杂的配置信息,就应该使用Preferences类。 -
从1.0版开始,标准类库就包含了
Stack类,它扩展了Vector类,甚至可以使用并非栈操作的insert和remove方法。 -
Java平台的
BitSet类用于存储一个位序列。C++中的
bitset模板与Java平台中的BitSet功能一样。 -
埃拉托色尼筛选法(sieve of Eratosthenes)用来查找素数。这并不是查找素数的一种非常好的方法,但是由于某些原因,它已经称为测试编译器性能的一种流行的基准。
假如寻找2~2_000_000之间的所有素数。这里实现关键机理是,遍历一个包含2万个位的位集,首先将所有位置为“开”状态。然后,将已知素数的倍数所对应的位都置为“关”状态。经过这个操作保留下来的位对应的就是素数。
第10章 图形用户界面程序设计
第11章 Swing用户界面组件
第12章 并发
12.1.什么是线程
- 不要调用
Tread类或Runnable对象的run方法,直接调用run方法只会在同一个线程中执行这个任务——而没有启动新的线程。应当调用Thread.start方法,这会创建一个执行run方法的新线程。
12.2.线程状态
-
线程可有6种状态:New(新建)、Runnable(可运行)、Blocked(阻塞)、Waiting(等待)、Timed waiting(计时等待)、Terminated(终止)。
要确定一个线程的当前状态,只需要调用
getState方法。-
New:使用
new操作符创建一个新线程时,处于New状态。 -
Runnable:调用
start方法后,处于Runnable状态。一个Runnable状态线程可能正在运行也可能没有运行。 -
Blocked、Waiting、Timed waiting:处于该状态时,要由线程调度器重新激活这个线程,具体细节取决于它是如何到达非活动状态的。
- 当一个线程试图获取一个内部的对象锁(而不是
java.util.concurrent库中的Lock),而这个锁目前被其他线程占有,该线程就会被阻塞。当所有其他线程都释放了这个锁,并且线程调度器允许该线程持有这个锁时,它将变成非阻塞状态。 - 当线程等待另一个线程通知调度器出现一个条件时,这个线程就会进入等待状态。调用
Object.wait方法或Thread.join方法,或者是等待java.util.concurrent库中的Lock或Condition时,就会出现这种情况。实际上,阻塞状态与等待状态并没有太大区别。 - 有几个方法有超时参数,调用这些方法会让线程进入计时等待状态。这一状态将一直保持到超时期满或者接受到适当的通知。带有超时参数的方法有
Thread.sleep和计时版的Object.wait、Thread.join、Lock.tryLock以及Condition.await。
- 当一个线程试图获取一个内部的对象锁(而不是
-
Terminated:
run方法正常退出,线程自然终止。或者因为一个没有捕获的异常终止了run方法,使线程意外终止。调用线程的
stop方法杀死一个线程,该方法抛出ThreadDeath错误对象。不过该方法已废弃,不要在自己的代码中调用这个方法。
当一个线程阻塞、等待、终止时,可以调度另一个线程运行。当一个线程被重新激活时,调度器检查它是否具有比当前运行线程更高的优先级,如果有,调度器会剥夺某个当前运行线程的运行权,选择一个新的线程运行。可能发生的线程状态转换:
![]()
-
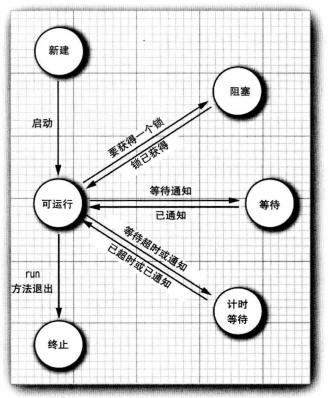
12.3.线程属性
-
除了已经废弃的
stop方法,没有方法可以强制线程终止。interrupt方法可以用来请求终止一个线程。每个线程都有一个boolean标志线程中断状态。每个线程都应该不时地检查该标志,以判断线程是否被中断。检查该标志使用isInterrupted方法。而静态方法interrupted检查当前线程是否被中断,而且调用该方法会清除该线程中断状态。线程被阻塞时,无法检查中断状态。
当在一个被
sleep或wait调用阻塞的线程上调用interrupt方法时,会抛出InterruptedException异常。如果设置了中断状态,再调用
sleep方法,它不会休眠。它会清除中断状态并抛出InterruptedException异常。没有任何语言要求被中断的线程应当终止,中断一个线程只是要引起它的注意,被中断的线程可以决定如何响应中断。更普遍的情况是,线程只希望将中断解释为一个终止请求。这种线程的
run方法具有如下形式:Runnable r = () -> { try { ... while (!Thread.currentThread().isInterrupted() && // more work to do ) { // do more work } } catch (InterruptedException e) { // thread was interrupted during sleep or wait } finally { // cleanup, if required } //exiting the run method terminates the thread }如果循环调用
sleep,不要检测中断状态,而应该捕获InterruptedException异常:Runnable r = () -> { try { ... while ( // more work to do ) { // do more work Thread.sleep(delay); } } catch (InterruptedException e) { // thread was interrupted during sleep or wait } finally { // cleanup, if required } //exiting the run method terminates the thread }很多发布的代码在底层抑制了
InterruptedException异常:catch (InterruptedException e) {}建议不要这样做。如果想不出在
catch子句中可以做什么有意义的工作,仍有两种合理的选择:1.调用interrupt设置中断状态,这样调用者可以检测中断状态。2.使用throws InterruptedException,去掉try语句块,这样调用者可以捕获这个异常:catch (InterruptedException e) { Thread.currentThread().interrupt(); }void mySubTask() throws InterruptedException { ... } -
使用
setDaemon(true)可以将线程转换为守护线程。当只剩下守护线程时,虚拟机就会退出。 -
默认情况下线程有容易记的名字,使用
setName方法为线程设置任何名字。 -
非检测型异常可能会导致线程终止,这种情况下,线程会死亡。不过对于可以传播的异常,并没有任何
catch子句(线程的run方法不能抛出任何检查型异常)。实际上,在线程死亡之前,异常会传递到一个用于处理未捕获异常的处理器(这个处理器必须属于一个实现了Thread.UncaughtExceptionHandler接口的类,该接口只有一个方法uncaughtException)。使用
Thread类的静态方法setDefaultUncaughtExceptionHandler为所有线程安装一个默认的处理器(未安装时默认处理器则为null)。使用setUncaughtExceptionHandler为任何线程安装一个处理器(未安装时处理器为该线程的ThreadGroup对象)。默认情况下,创建的所有线程同属一个线程组,但是也可以建立其他的组。由于现在引入了更好的特性来处理线程集合,所以建议不要再你自己的程序中使用线程组。
ThreadGroup实现的uncaughtException方法执行以下操作:- 如果该线程组有父线程组,那么调用父线程组的
uncaughtException方法。 - 否则,如果
Thread.getDefaultUncaughtExceptionHandler返回非null的处理器,则调用该处理器。 - 否则,如果
Throwable是ThreadDeath的一个实例,什么都不做。 - 否则,将线程名以及
Throwable的轨迹输出到System.err。
- 如果该线程组有父线程组,那么调用父线程组的
-
默认情况下,一个线程会继承构造它的那个线程的优先级。使用
setPriority方法可设置优先级,可设置为MIN_PRIORITY(1)与MAX_PRIORITY(10)之间任何值。(NORM_PRIORITY定义为5)线程的优先级高度依赖于系统。当虚拟机依赖于宿主机平台的线程实现时,Java线程的有限会映射到宿主机平台的优先级。如对于Windows只有7个优先级别,Java的一些优先级会映射到同一个操作系统优先级。在Oracle为Linux提供的Java虚拟机中,会完全忽略线程优先级——所有线程都有相同的优先级。
现在不要使用线程优先级了。
12.4.同步
-
有两种方法防止并发访问代码块:Java5引入的
ReentrantLock类,和synchronized关键字。两者保证串行化访问代码块。-
ReentrantLock类:称为重入锁,因为线程可以反复获得已拥有的锁。锁有一个持有计数来跟踪对
lock方法的嵌套调用(lock加一,unlock减一),持有计数为0时线程释放锁。构造
ReentrantLock对象可以传递boolean值以构造一个采用公平策略的锁。一个公平锁倾向于等待时间最长的线程。不过,这种公平保证可能严重影响性能。所以,默认情况下,不要求锁是公平的。即使使用公平锁,也无法确保线程调度器是公平的。如果线程调度器选择忽略一个已经为锁等待很长时间的线程,它就没有机会得到公平处理。
要把
unclock操作放在finally子句中。如果临界区抛出异常,锁必须释放。否则其他线程将永远阻塞。确保临界区中的代码不要因为抛出异常而跳出临界区。如果在临界区代码结束前抛出了异常,
finally子句释放锁,但是对象可能处于被破坏的状态。使用锁时,就不能使用try-with-resources语句。因为,解锁方法名不是
close,而且它的首部希望声明一个新变量,但是如果使用一个锁,可能想使用多个线程共享的那个变量(而不是新变量)。一个锁对象可以有一个或多个相关联的条件对象。等待获得锁的线程和已经调用了
await方法的线程存在本质上的不同。一旦一个线程调用了await方法,它就进入了这个条件的等待集。当锁可用时,该线程并不会变为可运行状态。实际上,它仍保持非活动状态,直到另一个线程在同一条件上调用singalAll方法。singalAll会重新激活等待这个条件的所有线程。当这些线程从等待集中移出时,它们再次成为可运行的线程,调度器最终将再次将它们激活。同时,它们会尝试重新进入该对象。一旦锁可用,它们中的某个线程将从await调用返回,得到这个锁,并从之前暂停的地方继续执行。此时,线程应当再次测试条件。不能保证现在一定满足条件——singalAll方法仅仅是通知等待的线程:现在有可能满足条件,值得再次检查条件。通常
await调用应该放在如下形式的循环中:while (!(OK to proceed)) { conditon.await(); }从经验上讲,只要一个对象的状态有变换,而且可能有利用等待的线程,就可以调用
singalAll。singal只是随机选择等待集中的一个线程,并解除这个线程的阻塞状态。这比解除所有线程的阻塞更高效,但也存在危险。如果随机选择的线程发现自己仍然不能运行,它就会再次阻塞。如果没有其他线程再次调用singal,系统就会进入死锁。示例:
package synch; import java.util.Arrays; import java.util.concurrent.locks.Condition; import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock; public class Bank { private final double[] accounts; private Lock bankLock; private Condition sufficientFunds; public Bank(int n, double initialBalance) { accounts = new double[n]; Arrays.fill(accounts, initialBalance); bankLock = new ReentrantLock(); sufficientFunds = bankLock.newCondition(); } public void transfer(int from, int to, double amount) throws InterruptedException { bankLock.lock(); try { while (accounts[from] < amount) { sufficientFunds.await(); } System.out.println(Thread.currentThread()); accounts[from] -= amount; System.out.printf(" %10.2f from %d to %d", amount, from, to); accounts[to] += amount; System.out.printf(" Total Balance: %10.2f%n", getTotalBalance()); sufficientFunds.signalAll(); } finally { bankLock.unlock(); } } public double getTotalBalance() { bankLock.lock(); try { double sum = 0; for (double a : accounts) { sum += a; } return sum; } finally { bankLock.unlock(); } } public int size() { return accounts.length; } } -
synchronized关键字:从1.0版本开始,Java中的每个对象都有一个内部锁。如果一个方法声明时有
synchronized关键字,那么对象的锁将保护整个方法。也就是说,要调用这个方法,线程必须获得内部对象锁。内部对象只有一个关联条件。
wait方法将一个线程增加到等待集中,notifyAll/notify方法可以解除等待线程的阻塞。(这三个方法都是Object的final方法)将静态方法声明为同步也是合法的。如果调用这样的一个方法,它会获得相关类对象的内部锁。
内部锁和条件存在一些限制。包括:
- 不能中断一个正在尝试获得锁的线程。
- 不能指定尝试获得锁时的超时时间。
- 每个锁仅有一个条件可能是不够的。
示例:
package synch2; import java.util.Arrays; public class Bank { private final double[] accounts; public Bank(int n, double initialBalance) { accounts = new double[n]; Arrays.fill(accounts, initialBalance); } public synchronized void transfer(int from, int to, double amount) throws InterruptedException { while (accounts[from] < amount) { wait(); } System.out.println(Thread.currentThread()); accounts[from] -= amount; System.out.printf(" %10.2f from %d to %d", amount, from, to); accounts[to] += amount; System.out.printf(" Total Balance: %10.2f%n", getTotalBalance()); notifyAll(); } public synchronized double getTotalBalance() { double sum = 0; for (double a : accounts) { sum += a; } return sum; } public int size() { return accounts.length; } }
对于上述两种方法的使用建议:
- 最好既不使用
Lock/Condition也不使用synchronized关键字。在许多情况下,可以使用java.util.concurrent包中的某种机制,它会为你处理所有的锁定。 - 如果
synchronized关键字适合你的程序,那么尽量使用这种方法,这样可以减少编写的代码量,还能减少出错的概率。 - 如果特别需要
Lock/Condition结构提供的额外功能,则使用Lock/Condition。
-
-
还有另外一种机制获得锁:即进入一个同步块。如以下示例:
public void transfer(Vector<Double> accounts, int from, int to, int amount) { synchronized (accounts) { accounts.set(from, accounts.get(from) - amount); accounts.set(to, accounts.get(to) + amount); } System.out.println(...); }这个方法是可行的,但是完全依赖于这样一个事实:
Vector类会对自己的所有更改方法使用内部锁。(Vector类的文档没有给出这样的承诺。你必须仔细研究源代码,而且还得希望将来的版本不会引入非同步的更改方法。)客户端锁定是非常脆弱的,通常不建议使用。
Java虚拟机对同步方法提供了内置支持。不过,同步块会编译为很长的字节码序列来管理内部锁。
-
监视器。// TODO 2023/11/15 meyok
-
编译器有一个假定:认为内存值只在代码中有显式的修改指令时才会改变。然而内存值有可能被另一个线程改变。
-
volatile关键字为实例字段的同步访问提供了一种免锁机制。如果声明一个字段为volatile,那么编译器和虚拟机就知道该字段可能被另一个线程并发更新。如:private boolean done; public synchronized boolean isDone() { return done; } public synchronized void setDone() { done = true; }或许使用内部对象锁不是一个好主意。如果另一个线程已经对该对象加锁,
isDone和setDone可能会阻塞。如果这是个问题,可以只为这个变量使用一个单独的锁。但是,这会很麻烦。在这种情况下,将字段声明为volatile就很合适:private volatile boolean done; public boolean isDone() { return done; } public void setDone() { done = true; }编译器会插入适当代码,以确保如果一个线程对
done变量做了修改,这个修改对读取这个变量的所有其他线程都可见。volatile变量不能提供原子性。如public void flipDone() { done = !done; }不能确保翻转字段中的值,不能保证读取、翻转和写入不被中断。 -
将字段声明为
final时,可以安全地访问一个共享字段。如:final var accounts = new HashMap<String, Double>();其他线程会在构造器完成构造之后才看到这个
accounts变量。当然,对这个映射地操作并不是线程安全的。如果有多个线程更改和读取这个映射,仍然需要进行同步。 -
java.util.concurrent.atomic包中有很多类使用了高效的机器级指令(而没有使用锁)来保证其他操作的原子性。-
AtomicInteger类提供incrementAndGet和decrementAndGet方法,它们分别以原子方式将一个整数进行自增或自减。如:public static AtomicLong nextNumber = new AtomicLong(); // in some thread... long id = nextNumber.incrementAndGet(); -
如果希望完成更复杂的更新,就必须使用
compareAndSet方法。例如,假设希望跟踪不同线程观察的最大值,下面代码是不行的:AtomicLong largest = new AtomicLong(); // in some thread... largest.set(Math.max(largest.get(), observed));事实上,可以提供一个lambda表达式更新变量,它会为你完成更新:
largest.updateAndGet(x -> Math.max(x, observed));largest.accumulateAndGet(observed, Math::max);getAndUpdate和getAndAccumulate方法返回原值。 -
如果有大量线程要访问相同的原子值,性能会大幅下降,因为乐观更新需要太多次重试。
LongAdder和LongAccumulator类解决了这个问题。LongAdder包括多个变量(加数),其总和为当前值。可以有多个线程更新不同的加数,线程个数增加时会自动提供新的加数。通常情况下,只有当所有工作都完成之后才需要总和的值,对于这种情况,这种方法会很高效。调用increment让计数器自增,或者调用add来增加一个量,另外调用sum来获取总和。如:var adder = new LongAdder(); for (...) { pool.submit(() -> { while (...) { ... if (...) { adder.increment(); } } }); } ... long total = adder.sum();increment方法不会返回原值。这样做会消除将求和分解到多个加数所带来的性能提升。LongAccumulator将这种思想推广到任意的累加操作。在构造器中,可以提供这个操作以及它的零元素。要加入新的值,可以调用accumulate,调用get来获得当前值。如:var adder = new LongAccumulator(Long::sum, 0); // in some thread... adder.accumulate(value);在内部,这个累加器包含变量 \(a_1\)、 \(a_2\)、 ...、 \(a_n\)。每个变量初始化为零元素。调用
accumulate并提供 \(v\) 时,其中一个变量会以原子方式更新为 $ a_i = a_i\ op\ v$,get的结果为 \(a_1\ op\ a_2\ op\ ...\ op\ a_n\)。如果选择一个不同的操作,可以计算最大值或最小值。一般来说,这个操作必须满足结合律和交换律。另外,DoubleAdder和DoubleAccumulator也采用同样的方式,只不过处理的是double值。
-
-
当程序挂起时,按下
[ctrl + \],将得到一个线程转储,这会列出所有的线程。每一个线程都有一个栈轨迹,告诉你线程当前在哪里阻塞。 -
使用
ThreadLocal辅助类可为各个线程提供各自的实例。如
SimpleDateFormat类并不是线程安全的,假如有以下静态变量:public static final SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");如果多个线程都执行以下操作:
String dateStamp = dateFormat.format(new Date());结果会很混乱,因为
dateFormat使用的内部数据结构可能会被并发的访问所破坏。可以使用同步,但开销太大;或者在需要时构造一个局部SimpleDateFormat对象,但这太浪费了(//TODO 2023/11/16 meyok:???)。要为每一个线程构造一个实例,可以使用以下代码:public static final ThreadLocal<SimpleDateFormat> dateFormat = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd"));要访问具体的格式化方法,可以调用:
String dateStamp = dateFormat.get().format(new Date());在一个给定线程中首次调用
get时,会调用构造器中的lambda表达式。此后,get方法方法会返回属于当前线程的那个实例。又如在多个线程中生成随机数也存在类似的问题。
java.util.Random类是线程安全的,但是如果多个线程需要等待一个共享的随机数生成器,这会很低效。可以使用ThreadLcoal辅助类为各个线程提供一个单独的生成器,不过Java7还另外提供了一个便利类,只需要做以下调用:int random = ThreadLocalRandom.current().nextInt(upperBound);ThreadLocalRandom.current()调用会返回特定于当前线程的Random类的实例。 -
stop、suspend和resume方法已经被废弃。stop方法天生就不安全,经验证明suspend方法经常会导致死锁。使用
stop,线程被终止,它会立即释放被它锁定的所有对象的锁。这会导致对象处于不一致的状态。希望停止一个线程的时候应该中断该线程,被中断的线程可以在安全的时候终止。与
stop不同,suspend不会破坏对象。但是,如果用suspend挂起一个持有锁的线程,那么在线程恢复运行之前这个锁是不可用的。如果调用suspend方法的线程试图获得同一个锁,那么程序死锁:被挂起的线程等着被恢复,而将其挂起的线程等待获得锁。想要安全地挂起线程,可以引入一个变量suspendRequested,并在run方法的某个安全的地方测试它,安全的地方是指在这里该线程没有锁定其他线程需要的对象。当该线程发现suspendRequested变量已经设置,将会继续等待,直到再次可用。
12.5.线程安全的集合
-
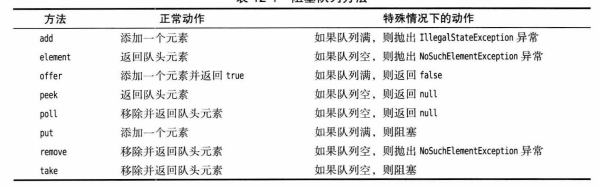
阻塞队列的方法:
![]()
阻塞队列方法分为以下3类,这取决于当队列满或空时它们完成的动作:
-
put和take:如果使用队列作为线程管理工具使用这两个方法,不能完成任务会阻塞。它们与不带超时参数的offer和poll方法等效。 -
add、remove和element:当试图向满队列添加元素或从空队列得到队头元素时,抛出异常。 -
offer、poll和peek:如果不能完成任务,只是给出一个错误提示而不是异常。poll和peek方法返回null来指示失败。因此,向这些队列插入null值是非法的。offer和poll方法还有给出超时时间的版本,超时时offer会返回false,poll会返回null。
-
-
java.util.concurrent包提供了阻塞队列的几个变体。默认情况下:LinkedBlockingQueue的容量没有上界,但是可以指定一个最大容量。LinkedBlockingDeque是一个双端队列。ArrayBlockingQueue在构造时需要指定容量,并且有可选参数指定是否需要公平性。PriorityBlockingQueue是一个优先队列。元素按照优先级顺序移除。这个队列没有容量上界。但是队列为空时,获取元素的操作会阻塞。DelayQueue包含实现了Delayed接口的对向。getDelay方法返回对象的剩余延迟,负值表示延迟已经结束。元素只有在延迟结束的情况下才能从DelayQueue移除。还需要实现compareTo方法,DelayQueue使用该方法对元素进行排序。TransferQueue接口,Java7新增。允许生产者线程等待,直到消费者准备就绪可以接受元素。如果生产者调用q.transfer(item),会阻塞,直到另一个线程将元素(item)删除。LinkedTransferQueue类实现了这个接口。
-
java.util.concurrent包提供了映射、有序集和队列的高效实现:ConcurrentHashMap、ConcurrentSkipListMap、ConcurrentSkipListSet和ConcurrentLinkedQueue。这些集合使用复杂的算法,通过允许并发地访问数据结构的不同部分尽可能减少竞争。这些类的
size方法并不一定在常量时间内完成操作,确定这些集合的当前大小通常需要遍历。size方法只能返回int,对于庞大的并发散列映射,mappingCount方法可以把大小作为long返回。集合返回弱一致性的迭代器,这意味着迭代器不一定能反映出它们构造之后的所有更改。但是,它们不会将同一个值返回两次,也不会抛出
ConcurrentModificationException异常。java.util包中的集合,在迭代器构造之后发生改变,迭代器会抛出ConcurrentModificationException异常。并发散列映射支持大量阅读器和一定数量书写器。在默认情况下认为可以有至多16个同时运行的书写器,可以有更多,但同一时间多于16其他线程将暂时阻塞。
在较新的Java版本中,并发散列映射将桶组织为树,而不是列表,键类型实现
Comparable,从而保证性能为 \(O(log(n))\)。 -
如果多个线程修改一个普通的
HashMap,可能破坏内部的数据结构,有些链接可能丢失,或者甚至构成循环,使得这个数据结构不再可用。对于ConcurrentHashMap绝对不会发生这种情况,get和put代码永远不会破坏数据结构。不过,由于操作序列不是原子的,所以结果不可预知。 -
对于映射条目的原子更新:
在老版本中,使用
replace操作,它会以原子方式用一个新值替换原子,前提是之前没有其他线程把原值替换为其他值。必须一直这样做,直到替换成功:do { oldValue = map.get(word); newValue = oldValue == null ? 1 : oldValue + 1; } while (!map.replace(word, oldValue, newValue));或者使用
ConcurrentHashMap<String, AtomicLong>:map.putIfAbsent(word, new AtomicLong()); map.get(word).incrementAndGet();如今,Java API提供了一些新的方法更方便地完成原子更新。调用
compute方法时,可以提供一个键和一个计算新值地函数。这个函数接受键和相关联地值(如果没有值,则为null),它会计算新值。如:map.compute(word, (k, v) -> v == null ? 1 : v + 1);ConcurrentHashMap中不允许有null值,null值用来指示映射中某个给定的键不存在。computeIfPresent和computeIfAbsent方法,它们分别只在已有、没有原值的情况下计算新值。如:map.computeIfAbsent(word, k -> new LongAdder()).increment();merge方法有一个参数表示键不存在时使用的初始值,否则就调用提供的函数来结合原值和初始值(与compute不同,这个提供的函数不处理键)。如:map.merge(word, 1L, (existingValue, newValue) -> existingValue + newValue);或者写为:
map.merge(word, 1L, Long::sum);如果传入
compute或merge的函数返回null,将从映射中删除现有的条目。使用
compute、merge时,所提供的函数不能做太多的工作。这个函数运行时,可能会阻塞对映射的其他更新操作。当然,这个函数也不能更新映射的其他部分。 -
Java API为并发散列对象提供了批操作。即使有其他线程在处理映射,这些操作也能安全地执行。批操作会遍历映射,处理遍历过程中找到的元素。这里不会冻结映射的当前快照。除非恰好知道批操作运行时映射不会修改,否则就要把结果看作是映射状态的近似。
有3种不同的操作:
- search(搜索):为每个键或值应用一个函数,直到函数生成一个非
null的结果。然后搜索终止,返回这个函数的结果。 - reduce(归约):组合所有键或值,这里要使用所提供的一个累加函数。
- forEach:为所有键或值应用一个函数。
每个操作都有4个版本:operationKeys处理键、operationValues处理值、operation处理键和值、operationEntries处理
Map.Entry对象。对于以上各个操作,需要指定一个参数化阈值。如果映射包含的元素多于这个阈值,就会并行完成操作。如果希望批操作在一个线程种运行,阈值设为
Long.MAX_VALUE,如果希望用尽可能多的线程运行批操作,阈值设为1。如希望找出第一个出现次数超过1000次的单词,可使用:
String result = map.search(threshold, (k, v) -> v > 1000 ? k : null);result会设置为第一个匹配的单词,或者如果搜索函数对所有输入都返回null,则返回null。forEach方法有两种形式。第一种形式只对各个映射条目应用一个消费者函数,如:map.forEach(threshold, (k, v) -> System.out.println(k + " -> " + v));第二种形式含有一个额外的转换器函数作为参数,要先应用这个函数,其结果会传递到消费者。只要这个转化器返回
null,这个值就会被悄无声息地跳过。如:map.forEach( threshold, (k, v) -> v > 1000 ? k + " -> " + v : null, // filter and transfermer System.out::println // the nulls are not passed to the consumer );reduce操作用一个累加函数组合其输入。与forEach类似,也可提供一个转换函数。如:Long sum = map.reduceValues(threshold, Long::sum); Integer maxLength = map.reduceValues( threshold, String::length, Integer::max );如果映射为空,或者所有条目都被过滤掉,
reduce操作会返回null。如果只有一个元素,则返回其转换结果,不会应用累加器。对于
int、long和double输出还有相应地特殊化操作,分别有后缀ToInt、ToLong和ToDouble。需要把输入转换为一个基本类型值,并指定一个默认值和一个累加器函数映射为空时返回默认值。如:long sum = map.reduceValuesToLong( threshold, Long::longValue, // transformer to primitive type 0, // default value for empty map Long::sum // primitive type accumulator );这些特殊化版本与对象版本的操作有所不同,对于对象版本的操作,只需要考虑一个元素。这里不是返回转换得到的元素,而是要与默认值累计。因此,默认值必须时累加器的零元素。
- search(搜索):为每个键或值应用一个函数,直到函数生成一个非
-
没有
ConcurrentHashSet类,不过可以使用ConcurrentHashMap的静态方法newKeySet获得对应的Set<K>,这实际上是ConcurrentHashMap<K, Boolean>的一个包装器(所有映射值都为Boolean.True,不过因为指示把它作为一个集,所以并不关心映射值)。如:Set<String> words = ConcurrentHashMap.<String>newKeySet();如果原来有一个映射,使用它的
keySet方法可以生成这个映射的键集。删除这个集中的元素,键(以及相应的值)也会从映射种删除。不过向键集中增加元素没有意义,因为没有相应的值可以增加。为此,ConcurrentHashMap还有第二个keySet方法,它包含一个默认值,为集增加元素时可使用这个方法:Set<String> words = map.keySet(1L); words.add("Java");如果”Java“在words中不存在,现在它会有一个值1。
-
CopyOnWriteArrayList和CopyOnWriteArraySet是线程安全的集合,其中所有的更改器会建立底层数组的一个副本。如果迭代访问集合的线程数超过更改集合的线程数,这样的安排是很有用的。当构造一个迭代器的时候,它包含当前数组的一个引用。如果这个数组后来被更改了,迭代器仍然引用旧数组,但是,集合的数组已经替换。因而,原来的迭代器可以访问一致(但可能过时的)视图,而且不存在任何同步开销。 -
Arrays类提供了大量并行化操作。静态Arrays.parallelSort方法可以对一个基本类型值或对象的数组排序,对对象排序时,可以提供一个Comparator。如:Arrays.parallelSort(words); Arrays.parallelSort(words, Comparator.comparing(String::length));对于所有方法都可提供一个边界,如:
values.parallelSort(values.length / 2, values.length);parallelSetAll方法会用由一个函数计算得到的值填充一个数组。这个函数接受元素索引,然后计算相应位置上的值。如:Arrays.parallelSetAll(values, i -> i % 10);parallelPrefix方法会用一个给定结合操作的相应前缀的累加结果替换各个数组元素。如:考虑数组[1, 2, 3, 4, ....]和x操作Arrays.parallelPrefix(values, (x, y) -> x * y);后为:
[1, 1 * 2, 1 * 2 * 3, 1 * 2 * 3 * 4, ....]。 -
任何集合类都可以通过使用同步包装器编程线程安全的。
如果希望迭代访问一个集合对象,同时另一个线程仍有机会更改这个集合,那么仍然需要使用”客户端“锁定。如果使用”for each“循环,就必须使用相同的代码,因为循环使用了一个迭代器。
最好使用
java.util.concurrent包中定义的集合,而不是同步包装器。经常更改的数组列表是一个例外。在这种情况下,同步的ArrayList要胜过CopyOnWriteArrayList。
12.6.任务和线程池
-
Runnable封装一个异步执行的任务,可以把它想象成一个没有参数的返回值和异步方法。Callable与Runnable类似,但是有返回值。Callable接口是一个参数化的类型,类型参数是返回值的类型,只有一个方法call。 -
Future保存异步计算的结果。Future对象的所有者在结果计算好之后就可以获得结果。Future<V>有以下方法:V get() V get(long timeout, TimeUnit unit) void cancel(boolean mayInterrupt) boolean isCancelled() boolean isDone()get方法调用会阻塞,第一个直到计算完成,第二个如果在计算完成之前调用超时,会抛出TimeoutException异常。如果允许该计算的线程被中断,会抛出InterruptedException异常。如果计算已经完成,get方法立即返回。cancel方法取消计算。如果计算还未开始,则不再开始。如果计算正在进行且mayInterrupt参数为true,它就会被中断。isDone方法检查计算是否还在进行。取消一个任务涉及两个步骤:必须找到并中断底层线程,另外任务实现(在
call方法中必须感知到中断,并放弃它的工作。如果一个Future对象不知道任务在哪个线程中执行,或者如果任务没有监视执行该任务的线程的中断状态,那么取消任务没有任何效果。 -
FutureTask实现了Future和Runnable接口。示例代码:
Callable<Integer> task = ...; FutureTask<Integer> futureTask = new FutureTask<>(task); Thread t = new Thread(futureTask); t.start(); ... Integer result = futureTask.get(); -
更常见的情况是,可以将一个
Callable传递到一个执行器。执行器(
Executors)类有许多静态工厂方法,用来构造线程池:![]()
newCachedThreadPool:构造一个线程池,会立即执行各个任务。如果有空闲线程可用,就使用现有的空闲线程执行任务,否则创建一个新线程。newFixedThreadPool:构造一个固定大小的线程池。如果提交的任务数多于空闲线程数,非得到服务的线程会被放到队列中,当其他任务完成以后再运行这些排队的任务。newSingleThreadExecutor:一个退化了的大小为1的线程池。由一个线程顺序地执行所提交地任务。
这3个方法返回实现了
ExecutorService接口的ThreadPoolExecutor类的对象。Java EE提供的
ManagedExecutorService子类很适用于Java EE环境中的并发任务。使用
submit方法将Runnable或Callable对象提交给ExecutorService:Future<T> submit(Callable<T> task) Future<?> submit(Runnable task) Future<T> submit(Runnable task, T result)线程池会在方便的时候尽早执行提交的任务。第二个
sumbit方法返回Future<?>,它可以执行isDone、cancel、isCancelled,但是get方法返回null(Runnable没有返回值)。第三个submit方法返回的Future<T>,它的get方法返回指定的result。使用完一个线程池时,调用
shutdown方法,启动线程池的关闭序列。被关闭的执行器不再接受新的任务,当所有任务都完成时,线程池中的线程死亡。shutdownNow方法会取消所有尚未开始的任务。Executors的newScheduledThreadPool和newSingleThreadScheduledPool方法返回实现了ScheduledExecutorService接口的对象。ScheduledExecutorService接口为调度执行或重复执行任务提供了一些方法,这是对支持建立线程池的java.util.Timer的泛化。可以调度Runnable或Callable在一个初始延迟之后运行一次,也可以调度Runnable定期运行。 -
执行器中的
invokeAny方法提交一个Callable对象集合中的所有对象,并返回某个已完成任务的结果。我们不知道返回的究竟是哪个任务的结果,这往往是最快完成的那个任务。执行器中的
invokeAll方法提交一个Callable对象集合中的所有对象,这个方法会阻塞,直到所有任务都完成,并返回表示所有任务答案的一个Future对象列表。如:List<Callable<T>> tasks = ...; List<Future<T>> results = executor.invokeAll(tasks); for (Future<T> result : results) { processFurther(result.get()); }for循环中,第一个result.get()会阻塞直到第一个结果可用,如果所有任务几乎同时完成,这不会有问题。如果需要按计算出结果的顺序得到这些结果,可以使用ExecutorCompletionService来管理。该服务会管理Future对象的一个阻塞队列,其中包含所提交任务的结果(一旦结果可用,就会放入队列)。如:var service = new ExecutorCompletionService<T>(executor); for (Callable<T> task : tasks) { service.submit(task); } for (int i = 0; i < tasks.size(); i++) { processFurther(service.take().get()); }代码示例:
package executors; import java.io.IOException; import java.nio.file.Files; import java.nio.file.Path; import java.time.Duration; import java.time.Instant; import java.util.*; import java.util.concurrent.*; import java.util.stream.Collectors; import java.util.stream.Stream; public class ExecutorDemo { public static long occurrences(String word, Path path) { try (var in = new Scanner(path)) { int count = 0; while (in.hasNext()) { if (in.next().equals(word)) { count++; } } return count; } catch (IOException ex) { return 0; } } public static Set<Path> descendant(Path rootDir) throws IOException { try (Stream<Path> entries = Files.walk(rootDir)) { return entries.filter(Files::isRegularFile).collect(Collectors.toSet()); } } public static Callable<Path> searchForTask(String word, Path path) { return () -> { try (var in = new Scanner(path)) { while (in.hasNext()) { if (in.next().equals(word)) { return path; } if (Thread.currentThread().isInterrupted()) { System.out.println("Search in " + path + " canceled."); return null; } } } throw new NoSuchElementException(); }; } public static void main(String[] args) throws IOException, InterruptedException, ExecutionException { try (var in = new Scanner(System.in)) { System.out.print("Enter base directory (e.g. /opt/jdk-9-src): "); String start = in.nextLine(); System.out.print("Enter keyword (e.g. volatile): "); String word = in.nextLine(); Set<Path> files = descendant(Path.of(start)); var tasks = new ArrayList<Callable<Long>>(); for (Path file : files) { Callable<Long> task = () -> occurrences(word, file); tasks.add(task); } ExecutorService executor = Executors.newCachedThreadPool(); Instant startTime = Instant.now(); List<Future<Long>> results = executor.invokeAll(tasks); long total = 0; for (Future<Long> result : results) { total += result.get(); } Instant endTime = Instant.now(); System.out.println("Occurrences of " + word + ": " + total); System.out.println("Time elapsed: " + Duration.between(startTime, endTime).toMillis() + " ms"); var searchTasks = new ArrayList<Callable<Path>>(); for (Path file : files) { searchTasks.add(searchForTask(word, file)); } Path found = executor.invokeAny(searchTasks); System.out.println(word + " occurs in: " + found); if (executor instanceof ThreadPoolExecutor) { System.out.println("Largest pool size: " + ((ThreadPoolExecutor) executor).getLargestPoolSize()); } executor.shutdown(); } } } -
fork-join框架,需要提供一个扩展
RecursiveTask<T>的类(如果计算会生成一个类型为T的结果)或者提供一个扩展RecursiveAction的类(如果不生成任何任务)。再覆盖compute方法来生成并调用子任务,然后合并其结果。

在后台,fork-join框架使用了一种有效的智能方法来平衡可用线程的工作负载,这种方法称为工作密取。每个工作线程都有一个双端队列来完成任务。一个工作线程将子任务压入其双端队列的队头。(只有一个线程可以访问队头,所以不需要加锁。)一个工作线程空闲时,它会从另一个双端队列的队尾“密取”一个任务。由于大的子任务都在队尾,这种密取很少出现。
fork-join池是针对非阻塞工作负载优化的。如果向一个fork-join池增加很多阻塞任务,会让它无法有效工作。可以让任务实现
ForkJoinPool.ManagedBlocker接口来解决。
代码示例:
package forkJoin;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import java.util.function.DoublePredicate;
public class ForkJoinTest {
public static void main(String[] args) {
final int SIZE = 10_000_000;
var numbers = new double[SIZE];
for (int i = 0; i < SIZE; i++) { numbers[i] = Math.random(); }
var counter = new Counter(numbers, 0, numbers.length, x -> x > 0.5);
var pool = new ForkJoinPool();
pool.invoke(counter);
System.out.println(counter.join());
}
}
class Counter extends RecursiveTask<Integer> {
public static final int THRESHOLD = 1000;
private double[] values;
private int from;
private int to;
private DoublePredicate filter;
public Counter(double[] values, int from, int to, DoublePredicate filter) {
this.values = values;
this.from = from;
this.to = to;
this.filter = filter;
}
@Override
protected Integer compute() {
if (to - from < THRESHOLD) {
int count = 0;
for (int i = from; i < to; i++) {
if (filter.test(values[i])) { count++; }
}
return count;
} else {
int mid = (from + to) / 2;
var frist = new Counter(values, from, mid, filter);
var second = new Counter(values, mid, to, filter);
invokeAll(frist, second);
return frist.join() + second.join();
}
}
}
compute方法中,invokeAll方法接收到很多任务并阻塞,直到所有这些任务全部完成。join方法将生成结果。我们对每个子任务引用join,返回其总和。
还有
get方法可得到结果,不过它可能抛出检查型异常而没使用。
12.7.异步计算
-
Future对象的get方法获得值时会阻塞,直到值可用。CompletableFuture类实现了Future接口,它提供了获得结果的另一种机制:需要注册一个回调,一旦结果可用,就会(在某个线程中)利用该结果调用这个回调。通过这种方式,无需阻塞就可以在结果可用时对结果进行处理。如:CompletableFuture<String> f = ...; f.thenAccept(s -> Process the result string s); -
想要异步运行任务并得到
CompletableFuture,不要把它直接提交给执行器服务,而应当调用静态方法CompletableFuture.supplyAsync。如:public CompletableFuture<String> readPage(URL url) { return CompletableFuture.supplyAsync(() -> { try { return new String(url.openStream().readAllBytes(), "UTF-8"); } catch (IOException e) { throw new UncheckedIOException(e); } }, executor); }如果省略执行器,任务会在一个默认的执行器(具体为
ForkJoinPool.commanPool()返回的执行器)上执行。supplyAsync方法的第一个参数是Supplier<T>而不是Callable<T>,他不能抛出检查型异常。 -
CompletableFuture可以采用两种方式完成:得到一个结果,或者有一个未捕获的异常。处理这两种情况使用whenComplete方法。要对结果(没有的话为null)调用所提供的函数。如:f.whenComplete((s, t) -> { if (t == null) { // Process the result s } else { // Process the Throwable t } }); -
CompletableFuture之所以被称为可完成的,是因为可以手动的设置一个完成值。(在其它并发库中,这样的对象被称为承诺)使用supplyAsync创建一个CompletableFuture时,任务完成时会隐式地设置完成值。不过也可显式的设置,以提供更大的灵活性。如:var f = new CompletableFuture<Integer>(); executor.execute(() -> { int n = workHard(arg); f.complete(n); }); executor.execute(() -> { int n = workSmart(arg); f.complete(n); });对一个异常完成
future,调用:Throwable t = ...; f.completeExceptionally(t);可以在多个线程中在同一个
future上安全地调用complete或completeExceptionlly。如果这个future已完成,这些调用没有任何作用。isDone方法指出一个Future对象是否已经完成(正常完成或产生一个异常)。在前面的例子中,如果结果已经由另一个方法得出,workHard和workSmart方法可以使用这个信息停止工作。与普通
Future不同,调用cancel方法时,CompletableFuture的计算不会中断。取消只会把这个Future对象设置为以异常方式完成(有一个CancellationException异常)。 -
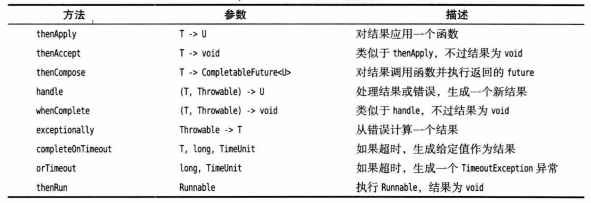
CompletableFuture类提供了一种机制,可以将异步任务组合为一个处理管线。为
CompletableFuture对象添加一个动作的方法:以下表中
... -> ...表示函数式接口的类型,不是真正的Java类型。每个方法还有相应的两个Async形式,一种用于共享一个ForkJoinPool,另一种有一个Executor参数。![]()
组合多个
Future的方法:![]()
![]()
前3个方法并发运行一个
CompletableFuture<T>和一个CompletableFuture<U>动作,并组合完成。中间3个方法并发运行两个
CompaletableFuture<T>动作。一旦其中一个动作完成,就传递它的结果,并忽略另一个结果。最后2个方法取一组可完成
Future(数目可变),并生成一个CompletableFuture<Void>,它会在所有这些Future都完成时或者其中任意一个Future完成时结束。allOf方法不会生成任何结果。anyOf方法不会终止其余的任务。理论上这一节介绍的方法接受
CompletionStage类型的参数,而不是CompletableFuture。CompletionStage接口描述如何组合异步计算,而Future接口强调的是计算的结果。CompletableFuture即是CompletionStage,也是Future。


12.8.进程
-
Process类在一个单独的OS进程中执行一个命令,允许我们与标准输入、输出和错误流交互。ProcessBuilder类则允许我们配置Process对象。ProcessBuilder类可以取代Runtime.exec调用,且更为灵活。 -
创建一个进程:
指定要执行的命令,可以是
List<String>,也可以是命令字符串,其中第一个字符串必须是可执行命令,而不是一个shell内置命令。如:var builder = new ProcessBuilder("gcc", "myapp.c");默认情况下,进程工作目录与虚拟机相同,可使用
directory方法修改工作目录:builder = huilder.directory(path.toFile());配置
ProcessBuilder的各个方法都返回自身,所以可以把命令串起来:Process p = new ProcessBuilder(command).directory(file)...start();Process的getOutputStream、getInputStream和getErrorStream获取标准输入、输出和错误流的管道。进程的输入流是JVM的一个输出流,进程的输出流和错误流是JVM的输入流。可指定新进程的这三个流与JVM相同:builder.redirectIO();如果只想进程某些流,可以把值
ProcessBuilder.Redirect.INHERIT传入ProcessBuilder的redirectInput、redirectOutput和redirectError方法。这些方法也可传入File对象,将流重新重定向到文件。进程启动时,会创建或删除输出和错误文件。要追加到现有文件,可以使用:builder.redirectOutput(ProcessBuilder.Redirect.appendTo(outputFile));合并输出和错误流使用:
builder.redirectErrorStream(true),如果这样做,就不能使用ProcessBuilder的redirectError方法和Process的getErrorStream方法。修改进程的环境变量示例:
Map<String, String> env = builder.environment(); env.put("LANG", "fr_FR"); env.remove("JAVA_HOME"); Process p = builder.start();Java9提供的
startPipeline方法,可以传入一个进程构造器列表,并从最后一个进程读取结果,实现类似于shell的|操作符,管道功能。如:List<Process> processes = ProcessBuilder.startPipeline( List.of( new ProcessBuilder("find", "/opt/jdk-9"), new ProcessBuilder("grep", "-o", "\\.[^./]*$"), new ProcessBuilder("sort"), new ProcessBuilder("uniq") ) ); Process last = process.get(process.size() - 1); var result = new String(last.getInputStram().readAllBytes()); -
配置构造器后,调用
start方法启动进程。如:Process process = new ProcessBuilder("/bin/ls", "-l") .directory(Path.of("/tmp").toFile()) .start(); try (var in = new Scanner(process.getInputStream())) { while (in.hasNextLine()) { System.out.println(in.nextLine()); } }进程流的缓存空间是有限的。如果有大量的输入和输出,可能需要在单独的线程中生成和消费这些输入输出。
等待进程完成,可使用
waitFor方法。无参数版本的按照管理,返回0表示成功,否则失败。可提供带时间限制的版本,进程未超时返回true,使用exitValue获取退出值。如:long delay = ...; if (process.waitFor(delay, TimeUnit.SECONDS)) { int result = process.exitValue(); ... } else { process.destroyForcibly(); }调用
isAlive可查看进程是否仍然存活。要杀死进程,使用destroy或destroyForcibly,两者区别取决于平台。如UNIX上,前者会以SIGTERM终止线程,后者以SIGKILL终止线程。(如果destroy方法可以正常终止线程,supportsNormalTermination方法将返回true)进程完成时会接受到一个异步通知,调用
onExit会得到一个COmpletableFuture<Process>,可以用来调度任何动作。如:process.onExit().thenAccept(p -> System.out.println("Exit value: " + p.exitValue())); -
要获得程序启动的一个进程的更多信息,或者想更多地了解计算机上正在允许的任何其他进程,可以使用
ProcessHandle接口(句柄)。有以下方法获得该接口:- 调用
Process的toHandle方法获取该process的ProcessHandle。 - 调用
ProcessHandle.of(id)获取对应操作系统进程ID的句柄。 Process.current()是运行这个JVM的进程的句柄。ProcessHandle.allProcesses()生成对当前进程可见的所有操作系统进程的Stream<ProcessHandle>。
ProcessHandle的pid、parent、children和descendants方法获取进程ID、父进程、子进程和后代进程。allProcesses、children和descendants方法返回的Stream<ProcessHandle>示例只是当时的快照。info方法可以生成一个ProcessHandle.Info对象,它提供了一些方法来获得进程的有关信息:arguments、command、commandLine、startInstant、totalCpuDuration、user,所有这些方法都返回Optional值,因为可能某个特定的OS不能报告这个信息。要监视或强制进程终止,与
Process类一样,ProcessHandle接口也有isAlive、supportsNormalTermination、destory、destoryForcibly和onExit方法,不过没有对应的waitFor方法。 - 调用
第13章 Java8的流库
13.1.从迭代到流的操作
-
集合的
parallelStream方法让流库以并行方式来执行过滤和计数。 -
流较于集合的区别:
- 流不存储元素。这些元素可能存储于底层集合,或者按需生成。
- 流操作不会修改其数据源。
- 流操作是尽可能惰性执行的。这意味着直至需要其结果时,操作才会执行。
13.2.流的创建
-
对于数组,使用
Stream.of()方法。Arrays.stream(array, from, to)可使用数组的一部分创建流。Stream.empty()创建不包含任何元素的流。Stream.generate(supplier)、Stream.iterate(seed, function)创建无限流,Stream.iterator(seed, predicate, function)添加Predicate<T>指定无限流的结束。Stream.ofNullable(element)使用一个对象创建长度为 0(element 为 null)或 1 的流。其它方法:
Stream<String> words = Pattern.compile("\\PL+").splitAsStream(contents);try (Stream<String> lines = Files.lines(path)) { // Process lines }StreamSupport.stream(iterable.spliterator(), false);StreamSupport.stream(Spliterators.spliteratorUnknownSize(iterator, Spliterator.ORDERED), false); -
流并没有收集其数据,数据一直存储在单独的集合种。如果修改了该集合,那么流操作的结果就会变成未定义的。流操作是惰性的,在终止操作得以执行时,集合可能已经发生了变换。
13.3.filter、map 和 flatMap 方法
// TODO:9,单子论。
13.4.抽取子流和组合流
- limit、skip、takeWhile、dropWhile、Stream.concat(stream1, tream2)(stream1 不应该是无限的,否则 stream2 无机会被处理)。
13.5.其它的流转换
-
distinct 会剔除重复元素,会保持稳定性。
-
stream.peek(consumer)不会剔除元素,只是调用消费函数。在 IDE 中,如果只想了解在流管道的某个特定点上会发生什么,那么可以添加以下代码,并在第二行上设置断点:
.peek(x -> { return; }).
13.6.简单约简
stream.count()返回 long 类型。stream.max(comparator)、stream.min(comparator)、stream.findFirt()、stream.findAny()(一般针对并行流)返回Option<T>值。stream.anyMatch(predicate)、stream.allMatch(predicate)、stream.noneMatch(predicate)返回 boolean。
13.7.Optional 类型
-
有效地使用 Optional 的关键在于:在值为 null 时会产生一个替代物,另一条策略是只有值存在时才消费该值。
optionalT.orElse(T); optionalT.orElseGet(supplier<T>); optional.<X extends Throwable>orElseThrow(supplier<? extends X>);optional.ifPresent(consumer); optional.ifPresentOrElse(consumer, runnable); -
optional.map(function); optional.flatMap(function); optional.filter(predicate).map(function); optional.or(supplier); // 将空 Optional 转换为一个可替代的 Optional -
optional.get()在值不存在时抛出异常(该方法在 Java 10 中有同义词optional.orElseThrow())。optional.isPresent()报告是否存在值。 -
Optional 类型正确的用法提示:
- Optional 类型的变量永远不应该为 null。
- 不要使用 Optional 类型的域。因为其代价是额外多出来一个对象。在类的内部,使用 null 表示缺失的域更容易操作。
- 不要在集合中放置 Optional 对象,并且不要将它们用作 map 的键。应该直接收集其中的值。
-
创建 Optional 值可使用:
Optional.of(element)(不能为 null)、optional.empty()、Optional.ofNullable(element)。 -
上面可以被下面代替:
// Optional<User> lookup(String id); ids.map(User::lookup).filter(Optional::isPresent).map(Optional::get); ids.map(User::lookup).flatMap(Optional::stream);Optional::stream会在值是否存在时返回Stream.empty()或Stream.of(value)。// User classicLookup(String id); ids.map(User::classicLookup).filter(Objects::nonNull); ids.flapMap(id -> Stream.ofNullable(User.classicLookup(id))); ids.map(User::classicLookup).flapMap(Stream::ofNullable);
13.8.收集结果
-
处理完流后,使用 iterator 方法产生迭代器;forEach 方法将函数应用于每个元素(并行流会按任意顺序,要按流中顺序使用 forEachOrdered 方法);使用 toArray 方法将结果收集到数组中(默认收集到 Object[] 数组,要数组的特定类型需要传入数组的 new 方法,如
String[]::new)。 -
将流中元素收集到另一个目标中,可使用 collect 方法,接受一个 Collector 接口的实例。Collectors 类提供了大量用于生成常见收集器的工厂方法。如:
List<String> result = stream.collect(Collectors.toList()); Set<String> result = stream.collect(Collectors.toSet()); TreeSet<String> result = stream.collect(Collectors.toCollection(TreeSet::new)); String result = stream.collect(Collectors.joining()); String result = stream.collect(Collectors.joining(", "));如果想要将结果约简为总和、数量、平均值、最大值或最小值,可以使用 summarizing(Int|Long|Double) 方法中的一个,产生 (Int|Long|Double)SummaryStatistics 对象,调用其方法获取。如:
IntSummaryStatistics summary = stream.collect(Collectors.summarizingInt(String::length)); summary.getAverage(); summary.getMax();
13.9.收集到映射表中
-
Collectors.toMap 方法第一个函数引元用于生成键,第二个函数引元用于生成值,还可以有第三个函数引元用于处理键冲突(否则没有就会抛出异常),还可以有第四个函数引元用于指定特定的 Map 类型。如:
Map<Integer, Person> idToPerson = people.collect( Collectors.toMap( Person::getId, Function::identify(), binaryOperator, TreeMap::new ) );对于每一个 toMap 方法,都含有一个等价的可以产生并发映射表的 toConcurrentMap 方法。单个并发映射表可以用于并行集合处理。当使用并行流时,共享的映射表比合并映射表更高效。注意,元素不再是按照流中的顺序收集的。
13.10.群组和分区
-
将具有相同特性的值群聚成组:
Map<String, List<Locale>> countryToLocales = locales.collect(COllectors.groupingBy(Locale::getCountry));当分类函数是 Predicate 时,使用 partitioningBy 更高效:
Map<Boolean, List<Locale>> englishAndOtherLocales = locales.collect(COllectors.partitioningBy(l -> l.getLanguage().equals("en")));如果使用 groupingByConcurrent 方法,就会在使用并行流时获得一个被并行组装的并行映射表。
13.11.下游收集器
-
groupingBy 方法产生的映射表中值都是列表,假如要对该列表进行处理,则需要下游收集器。如(假如导入了 Collectors 中所有静态方法):
Map<String, Set<Locale>> countryToLocaleSet = locales.collect(groupingBy(Locale::getCountry, toSet())); Map<String, Long> countryToLocaleCounts = locales.collect(groupingBy(Locale::getCountry, counting())); Map<String, Integer> stateToCityPopution = cities.collect(groupingBy(City::getState, summingInt(City::getPopulation))); Map<String, IntSummaryStatistics> stateToCityPoputionSummary = cities.collect(groupingBy(City::getState, summarizingInt(City::getPopulation))); Map<String, Optional<City>> stateToLargestCity = cities.collect(groupingBy(City::getState, maxBy(Comparator.comparing(City::getPopulation))));Map<Character, Integer> stringCountsByStartingLetter = strings.collect(groupingBy(s -> s.charAt(0), collectingAndThen(String::length, toSet()))); Map<Character, Set<Integer>> stringLengthsByStartingLetter = strings.collect(groupingBy(s -> s.charAt(0), mapping(String::length, toSet())); Map<String, Set<String>> countryToLanguages = locales.collect(groupingBy(Locale::getDisplayCountry, mapping(Locale::getDisplayLanguage, toSet()))); Map<String, Set<City>> largeCitiesByState = cities.collect(groupingBy(City::getState, filtering(c -> c.getPopulation() > 500_000, toSet())));
13.12.约简操作
-
Optional<T> reduce(BinaryOperator<T> accumulator); T reduce(T identity, BinaryOperator<T> accumulator); <U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);约简操作要求是可结合的,即组合元素时使用的顺序没有影响,如减法就不是可结合的。
第二种提供了一个初始值,当流为空时,不返回空 Optional 而是 identity。第三种用于处理非 (T, T) -> T 而是 (U, T) -> U 的函数,不过当计算并行化时,需要结合 U 与 U,所以还需要提供第二个结合函数。如获取流中所有字符串长度之和:
int sum = values.stream().reduce(0, (total, word) -> total + word.length(), Integer::sum);
13.13.基本类型流
- 流库中有专门的 IntStream、LongStream、DoubleStream 用来直接存储基本类型值,而无须使用包装器。
- 创建 IntStream 流有 Intstream.of、Arrays.stream 方法。IntStream 依然有静态 generate、iterate 方法,IntStream、LongStream 有静态方法 range、rangeClosed 用于生成步长为 1 的整数范围。
- CharSequence 的 codePoints 和 chars 方法,用于生成由字符的 Unicode 码或由 UTF-16 编码机制的码元构成的 IntStream。
- 对于对象流可使用 maoToInt、mapToLong、mapToDouble 转换为基本类型流。
- boxed 方法将基本类型流转换为对象流。
- 基本类型流与对象流的主要差异:
- toArray 方法返回基本类型数组。
- 产生可选结果的方法返回 OptionalInt、OptionalLong、OptionalDouble,具有 getAsInt、getAsLong、getAsDouble 方法而不是 get 方法。
- 具有分别返回总和、平均值、最大值、最小值的 sum、average、max、min 方法。
- summaryStatistics 方法会产生一个类型为 IntSummaryStatistics、LongSummaryStatistics、DoubleSummaryStatistics 的对象。
- Random 类具有 ints、longs、doubles 方法,它们会返回由随机数构成的基本类型流。如果需要的是并行流中的随机数,那么需要使用 SplittableRandom 类。
13.14.并行流
-
Collection 的 parallelStream 方法获取并行流,任意流的 parallel 方法将其转换为并行流。只要在终结方法执行时流处于并行模式,所有中间流操作就都将被并行化。
-
当流操作并行运行时,其目标是让其结果与顺序执行时返回的结果相同。重要的是,这些操作是无状态的,并且可以以任意顺序执行。如以下短单词计数代码就不是正确的,每次执行结果并不一定相同:
int[] shortWords = new int[12]; words.parallelStream().forEach(s -> { if (s.length() < 12) { shortWords[s.length()]++; } });可以修改为:
Map<Integer, Long> shortWordCounts = words.parallelStream().filter(s -> s.length() < 12).collect(groupBy(String::length, counting())); -
默认情况下,从有序集合(数组和列表)、范围、生成器和迭代器产生的流,或者通过调用 Stream.sorted 产生的流,都是有序的。它们的结果是按照原来元素顺序累积的,因此是完全可预知的。排序并不排斥高效的并行处理。
-
当放弃排序需求时(Stream 的 unordered 方法),有些操作可以被更有效地并行化。我们可以放弃排序要求来提高 limit 方法速度。如
words.parallelStream().unordered().limit(n)。 -
不要指望通过将所有的流都转换为并行流就能够加速操作,要牢记下面几条:
- 并行化会导致大量的开销,只有面对非常大的数据集才划算。
- 只有在底层的数据源可以被有效地分隔为多个部分时,将流并行化才有意义。
- 并行流使用的线程池可能会因诸如文件 I/O 或网络访问这样的操作被阻塞而饿死。
只有面对海量的内存数据和运算密集处理。并行流才会工作最佳。
-
在 Java9 之前对 Files.lines 方法返回的流进行并行化没意义(数据不可分隔,读取文件后半部分需读取文件前半部分),现在该方法使用的是内存映射文件,因此能有效的进行分隔。处理大型文件的各个行,并行化该流可能会提高效率。
-
默认情况下,并行流使用的是 ForkJoinPool.commonPool 返回的全局 fork-join 池。只有在操作不会阻塞并且我们不会将这个池与其它任务进行共享时这种方法才不会有什么问题,否则需要使用另一个不同的池。如:
ForkJoinPool customPool = ...; result = customPool.submit(() -> stream.parallel().map(...).collect(...)).get(); // 异步方式 CompletableFuture.supplyAsync(() -> stream.parallel().map(...).collect(...), customPool).thenAccept(result -> ...);
第14章 输入与输出
14.1.输入/输出流
-
在 Java API 中,可以从其中读入、写入一个字节序列的对象称作输入流、输出流。这些字节序列的来源地和目的地可以是文件、网络连接、内存块。抽象类 InputStream、OutputStream 构成了输入、输出(I/O)类层次结构的基础。抽象类 Reader、Writer 是专门用于处理 Unicode 字符的单独的类层级结构,这些类拥有的读入、写出操作都是基于两字节的 char 值的而不是基于 byte 值的。
-
InputStream 的 read 方法读入一个字节,返回该字节,或者遇到输入源结尾时返回 -1。InputStream 类有若干个抽象方法,可以读入一个字节数组,或者跳过大量的字节。Java9 开始有读取所有字节的 readAllBytes 方法。transferTo 方法将所有字节从一个输入流传递到一个输出流。
OutStream 类有抽象方法 write,向某个输出位置写入一个字节或字节数组。
-
read、write 方法在执行时都将阻塞,直至字节确实被读入或写出。如果流不能被立即访问(通常是网络繁忙),那么当前线程将被阻塞,等待指定流变为可用这段时间内,其他线程有机会执行有用的工作。available 方法可以检查当前可读入的字节数量,这意味者下面这样的代码片段不可能被阻塞:
int bytesAvailable = in.available(); if (bytesAvailable > 0) { var data = new byte[bytesAvailable]; in.read(data); } -
完成对输入/输出流的读写时,应该调用 close 方法关闭它。关闭输出流的同时还会冲刷用于该输出流的缓冲区:所有被临时置于缓冲区中,以便用更大的包的形式传递的字节在关闭输出流时都将被送出。如果不关闭文件,最后一个包可能永远也得不到传递。使用 flush 方法可以人为地冲刷这些输出。
-
Java 流家族:
![]()
![]()
DataInputStream、DataOutputStream 可以以二进制格式读写所有的基本 Java 类型。ZipInputStream、ZipOutputStream 可以以 ZIP 压缩格式读写文件。
还有四个附加接口:
![]()
Closeable 扩展了 AutoCloseable,前者的 close 方法只允许抛出 IOException,而后者允许抛出任何异常。
Readable 接口只有一个方法
int read(CharBuffer cb)。CharBuffer 类拥有按顺序和随机地进行读写访问的方法,它表示一个内存中的缓冲区或者一个内存映像的文件。Appendable 拥有同于添加单个字符的
Appendable append(char c)方法和添加字符序列的Appendable append(CharSequence s)方法。 -
FileInputStream、FileOutputStream 可以提供附着在一个磁盘文件上的输入流、输出流,只需向其构造器提供文件名或文件的完整路径名。
所有在 java.io 中的类都将相对路径解释为以用户工作目录开始,可通过
System.getProperty("user.dir")来获取该信息。 -
反斜杠字符在 Java 字符串都是转移字符,在 Windows 中路径名中应使用
\\或/。但是不推荐这样做,对于可移植程序来说,应该使用程序所运行平台的文件分隔符,可以通过常量字符串 java.io.File.separator 来获得它。 -
FileInputStream 没有任何读入数值类型方法,DataInputStream 也没有任何从文件中获取数据的方法。不过其他的输入流可以将字节数组组装到更有用的数据类型中,如从文件中读取数组可以通过以下操作:
var fin = new FileInputStream("employee.dat"); var din = new DataInputStream(fin); double x = din.readDouble(); -
FilterInputStream、FilterOutputStream 这些文件的子类用于向处理字节的输入/输出流添加额外的功能。通过嵌套过滤器来添加多重功能。如:
-
输入流在默认情况下时不被缓冲区缓存的,每次 read 调用都会请求 OS 分发一个字节。可以请求一个数据块置于缓冲区这样更高效,如:
var din = new DataInputStream(new BufferedInputStream(new FileInputStream("employee.dat"))); -
在读入输入时,预览下一字节,不是想要的值则放回,这需要 PushbackInputStream:
var pbin = new PushbackInputStream(new BufferedInputStream(new FileInputStream("employee.dat"))); int b = pbin.read(); pbin.unread(b);var pbin = new PushbackInputStream(new BufferedInputStream(new FileInputStream(""))); var din = new DataInputStream(pbin); int read = din.readInt(); pbin.unread(read); -
从一个 ZIP 压缩文件中读入数字:
var zin = new ZipInputStream(new FileInputStream("")); var din = new DataInputStream(zin);
-
-
保存数据时,可选择二进制格式或文本格式。
-
对于文本格式的 I/O:
-
在存储文本字符串时,需要考虑字符编码方式。OutputStreamWriter 类将使用选定的字符编码方式,把 Unicode 码元的输入流转换为字节流。InputStreamReader 类将包含字节(用某种字符编码方式表示的字符)的输入流转换为可以产生 Unicode 码元的读入器。
var in = new InputStreamReader(System.in); var in = new InputStreamReader(new FileInputStream("data.txt"), StandardCharsets.UTF_8);上者输入流读入器会假定使用主机系统所使用的默认字符编码方式。
-
对于文本输出,可以使用 PrintWriter,这个类拥有以文本格式打印字符串和数字的方法。为了打印文件,需要用文件名和字符编码方式构建一个 PrintWirter 对象。为输出到打印写出器,需要使用与使用 System.out 时相同的 print、println、printf 方法。如:
try (var out = new PrintWriter("", StandardCharsets.UTF_8)) { out.print("Harry Hacker"); out.print(' '); out.print(75_000); }println 方法在行中添加了对目标 OS 来说恰当的行结束符,可通过
System.getProperty("lines.separator")来获得。如果写出器设置为自动冲刷模式,那么只要调用 println,缓冲区所有字符都会被发送到目的地。默认情况下,自动冲刷器时禁用的。可以通过构造器参数来启用:var out = new PrintWriter(new OutputStreamWriter(new FileOutputStream(""), StandardCharsets.UTF_8), true);print 方法不抛出异常,可使用 checkError 方法来查看输出流是否出现了某些错误。
System.in是InputStream类型,System.out、System.err是PrintStream类型。在 Java1.0 中,PrintStream 类只是通过将高字节丢弃的方式把所有 Unicode 字符(那时仍旧是 16 位编码方式)截断为 ASCII 字符。这个问题在 Java1.1 引入读入器和写出器得到修正,但为了兼容已有代码,
System.in、System.out、System.err仍旧是输入/输出流而不是读入器/写出器。不过 PrintStream 类在内部采用与 PrintWriter 相同的方式将 Unicode 字符转换为默认的主机编码方式。PrintStream 与 PrintWriter 不同的是它允许用write(int)、write(byte[])方法输出原生字节。 -
对于读入文本输入。可以使用 Scanner 类,接受输入流参数。使用 Scanner 读入符号(token),即由分隔符分隔的字符串,默认分隔符是空白字符,可以使用 useDelimiter 方法修改分隔符。
Scanner in = ...; in.useDelimiter("\\PL+"); while (in.hasNext()) { String word = in.next(); }或者读取一个包含所有符号的流:
Stream<String> words = in.tokens(); -
对于短小文本文件,可以像以下方式读入字符串中:
String str = Files.readString(path, charset);将文件按一行行读入,可以使用:
List<String> lines = Files.readAllLines(path, charset);文件太大,可以将行惰性处理为一个
Stream<String>对象:try (Stream<String> lines = Files.lines(path, charset)) { ... } -
早期 Java 版本处理文本输入的唯一方式是通过 BufferedReader 类,它的 readLine 方法会产生一行文本,在无更多输入时返回 null。
try (var in = new BufferedReader(new InputStreamReader(inputStream, charset))) { String line; While ((line = in.readLine()) != null) { } }如今,BufferedReader 类有 lines 方法产生
Stream<String>对象。
-
-
为了表示使用的是高位优先还是低位优先,文件可以以”字节顺序标记“开头,这个标记为 16 为位数值 0xFEFF。读入器可以使用这个值来确定字节顺序,然后丢弃它 。
UTF-16 需要考虑字节序问题,但 UTF-8 不需要,不过有些程序使用 UTF-8 时依然添加了”字节顺序标记“。Java 对于 UTF-8 读入”字节顺序标记“并未处理,需要手动剥离。
-
平台使用的编码方式可以使用 Charset.defaultCharset 返回,Charset.availableCharsets 会返回所有可用的 Charset 实例。
Oracle 的 Java 实现有一个用于覆盖平台默认值的系统属性 file.encoding。但是它并非官方支持的属性。并且 Java 库的 Oracle 实现的所有部分并非都以一致的方式处理该属性,因此,你不应该设置它。
StandardCharsets 类具有 Charset 静态变量,用于表示每种 Java 虚拟机都必须支持的字符编码方式。
为了获得另一种编码方式的 Charset,可以使用 forName 方法:
Charset shiftJIS = Charset.forName("Shift-JIS"); -
在读入或写出文本时,应该使用 Charset 对象。如:
var str = new String(bytes, StandardCharsets.UTF-8); -
如果不指定任何编码方式,有些方法会使用默认的平台编码方式(如
String(byte[])),而其他方法会使用 UTF-8(如Files.readAllLines(path))。
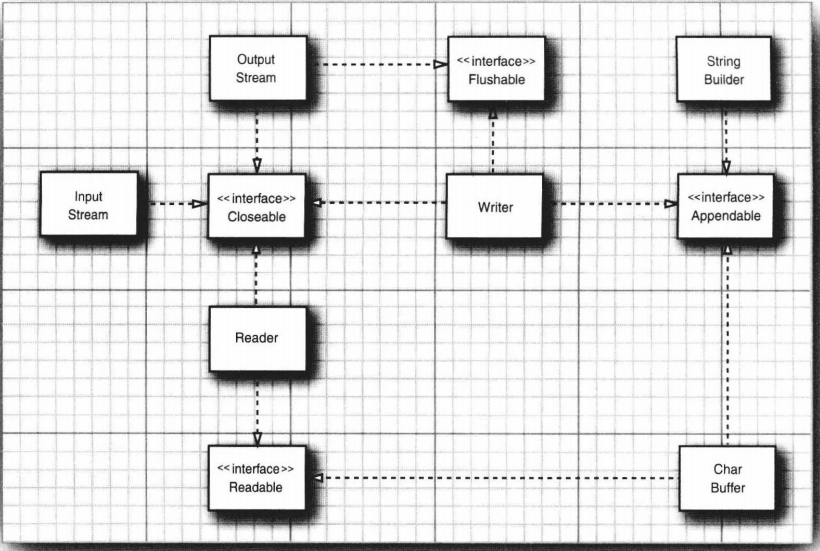
14.2.读写二进制数据
-
在 Java 中,所有的值都按照高位在前的模式写出(指从内存中写出到文件),不管使用任何处理器,这使得 Java 数据文件可以独立于平台。
-
DataOutput 的 writeUTF 方法使用修订版的 8 位 Unicode 转换格式写出字符串。这种方式与直接使用标准的 UTF-8 编码方式不同,其中,Unicode 码元序列首先用 UTF-16 表示其结果后,使用 UTF-8 规则进行编码。修订后的编码方式对于编码大于 0xFFFF 的字符的处理有所不同,这是为了向后兼容在 Unicode 还没有超过 16 位时构建的虚拟机。因为没有其他方法会使用 UTF-8 这种修订,所以应该只在写出用于 Java 虚拟机的字符串时才使用 writeUTF 方法,例如,需要编写一个生成字节码程序时。对于其他场合,都应该使用 writeChars 方法。
-
磁盘文件都是随机访问的,但是与网络套接字通信的输入/输出流却不是。
-
RandomAccessFile 可以打开一个随机访问文件,第二个参数指定只读或是同时读写。
随机访问文件有一个表示下一个将被读入或写出的字节所处位置的文件指针。seek 方法可设置该位置,getFilePointer 获取该位置,length 方法获取文件中的字节数。
RandomAccessFIle 实现了 DataInput、DataOutput 接口。对于字符串的读入、写出,可以提供两个助手方法:
public static void writeFixedString(String s, int size, DataOutput out) throws IOException { for (int i = 0; i < size; i++) { char ch = 0; if (i < s.length()) { ch = s.charAt(i); } out.writeChar(ch); } } public static String readFixedString(int size, DataInput in) throws IOException { StringBuilder b = new StringBuilder(size); int i = 0; boolean done = false; while (!done && i < size) { char ch = in.readChar(); i++; if (ch == 0) { done = true; } else { b.append(ch); } } in.skipBytes(2 * (size - i)); return b.toString(); } -
在 Java 中可以使用 ZipInputStream 读入 ZIP 文档。浏览文档中每个单独的像,getNextEntry 方法返回一个描述这些像的 ZipEntry 类型的对象,closeEntry 方法用来读下一项。如:
var zin = new ZipInputStream(new FileInputStream(zipname)); ZipEntry entry; while ((entry = zin.getNextEntry()) != null) { // read the contents of zin zin.closeEntry(); } zin.close();使用 ZipOutputStream 写出 ZIP 文档。对于 ZIP 文档中每一项,创建 ZipEntry 对象传递文件名参数,putNextEntry 写出新文件,并将文件数据发送到 ZIP 输出流中,完成时应该调用 closeEntry。如:
var zout = new ZipOutputStream(new FileOutputStream(zipname)); // for all files { var ze = new ZipEntry(filename); zout.putNextEntry(ze); // send data to zout zout.closeEntry(); } zout.close();
14.3.对象输入/输出流和序列化
-
保存对象到输出流和从输入流读取对象需要使用 ObjectOutputStream 和 ObejctInputStream,使用 writeObject、readObject 方法:
var out = new ObjectOutputStream(new FileOutputStream("")); out.writeObject(object);var in = new ObjectInputStream(new FileOutputStream("")); var object = (T) in.readObject();对于该对象必须实现 Serialiazable 接口。这两个类实现了 DataInput、DataOutput 接口,也可以写出、读入基本类型,使用诸如 writeInt、readInt 方法。
-
对于每个对象都是用一个序列号保存的。其算法为:
- 对于遇到的每个对象引用都关联一个序列号。
- 对于每个对象,当第一次遇到时,保存其对象数据到输出流中。
- 如果某个对象之前已经被保存过,那么只写出”与之前保存过的序列号为 x 的对象相同“。
在读回对象时,整个过程是反过来的:
- 对于对象输入流中的对象,在第一次遇到其序列号时,构建它,并使用流中的数据来初始化它,然后记录这个序列号和新对象之间的关联。
- 当遇到”与之前保存过的序列号为 x 的对象相同“这一标记时,获取这个序列号相关联的对象的引用。
-
对象序列化是以特殊的文件格式存储对象数据的。
每个文件都是以
AC ED开头,后面是对象序列化格式的版本号(如00 05)。-
字符串对象被存为
74 两字节表示的字符串长度 所有字符,字符串中的 Unicode 字符被存储为修订过的 UTF-8 格式。如:74 00 05 Harry -
存储一个对象时,对象所属的类也必须存储。这个类的描述包括:类名、序列化的版本唯一 ID(它是数据域类型和方法签名的指纹)、描述序列化方法的标志集、对数据域的描述。
指纹是通过对类、超类、接口、域类型和方法签名按照规范方式排序,然后将安全散列算法(SHA)应用于这些数据而获得的。SHA 得到的是 20 字节,序列化机制只是用了前 8 字节作为类的指纹。当读入一个对象时,会拿其指纹与它所属的类的当前指纹进行比对,如果它们不匹配,那么就说明这个类的定义在该对象被写出之后发生过变化,因此会产生一个异常。
类标识符存储为:
72 2 字节的类名长度 类名 8 字节长的指纹 1 字节长的标志 2 字节长的数据域描述符的数量 数据域描述符 78(结束标记) 超类类型(如果没有就是 70)标志字节是由在 java.io.ObjectStreamConstants 中定义的 3 位掩码构成的。
...略
-
-
某些数据域是不可序列化的。Java 拥有一种很简单的机制来放置这种域被序列化,就是将其标记为 transient。
-
序列化机制为单个的类提供了一种方式,去向默认的读写行为添加验证或任何其他想要的行为。可序列化的类可以定义具有下列签名的方法:
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException; private void writeObject(ObjectOutputStream out) throws IOException;之后,数据域就不再被自动序列化,而是调用这些方法。如:
public class LabeledPoint implements Serializable { private String label; private transient Point2D.Double point; private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException { in.defaultReadObject(); point = new Point2D.Double(in.readDouble(), in.readDouble()); } private void writeObject(ObjectOutputStream out) throws IOException { out.defaultWriteObject(); out.writeDouble(point.getX()); out.writeDouble(point.getY()); } } -
除了让序列化机制来保存和恢复对象数据,类还可以定义它自己的机制。为了做到这一点,该类必须实现 Externalizable 接口,它需要定义两个方法:
public void writeExternal(ObjectOutput out) throws IOException; public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;这些方法对包括超类数据在内的整个对象的存储和恢复负全责。在读入可外部化的类时,对象输入流将用无参构造器创建一个对象,然后调用 readExternal 方法。如:
public class Employee implements Externalizable { private String name; private double salary; private LocalDate hireDay; @Override public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException { name = in.readUTF(); salary = in.readDouble(); hireDay = LocalDate.ofEpochDay(in.readLong()); } @Override public void writeExternal(ObjectOutput out) throws IOException { out.writeUTF(name); out.writeDouble(salary); out.writeLong(hireDay.toEpochDay()); } } -
在序列化和反序列化时,如果目标对象是唯一的,那么必须加倍小心,这通常会在实现单例和类型安全的枚举时发生。
如在枚举出现之前,有遗留代码是这种类型的:
public class Orientation { public static final Orientation HORIZONTAL = new Orientation(1); public static final Orientation VERTICAL = new Orientation(2); private int value; private Orientation(int v) { value = v; } }将其序列化后再反序列化:
try ( ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("")); ObjectInputStream in = new ObjectInputStream(new FileInputStream("")) ) { Orientation original = Orientation.HORIZONTAL; out.writeObject(original); var saved = (Orientation) in.readObject(); if (saved == Orientation.HORIZONTAL) { // always false } }事实上,saved 将是 Orientation 的一个全新对象,即使构造器是私有的,序列化机制也可以创建新的对象。为解决这个问题,需要在对象中定义 readResolve 这个特殊的序列化方法。如果定义了该方法,在对象序列化之后会调用它,它必须返回一个对象,而该对象之后会成为 readObject 的返回值。如:
protected Object readResolve() throws ObjectStreamException { if (value == 1) return Orientation.HORIZONTAL; if (value == 2) return Orientation.VERTICAL; throw new ObjectStreamException(); // this shouldn't happen } -
在类演化过程中,对于旧类的指纹可以使用 serialver 单机程序获取,如
serialver Employee。对于新类,把 serialVersionUID 定义为旧类的指纹,它就不再需要重新人工计算,直接使用这个值。如:public static final long serialVersionUID = ...L;如果这个类只有方法发生变化,那么在读入新对象数据时是不会有任何问题的,但如果数据域发生变化就可能有问题。对象输入流会将这个类当前版本的数据域与被序列化的版本中的数据域进行比较,只会考虑非瞬时和非静态的数据域。如果名字匹配但类型不匹配,不会进行类型转化;被序列化对象具有当前版本未有的数据域则会丢弃;当前版本具有被序列化对象未有的数据域则会设置为默认值。
-
序列化为克隆对象提供了简便途径,只要求对应类是可序列化的即可。其做法为:直接将对象序列化到输出流,然后将其都会,这样产生的新对象是先有对象的一个深拷贝,此过程中可用 ByteArrayOutputStream 将数据保存到字节数组中。如:
class SerialCloneable implements Cloneable, Serializable { @Override public Object clone() throws CloneNotSupportedException { try { var bout = new ByteArrayOutputStream(); try (var out = new ObjectOutputStream(bout)) { out.writeObject(this); } try (var bin = new ByteArrayInputStream(bout.toByteArray())) { var in = new ObjectInputStream(bin); return in.readObject(); } } catch (IOException | ClassNotFoundException e) { var e2 = new CloneNotSupportedException(); e2.initCause(e); throw e2; } } }当心这个方法,尽管灵巧但是这比显示构造新对象并复制或克隆数据域的克隆方法慢得多。
14.4.操作文件
-
Path 表示的是一个目录名序列,其后还可以跟着一个文件名。
-
静态 Paths.get(string...) 接受一个或多个字符串,并将它们用默认文件系统的路径分隔符连接起来,返回 Path 对象。
-
组合和解析路径的方法:
p.resolve(q)(p 是 Path,q 是 Path 或 String)返回 Path 对象,其规则是:
- q 为绝对路径即返回 q。
- 否则,根据文件系统的规则,将”p 后面跟着 q“作为结果。
p.resolveSibling(q) 返回 p 产生的兄弟路径。如:
// workPath 是 /opt/myapp/work,则返回 /opt/myapp/temp Path temp = workPath.resolveSibling("temp");p.relativize(r) 将产生 q,而对 q 进行 resolve 将得到 r。如:
// p 为 /home/harry,r 为 /home/fred/input.txt,则 q 为 ../fred/input.txt Path q = p.relativize(r);p.normalize() 将异常所有冗余的
.和..。如:// p 为 /home/harry/../fred/./input.txt,q 为 /home/fred/input.txt Path q = p.normalize();toAbsolutePath 方法将产生给定路径的绝对路径。
还有其它方法,如:
Path p = Paths.get("/home", "fred", "myprog.properties"); Path parent = p.getParent(); Path file = p.getFileName(); Path root = p.getRoot();Scanner 构造器可以传递 Path 对象。
可能遗留的 API 使用的是 File 而不是 Path。Path 的 toFile 和 File 的 toPath 可以相互转化得到。
-
Files 的方法可以使得普通文件操作变得更快捷。如:
byte[] bytes = Files.readAllBytes(path); String content = Files.readString(path, charset); List<String> lines = Files.readAllLines(path, charset);Files.writeString(path, content, charset); Files.write(path, content.getBytes(charset), StandardOpenOption.APPEND); Files.write(path, lines, charset);这些简便方法适用于中等长度文本文件,对于文件长度较长的,或者二进制文件,依然应该使用输入/输出流、读入器/写出器。如:
InputStream in = Files.newInputStream(path); OutputStream out = Files.newOutputStream(path); Reader in = Files.newBufferedReader(path, charset); Writer out = Files.newBufferedWriter(path, charset); -
创建新目录可以使用
Files.createDirectory(path),不过这要求路径中除最后一个部件外,其它部分必须存在。而要创建路径中的中间目录应该使用Files.createDirectories(path)方法。创建空文件使用
Files.createFile(path),文件已存在会抛出异常。检查文件是否存在和创建文件是原子性的,该方法在执行过程中,其它程序是无法执行文件的创建操作的。有些便捷方法可以用来创建给定位置或者系统指定位置创建临时文件或临时目录:
Path newPath = Files.createTempFile(dir, prefix, suffix); Path newPath = Files.createTempFile(prefix, suffix); Path newPath = Files.createTempDirectory(dir, prefix); Path newPath = Files.createTempDirectory(prefix);dir 是一个 Path 对象,prefix、suffix 是可以为 null 的字符串。
-
复制文件与移动文件:
Files.copy(fromPath, toPath); Files.move(fromPath, toPath);如果目标路径已存在,那么复制或移动将失败。REPLACE_EXISTING 选项覆盖已有目标路径,COPY_ATTRIBUTES 选项复制文件所有的文件属性。还可以将一个输入流复制到 Path 中,将一个 Path 复制到输入流中。如:
Files.copy(fromPath, toPath, StandardCopyOption.REPLACE_EXISTING, StandardCopyOption.COPY_ATTRIBUTES); Files.copy(inputStream, toPath); Files.copy(fromPath, outputStream);移动操作可以定义为原子性的:
Files.move(fromPath, toPath, StandardCopyOption.ATOMIC_MOVE);删除文件调用 delete 方法,文件不存在会抛出异常。因此可以使用 deleteIfExists 方法,该方法还可以用来删除空目录。如:
Files.delete(path); boolean deleted = Files.deleteIfExists(path); -
用于文件操作的标准选项:
![]()
![]()
-
静态方法 exists、isHidden、isReadable、isWritable、isExecutable、isRegularFile、isDirectory、isSymbolicLink 返回 boolean 检查路径的某个属性结果。size 方法返回文件字节数。getOwner 方法将文件的拥有者作为 java.nio.file.attribute.UserPrincipal 的一个实例返回。
所有文件系统都会报告一个基本属性集,它们被封装到 BasicFileAttributes 接口中。基本文件属性包括:
- 创建文件、最后一次访问以及最后一次修改文件时间,这些时间都表示为 java.nio.file.attribute.FileTime。
- 文件是常规文件、目录还是符号链接,抑或都不是。
- 文件尺寸。
- 文件主键,这是某种类的对象,具体所属类与文件系统相关,可能是文件的唯一标识符,也可能都不是。
获取这些属性可调用:
BasicFileAttributes attributes = Files.readAttributes(path, BasicFileAttributes.class);如果用户文件系统兼容 POSIX,则可以获取一个 PosixFileAttributes 实例:
PosixFileAttributes attributes = Files.readAttributes(path, PosixFileAttributes.class); -
Files.list 方法放回一个可以读取目录中的各个项的
Stream<Path>对象,list 方法不会处理子目录。要处理目录中的所有子目录使用 File.walk 方法,可以添加参数只当访问数的深度,还具有 FileVisitOption... 的可变长参数,但是只能提供一种选项 FOLLOW_LINKS,即跟踪符号链接。读取目录涉及需要关闭系统资源,所以应该使用 try-with-resources 块。如以下代码实现将一个目录复制另一个目录:try (Stream<Path> entries = Files.walk(source)) { entries.forEach(p -> { try { Path q = target.resolve(source.relativize(p)); if (Files.isDirectory(p)) { Files.createDirectory(q); } else { Files.copy(p, q); } } catch (IOException e) { throw new UncheckedIOException(e); } }); }如果需要过滤 walk 返回的路径,并且过滤标准涉及与目录存储相关的文件属性,那么应该使用 find 方法来代替 walk 方法,可以用某个谓词函数调用该方法,该谓词函数接受一个 Path 和一个 BasicFileAttributes。
-
相较于 Files.walk 有时需要更细粒度的控制,可以使用 Files.newDirectoryStream ,会产生 DirectoryStream(它不是 java.util.streamStream 的子接口,是 Iterable 的子接口),访问目录中的项并没有具体的顺序。可以使用 glob 模式来过滤文件。
try (DirectoryStream<Path> entries = Files.newDirectoryStream(dir, "*.java")) { for (Path entry : entries) { // process entry } }glob 模式:
![]()
-
如果想访问某个目录的所有子孙目录,使用 walkFileTree 方法,并向其传递一个 FileVisitor 类型对象,这个对象会得到以下通知:visitFile 遇到一个文件或目录时、preVisitDirectory 在一个目录被处理前、postVisitDirectory 在一个目录处理后、visitFileFailed 试图访问文件或目录时发生错误。对于上述情况,都可指定是否希望执行下面的操作:FileVisitResult.COUNTINE、FileVisitResult.SKIP_SUBTREE、FileVisitResult.SKIP_SIBLINGS、FileVisitResult.TERMINATE。当有任何方法抛出异常,就会终止访问,而这个异常会从 walkFileTree 方法中抛出。
SimpleFileVisitor 实现了 FileVisitor 接口,但是其除 visitFileFailed 方法之外的所有方法并不做任何处理而是直接继续访问,而 visitFileFailed 方法会抛出有失败导致的异常,并进而终止访问。
打印给定目录下子目录示例:
Files.walkFileTree(Paths.get("/"), new SimpleFileVisitor<Path>() { @Override public FileVisitResult preVisitDirectory(Path path, BasicFileAttributes attrs) throws IOException { System.out.println(path); return FileVisitResult.CONTINUE; } @Override public FileVisitResult visitFile(Path path, BasicFileAttributes attrs) throws IOException { return FileVisitResult.SKIP_SUBTREE; } @Override public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException { return FileVisitResult.CONTINUE; } });删除目录树:
Files.walkFileTree(root, new SimpleFileVisitor<Path>() { @Override public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException { Files.delete(file); return FileVisitResult.CONTINUE; } @Override public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException { if (exc != null) { throw exc; } Files.delete(dir); return FileVisitResult.CONTINUE; } }); -
对于 ZIP 文档,以下会建立一个包含 ZIP 文档中所有文件的文件系统:
FileSystem fs = FileSystems.newFileSystem(Paths.get(zipname), null);如果知道文件名,那么通过以下方式复制文件,其中 fs.getPath 对于任意文件系统来说都与 Paths.get 类似:
Files.copy(fs.getPath(sourceName), targetPath);列出 ZIP 文档中的所有文件:
FileSystem fs = FileSystems.newFileSystem(Paths.get(zipname), null); Files.walkFileTree(fs.getPath("/"), new SimpleFileVisitor<Path>() { @Override public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException { System.out.println(file); return FileVisitResult.CONTINUE; } });

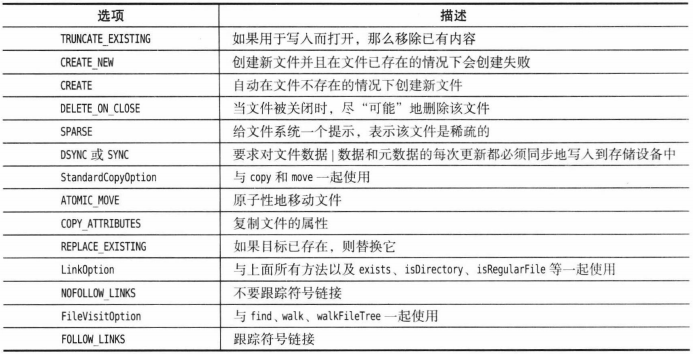
14.5.内存映射文件
-
大多数 OS 都可以利用虚拟内存实现来将一个文件或文件的一部分映射到内存中。然后,这个文件就可以被当作内存数组一样地访问,这比传统地文件操作要快得多。
-
对于中等尺寸文件地顺序读入则没有必要使用内存映射。
-
使用 java.nio 包来使用内存映射,步骤如下:
-
首先从文件中获得一个通道,通道是用于磁盘文件的一种抽象,它使我们可以访问诸如内存映射、文件加锁机制以及文件间快速数据传递等 OS 特性:
FileChannel channel = FileChannel.open(path, options); -
然后通过调用 FileChannel 类的 map 方法从这个通道中获得一个 ByteBuffer。可以指定想要映射的文件区域与映射方式,支持的模式有三种:
- FileChannel.MopMode.READ_ONLY:所产生的缓冲区是只读的,任何对该缓冲区读入的尝试都会抛出异常。
- FileChannel.MopMode.READ_WRITE:所产生的缓冲区是可写的,任何修改都会在某个时刻写回到文件中。其他映射同一个文件的程序可能不能立即看到这些修改,多个程序同时进行文件映射的确切行为是依赖 OS 的。
- FileChannel.MopMode.PRIVATE:所产生的缓冲区是可写的。但是任何修改对这个缓冲区来说都是私有的,不会传播到文件。
-
有了缓冲区就可使用 ByteBuffer 类和 Buffer 超类的方法读写数据了。
缓冲区支持顺序和顺序数据访问,get、put 操作移动位置。如:
// 顺序遍历缓冲区中所有字节 while (buffer.hasRemain()) { byte b = buffer.get(); ... } // 随机访问缓冲区中所有字节 for (int i = 0; i < buffer.limit(); i++) { byte b = buffer.get(i); ... }使用
get(byte[] bytes)、get(byte[], offset, length)读字符数组。getX(X 为基本类型)读入在文件中存储为二进制值的基本类型,Java 对二进制数据才有高位在前,要使用低位在前则调用buffer.order(ByteOrder.LITTLE_ENDIAN);,查询缓冲区当前字节顺序使用ByteOrder b = buffer.order();。putX(X 为基本类型)方法向缓冲区写数字。
-
-
使用内存映射计算 CRC 示例:
public static long checksumMappedFile(Path filename) throws IOException { try (FileChannel channel = FileChannel.open(filename)) { var crc = new CRC32(); int length = (int) channel.size(); MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_ONLY, 0, length); for (int i = 0; i < length; i++) { int c = buffer.get(i); crc.update(c); } return crc.getValue(); } } -
缓冲区是具有相同类型的数值构成的数组,Buffer 类是一个抽象类,它有具体子类 ByteBuffer、CharBuffer、IntBuffer、LongBuffer、ShortBuffer(StringBuffer 跟这些缓冲区没关系)。
-
每个缓冲区都具有:
- 一个容量,它永远不能改变。
- 一个界限,超过它进行读写没有意义。
- 一个读写位置,下一个值将在此进行读写。
- 一个可选标记,用于重复一个读入或写出操作。
这些值满足 \(0 \leq 标记 \leq 读写位置 \leq 界限 \leq 容量\)
-
使用缓冲区的主要目的是执行“写,然后读入”循环。假设有缓冲区开始位置为 0,界限等于容量,使用 put 不断添加值,直到数据源耗尽或者到达容量大小时,就切换读入操作。调用 flip,将界限设置到当前位置,位置复位到 0,remaining 方法返回正数时($ 界限 - 位置 $)不断 get,然后调用 clear 位置设 0 界限复位至容量,为下一次写循环准备。
想重读缓冲区使用 rewind、mark/reset 方法。
获取缓冲区可以调用诸如 ByteBuffer.allocate、ByteBuffer.wrap 这样的静态方法。然后可以用来自某个通道的数据填充缓冲区,或者将缓冲区的内容写出到通道中。如:
ByteBuffer buffer = ByteBuffer.allocate(RECORD_SIZE); channel.read(buffer); channel.position(newpos); buffer.flip(); channel.write(buffer);
14.6.文件加锁机制
-
要锁定一个文件,可使用 FileChannel 的 lock 或 tryLock 方法,前者会阻塞直到可获得锁,后者将立即返回,返回锁(FileLock 对象)或 null。这个文件将保持锁定直至通道关闭或者锁上调用 release 方法。锁定时还可以只锁定文件的一部分。还可添加 shared 布尔值,指定共享锁还是排他锁,但并非所有 OS 都支持共享锁,有可能共享锁获得的是排他锁。调用 FileLock 的 isShared 可查询所持有的锁类型。
如果锁定了文件尾部,而这个文件的长度随后增长并超过了锁定的部分,那么增长出来的额外锁定区域是未锁定的,想要锁定所有字节,可以使用 Long.MAX_VALUE 来表示尺寸。
-
确保在操作完成时释放锁,最好写在 try-with-resources 语句中。
-
文件加锁机制是依赖于 OS 的,需要注意以下几点:
- 在某些系统中,文件加锁只是建议性的,如果一个应用未能得到锁,它仍旧可以向被另一个应用并发锁定的文件执行写操作。
- 在某些系统中,不能在锁定一个文件的同时将其映射到内存中。
- 文件锁是由整个 Java 虚拟机持有的。
- 在一些系统中,关闭一个通道会释放由 Java 虚拟机持有的底层文件上的所有锁。因此,在同一个锁定文件上应避免使用多个通道。
- 在网络文件系统上锁定文件是高度依赖系统的,因此应该尽量避免。
14.7.正则表达式
-
正则表达式中,如果字符类包含
-,那么它必须是第一项或者最后一项;如果要包含[,那么它必须是第一项;如果要包含^,那么它可以是除开始位置外的任何位置。其中只需要转义[和^。 -
正则表达式语法:
![]()
![]()
![]()
与 \p 一起使用的预定义字符类名字:
![]()
-
默认情况下,量词要匹配能够使整个匹配成功的最大可能重复次数。可以修改这种行为,方法是使用后缀
?(使用勉强或吝啬匹配,也就是匹配最小重复次数)或者使用后缀+(使用占有或贪婪匹配,也就是即使让整个匹配失败,也要匹配最大的重复次数)。如cab匹配[a-z]*ab但不匹配[a-z]*+ab。 -
Java 测试字符串是否匹配某个正则表达式:首先使用正则表达式创建 Pattern 对象,然后使用 pattern.matcher 方法获取 Matcher,matcher 的 matches 方法可返回是否匹配。如:
Pattern pattern = Pattern.compile(patternString); Matcher matcher = pattern.matcher(input); // input 是实现了 CharSequence 接口的对象 if (matcher.matches()) { ... }匹配可以设置一个或多个标志,可以在 compile 中设置参数设置,或者在模式中设置。如:
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE + Pattern.UNICODE_CASE); String regex = "(?iU:expression)";各个标志含义:
Pattern.CASE_INSENSITIVE、i:匹配时忽略字母大小写。默认情况下只针对 US ASCII 字符。Pattern.UNICODE_CASE、u:当与 CASE_INSENSITIVE 组合使用时,用 Unicode 字母的大小写来匹配。Pattern.UNICODE_CHARACTER_CLASS、U:选择 Unicode 字符类代替 POSIX,其中蕴含了 UNICODE_CASE。Pattern.MULTILINE、m:^、$匹配行的开头和结尾,而不是整个输入的开头和结尾。Pattern.UNIX_LINES、d:在多行模式中匹配^、$时,只有\n被识别成行终止符。Pattern.DOTALL、s:.匹配所有字符,包括行终止符。Pattern.COMMENTS、x:空白字符和注释将被忽略。Pattern.LITERAL:该模式将被逐字地接纳,必须精确匹配,因字母大小写而造成地差异除外。Pattern.CANON_EQ:考虑 Unicode 字符规范的等价性。
-
想要在集合或流中匹配元素,可以将模式转换为谓词。如:
Stream<String> result = strings.filter(pattern.asPredicate()); -
正则表达式中用群组来定义子表达式,群组用
()括起来。Matcher 对象可以揭示群组的边界。下面方法将产生指定群组的开始索引和结尾之后的索引。int start(int groupIndex); int end(int groupIndex);也可以通过以下方法抽取群组匹配的字符串:
String group(int groupIndex);群组号为 0 表示整个输入,实际群组编号是从 1 开始的,嵌套群组是按照前括号排序的。groupCount 方法可获取群组数。
-
对于不使用正则表达式匹配全部输入,而是找出输入中一个或多个匹配的子字符串。使用 matcher 的 find 方法,返回 true 时,使用 start、end、group 来操作匹配的内容。如:
while (matcher.find()) { int start = matcher.start(); int end = matcher.end(); String match = matcher.group(); ... }或者,使用 results 方法获取所有匹配子字符串的一个
Stream<MatchResult>(Matcher 类实现 MatchResult 接口,MatchResult 接口含有 start、end、group 方法)。如:List<String> matches = pattern.matcher(input).results().map(MatchResult::group).collect(Collectors.toList());scanner 的 findAll 也可获取一个
Stream<MatchResult>,如:Stream<String> words = scanner.findAll("\\pL+").map(MatchResult::group); -
对于需要将输入按照匹配的分隔符分开,而其他部分保持不变,可以使用:
-
Pattern commas = Pattern.compile("\\s*,\\s*"); String[] tokens = commas.split(input); -
有多个标记可惰性处理:
Stream<String> tokens = commas.splitAsStream(input); -
不关心预编译模式和惰性获取,可使用 string 的 split 方法:
String[] tokens = input.split("\\s*,\\s*"); -
输入数据在文件中,需要使用扫描器:
Scanner in = ...; in.useDelimiter("\\s*,\\s*"); Stream<String> tokens = in.tokens();
-
-
matcher 的 replaceAll 可以将正则表达式匹配的地方进行替换。如:
String output = Pattern.compile("[0-9]+").matcher(input).replaceAll("#");替换字符串可以包含对模式中群组的引用:
$n表示替换成第 n 个群组,${name}表示被替换为具有给定名字的组,因此需要使用\$表示在替换文本中包含一个$字符。如果字符串包含$、\有不想它们解释为群组的替换符,那么就可以使用matcher.replaceAll(Matcher.quoteReplacement(str))。replaceAll 接受函数参数,该函数接受 MatchResult 对象,返回字符串。如:
String result = Pattern.compile("\\pL{4,}").matcher("Mary had a little lamb").replaceAll(m -> m.group().toUpperCase());replaceFirst 方法只替换第一次匹配。

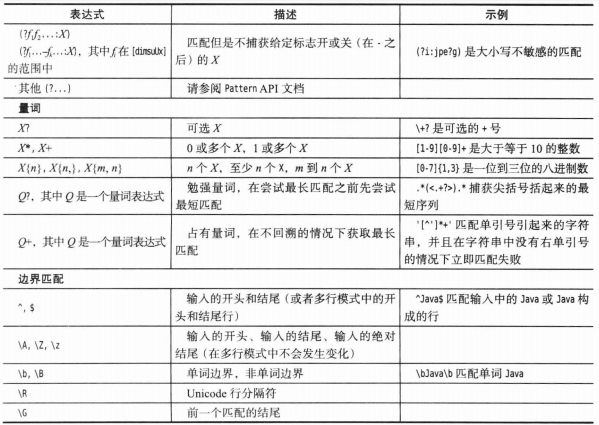
第15章 XML
15.1.XML 概述
- HTML 与 XML 的重要区别:
- XML 大小写敏感。
- XML 结束标记不可省略。
- XML 单个标签没有结束标签必须写成
</ ...>。 - XML 属性值必须使用引号括起来。
- XML 属性必须有属性值。
15.2.XML 文档的结构
-
XML 文档模板:
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE config PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN" "../template.dtd"> <conifg> <entity id="title"> <font> <name>Helvetica</name> <size>36</size> </font> </entity> </conifg> -
在设计 XML 文档结构时,最好让元素只包含子元素或者文本。如果避免混合式内容,可以简化解析过程。
-
对于属性和值的选择,一条常用的经验法则是:属性只应该用来修改值的解释,而不是用来指定值。
-
XML 标记:
- 符号引用。如
é、é。 - 实体引用。如
<、>。还可以在 DTD 中定义其他的实体引用。 - CDATA 用
<![CDATA[和]]>界定,CDATA 不能包含]]>部分。 - 处理指令。如
<?xml version="1.0" encoding="utf-8"?>。 - 注释。如
<!-- This is a comment. -->。注释不应该包含--。
- 符号引用。如
15.3.解析 XML 文档
-
Java 提供了两种 XML 解析器:像 DOM 解析器这样的树型解析器、像 SAX 解析器这样的流机制解析器。
如果要处理很长的文档,DOM 解析器生成的树结构会消耗大量内存。如果只是对于某些元素感兴趣,而不关心其上下文,应该使用 SAX。
-
使用 DOM 方式:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); try { DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse(source); } catch (ParserConfigurationException e) { ... }source 可以是 File、URL、InputStream。如果使用输入流作为输入源,那么对于那些以该文档的位置为相对路径而被引用的文档,解析器将无法定位,可以通过安装一个实体解析器(entity resolver)来解决这个问题。
Document 对象是 XML 文档的树型结构在内存中的表现方式,它由实现了 Node 接口及其各种子接口的类的对象构成:
![]()
document 的 getDocumentElement 启动对文档内容的分析,返回 Element 根元素。element 的 getTagName 方法返回标签名,getChildNodes 返回 NodeList 子元素集合。nodeList 的 getLength 方法返回元素项数,item 方法指定索引值获取对应的 Node 项。
注意 getChildNodes 返回包含空白项。如以下文档中 font 的 getChildNodes 返回 5 项:
<font> <name>Helvetica</name> <size>36</size> </font>如果要忽略空白,可判断 Node 是否属于 Element。如:
Element root = doc.getDocumentElement(); NodeList children = root.getChildNodes(); for (int i = 0; i < children.getLength(); i++) { Node child = children.item(i); if (child instanceof Element) { var childElement = (Element) child; ... } }如果 Node 只包含文本,则它是 Text。如:
for (int i = 0; i < children.getLength(); i++) { Node child = children.item(i); if (child instanceof Element) { var childElement = (Element) child; var textNode = (Text) childElement.getFirstChild(); String text = textNode.getData().trim(); if (childElement.getTagName().equals("name")) { name = text; } else if (childElement.getTagName().equals("size")) { size = Integer.parseInt(text); } } }getLastChild 方法获取最后一项子元素,getNextSibling 得到下一个兄弟节点。遍历子节点集的另一种方法就是:
for (Node childNode = element.getFirstChild(); childNode != null; childNode = childNode.getNextSibling()) { ... }getAttributes 方法获取节点属性,返回 NamedNodeMap 对象,其包含描述属性的 Node 对象,可以和遍历 NodeList 一样的方式在 NamedNodeMap 中遍历各子节点。调用 getNodeName 和 getNodeValue 方法获取属性名、属性值。如:
NamedNodeMap attributes = element.getAttributes(); for (int i = 0; i < attributes.getLength(); i++) { Node attribute = attributes.item(i); String name = attribute.getNodeName(); String value = attribute.getNodeValue(); ... }直到属性名还可以直接获取。如
String unit = element.getAttribute("unit");
15.4.验证 XML 文档
-
指定 XML 文件结构可通过 DTD(文档定义类型)或 XML Schema 定义。如:
<!ELEMENT font (name,size)<xsd:element name="font"> <xsd:sequence> <xsd:element name="name" type="xsd:string"/> <xsd:element name="size" type="sxd:int"/> </xsd:sequence> </xsd:element>与 DTD 相比。XML Schema 可以表达更加复杂的验证条件。
-
提供 DTD 可以直接写在 XML 文档中。如:
<?xml version="1.0"?> <!DOCTYPE config [ <!ELEMENT config ...> more rules ... ]> <config> ... </config>或者将 DTD 存储在外部:
<!DOCTYPE config SYSTEM "config.dtd"><!DOCTYPE config SYSTEM "http://myserver.com/config.dtd">如果使用 DTD 的相对 URL(如
"config.dtd"),那么要给解析器一个 File 或 URL 对象,而不是 InputStream。如果必须从一个输入流来解析,则需提供一个实体解析器。最后有一个来源于 SGML 的用于识别“众所周知的” DTD 的机制,如果 XML 处理器知道如何定位带有公共标识符的 DTD,则不需要 URL。如:
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">DTD 的系统标识符 URL 可能实际无法正常工作,或者会显著地降低性能。对于降低性能可以使用实体解析器,将公共标识符映射为本地文件。Java9 之前不得不提供一个实现了 EntityResolver 接口并实现了 resolveEntity 方法的对象。现在可以使用 XML 目录来管理这种映射,我们需要提供一个或多个具有以下形式目录文件:
<?xml version="1.0"?> <!DOCTYPE catalog PUBLIC "-//OASIS//DTD XML Catalog V1.0//EN" "http://www.oasis-open.org/committees/entity/release/1.0/catalog.dtd"> <catalog xmlns="urn:oasis:names:tc:entity:xmlns:xml:catalog" prefer="public"> <public publicId="..." uri="..."/> ... </catalog>然后项下面这样构造和安装一个解析器:
builder.setEntityResolver(CatalogManager.catalogResolver( CatalogFeatures.defaults(), Paths.get("catalog.xml").toAbsolutePath().toUri() ));除了在程序中设置目录文件的位置,还可以在命令行中用
javax.xml.catalog.files系统属性来设置它,我们需要提供由分号分隔的 file 的绝对 URL。 -
DTD:
-
ELEMENT 规则用于指定某个元素可以拥有什么样的子元素。可以指定一个正则表达式,它由以下组成部分构成:
![]()
如:
<!ELEMENT chapter (intro,(heading,(para|image|table|note)+)+)>当一个元素包含文本时,它只能包含文本,或者包含任意顺序的文本和标签组合:
<!ELEMENT name (#PCDATA)> <!ELEMENT para (#PCDATA|em|strong|code)*> <!ELEMENT captionedImage (image,#PCDATA)> <!-- 非法 -->实际上 DTD 规则中并不能为元素指定任意的正则表达式,XML 解析器会拒绝某些导致非确定性的复杂规则。如
((x,y)|(x,z))是非确定性的,解析器看到 x,不知道选择哪个,但可改写为(x,(y,z)),((x,y)*|x?)是非确定性的但无法改写为确定性的。对于有歧义的 DTD,不会给出警告而是解析时选择第一个匹配项,这将导致它拒绝一些正确的输入。 -
ATTLIST 指定元素的属性规则,其通用语法为:
<!ATTLIST element attribute type default>合法的属性类型:
![]()
属性默认值语法:
![]()
一般情况下推荐用元素而非属性来描述数据。但属性有个优点是,对于枚举类解析器能够检验取值是否合法。
CDATA 属性值处理与 #PCDATA 处理有微妙差别。属性值首先被规范化,即处理对字符和实体的引用,并且要用空格替换空白字符。
NMTOKEN 与 CDATA 类似,但大多数非字母数字字符和内部的空白字符是不允许使用的,而且解析器会删除起始和结尾的空白字符。NMTOKENS 是一个以空白字符分隔的名字标记列表。
ID 是在文档中必须唯一的名字标记,解析器会检查其唯一性。IDREF 是对同一文档中已存在的 ID 的引用,解析器也会对它进行检查。IDREFS 是以空白字符分隔的 ID 引用的列表。
ENTITY 属性值将引用一个“未解析的外部实体”。
-
ENTITY 定义实体。如:
<!ENTITY back.label "Back">其他地方的文本可以包含对这个实体的引用,如:
<menuitem label="&back.label;"/>
-
-
配置解析器进行 DTD 校验。
通知文档生成工厂打开验证特性:
factory.setValidating(true);忽略文本之间的空白字符:
factory.setIgnoringElementContentWhitespace(true);安装错误处理器:
builder.setErrorHandler(handler); -
XML Schema:
如果要在文档中引用 Schema 文件,需要在根元素中添加属性。如:
<?xml version="1.0"?> <config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="config.xsd"> ... </config>Schema 为每个元素和属性都定义了类型。类型中的简单类型是对内容有限制的字符串,其他的都是复杂类型。具有简单类型的元素可以没有任何属性和子元素,否则它就必然是复杂类型。属性总是简单类型。
一些简单类型已被内建到了 XML Schema 内,包括
xsd:string、xsd:int、xsd:boolean(前缀xsd:表示 XSL Schema 定义的命名空间,有些代之以xs:)。定义自己的简单类型。如:
<xsd:simpleType name="StyleType"> <xsd:restriction base="xsd:string"> <xsd:enumeration value="PLAIN"/> <xsd:enumeration value="BOLD"/> <xsd:enumeration value="ITALIC"/> <xsd:enumeration value="BOLD_ITALIC"/> </xsd:restriction> </xsd:simpleType>定义元素时,指定其类型:
<xsd:element name="name" type="xsd:string"/> <xsd:element name="size" type="xsd:int"/> <xsd:element name="style" type="xsd:StyleType"/>可以把类型组合为复杂类型:
<xsd:complexType name="FontType"> <xsd:sequnece> <xsd:element ref="name"/> <xsd:element ref="size"/> <xsd:element ref="style"/> </xsd:sequnece> </xsd:complexType>也可嵌套定义:
<xsd:complexType name="FontType"> <xsd:sequnece> <xsd:element ref="name"/> <xsd:element ref="size"/> <xsd:element ref="style"> <xsd:simpleType> <xsd:restriction base="xsd:string"> <xsd:enumeration value="PLAIN"/> <xsd:enumeration value="BOLD"/> <xsd:enumeration value="ITALIC"/> <xsd:enumeration value="BOLD_ITALIC"/> </xsd:restriction> </xsd:simpleType> </xsd:element> </xsd:sequnece> </xsd:complexType>xsd:sequence结构与 DTD 的连接符号等价欸,而xsd:choice结构与|操作符等价。如果要允许重复元素,可以使用 minoccurs 和 maxoccurs 属性。如:
<xsd:element name="item" type="..." minoccurs="0" maxoccurs="unbounded" />如果要指定属性,可以把
xsd:attribute元素添加到 complexType 定义中去:<xsd:element name="size"> <xsd:complexType> ... <xsd:attribute name="unit" type="xsd:string" use="optional" default="cm"/> </xsd:complexType> </xsd:element>可以把 Schema 元素和类型定义封装在
xsd:schema元素中:<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> ... </xsd:schema> -
解析带有 Schema 的 XML 文件和解析带有 DTD 的文件相似,但有 2 点差别:
-
必须打开对命名空间的支持,即使在 XML 文件里可能不会用到它。
factory.setNamespaceAware(true); -
必须通过以下的“魔咒”来准备好处理 Schema 的工厂。
final String JAXP_SCHEMA_LANGUAGE = "http://java.sun.com/xml/jaxp/properties/schemaLanguage"; final String W3C_XML_SCHEMA = "http://www.w3.org/2001/XMLSchema"; factory.setAttribute(JAXP_SCHEMA_LANGUAGE, W3C_XML_SCHEMA);
-
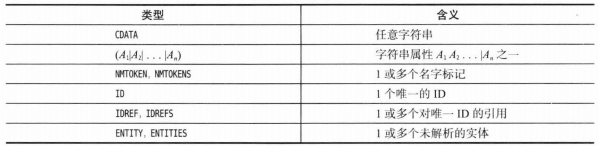

15.5.使用 XPath 来定位信息
-
使用 XPath 的以下操作比普通的 DOM 方式简单的多:
- 获得文档根节点。
- 获取第一个子节点,并将其转型为一个 ELement 对象。
- 在其所有子节点中定位 title 元素。
- 获取其第一个子元素,并将其转型为一个 CharacterData 节点。
- 获取其数据。
-
假设对于 HTML 文档,其 XPath 表达式示例:
html/body/form描述了 HTML 文件中 body 下所有 form 元素,html/body/form[1]描述第一个,html/body/form[1]/@action描述第一个的 action 属性。XPath 表达式还有很多有用的函数,如
count(html/body/form)。 -
XPath 使用,首先创建 XPath 对象,在Dion公用 evaluate、evaluateException(Java9 及以后) 方法:
XPathFactory xpfactory = XPathFactory.newInstance(); XPath xPath = xpfactory.newXPath();String username = xPath.evaluate("/html/head/title/text()", doc); XPathNodes result = xPath.evaluateExpression("/html/body/form", doc, XPathNodes.class); NodeList nodes = (NodeList) xPath.evaluate("", doc, XPathConstants.NODESET); Node node = xPath.evaluateExpression("/html/body/form[1]", doc, Node.class); Node node = (Node) xPath.evaluate("/html/body/form[1]", doc, XPathConstants.NODE); int count = xPath.evaluateExpression("count(/html/body/form)", doc, Integer.class); int count = ((Number) xPath.evaluate("count(/html/body/form)", doc, XPathConstants.NUMBER)).intValue();XPathNodes 与 NodeList 类似,但是扩展了 Iterable 接口。
如果直到有前一次计算得到的节点,可以调用:
String result = xPath.evaluate(expression, node);如果不知道 XPath 表达式计算的结果是什么,可以调用:
XPathEvaluationResult<?> result = xPath.evaluateExpression(expression, doc);result.type()是 XPathEvaluationResult.XPathResultType 枚举 STRING、NODESET、NODE、NUMBER、BOOLEAN 之一。调用result.value()获取结果。
15.6.使用命名空间
-
命名空间是由 URI(Uniform Resource Identifier)来标识的,比如:
http://www.w3.org/2001/XMLSchema uuid:1c759aed-b748-475c-ab68-10679700c4f2 urn:com:books-r-usURL 只用作标识符字符串,而不是一个文件的定位符。在命名空间的 URL 所表示的位置上不需要有任何文档,XML 解析器不会尝试去该处查找任何东西。然而为了给可能会遇到不熟悉的命名空间的程序员提供一些保证,人们习惯于将解释该命名空间的文档放在 URL 位置上。
-
只有子元素继承了它们父元素的命名空间,而不带显示前缀的属性并不是命名空间的一部分。如:
<configuration xmlns="http://www.horstmann.com/corejava" xmlns:si="http://www.bipm.fr/enus/3_SI/si.html"> <size value="210" si:unit="mm"/> ... </configuration>configuration 和 size 都是 URI 为
http://www.horstmann.com/corejava的命名空间一部分,而 si:unit 是 URI 为http://www.bipm.fr/enus/3_SI/si.html的一部分,value 不是任何命名空间的一部分。 -
默认情况下,Java XML 库的 DOM 解析器并非“命名空间感知的”。要打开命名空间处理特性,需要调用 DocumentBuilderFactory 类的 setNamespaceAware 方法。这样该工厂产生的所有生成器便都支持命名空间了。每个节点有三个属性:
- 带有前缀的限定名,由 getNodeName 和 getTagName 等方法返回。
- 命名空间 URI,由 getNamespaceURI 方法返回。
- 不带前缀的命名空间的本地名,由 getLocalName 方法返回。
如果对命名空间的感知特性被关闭,getNodeName 和 getTagName 方法返回 null。
15.7.流机制解析器
-
Java 提供两种流机制解析器:SAX 解析器和 StAX 解析器(Java6 及以上)。SAX 解析器使用的是事件回调,StAX 解析器提供了遍历解析事件的迭代器。
-
SAX 解析器在 XML 输入数据的各个部分时会报告事件,但不会以任何方式存储文档,而是由事件处理器建立相应的数据结构。实际上,DOM 解析器是在 SAX 解析器的基础上构建的,它在接收到解析器事件时构建 DOM 树。
ContentHandler 接口定义了若干个在解析文档时解析器会调用的回调方法。
SAXParserFactory factory = SAXParserFactory.newInstance(); SAXParser parser = factory.newSAXParser(); parser.parse(source, handler);source 可以是一个文件、一个 URL 字符串或者是一个输入流。handler 属于 DefaultHandler(实现了 EntityResolver、DTDHandler、ContentHandler、ErrorHandler)的一个子类。
与 DOM 解析器一样,命名空间处理特性默认是关闭的,可以调用以下方法打开:
factory.setNamespaceAware(true); -
StAX 解析器是一种“拉解析器”,与安装事件处理器不同,只需使用下面这样的基本循环来迭代所有事件:
InputStream in = url.openStream(); XMLInputFactory factory = XMLInputFactory.newInstance(); XMLStreamReader parser = factory.createXMLStreamReader(in); while (parser.hasNext()) { int event = parser.next(); // Call parser methods to obtain event details }默认情况下,命名空间是启用的,通过以下关闭:
factory.setProperty(XMLInputFactory.IS_NAMESPACE_AWARE, false);
15.8.生成 XML 文档
-
不带名称空间:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.newDocument(); Element rootElement = doc.createElement(rootName); rootElement.setAttribute(name, value); doc.appendChild(rootElement); Element childElement = doc.createElement(childName); rootElement.appendChild(childElement); Text textNode = doc.createTextNode(textContents); childElement.appendChild(textNode); -
带名称空间:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); factory.setNamespaceAware(true); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.newDocument(); String namespace = "http://www.w3.org/2000/svg"; Element rootElement = doc.createElementNS(namespace, "svg"); Element svgElement = doc.createElementNS(namespace, "svg:svg"); rootElement.setAttributeNS(namespace, qualifiedName, value); -
写出文档:
Transformer t = TransformerFactory.newInstance().newTransformer(); t.setOutputProperty(OutputKeys.DOCTYPE_SYSTEM, systemIdentifier); t.setOutputProperty(OutputKeys.DOCTYPE_PUBLIC, publicIdentifier); t.setOutputProperty(OutputKeys.INDENT, "yes"); t.setOutputProperty(OutputKeys.METHOD, "xml"); t.setOutputProperty("{http://xml.apache.orgh/xslt}indent-amount", "2"); t.transform(new DOMSource(doc), new StreamResult(new FileOutputStream(file)));DOMImplementation impl = doc.getImplementation(); var implLS = (DOMImplementationLS) impl.getFeature("LS", "3.0"); LSSerializer ser = implLS.createLSSerializer(); ser.getDomConfig().setParameter("format-pretty-print", true); String str = ser.writeToString(doc); LSOutput out = implLS.createLSOutput(); out.setEncoding("UTF-8"); out.setByteStream(Files.newOutputStream(path)); ser.write(doc, out); -
使用 StAX 写出 XML 文档:
XMLOutputFactory factory = XMLOutputFactory.newInstance(); XMLStreamWriter writer = factory.createXMLStreamWriter(out); writer.writeStartDocument(); writer.writeStartElement(name); writer.writeAttribute(name, value); writer.writeCharacters(text); writer.writeEndElement(); writer.writeEmptyElement(name); writer.writeEndDocument();
15.9.XSL 转换
- XSL 转换(XSLT)机制可以指定将 XML 文档转换为其他格式的规则。
第16章 网络
16.1.连接到服务器
-
一个基本的网络程序:
try ( var s = new Socket("time-a.nist.gov", 13); var in = new Scanner(s.getInputStream(), StandardCharsets.UTF_8) ) { while (in.hasNext()) { String line = in.nextLine(); System.out.println(line); } }上述存在两个服务器超时的问题:
- 在套接字读取信息时,在有数据可供访问之前,读操作将会被阻塞。如果此时主机不可达,那么应用将要等待很长的时间,并且因为受底层 OS 的限制而最终导致超时。对于不同的应用,应该确定合理的超时值,调用 setSoTimeout 方法设置该超时值(单位毫秒)。此时超时会抛出异常。
- 对于 Socket 构造会一直无限期地阻塞下去,直到建立了到达主机地初始连接为止。可以通过先构造一个无连接地套接字,然后再使用一个超时来进行连接的方式解决这个问题。
try (Socket s = new Socket()) { s.connect(new InetSocketAddress("time-a.nist.gov", 13), 10_000); s.setSoTimeout(10_000); try (Scanner in = new Scanner(s.getInputStream(), StandardCharsets.UTF_8)) { while (in.hasNext()) { String line = in.nextLine(); System.out.println(line); } } } -
InetAddress.getByName 方法返回掉膘某个主机的 InetAddress 对象,该对象的 getAddress 方法返回其 IP 的 4 字节数组。如:
InetAddress address = InetAddress.getByName("time-a.nist.gov"); byte[] addressBytes = address.getAddress();一些访问量大的主机名通常会对应多个因特网地址,getByName 返回其中一个,getAllByName 则返回所有的 InetAddress 数组。
对于 localhost,getByName 总会返回本地回环地址 127.0.0.1,使用InetAddress.getLocalHost 则得到本地主机的地址。
16.2.实现服务器
-
ServerSocket 用于创建服务器套接字,调用其 accept 方法使程序等待客户端连接到对应端口,该方法返回对应的 Socket 对象。
try (ServerSocket s = new ServerSocket(8189)) { try (Socket incoming = s.accept()) { InputStream inputStream = incoming.getInputStream(); OutputStream outputStream = incoming.getOutputStream(); try (Scanner in = new Scanner(inputStream, StandardCharsets.UTF_8)) { PrintWriter out = new PrintWriter(new OutputStreamWriter(outputStream, StandardCharsets.UTF_8)); // ... } } } catch (IOException e) { // ... }对于服务器支持多个客户端连接,上述代码会使得任何一个客户端都可以因长时间地连接服务而独占服务。这可通过多线程来进行处理,将 accept 的返回对象放在新线程中运行,主线程循环调用 accept 方法。如以下示例,ThreadedEchoHandler 是一个实现了 Runnable 的类:
try (ServerSocket s = new ServerSocket(8189)) { while (true) { try (Socket incoming = s.accept()) { var r = new ThreadedEchoHandler(incoming); var t = new Thread(r); t.run(); } } } catch (IOException e) { } -
半关闭提供这样的能力:套接字连接的一端可以终止其输出,同时仍旧可以接受来自另一端的数据。可以通过关闭一个套接字的输出流来表示发送给服务器的请求数据已经结束,但是必须保持输入流处于打开状态。如:
try (var socket = new Socket(host, post)) { Scanner in = new Scanner(socket.getInputStream(), StandardCharsets.UTF_8); PrintWriter writer = new PrintWriter(socket.getOutputStream()); writer.print(...); writer.flush(); socket.shutdownOutput(); while (in.hasNextLine()) { String line = in.nextLine(); ... } } catch (IOException e) { throw new RuntimeException(e); } -
上述示例中,当线程因套接字无法响应而发生阻塞时,则无法通过调用 interrupt 来解除阻塞。为中断套接字操作,可使用 SocketChannel 类。如:
SocketChannel channel = SocketChannel.open(new InetSocketAddress(host, port));通道并没有与之相关联的流。它的 read、write 方法都是通过使用 Buffer 对象来实现的。WritableByteChannel、ReadableByteChannel 接口声明了这两个方法。
如果不想处理缓冲区,可使用 Scanner 类从 SocketChannel 中获取信息。通过 Channels.newOutputStream 可以将通道转换成输出流。
Scanner in = new Scanner(channel, StandardCharsets.UTF_8); OutputStream outStream = Channels.newOutputStream(channel);当线程正在执行打开、读取和写入操作时,如果线程发生中断,那么这些操作将不会陷入阻塞,而是以抛出异常的方式结束。
16.3.获取 Web 数据
-
URI(Uniform Resource Identifier)是个纯粹的语法结构,包含用来指定 Web 资源的字符串的各个组成部分。URL(Uniform Resource Locator)是 URI 的一个特例,它包含用于定位 Web 资源的足够信息。
-
URI 规范:
[scheme:]schemeSpecificPart[#fragment]包含
[scheme:]部分称为绝对 URI,否则为相对 URI。绝对 URI 的schemeSpecificPart不是以/开头的称为不是透明的。所有绝对透明 URI 和所有相对 URI 都是分层的。一个分层 URI 的 schemeSpecificPart 具有以下结构:
[//authority][path][?query]对于基于服务器的 URI,authority 部分具有以下形式:
[user-info@]host[:port] -
URI 类的作用之一是解析标识符并将它分解成各种不同的组成部分:getScheme、getSchemeSpecificPart、getAuthority、getUserInfo、getHost、getPort、getPath、getQuery、getFragment。
另一个作用是处理绝对标识符和相对标识符:relativize、resolve。
-
构建 URL 对象可使用 String 参数的构造器,URL 对象的 openStream 方法会产生 InputStream 对象。
-
如果想从某个 Web 资源获取更多信息,那么应该使用 URLConnection 类。
操作 URLConnection 类步骤:
-
使用 url 对象的 openConnection 方法获取 URLConnection 对象。
-
调用 URLConnection 对象的一系列 set 方法设置对应的请求属性。
默认情况下,建立的连接只产生从服务器读取信息的输入流,而不产生任何执行写操作的输出流,想获取输出流则需要调用 setDoOutput 方法。
setIfModifiedSince 方法用于告诉连接只对自某个特定日期以来被修改过的数据感兴趣。setRequestProperty 可以用来设置对特定协议起作用的任何”名-值对“。
-
调用 URLConnection 对象的 connection 方法连接远程资源,该方法还可以用于向服务器查询头信息。
-
与服务器建立连接后,可以查询头信息。getHeaderFieldKey和 getHeaderField 方法枚举了消息头的所有字段,getHeaderFields 方法返回一个包含了消息头中所有字段的标准 Map 对象,为了方便使用还有一些如 getContentType 的 get 方法查询各标准字段。
connection.getHeaderFieldKey(n)获取响应头的第 n 个键,键从 1 开始,如果 n 为 0 或者大于消息头的字段总数返回 null(没有哪种方法可以返回字段数量)。connection.getHeaderField(0)和connection.getHeaderFields().get(null)返回响应状态行。为简便起见,Java 提供 6 个方法用以访问最常用的消息头类型的值,其中返回类型为 long 的方法返回的是从格林尼治时间 1970 年 1 月 1 日开始计算的秒数:
![]()
-
最后,访问资源数据。使用 getInputStream 方法获取输入流,该输入流和 URL 对象的 openStream 方法产生的输入流相同。如果服务端出现错误,getInputStream 方法调用会抛出异常,但是,此时服务器可能仍向浏览器返回一个错误页面,为捕捉这个错误页,可调用 getErrorStream 方法返回 InputStream。
-
-
如果要创建以
http://或https://开头的 URL,那么将所产生的连接对象可以强制类型转换为 URLConnection 的子类 HttpURLConnection。 -
如果 cookie 需要在重定向中从一个站点发送给另一个站点,那么可以像下面这样配置一个全局的 cookie 处理器:
CookieHandler.setDefault(new CookieManager(null, CookiePolicy.ACCEPT_ALL));
16.4.HTTP 客户端
-
Java9、Java10 的 HttpClient 位于 jdk.incubator.http 包中,使用时需要添加命令行选项
--add-modules jdk.incubator.http,Java11 时位于 java.net.http 包中。 -
HttpClient 对象可以发出请求并接受响应。可以通过下面的调用获取客户端:
HttpClient client = HttpClient.newHttpClient();或者如果需要配置客户端,可以使用像下面这样的构建器 API:
HttpClient client = HttpClient.newBuilder() .followRedirects(HttpClient.Redirect.ALWAYS) .build();即,获取一个构造器,调用其方法定制需要待构建的项,然后调用 build 方法来终结构造过程。这是一种构建不可修改对象的常见模式。
-
还可以遵循构造器模式来定制请求。如:
HttpRequest request = HttpRequest.newBuilder() .uri(new URI("http://horstmann.com")) .GET() .build(); HttpRequest request = HttpRequest.newBuilder() .uri(new URI(uri)) .header("Content-Type", "application/json") .POST(HttpRequest.BodyPublishers.ofString(jsonString)) .build(); -
在发送请求时,需要告诉客户端如何处理响应。如将响应体当作字符串处理:
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString()); String bodyString = response.body();HttpResponse 是一个泛化接口,它的类型参数表示体的类型。
还有其他响应体处理器:BodyHandlers.ofFile 将响应存储到给定的文件中、BodyHandlers.ofFileDownload 会用 Content-Disposition 头中的信息将响应存入给定的目录中、BodyHandlers.discarding 会直接丢弃响应。
HttpResponse 对象还会产生状态码和响应头:
int status = response.statusCode(); HttpHeaders responseHeaders = response.headers();可以将 HttpHeaders 对象转换为一个映射表,如果只想要某个特定键的值,并且知道它没有多个值,那么可以调用 firstValue 方法:
Map<String, List<String>> headerMap = responseHeaders.map(); Optional<String> lastModified = responseHeaders.firstValue("Last-Modified"); -
对于响应可以异步处理:
HttpClient client = HttpClient.newBuilder() .executor(Executors.newCachedThreadPool()) .build(); HttpRequest request = HttpRequest.newBuilder() .uri(uri) .GET() .build(); client.sendAsync(request, HttpResponse.BodyHandlers.ofString()).thenAccept(response -> ...); -
为了启用针对 HttpClient 记录日志的功能,需要在 JDK 的 net.properties 文件中添加下面的行:
jdk.httpclient.HttpClient.log=all除了 all,还可以指定为一个由逗号分隔的列表,其中包含 headers、requests、content、errors、ssl、trace 和 frames,后面还可以选择跟着
:control、:data、:window或:all。中间不要使用如何空格。然后,将名为 jdk.httpclient.HttpClient 的日志管理器的记录级别设置为 INFO。
16.5.发送 E-mail
-
对于使用套接字:
-
打开一个到达主机的套接字:
Socket s = new Socket("mail.yourserver.com", 25); PrintWriter out = new PrintWriter(new OutputStreamWriter(s.getOutputStream(), StandardCharsets.UTF_8)); -
发送以下信息到打印流:
HELO sending host MAIL FROM: sender e-mail address RCPT TO: recipient e-mail address DATA Subject: subject (blank line) mail message (any number of lines) . QUITSMTP 规范规定,每一行都要以
\r再紧跟一个\n结尾。
-
-
还可以使用 JavaMail,略。
第17章 数据库编程
17.1.JDBC 的设计
-
JDBC 和 ODBC 都遵循一个思想:根据 API 编写的程序都可以与驱动管理器进行通信,而驱动管理器则通过驱动程序与实际的数据库进行通信。
-
JDBC 的三层模型:客户端不直接调用数据库,而是调用服务器上的中间件层,由中间件层完成数据库的查询操作。

17.2.结构化查询语言
- 我们可以将 JDBC 包看作是一个用于将 SQL 语句传递给数据库的 API。
17.3.JDBC 配置
-
JDBC URL 的一般语法为:
jdbc:subprotocol:other stuffsubprotocol用于选择连接到数据库的具体驱动程序。other stuff参数的格式随所使用的subprotocol不同而不同。 -
许多 JDBC 的 JAR 文件会自动注册驱动类。包含
META-INF/services/java.sql.Driver文件的 JAR 文件可以自动注册驱动类。通过使用 DriverManager,可以用两种方式来注册驱动器:
-
在 Java 程序中加载驱动器类,如:
Class.forName("org.postgresql.Driver"); -
设置 jdbc.drivers 属性,这种方式可提供多个驱动器,用冒号将它们分开。如:
java -Djdbc.drivers=org.postgresql.Driver ProgramNameSystem.setProperty("jdbc.drivers", "org.postgresql.Driver");
-
-
连接到数据库:
Connection conn = DriverManager.getConnection(url, username, password);
17.4.使用 JDBC 语句
-
执行 SQL 语句前先获取 Statement 对象:
Statement stat = conn.createStatement();对于 INSERT、UDPATE、DELETE、CREATE TABLE、DROP TABLE 之类的语句,可使用 Statement 的 executeUpdate 方法,对于 SELECT 语句,可以使用 executeQuery 方法返回 ResultSet 对象,还有 execute 方法可以执行任意的 SQL 语句。
对于 ResultSet,其初始化时被设定在第一行之前的位置,必须调用 next 方法移动一行,它没有 hasNext 方法,需要不断调用 next 直到返回 false。ResultSet 的一系列 get 方法可传递 int 参数(表示第几列,从 1 开始)或 String 参数(表示列名),如果 get 方法类型和列的数据类型不一致,每个 get 方法都会进行合理的类型转换。
-
每个 Connection 对象可以创建多个 Statement 对象,每个 Statement 对象可以用于多个不相关的命令和查询。但是,一个 Statement 对象最多只能有一个打开的结果集。每个连接上的语句数是有限制的,可使用 DatabaseMetaData 接口的 getMaxStatements 方法获取 JDBC 驱动程序支持的同时打开的语句对象总数。
确保在一个 Statement 对象上触发新的查询或更新语句之前结束对所有结果集的处理,因为前序查询的所有结果集都会被自动关闭。
使用完 ResultSet、Statement、Connection 对象后,应立即调用 close 方法关闭,后者的 close 方法也会关闭相应前者。可以在 Statement 上调用 closeOnCompletion 方法,在其所有结果集都被关闭后,该语句会立即被自动关闭。
-
每个 SQLException 都有一个由多个 SQLException 对象构成的链,这些对象可以通过 getNextException 方法获取。
SQLException 实现了
Iterable<Throwable>接口,其 iterator 方法返回Iterator<Throwable>。可以在 SQLException 上调用 getSQLState 和 getErrorCode 方法来进一步分析,前者产生符合 X/Open 或 SQL:2003 标准的字符串(调用 DatabaseMetaData 的 getSQLStateType 方法可查出驱动程序所使用的标准),后者产生的错误代码则与具体的提供商相关。SQL 异常类型:
![]()
数据库驱动程序可以将非致命问题作为警告报告,可以从连接、语句和结果集获取这些警告。SQLWarning 是 SQLException 的子类(尽管 SQLWaring 不会被当作异常抛出),调用 getSQLState、getErrorCode 获取警告的更多信息。警告也是串成链的,使用下面的循环获取:
SQLWarning w = stat.getWarnings(); while (w != null) { // do something with w w = w.getNextWarning(); }
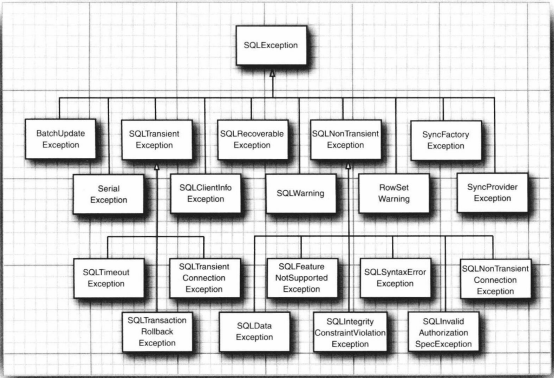
17.5.执行查询操作
-
预备语句的使用示例:
Connection conn = DriverManager.getConnection(""); String publisherQuery = "SELECT Books.Price, Books " + "FROM Books, Publishers " + "WHERE Books.Publisher_Id = Publishers.Publisher_id AND Publishers.Name = ?"; PreparedStatement stat = conn.prepareStatement(publisherQuery); stat.setString(1, publisher); ResultSet resultSet = stat.executeQuery(); -
要读取 LOB,需要执行 SELECT 语句,然后再 ResultSet 上调用 getBlob 或 getClob 方法,这会获得 Blob 或 Clob 对象。
从 Blob 中获取二进制数据可以调用 getBytes 或 getBinaryStream。如:
PreparedStatement stat = conn.prepareStatement("SELECT Cover FROM BookCovers WHERE ISBN = ?"); stat.setString(1, isbn); try (ResultSet result = stat.executeQuery()) { if (result.next()) { Blob coverBlob = result.getBlob(1); Image coverImage = ImageIO.read(coverBlob.getBinaryStream()); ... } }类似的,如果获取 Clob 对象,可以调用 getSubString 或 getCharacterStream 方法来获取其中的字符数据。
-
要将 LOB 置于数据库中,需要在 Connection 对象上调用 createBlob 或 createClob,燃火获取一个用于该 LOB 的输入流或写出器,写出数据,并将该对象存储到数据库中。如:
Blob coverBlob = conn.createBlob(); int offset = 0; OutputStream out = coverBlob.setBinaryStream(offset); ImageIO.write(coverImage, "PNG", out); PreparedStatement stat = conn.prepareStatement("INSERT INTO Cover VALUES (?, ?)"); stat.setString(1, isbn); stat.setBlob(2, coverBlob); stat.executeUpdate(); -
“转义”语法是各种数据库普遍支持的特性,但是数据库使用的是与数据库相关的语法变体,因此,将转移语法转译为特定数据库的语法是 JDBC 驱动程序的任务之一。SQL 转义主要用于下列场景:
-
日期和时间字面常量:需要按照 ISO 8601 格式指定它的值。d、t、ts 分表表示 DATE、TIME 和 TIMESTAMP 值。如:
{d '2008-01-24'} {t '23:59:59'} {ts '2008-01-24 23:59:59.999'} -
标量函数:指仅返回单个值的函数。JDBC 规范提供了标准名字,并将其转译为数据库相关名字。调用函数如下示例:
{fn left(?, 20)} {fn user()} -
存储过程:使用 call 命令,存储过程没有任何参数时,可以不加上括号,使用
=来捕获存储过程的返回值。如:{call PROC1(?, ?)} {call PROC2} {call ? = PROC3(?)} -
外连接。如:
SELECT * FROM {oj Books LEFT JOIN Publishers ON Books.Publisher_Id = Publisher.Publisher_Id} -
在 LIKE 子句中的转义字符:
_和%在 LIKE 子句中具有特殊含义。目前不存在任何在字面上使用它们的标准方式,如果想要匹配_,则必须使用如下面的结构:... WHERE ? LIKE %!_% {escape '!'}这里将
!定义为转义字符,!_表示字面常量下划线。
-
-
一个查询可能返回多个结果集。下面是获取所有结果集的步骤:
- 使用 execute 方法来执行 SQL 语句。
- 获取第一个结果集或更新计数。
- 重复调用 getMoreResults 方法以移动到下一个结果集。
- 当不存在更多的结果集或更新计数时,完成操作。
如果由多结果集构成的链中的下一项是结果集,execute 和 getMoreResults 方法将返回 true,而如果在链中的下一项不是更新计数,getUpdateCount 返回 -1。如:
boolean isResult = stat.execute(command); boolean done = false; while (!done) { if (isResult) { ResultSet result = stat.getResultSet(); // do something with result } else { int updateCount = stat.getUpdateCount(); if (updateCount >= 0) { // do something with updateCount } else { done = true; } } if (!done) { isResult = stat.getMoreResults(); } } -
当我们项数据表中插入一个新行,且其键自动生成时,可以用下面的代码来获取这个键:
stat.executeUpdate(insertStatement, Statement.RETURN_GENERATED_KEYS); ResultSet rs = stat.getGeneratedKeys(); if (rs.next()) { int key = rs.getInt(1); ... }
17.6.可滚动和可更新的结果集
-
默认情况下,结果集是不可滚动和不可更新的。为了从查询中获取可滚动的结果集,必须使用下面的方法得到一个不同的 Statement 对象:
Statement stat = conn.createStatement(type, concurrency); PreparedStatement stat = conn.prepareStatement(command, type, concurrency);type 可取 ResultSet 接口的以下值:
值 解释 TYPE_FORWARD_ONLY 结果集不能滚动(默认值) TYPE_SCROLL_INSENSITIVE 结果集可以滚动,但对数据库变化不敏感 TYPE_SCROLL_SENSITIVE 结果集可以滚动,但对数据库变化敏感 ”对数据库变化是否敏感“指数据库在查询生成结果集之后发生了变化,那么结果集是否反映出这些变化。
concurrency 可取 ResultSet 接口的以下值:
值 解释 CONCUR_READONLY 结果集不能用于更新数据库(默认值) CONCUR_UPDATABLE 结果集可以用于更新数据库 并非所有数据库驱动程序都支持可滚动和可更新的结果集(DatabaseMetaData 的 supportResultSetType、supportResultSetConcurrency 方法查看)。即便是数据库支持所有的结果集模式,某个特定的查询也可能无法产生带有所要求的所有属性的结果集(这种情况下,executeQuery 返回一个功能较少的 ResultSet 对象,并添加一个 SQLWarning 到连接对象)。可以使用 ResultSet 的 getType、getConcurrency 查看实际支持的模式。如果不检查结果集功能就发起一个不支持的操作,那么该操作将抛出异常。
-
ResultSet 的滚动集方法:结果集向上滚动调用 previous 方法,位于实际行返回 true 否则 false。使用 relative 将游标向前或向后移动多行。使用 absolute 将游标移动到指定行(第一行为 1),返回 0 表示不在任何行上。还有 first、last、beforeFirst、afterLast、isFirst、isLast、isBeforeFirst、isAfterLast 方法。
-
可更新的结果集并非必须是可滚动的。
并非所有的查询都会返回可更新的结果集(如查询涉及多个表的连接操作)。ResultSet 的 getConcurrency 确定结果集是否是可更新的。
可更新的结果集更新示例:
Statement stat = conn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE); ResultSet rs = stat.executeQuery(""); while (rs.next()) { if (...) { double increase = ...; double price = rs.getDouble("Price"); rs.updateDouble("Price", price + increase); rs.updateRow(); } }updateXxx 方法也可指定列序号而不一定要列名,注意该列序号是该列在结果集中的序号。
调用 cancelRowUpdates 方法可取消对当前列的更新。如果未调用 updateRow 就将游标移动到其他行,那么对此行所做的所有更新都将被丢弃。deleteRow 方法会立即将游标所指行从结果集和数据库中删除。
可更新的结果集新建一个行示例:
rs.moveToInsertRow(); rs.updateString("Title", title); rs.updateString("ISBN", isbn); rs.updateString("Publisher_Id", pubid); rs.updateDouble("Price", price); rs.insertRow(); rs.moveToCurrentRow();对于插入行没有指定的列将会被设置为 SQL 的 null。如果这个列有 NOT NULL 约束,则会抛出异常,这行也无法插入。
17.7.行集
-
可滚动的结果集需要始终与数据库保存连接。RowSet 接口扩展自 ResultSet 接口,却无须始终保持与数据库的连接。
行集还适用于将查询结果移动到复杂应用的其他层,或者是诸如手机之类的其他设备中。
javax.sql.rowset 包中提供了 CachedRowSet、WebRowSet、FileteredRowSet、JoinRowSet、JdbcRowSet 接口,它们都扩展了 RowSet 接口。
在 Java7 中,获取行集的标准方式:
RowSetFactory factory = RowSetProvider.newFactory(); CachedRowSet crs = factory.createCachedRowSet(); -
CachedRowSet 有一个重要的优点:断开数据库连接后仍然可以使用行集。修改 CachedRowSet 中的数据,这些修改不会立即反馈到数据库中,必须发起一个显式的请求,以便让数据库真正接受所有修改,此时 CachedRowSet 类会重新连接到数据库,并通过执行 SQL 语句向数据库中写入所有修改后的数据。
可以使用一个结果集填充 CachedRowSet 对象:
ResultSet result = ...; RowSetFactory factory = RowSetProvider.newFactory(); CachedRowSet crs = factory.createCachedRowSet(); crs.populate(result); conn.close();使用结果集填充行集,行集无法获知需要更新数据的数据库表名。此时,必须调用 setTable 方法来设置表名。
也可以让 CachedRowSet 对象自动建立一个数据库连接:
RowSetFactory factory = RowSetProvider.newFactory(); CachedRowSet crs = factory.createCachedRowSet(); crs.setUrl("jdbc:derby://localhost:1527/COREJAVA"); crs.setUsername("dbuser"); crs.setPassword("secret"); crs.setCommand("SELECT * FROM Books WHERE Publisher_ID = ?"); crs.setString(1, publisherId); crs.execute();如果查询结果非常大,不想将所有行放入行集中,可以调用 setPageSize 方法设置获取一页并指定页大小,nextPage 方法获取下一页。
可以使用与结果集中相同的方法来查看和修改行集中的数据。如果修改了行集中的内容,那么必须调用以下方法将修改写回到数据库中:
crs.acceptChanges(conn); crs.acceptChanges();在填充了行集之后,将行集写回数据库中时,数据库中的数据有可能发生了变化,它会检查行集中的原始值是否与数据库中的当前值是否一致,一致则覆盖,否则抛出异常且不向数据库中写回任何值。
17.8.元数据
-
在 SQL 中,描述数据库或其组成部分的数据称为元数据。可获得三类元数据:关于数据库的元数据、关于结果集的元数据以及关于预备语句参数的原数据。
-
获取所有数据库表信息的结果集示例:
DatabaseMetaData meta = conn.getMetaData(); ResultSet mrs = meta.getTables(null, null, null, new String[]{"TABLE"}); -
DatabaseMetaData 接口用于提供有关数据库的数据,ResultSetMetaData 则用于提供结果集的相关信息。如:
ResultSet rs = stat.executeQuery("SELECT * FROM " + tableName); ResultSetMetaData meta = rs.getMetaData(); for (int i = 1; i <= meta.getColumnCount(); i++) { String columnName = meta.getColumnLabel(i); int columnWidth = meta.getColumnDisplaySize(i); ... }
17.9.事务
-
默认情况下,数据库连接处于自动提交模式,调用 Connection 的 setAutoCommit 可设置。commit 方法提交事务,rollback 方法回滚,setSavepoint 方法设置保存点,releaseSavepoint 释放保存点。
-
对于批量更新,DatabaseMetaData 接口的 supportsBatchUpdates 方法可获知是否支持该特性。
同一批语句可以是 INSERT、UPDATE、DELETE、CREATE TABLE、DROP TABLE 等,但添加 SELECT 语句会抛出异常。
Statement 的 addBatch 方法添加一条语句到批操作,executeBatch 方法执行批操作。整个批操作被视为单个事务。
-
JDBC 支持的 SQL 数据类型以及它们在 Java 语言中对应的数据类型:
![]()
从数据库中获得一个 LOB 或数组并不等于获取了它的实际内容,只有在访问具体的值时它们才会从数据库中被读取出来。
17.10.Web 与企业应用中的连接管理
第18章 日期和时间 API
Java1.0 的 Date 类事后证明它过于简单了,Java1.1 引入 Calendar 类后,Date 类中的大部分方法就被弃用了。
18.1.时间线
-
1967 年开始,根据铯 133 原子的内在特性推导出秒的新的精确定义。官方时间的维护器时常需要将绝对时间与地球自转进行同步(官方时间每天不一定是 86400 秒)。
-
Java 的 Date 和 Time API 规范要求 Java 使用的时间尺度为:
- 每天 86400 秒。
- 每天正午与官方时间精确匹配。
- 在其他时间点上,以精确定义的方式与官方时间接近匹配。
-
在 Java 中,Instant 表示时间线上的某个点。原点被设置为穿过伦敦格林尼治皇家天文台的本初子午线所处时区的 1970 年 1 月 1 日的午夜。从原点开始,时间按照每天 86400 秒向前或向后度量,精确到纳秒。Instant 的值向前可追溯 10 亿年(Instant.MIN),最大的值 Instant.MAX 是公元 1000000000 年的 12 月 31 日。
-
Instant.now 给出当前时刻,equals 和 compareTo 方法可用来比较两个 Instant 对象,可以将 Instant 对象用作时间戳。
Duration.between 方法获取两个时刻之间的时间差。duration 对象的 toNanos、toMillis、getSeconds、toMinutes、toHours、toDays 获得 Duration 按照传统单位度量的时间长度。如果精确到纳米级,需要注意上溢问题,long 值最多可存储大约 300 年时间对应的纳秒数。可以使用更长的 Duration,即让 Duration 对象用一个 long 存储秒数,用另外一个 int 来存储纳秒数。
可以使用以下代码获取算法执行时间:
Instant start = Instant.now(); runAlgorithm(); Instant end = Instant.now(); Duration timeElapsed = Duration.between(start, end); long millis = timeElapsed.toMillis();如果检验某个算法是否比另一个算法至少快 9 倍,可执行:
boolean overTenTimesFaster = timeElapsed.multipliedBy(10).minus(timeElapsed2).isNegative(); boolean overTenTimesFaster = timeElapsed.toNanos() * 10 < timeElapsed2.toNanos();Instant 和 Duration 都是不可修改的类,所以诸如 multipliedBy、minus 这样的方法都返回新的对象。
18.2.本地日期
-
在 Java API 中有两种人类时间,本地日期 LocalDate/本地时间 LocalTime 和时区时间 ZonedDateTime。
-
有许多计算并不需要时区,在某种情况下,时区甚至是一种阻碍。考虑到这个原因,API 的设计者们推荐程序员不要使用时区时间,除非确实想要表示绝对时间的实例。生日、假日、计划时间等通常最好都表示成本地日期/本地时间。
-
LocalDate 是带有年、月、日的日期。为构建 LocalDate 对象,可以使用 now、of 静态方法。与 UNIX 和 java.util.Date 中使用的月从 0 开始计算而年从 1900 开始计算的不规则惯用法不同,需要提供通常使用的月份数字,或者可以使用 Month 枚举。如:
LocalDate today = LocalDate.now(); LocalDate alonzosBirthday = LocalDate.of(1903, 6, 14); LocalDate alonzosBirthday = LocalDate.of(1903, Month.JUNE, 14); -
Instant 之间的时长用 Duration 表示,而 LocalDate 之间的时长用 Period 表示。
-
LocalDate 对象的 plus、minus 系列方法获取新的 LocalDate 对象,until 方法只含有一个 ChronoLocalDate 参数的版本返回两个 LocalDate 差的 Period 对象,不过实际上该 Period 对象并不是很有用,因为每个月天数不同,可以使用 until 方法含 Temporal 参数和 TemporalUnit 参数版本。如以下获取两个 LocalDate 之间的天数差:
long days = independenceDay.until(christmas, ChronoUnit.DAYS); -
LocalDate 对象的 getDayOfWeek 会产生星期日期,即 DayOfWeek 枚举的某个值,DayOfWeek.MONDAY 的枚举值为 1,DayOfWeek.SUNDAY 的枚举值为 7。DayOfWeek 枚举的 getValue 方法获取枚举值,plus、minus 方法以 7 为模计算星期日期。
java.util.Calendar 的周日枚举值为 1,周六枚举值为 7。
-
LocalDate 对象的 dateUntil 方法产生 LocalDate 对象流。如:
LocalDate start = LocalDate.of(2000, 1, 1); LocalDate endExclusive = LocalDate.now(); Stream<LocalDate> allDays = start.datesUntil(endExclusive); Stream<LocalDate> firstDaysInMonth = today.datesUntil(endExclusive, Period.ofMonths(1)); -
除了 LocalDate 之外,还有 MonthDay、YearMonth 和 Year 类可以描述部分日期。
18.3.日期调整器
-
TemporalAdjusters 类提供了大量用于常见调整的静态方法,可以将调整方法的结果传递给 LocalDate 对象的 with 方法。如某个月的第一个星期二可以像下面这样计算:
LocalDate firstTuesDay = LocalDate.of(year, month, 1).with(TemporalAdjusters.nextOrSame(DayOfWeek.TUESDAY)); -
还可以通过实现 TemporalAdjuster 接口来创建自己的调整器。下面是用于计算下一个工作日的调整期:
TemporalAdjuster NEXT_WORKDAY = w -> { var result = (LocalDate) w; do { result = result.plusDays(1); } while (result.getDayOfWeek().getValue() >= 6); return result; };注意 lambda 表达式的参数类型为 Temporal,它必须被强制类型转换为 LocalDate。使用 TemporalAdjusters.ofDateAdjuster 可以避免这种强制类型转换,该方法接受参数类型为
UnaryOperator<LocalDate>,如:TemporalAdjuster NEXT_WORKDAY = TemporalAdjusters.ofDateAdjuster(w -> { var result = w; do { result = result.plusDays(1); } while (result.getDayOfWeek().getValue() >= 6); return result; });
18.4.本地时间
-
LocalTime 表示当日时刻,用 now 或 of 方法创建其实例。如:
LocalTime rightNow = LocalTime.now(); LocalTime bedTime = LocalTime.of(22, 30); -
LocalTime 的 plus、minus 实例方法都是按照一天 24 小时循环操作的。
-
还有一个表示日期和时间的 LocalDateTime 类,这个类适合存储固定时区的时间点。
18.5.时区时间
-
互联网编码分配管理机构(Internet Assigned Numbers Authority,IANA)保存着一个数据库,里面存储着世界上所有已知的时区,它每年会更新数次,而批量更新会处理夏令时的变更规则。Java 使用了 IANA 数据库。
-
每个时区都有一个 ID(如 America/New_York、Europe/Berlin)。想要找出所有可用的时区,可以调用 ZoneId.getAvailableZoneIds。
-
给定一个时区 ID,静态方法 ZoneId.of 可以产生一个 ZoneId 对象。可以通过调用
local.atZone(zoneId)用这个对象将 LocalDateTime 对象转换为 ZonedDateTime 对象,或者可以通过调用静态方法ZonedDateTime.of(year, month, day, hour, minute, second, nano, zoneId)来构造一个 ZonedDateTime 对象。 -
ZonedDateTime 对象的 toInstant 方法获得对应的 Instant 对象。反过来,
instant.atZone(ZoneId.of("UTC"))则获得格林尼治皇家天文台的 ZonedDateTime 对象。 -
当夏令时开始时,时钟要向前拨快一小时。当构建的时间对象正好落入着跳过去的一个小时内时,时间会快一小时。
ZonedDateTime skipped = ZonedDateTime.of( LocalDate.of(2013, 3, 31), LocalTime.of(2, 30), ZoneId.of("Europe/Berlin") ); // Constructs March 31 3:30反过来,当夏令时结束时,时钟要像回拨慢一小时,这样同一个本地时间就会出现两次。但构建位于这个时间段内的时间对象时,就会得到这两个时刻中较早的一个。
ZonedDateTime ambiguous = ZonedDateTime.of( LocalDate.of(2013, 10, 27), LocalTime.of(2, 30), ZoneId.of("Europe/Berlin") ); // 2013-10-27T02:30+02:00[Europe/Berlin] ZonedDateTime anHourLater = ambiguous.plusHours(1); // 2013-10-27T02:30+01:00[Europe/Berlin]一个小时后具有相同的小时和分钟,但是时区的偏移量会发生变化。
在调整跨越夏令时边界的日期时需要特别注意。例如,如果将会议设置在下个星期,不要直接加上一个 7 天的 Duration,而是应该使用 Period 类:
ZonedDateTime nextMeeting = meeting.plus(Duration.ofDays(7)); // Caution! Won't work with daylight saving time ZonedDateTime nextMeeting = meeting.plus(Period.ofDays(7)); -
还有一个 OffsetDateTime 类,它表示与 UTC 具有偏移量的时间,但是没有时区规则的束缚。这个类被设计用于专用应用,这些应用特别需要剔除这些规则的约束,如某些网络协议。对于人类时间还是应该使用 ZonedDateTime。
18.6.格式化和解析
-
DateTimeFormatter 类提供了三种用于打印日期/时间值的格式器:预定义的格式器、locale 相关的格式器、带有定制模式的格式器。
java.time.format.DateTimeFormatter 类被设计用来替代 java.util.DateFormat,如果为了向后兼容性而需要后者的实例,可以调用 toFormat 方法。
-
预定义的格式器:
![]()
如:
ZonedDateTime apollo11launch = ZonedDateTime.of(1969, 7, 16, 9, 32, 0, 0, ZoneId.of("America/New_York")); String formatted = DateTimeFormatter.ISO_OFFSET_DATE_TIME.format(apollo11launch); // 1969-07-16T09:32:00-04:00 -
对于日期和时间而言,有 4 种与 locale 相关的格式化风格:
![]()
静态方法 ofLocalizedDate、ofLocalizedTime、ofLocalizedDateTime 可以创建这种格式器。如:
DateTimeFormatter formatter = DateTimeFormatter.ofLocalizedDateTime(FormatStyle.LONG); String formatted = formatter.format(apollo11launch); // July 16, 1969 9:32:00 AM EDT这些方法使用了默认的 locale,为切换到不同的 locale,可以直接使用 withLocale 方法:
String formatted = formatter.withLocale(Locale.FRENCH).format(apollo11launch); // 16 juillet 1969 09:32:00 EDTDayOfWeek、Month 枚举都有 getDisplayName 方法,可以按照不同的 locale 和格式给出星期日期和月份的名字。如:
for (DayOfWeek w : DayOfWeek.values()) { System.out.println(w.getDisplayName(TextStyle.SHORT, Locale.ENGLISH) + " "); // Prints Mon Tue Wed Thu Fri Sat Sun } -
定制模式的格式器,使用静态方法 ofPattern,传入的 String 参数,按照人们日积月累而定制的显得有些晦涩的规则,每个字母都表示一个不同的时间域,而字母重复的次数对应于所选择的特定格式:
![]()
如:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("E yyyy-MM-dd HH:mm"); String formatted = formatter.format(apollo11launch); // Wed 1969-09-16 09:32 -
为解析字符串中的日期/时间值,可以使用众多的静态 parse 方法之一。如:
LocalDate churchsBirthday = LocalDate.parse("1903-06-14"); ZonedDateTime apollo11launch = ZonedDateTime.parse("1969-07-16 03:32:00-0400", DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ssxx"));前者使用标准的 ISO_LOCAL_DATE 格式器,后者使用定制的格式器。
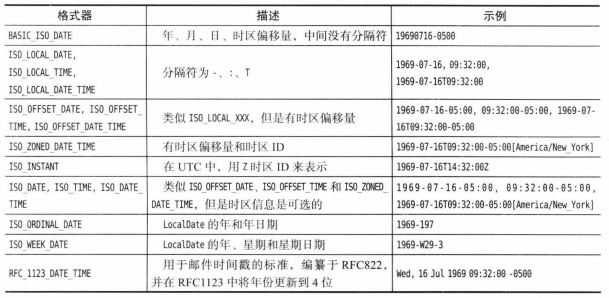

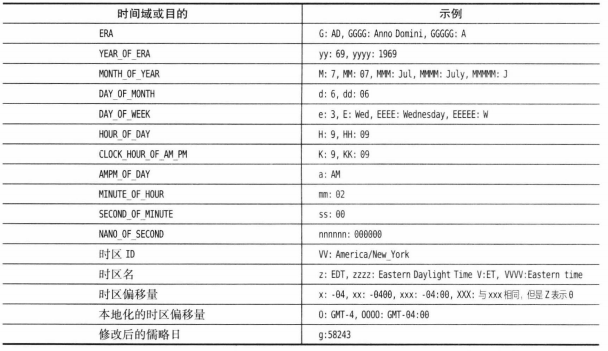
18.7.与遗留代码的互操作
-
Instant 类近似于 java.util.Date。Java8 中,这个类有两个额外的方法:将 Date 转换为 Instant 的 toInstant 方法,以及反方向转换的静态方法 from。
-
ZonedDateTime 类近似于 java.util.GregorianCalendar。Java8 中,这个类有细粒度的转换方法。toZonedDateTime 方法可以将 GregorianCalendar 转换为 ZonedDateTime,而静态的 from 方法可以执行反方向的转换。
-
另一个可用于日期和时间类的转换集位于 java.sql 包中。可以传递一个 DateTimeFormatter 给使用 java.text.Format 的遗留代码。下表对这些转换进行了总结:
![]()
![]()

第19章 国际化
19.1.locale
-
locale 由 5 个部分组成:
-
一种语言,由 2 个或 3 个小写字母表示。常见的 ISO-639-1 语言代码:
![]()
-
可选的一段脚本,由首字母大写的四个字母表示。如 Latin(拉丁文)、Cyrl(西里尔文)、Hant(繁体中文)。
-
可选的一个国家或地区,由 2 个大写字母或 3 个数字表示。常见的 ISO-3166-1 国家代码:
![]()
-
可选的一个变体,用于指定各种杂项特性。如方言和拼写规则。
-
可选的一个扩展。扩展描述了日历(例如日本历)和数字(替代西方数字的泰语数字)等内容的本地偏好。Unicode 标准规范了其中的某些扩展,这些扩展应该以
u-和两个字母的代码开头,这两个字母的代码制定了该扩展处理的时日历(ca)还是数字(nu),或者是其他内容。例如u-nu-thai表示使用泰语数字。其他扩展是完全任意的,并且以x-开头,如x-java。
locale 是用标签描述的,标签是由 locale 的各个元素通过连字符连接起来的字符串,例如
en-US。如果只指定了语言,那么该 locale 就不能用于与国家相关的场景,如货币。
-
-
可以像下面这样用标签字符串来构建 Locale 对象:
Locale usEnglish = Locale.forLanguageTag("en-US");toLanguageTag 方法可以生成给定 locale 的语言标签。如
Locale.US.toLanguageTag()生成字符串"en-US"。为方便起见,有许多为各个国家定义的 Locale 对象,如
Locale.CANADA、Locale.CHINA、Locale.RPC。还有许多预定义的语言 Locale,它们只设定了语言而没有设定位置,如Locale.CHINESE、Locale.ENGLISH。静态的 getAvailableLocales 方法会返回由 Java 虚拟机能识别的所有 locale 构成的数组。可以用 Locale.getISOLanguages 获取所有语言代码,使用 Locale.getISOCountries 获取所有国家代码。
-
Locale.getDefault 获得作为本地 OS 的一部分而存放的默认 locale。可以调用 setDefault 来改变默认的 Java locale(只对程序有效,对 OS 不会有影响)。
-
有些 OS 允许用户为显示消息和格式化指定不同的 locale,想要获取这些偏好可调用:
Locale displayLocale = Locale.getDefault(Locale.Category.DISPLAY); Locale formatLocale = Locale.getDefault(Locale.Category.FORMAT); -
在 UNIX 中,可以为数字、货币和日期分别设置 LC_NUMERIC、LC_MONETARY、LC_TIME 环境变量来指定不同的 locale。但是 Java 并不会关注这些设置。
-
启动程序时改变默认的 locale,如:
java -Duser.language=de -Duser.region=CH MyProgram -
Locale 类中唯一有用的是那些识别语言和国家代码的方法,其中最重要的一个是 getDisplayName,它返回一个描述 locale 的字符串。不过显示的名字是以默认的 locale 来显示的,这可能不太恰当,可以使用对应的 Locale 参数。如:
Locale loc = new Locale("de", "CH"); System.out.println(loc.getDisplayName(Locale.GERMAN)); -
即使把字符串中字母大小写转换也可能是与 locale 相关的,toUpperCase、toLowerCase 可接受 Locale 参数。
-
可以显示地指定输入/输出操作的 locale。从 Scanner 读入数字时,可用 useLocale 方法设置它的 locale。String.format 和 PrinterWriter.printf 方法也可接受一个 Locale 参数。
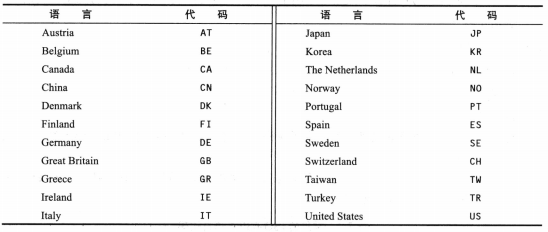
19.2.数字格式
-
Java 类库提供了一个格式器对象的集合,它可以对 java.text 包中的数字值进行格式化和解析。
-
可以通过以下步骤对特定的 locale 数字进行格式化:
- 获得 Locale 对象。
- 使用 NumberFormat 的工厂方法 getNumberInstance、getCurrencyInstance、getPercentInstance 得到格式器对象(该对象类型是抽象类 NumberFormat 的子类)。这些格式器对象可以分别对数字、货币量、百分比进行格式化和解析。
- 使用这些格式器对象进行格式化和解析。
-
对德语中货币值进行格式化示例:
Locale loc = Locale.GERMAN; NumberFormat currFmt = NumberFormat.getCurrencyInstance(loc); double amt = 123456.78; String result = currFmt.format(amt);读取一个按照某个 locale 的惯用法而输入或存储的数字,那么就需要使用 parse 方法:
TextField inputField; ... NumberFormat fmt = NumberFormat.getNumberInstance(); Number input = fmt.parse(inputField.getText().trim()); double x = input.doubleValue();parse 返回类型为 Number,返回对象类型为 Double 或 Long。
-
格式化货币值可使用 getCurrencyInstance 获取对应的格式化器对象进行格式化。
为美国用户设置欧元格式示例:
NumberFormat euroFormatter = NumberFormat.getCurrencyInstance(Locale.US); euroFormatter.setCurrency(Currency.getInstance("EUR"));Currency.getInstance 的货币标识符参数由 ISO 4217 定义,这是其中一部分:
![]()

19.3.日期和时间
-
星期的第一天可以是周六、周日、周一,取决于 locale,可以通过以下方式获取星期的第一天:
DayOfWeek first = WeekFields.of(locale).getFirstDayOfWeek();
19.4.排序和规范化
-
Java 中,compareTo 比较字符串使用的是 UTF-16 编码值。
-
为获得 locale 敏感的比较器,可以调用 Collator.getInstance 方法。如:
Collator coll = Collator.getInstance(locale); words.sort(coll); -
排序器有几个高级的设置项。可以设置排序器的强度来选择不同的排序行为。字符间的差别可以被分为首要的(primary)、其次的(secondary)和再其次的(teriary),对应的强度分别为 Collator.PRIMARY、Collator.SECONDARY、Collator.TERTIARY,最后还有 Collator.IDENTICAL,它不允许存在任何差别。具体是哪个强度在产生作用取决于语言环境。
各强度下排序示例(英语 locale):
![]()
-
强度被设置为 Collator.IDENTICAL 时,在与排序器的另一种设置——分解模式,联合使用时,会非常有用。
一个字符或字符序列被描述为 Unicode 时可能有多种方式。如“Å”可以是 U+00C5,也可以是 U+0065 和 U+030A(“A”加上方组合环重音符号)。Unicode 标准对字符串定义了四种规范化格式:D、KD、C、KC。在规范化 C 中,重音符号总是组合的;在规范化 D 中,重音字符被分解为基字符和组合重音符。规范化形式 KC 和 KD 也会分解字符,例如连字或商标。
可以选择排序器的规范化程度:Collator.NO_DECOMPOSITION 不做对字符串做任何规范化、Collator.CANONICAL_DECOMPOSITION(默认值)使用规范化形式 D、Collator.FULL_DECOMPOSITION 使用规范化形式 KD 的“完全分解”。如以下例子:
![]()
-
Collator 的 getCollationKey 方法返回一个 CollationKey 对象,可使用它进行更进一步、更快速的比较操作。如:
String a = ...; CollationKey aKey = coll.getCollationKey(a); if (aKey.compareTo(coll.getCollationKey(b)) == 0) { ... } -
Normalizer.normalize 方法可以实现将字符串转换为其规范化形式。如:
String name = "Ångström"; String normalized = Normalizer.normalize(name, Normalizer.Form.NFD); // uses normalization form D


19.5.消息格式化
-
Message 类可以用来对包含变量部分的文本进行格式化,它的格式化方式与 printf 方法类似,但是它支持 locale,并且可以对数字和日期进行格式化。
-
Message 类格式化数字和日期示例:
String msg = MessageFormat.format("On {2}, a {0} destroyed {1} houses and caused {3} of damage.", "hurricane", 99, new GregorianCalendar(1999, 0, 1).getTime(), 10.0E8); // On 1999/1/1 上午12:00, a hurricane destroyed 99 houses and caused 1,000,000,000 of damage.占位符索引后面可以跟一个类型和一个风格,之间用逗号隔开。类型,以及它能选择的风格可以是:
- number:风格可以是 integer、currency、percent,或者数字格式模式(如
$、##0)。 - time、date:风格可以是 short、medium、long、full,或者一个日期格式(如
yyyy-MM-dd)。 - choice:风格是一个选择格式。选择格式是由一个序列对构成的,每一个包括一个下限和一个格式字符串,下线和格式化字符串由
#分隔,对与对之间用|分隔。事实上,第一个下限会被忽略。可以使用<替代#来表示严格小于下限。如果愿意的话,第一个下限可以设为-∞(Unicode 代码为 -\u221E)。
如:
String msg = MessageFormat.format("On {2, date, long}, a {0} destroyed {1} houses and caused {3, number, currency} of damage.", "hurricane", 99, new GregorianCalendar(1999, 0, 1).getTime(), 10.0E8); // On 1999年1月1日, a hurricane destroyed 99 houses and caused ¥1,000,000,000.00 of damage.又如,对于
{1, choice, 0#no houses|1#one house|2#{1} houses},{1}取不同值的格式化值:![]()
MessageFormat.format 使用当前的 locale 对值进行格式化。想要用任意的 locale 进行格式化,由于未提供“varargs”参数方法,就必须将格式化的值保存到 Object 数组中。如:
MessageFormat mf = new MessageFormat(pattern, loc); String msg = mf.format(new Object[]{ values }); - number:风格可以是 integer、currency、percent,或者数字格式模式(如

19.6.文本输入和输出
-
任何使用 println 方法写入的行都是被正确终止的。唯一的问题是是否打印了包含
\n字符的行,它们不会被修改为平台的行结束符。而使用%n会产生平台相关的行结束符。如:out.println("Hello%nWorld%n");在 Windows 上产生
Hello\r\nWorld\r\n,在其它所有平台上产生Hello\nWorld\n。 -
Charset.defaultCharset 返回的是 JVM 的默认 charset,默认 charset 在虚拟机启动时决定,通常根据语言环境和底层操作系统的 charset 来确定,可通过启动 JVM 时的
-Dfile.encoding修改。System.setProperty("file.encoding", "xxx")并不会修改 defaultCharset,因为后者在 JVM 启动时就已经确定了。 -
来自 java.util.logging 库的日志消息被发送到控制台时,会采用控制台的编码机制来书写。文件中的日志消息会使用 FileHandler 来处理,他在默认情况下使用平台的编码机制。
-
在向 javac 编译器传递有效的以字节顺序标志开头的 UTF-8 源文件时,编译会以产生错误消息“illegal character:\65279”而失败。
-
只有编译后的 class 文件才能随处使用,因为它们会自动地使用“modified UTF-8”编码来处理标识符和字符串。程序编译和运行时,涉及 3 种字符编码:
- 源文件:平台编码。
- 类文件:modified UTF-8。
- 虚拟机:UTF-16。
19.7.资源包
-
资源包的命名规则:baseName_language_country 或者 baseName_language。最后作为后备,可以把默认资源放到一个没有后缀的文件中。
-
可以使用下面的命令加载一个包:
ResourceBundle currentResources = ResourceBundle.getBundle(baseName, currentLocale);其查找资源包顺序为:
- baseName_currentLocaleLanguage_currentLocaleCountry
- baseName_currentLocaleLanguage
- baseName_currentLocaleLanguage_defaultLocaleCountry
- baseName_defaultLocaleLanguage
- baseName
未查找到会抛出异常。
查找到对应的包了也会继续查找,继续被查找的包会成为“父包”。当需要的资源在对应包不存在时,会在其“父包”中查找。
-
资源包可以是一个 properties 文件,也可以是一个扩展了 ResourceBundle 的类。而实现资源包类最简单的方法就是继承 ListResourceBundle 类,ListResourceBundle 类会让你把所有资源放到一个对象数组中并提供查找功能。需要遵循以下的代码框架:
public class baseName_language_country extends ListResourceBundle { private static final Object[][] contents = { {key1, value1}, {key2, value2}, ... }; @Override protected Object[][] getContents() { return contents; } }// TODO:这是什么语法???或者可以继承 ResourceBundle 类,然后实现 getKeys 方法(用于枚举所有键)和 handleGetObject 方法(用给定的键查找对应的值),ResourceBundle 类的 getObject 方法会调用提供的 handleGetObject 方法。
Java9 之前,属性文件都是 ASCII 文件。如果使用旧版本的 Java,并且需要将 Unicode 字符放到属性文件中,则使用 \uxxxx 编码方式对它们编码。
当搜索包时,如果类中的包和属性文件中的包都存在匹配,则优先选择类中的包。
19.8.一个完整的例子
第20章 脚本、编译与注解处理
20.1.Java 平台的脚本机制
-
当 JVM 启动时,它会发现可用的脚本引擎。枚举这些引擎,需要调用 scriptEngineManager 的 getEngineFactories 方法。可以获取支持的引擎名、MIME 类型和文件扩展名。如:
![]()
通常,直到所需要的引擎,可以直接通过名字、MIME 类型或者文件扩展请求它。如:
ScriptEngine engine = manager.getEngineByName("nashorn"); -
有了引擎,可以通过 eval 方法调用脚本。可以提供一个 String,或者 Reader。
Object result = engine.eval(scriptString); Object result = engine.eval(reader);可以在同一个引擎上调用多个脚本。如果一个脚本定义了变量、函数或类,那么大多数引擎都会保留这些定义,以供将来使用。如:
engine.eval("n = 1728"); Object result = engine.eval("n + 1"); -
想要知道在多个线程中并发执行脚本是否安全,可以调用:
ScriptEngineFactory factory = engine.getFactory(); Object param = factory.getParameter("THREADING");返回值是下列之一:
- null:并发执行不安全。
- MULTITHREADED:并发执行安全。一个线程的执行效果对另外的线程有可能是可视的。
- THREAD-ISOLATED:除了 MULTITHREADED,还会为每个线程维护不同的变量绑定。
- STATELESS:除了 THREAD-ISOLATED,脚本还不会改变变量绑定。
-
可以像引擎中添加新的变量绑定,绑定由名字及其相关联的 Java 对象构成。如:
engine.put("k", 1728); Object result = engine.eval("k + 1");脚本代码从”引擎作用域“中的绑定里读取 k 的定义,因为大多数脚本语言都可以访问 Java 对象,通常使用的是比 Java 语法更简单的语法。如:
engine.put("b", new JButton()); engine.eval("b.text = 'Ok'");除了引擎作用域外,还有全局作用域。任何添加到 ScriptEngineManager 中的绑定对所有引擎都是可见的。
除了向引擎或全局作用域添加绑定之外,还可以将绑定收集到一个类型为 Bindings 的对象中,然后将其传递给 eval 方法。如:
Bindings scope = engine.createBindings(); scope.put("b", new JButton()); engine.eval(scriptString, scope);如果绑定集不应该为将来对 eval 方法调用而持久化,那么这么做就很有用。
使用引擎作用域和全局作用域之外的其他域,需要自己解决。需要一个实现了 ScriptContext 接口的类,管理着一个作用域集合。每个作用域都是由一个整数标识的,越小应该越先被搜索。(标准类库提供了 SimpleScriptContext 类,但是它只能持有全局作用域和引擎作用域。)
-
通过调用脚本上下文的 setReader 和 setWriter 方法来重定向脚本的标准输入和输出。如:
StringWriter writer = new StringWriter(); engine.getContext().setWriter(new PrintWriter(writer, true));setReader 和 setWriter 只会影响脚本引擎的标准输入和输出源。如下面的 JavaScript 代码只有第一个被重定向:
println("Hello"); java.lang.System.out.println("World");Nashorn 引擎没有标准输入源的概念,因此调用 setReader 没有任何效果。
-
调用脚本语言的函数,需要对应引擎实现了 Invocable 接口(如 Nashorn),需要使用函数名来调用 invokeFunction 方法,函数名后面是函数的参数。如:
// JavaScript engine.eval("function greet(how, whom) { return how + ',' + whom + '!' }"); Object result = ((Invocable) engine).invokeFunction("greet", "Hello", "World");如果脚本语言是面向对象的,那么就可以调用 invokeMethod。如:
// JavaScript engine.eval("function Greeter(how) { this.how = how }"); engine.eval("Greeter.prototype.welcome = function(whom) { return this.how + ', ' + whom + '!' }"); Object yo = engine.eval("new Greeter('Yo')"); Object result = ((Invocable) engine).invokeMethod(yo, "welcome", "World");即时引擎没有实现 Invocable 接口,也可使用一种独立于语言的方式来调用某个方法。ScriptEngineFactory 的 getMethodCallSyntax 方法可以产生一个字符串,可将其传递给 eval 方法。但是所有的方法参数必须都与名字绑定,而 invokeMethod 方法可以是任意值调用的。
可以让脚本引擎实现一个 Java 接口,然后就可以用 Java 方法调用语法来调用脚本函数。其细节取决于脚本引擎,但是典型情况是需要为该接口中的每个方法提供一个函数。如:
public interface Greeter { String welcome(String whom); }engine.eval("function welcome(whom) { return 'Hello, ' + whom + '!' }"); Greeter g = ((Invocable) engine).getInterface(Greeter.class); String result = g.welcome("World");总之,如果想从 Java 中调用脚本代码,同时又不想因这种脚本语言的语法而受到困扰,那么 Invocable 接口就很有用。
-
某些脚本引擎处于对执行效率的考虑,可以将脚本代码编译为某种中间格式,这些引擎实现了 Compilable 接口。只需要重复执行时,我们才希望编译脚本。编译执行示例:
FileReader reader = new FileReader("myscript.js"); CompiledScript script = null; if (engine instanceof Compilable) { script = ((Compilable) engine).compile(reader); } if (script != null) { script.eval(); } else { engine.eval(reader); }

20.2.编译器 API
-
调用编译器示例:
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler(); OutputStream outStream = ...; OutputStream errStream = ...; int result = compiler.run(null, outStream, errStream, "-sourcepath", "src", "Test.java");返回 0 表示编译成功。编译器回想给它的流发送输出和错误信息,如果将这些值设置为 null,则会使用 System.out 和 System.err。run 的第一个参数为输入流,由于编译器不会接受任何控制台输入,因此总是应该让其保持为 null。
如果在命令行调用 javac,那么 run 方法其余的参数就会作为变量传递给 javac。这些变量是一些选项或文件名。
-
通过 CompilationTask 对象可以对编译过程进行更多的控制,如从字符串中提供源码,在内存中捕获类文件,或者处理错误和警告信息。按照下面的方式调用:
JavaCompiler.CompilationTask task = compiler.getTask( errWriter, // Uses System.err if null fileManager, // Uses the standard file manager if null diagnostics, // Uses System.err if null options, // null if no options classes, // For annotation processing; null if none sources);最后三个参数是 Iterable 的实例。如 options 可为
List.of("-d", "bin")。classes 参数只用于注解处理。在这种情况下,还需要一个 Processor 对象的列表来调用
task.processors(annotationProcessors)。sources 是 JavaFileObject 实例。如果要编译磁盘文件,调用 standardJavaFilemanager 对象的 getJavaFileObjects 方法。如:
StandardJavaFileManager fileManager = compiler.getStandardFileManager(null, null, null); Iterable<? extends JavaFileObject> sources = fileManager.getJavaFileObjectsFromStrings(List.of("File1.java", "File2.java"));getTask 方法会返回任务对象,但是不会启动编译过程。CompilationTask 类扩展了
Callable<Boolean>,可以将其对象传递给 ExecutorService 以并行执行,或者只是做出如下的同步调用:Boolean success = task.call(); -
为了监听错误信息,需要按照一个 DiagnosticListener,这个监听器会在编译器报告警告或错误消息时收到一个 Diagnostic 对象。DiagonsticCollector 类实现了这个接口,它将收集所有的诊断信息,使得可以在编译完成之后遍历这些信息。如:
DiagnosticCollector<JavaFileObject> collector = new DiagnosticCollector<>(); compiler.getTask(null, fileManager, collector, null, null, sources).call(); for (Diagnostic<? extends JavaFileObject> d : collector.getDiagnostics()) { System.out.println(d); }还可以在 StandardJavaFilemanager 安装 DiagnosticListener 对象,这样就可以捕获到有关文件缺失的消息。如:
StandardJavaFileManager fileManager = compiler.getStandardFileManager(diagnostics, null, null); -
如果动态地生成了源代码,那么就可以内存种获取它来进行编译,而无须在磁盘上保存文件。如:
public class StringSource extends SimpleJavaFileObject { private String code; StringSource(String name, String code) { super(URI.create("string:///" + name.replace('.', '/') + ".java"), Kind.SOURCE); this.code = code; } public CharSequence getCharContent(boolean ignoreEncodingErrors) { return code; } }List<StringSource> sources = List.of(new StringSource(className1, class1CodeString), ...); task = compiler.getTask(null, fileManager, diagnostics, null, null, sources); -
如果动态地编译类,那么就无须将类文件写出到磁盘上,可以将其存储在内存,并立即加载它们。如:
public class ByteArrayClass extends SimpleJavaFileObject { private ByteArrayOutputStream out; ByteArrayClass(String name) { super(URI.create("bytes:///" + name.replace('.', '/') + ".class"), Kind.CLASS); } public byte[] getCode() { return out.toByteArray(); } public OutputStream openOutputStream() throws IOException { out = new ByteArrayOutputStream(); return out; } }List<ByteArrayClass> classes = new ArrayList<>(); StandardJavaFileManager stdFileManager = compiler.getStandardFileManager(null, null, null); JavaFileManager fileManager = new ForwardingJavaFileManager<JavaFileManager>(stdFileManager) { public JavaFileObject getJavaFileOutput(Location location, String className, Kind kind, FileObject sibling) throws IOException { if (kind == Kind.Class) { ByteArrayClass outfile = new ByteArrayClass(className); classes.add(outfile); return outfile; } else { return super.getJavaFileForOutput(location, className, kind, sibling); } } };class ByteArrayClassLoader extends ClassLoader { private Iterator<ByteArrayClass> classes; public ByteArrayClassLoader(Iterator<ByteArrayClass> classes) { this.classes = classes; } public Class<?> findClass(String name) throws ClassNotFoundException { for (ByteArrayClass cl : classes) { if (cl.getName().equals("/" + name.replace('.', '/') + ".class")) { byte[] bytes = cl.getCode(); return defineClass(name, bytes, 0, bytes.length); } } throw new ClassNotFoundException(name); } }ByteArrayClassLoader loader = new ByteArrayClassLoader(classes); Class<?> cl = Class.forName(className, true, loader);
20.3.使用注解
- 注解是那些插入到源代码中使用其他工具可以对其进行处理的标签。注解不会改变程序的编译方式。Java 编译器对于包含注解和不包含注解的代码会生成相同的虚拟机指令。为了能够收益于注解,需要选择一个处理工具,然后向处理工具可以理解的代码中插入注解,之后运用该处理工具处理代码。
- Method、Constructor、Field、Class、Package 这些类都实现了 AnnotatedElement 接口,其 getAnnotation 方法可获取注解对象,调用注解对象的相关方法可获取元素值。
- 注解可以在源码级、字节码级和运行时进行处理。
20.4.注解语法
-
所有的注解接口都隐式地扩展自 java.lang.annotation.Annotation 接口,这个是个常规接口。无法扩展注解接口,并且从来不用为注解接口提供实现类。
-
注解元素的类型为下列之一:
- 基本类型。
- String。
- Class(具有一个可选的类型参数,如
Class<? extends MyClass>)。 - enum 类型。
- 注解类型。
- 由前面所述类型组成的数组(由数组组成的数组不是合法的元素类型)。
如:
public @interface BugReport { enum Status { UNCONFIRMED, CONFIRMED, FIXED, NOTABUG } boolean showStopper() default false; String assignedTo() default "[none]"; Class<?> testCase() default Void.class; Status status() default Status.UNCONFIRMED; Reference ref() default @Reference(); String[] reportedBy(); } -
每个注解都具有以下格式:
@AnnotationName(elementName1=value1, elementName2=value2, ...)元素顺序无关紧要。
如果元素值未指定,使用默认值,默认值并不是和注解存储在一起的,它们是动态计算而来的,修改默认值之后对于已经编译的类文件也有效。
如果没有指定元素,可以不使用括号,这样的注解也被称为标记注解。
如果一个元素具有特殊名字 value,并且没有指定其他元素,那么就可忽略这个元素名以及等号。这是单值注解。
如果元素值是数组,除非数组长度为一,否则需要用大括号括起来。
因为注解是由编译器计算而来的,因此所有元素值必须是编译器常量。一个注解元素永远不能设置为 null,甚至不允许其默认值为 null。
注解元素值虽然可以是注解对象,但注解中不允许引入循环依赖。
-
注解可以出现的地方分为两类:声明和类型用法声明注解可以出现在下列声明处:
- 包。
- 类(包括 enum)。
- 接口(包括注解接口)。
- 方法。
- 构造器。
- 实例域(包含 enum 常量)。
- 局部变量。
- 参数变量。
- 类型参数。
包是在文件 package-info.java 中注解的,该文件只包含以注解先导的包语句。
对局部变量的注解只能在源码级别上进行处理,类文件并不描述局部变量。因此,所有的局部变量注解在编译完一个类的时候就会被遗弃掉。同样的,对包的注解不能在源码级别之外存在。
@NonNull 注解是 Checker Framework 的一部分,通过这个框架,可以在程序中包含断言。
-
类型用法注解可以出现在下面的位置:
- 与泛化类型参数一起使用。如
List<@NonNull String>。 - 数组中的任何位置。如
@NonNull String[][] words、String @NonNull [][] words、String[] @NonNull [] words分别表示words[i][j]、words、words[i]不为 null。 - 与超类和实现接口一起使用。如
class Warning extends @Localized Message。 - 与构造器调用一起使用。如
new @Localized String(...)。 - 与强制转型和 instanceof 检查一起使用。如
(@Localized String) text、if (text instanceof @Localized String)。(这些注解只供外部工具使用,它们对强制类型转换和 instanceof 检查不会产生任何影响。) - 与异常规约一起使用。如
public String read() throws @Localized IOException。 - 与通配符和类型边界一起使用。如
List<@Localized ? extends Message>、List<? extends @Localized Message>。 - 与方法和构造器引用一起使用。如
@Localized Message::getText。
有多种类型位置是不能被注解的。如
@NonNull String.class、import java.lang.@NonNull String;。注解可以放在其他修饰符前面和后面,习惯的做法是:类型用法注解放在其他修饰符后面,声明注解放在其他修饰符前面。
如果一个注解可以同时应用于变量和类型用法,并且它确实被应用到了某个变量声明上,那么该变量和类型用法就都被注解了。如:
public User getUser(@NonNull String userId)如果
@NonNull可以同时应用于参数和类型用法,那么 userId 参数就被注解了,而其参数类型是@NonNull String。 - 与泛化类型参数一起使用。如
-
在实例方法中注解 this,可以通过如以下方式:
public boolean equals(@ReadOnly Point this, @ReadOnly Objects other) { ... }第一个参数被称为接收器参数,它必须被命名为 this,类型为要构建的类。
只能为方法而不能为构造器提供接收器参数。
内部类构造器参数会有一个对外部类的引用,也可以让这个参数显式化。如:
public class Sequence { private int from; private int to; class Iterator implements java.util.Iterator<Integer> { private int current; public Iterator(@ReadOnly Sequence Sequence.this) { this.current = Sequence.this.from; } ... } ... }
20.5.标准注解
-
Java SE 在 java.lang、java.lang.annotation 和 javax.annotation 包中定义了大量注解。其中四个是元注解,用于描述注解接口的行为属性,
其中的三个是规则接口,可以用它们来注解源码中的项。标准注解:![]()
-
用于编译的注解:
-
@Deprecated注解可以被添加到任何不再鼓励使用的项上。该注解会一直持久化到运行时。使用一个已过时的项时,编译器会发出警告。jdeprscan 工具可以扫描 JAR 文件集中的过时元素,它是 JDK 的组成部分。
-
@SuppressWarnings注解会告知编译器阻止特定类型的警告信息。 -
@Overide只能应用到方法上。编译器会检查具有这种注解的方法是否真正覆盖了来自一个用于超类的方法,没有会报告错误。 -
@Generated注解的目的时供代码生成工具来使用的,任何生成的源代码都可以被注解,从而与程序员提供的代码分开。
-
-
用于管理资源的注解:
@PostConstruct和@PreDestroy注解用于控制对象生命周期的环境中。标记了这些注解的方法应该在对象被构造之后,或者在对象被移除之前,紧接着调用。@Resource用于资源注入。
-
元注解:
-
@Target应用于一个注解,限制该注解可以应用到哪些项上。下表中列出了所有可能取值的情况,可以指定任意数量,它们属于枚举类型 ElementType:![]()
一条没有
@Target限制的注解可以应用于任何项上。编译器将检查是否将一条注解应用到某个允许的项上,如果没有会导致一个编译器错误。
-
@Retention指定一条注解应该保留多长时间,默认值为RetentionPolicy.CLASS,可取值如下:![]()
-
@Documented为像 Javadoc 这样的归档工具提供了一些提示。如果某个注解是暂时性的,那么就不应该对它们的用法进行归档。
将一个注解应用到自身是合法的,如
@Documented。 -
@Inherited只用用于对类的注解。如果一个类具有继承注解,那么它的所有子类都自动具有同样的注解。
-
-
对于 Java SE8 来说,将同种类型的注解多次应用于某一项是合法的。为了向后兼容,可重复注解的实现者需要提供一个容器注解,它可以将这些重复注解存储到一个数组中。如:
@Repeatable(TestCases.class) @interface TestCase { String params(); String expexted(); } @interface TestCases { TestCase[] value(); }无论何时,用户提供了多个
@TestCase注解,它们就会自动地被包装到一个@TestCases注解中。如果调用 getAnnotation 来查找某个可重复注解,而这个注解确实重复了,那么会得到 null,因为重复注解被包装到了容器注解中。在这种情况下,应该调用 getAnnotationsByType,这个调用会“遍历”容器,并给出一个重复注解地数组。

20.6.源码级注解处理
-
注解地另一种用法是自动处理源代码以产生更多的源代码、配置文件、脚本或其他任何我们想要生成的东西。
-
注解处理器已经被集成到了 Java 编译器中。在编译过程中,可以通过运行下面的命令来调用注解处理器:
javac -processor ProcessorClassName1,ProcessorClassName1,... sourceFiles编译器会定位源文件中的注解。每个注解处理器会依次执行,并得到它感兴趣的注解。如果某个注解处理器创建了一个新的源文件,那么上述过程将重复执行。如果某次处理循环没有再产生任何新的源文件,那么就编译所有的源文件。
注解处理器只能产生新的源文件,无法修改已有的源文件。
注解处理器通常通过扩展 AbstractProcessor 类而实现 Process 接口,需要指定处理器支持的注解。如:
@SupportedAnnotationTypes("xyz.meyok.annotations.ToString") @SupportedSourceVersion(SourceVersion.RELEASE_11) public class ToStringAnnotationProcessor extends AbstractProcessor { @Override public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) { ... } }处理器可以声明具体的注解类型或诸如
xyz.meyok*、*这样的通配符。在每一轮中,process 方法都会被调用一次,调用时会传递给由这一轮在所有文件中发现的所有注解构成的集,以及包含了有关当前处理轮船的信息的 RoundEnvironment 引用。
-
应该使用语言模型 API 来分析源码级的注解。略。
20.7.字节码工程
第21章 Java 平台模块系统
21.1.模块的概念
- 一个 Java 平台模块包含:
- 一个包集合。
- 可选地包含资源文件和像本地库这样的其他文件。
- 一个有关模块中可访问的包的列表。
- 一个有关这个模块依赖的所有其他模块的列表。
21.2.对模块命名
- 模块是包的集合。模块中的包名无须彼此相关。模块名和包名相同时完全可行的。模块之间没有任何层次关系。
- 命名模块最简单的方式是按照模块提供的顶级包来命名。可以使用更短的模块名来命名不打算给其他程序员使用的模块。
21.3.模块化的“Hello, World!”程序
-
“不具名的”包是不能包含在模块中的。
-
让程序作为模块化应用程序来运行,需要指定模块路径,还需要以“模块名/类名”的形式指定主类。如:
java --module-path v2ch09.hellomod --module v2ch09.hellomod/xyz.meyok.hello.HelloWorld--module-path和--module可以使用-p和-m代替。运行时可能会得到警告信息,建议不要给模块名添加版本号,可使用注解抑制:
// module-info.java @SuppressWarnings("module") module v2ch09.hellomod { }注解类型必须具有值为
ElementType.MODULE的target。
21.4.对模块的需求
-
JDK 以及被模块化了,模块化的程序在需要 JDK 中内容,如 javax.swing(在 java.desktop 模块中),需要在模块中声明它依赖于对应的模块:
@SuppressWarnings("module") module v2ch09.requiremod { requires java.desktop; } -
模块不会自动地将访问权限传递给其他模块。
-
按照 Java 模块系统地用于,模块 M 会在下列情况下读入模块 N:
- M 需要 N。
- M 需要某个模块,该模块传递性地需要 N。
- N 是 M 或 java.base。
21.5.导出包
-
一个模块想要使用其他模块中的包就必须声明需要该模块,但是只有在对应模块中用 exports 声明它的哪些包可用时才能被该模块使用。
-
模块没有作用域概念,不能在不同模块中放置两个具有相同名字的包,即使时隐藏的包情况也是如此。
21.6.模块化的 JAR
-
module-info.class 在 JAR 文件的根部,这样的 JAR 文件被称为模块的 JAR。
-
如果使用像 Maven、Ant 或 Gradle 这样的构建工具,那么只需按照惯用的方式构建 JAR 文件。只要 module-info.java 包含在内,就可以得到该模块的 JAR 文件。
-
创建 JAR 文件时,可以选择指定版本号。如:
jar -c -v -f xyz.meyok.greet@1.0.jar --module-version 1.0 -C xyz.meyok.greet .可以通过反射 API 找到版本号。如:
Option<String> version = Greeter.class.getMethod().getDescriptor().rawVersion();将产生一个包含版本号字符串(如
"1.0")的 Optional。 -
等价于类加载器的模块是一个层。Java 平台模块系统会将 JDK 模块和应用程序模块加载到启动层。程序还可以使用分层 API 加载其他模块。这种程序可以选择考虑模块的版本。
21.7.模块和反射式访问
-
如果一个类在某个模块中,那么对非公有成员的反射式访问将失败。
-
通过使用 opens 关键词,模块就可以打开包,从而启动对给定包中的类的所有实例进行反射式访问。如:
module v2ch09.hellomod { requires xyz.meyok.util; opens xyz.meyok.palces; }exports 和 opens 的区别在于,exports 导出的包可以在编译和 runtime 期间访问其 public 成员。opens 声明的包,则还可以在运行期间通过反射来访问其 public 和 private 成员。
也可使用 open 关键字开放模块,开放的模块可以授权对其所有包的运行时访问,就像所有的包都用了 exports 和 opens 声明过一样。如:
open module v2ch09.hellomod { requires xyz.meyok.util; }JAR 文件除了类文件和清单外,还可以包含的文件资源,它们可以被 Class.getResourceAsStream 方法加载,在模块中,现在还可以被 Module.getResourceAsStream 加载。如果资源存储在匹配模块的某个包的目录中,那么这个包必须对调用者是开放的。在其他目录中的资源,以及类文件和清单,可以被任何人读取。
21.8.自动模块
-
Java 平台模块系统提供了两种机制来填补当今的前模块化世界与完全模块化应用程序割裂开来的鸿沟:自动化模块和不具名模块。
-
可以把任何 JAR 文件置于模块路径的目录而不是类路径的目录中,是先将其转换成一个模块。模块路径上没有 module-info.class 文件的 JAR 被称为自动模块。自动模块有以下属性:
- 模块隐式地包含对其他所有模块地 requires 子句。
- 其所有包都被导出,且是开放的。
- 如果在 JAR 文件清单 META-INF/MANIFEST.MF 中具有键为 Automatic-Module-Name 的项,那么它的值会变为模块名。否则,模块名将从 JAR 文件文件名中获得,将文件名中尾部的版本号删除,并将非字母数字的字符替换为句点。
-
自动模块使用示例:使用 commons-csv.1.5.jar 作为自动模块,利用该 JAR 进行测试(该 JAR 1.5 版本并非模块,也没有 Automatic-Module-Name,其模块名将为 commons.csv)。
各目录文件:
│ commons-csv-1.5.jar │ └─v2ch09.automod │ module-info.java │ └─xyz └─meyok └─places CSVDemo.java测试主类:
package xyz.meyok.places; import java.io.FileReader; import java.io.IOException; import org.apache.commons.csv.*; public class CSVDemo { public static void main(String[] args) throws IOException { FileReader in = new FileReader("countries.csv"); Iterable<CSVRecord> records = CSVFormat.EXCEL.withDelimiter(';').withHeader().parse(in); for (CSVRecord record : records) { String name = record.get("Name"); double area = Double.parseDouble(record.get("Area")); System.out.println(name + " has area " + area); } } }module-info.java:
@SuppressWarnings("module") module v2ch09.automod { requires commons.csv; }执行命令:
javac -p v2ch09.automod:commons-csv-1.5.jar v2ch09.automod/xyz/meyok/places/SCVDemo.java v2ch09.automod/module-info.java java -p v2ch09.automod:commons-csv-1.5.jar -m v2ch09.automod/xyz.meyok.places.SCVDemo
21.9.不具名模块
- 任何不再模块路径中的类都是不具名模块的一部分。从技术上说,可能会有多个不具名模块,但是它们合起来就像是单个不具名的模块。与自动模块一样,不具名模块可以访问所有的其他模块,它的所有包都会被导出,并且都是开放的。但是,没有任何明确模块可以访问不具名模块。
21.10.用于迁移的命令行标识
21.11.传递的需求和静态的需求
-
transitive 修饰符使得 模块的声明需要被传递。如:
module javafx.controls { requires transitive javafx.base; }任何声明需要 javafx.controls 的模块现在都自动地需要 javafx.base。
-
可用
requires transitive来聚集模块。 -
requires static声明一个模块必须在编译时出现,而在运行时是可选的。
21.12.限定导出和开放
-
exports ... to ...可以限定某些模块可以访问这个包,其他模块不想。如 javafx.base 模块含有以下语句:exports com.sun.javafx.collections to javafx.controls, javafx.graphics, javafx.fxml, javafx.swing; -
opens ... to ...可将包限定到只对某些包开放。如:opens xyz.meyok.places to xyz.meyok.util;
21.13.服务加载
-
ServiceLoader 类提供了一种轻量级机制,用于将服务接口与实现匹配起来。如,服务拥有一个接口和一个或多个可能的实现,服务消费者必须基于其认为合适的标准在提供的所有实现中选择一个。在过去,实现是通过将文本文件放置到包含实现类的 JAR 文件的 META-INF/services 目录中而提供给服务消费者的。模块系统提供了一种更好的方式,与提供文本文件不同,可以添加语句到模块描述符中。
提供服务实现的模块可以添加一条 provides 语句,他列出了服务接口(可能定义在任何模块中),以及实现类(必须是该模块的一部分)。如(xyz.meyok.greetsvc.internal 包含了实现,该服务模块只导出了 xyz.meyok.greetsvc 包,但没导出包含实现的包):
module xyz.meyok.greetsvc { exports xyz.meyok.greetsvc; provides xyz.meyok.greetsvc.GreeterService with xyz.meyok.greetsvc.internal.FrenchGreeter, xyz.meyok.greetsvc.internal.GermanGreeterFactory }这与 META-INF/services 文件等价。
使用它的消费模块包含一条 uses 语句。如 v2ch09.userservice 模块会消费该服务:
module v2ch09.useservice { requires xyz.meyok.greetsvc; uses xyz.meyok.greetsvc.GreeterService; }消费者模块中代码调用
ServiceLoader.load(ServiceInterface.class)时,所匹配的提供者类将被加载,尽管它们可能不在可访问的包中。如:package xyz.meyok.hello; import java.util.*; import xyz.meyok.greetsvc.*; public class HelloWorld { public static void main(String[] args) { ServiceLoader<GreeterService> greeterLoader = ServiceLoader.load(GreeterService.class); String desiredLanguage = args.length > 0 ? args[0] : "de"; GreeterService chosenGreeter = null; for (GreeterService greeter : greeterLoader) { if (greeter.getLocale.getLanguage().equals(desiredLanguage)) { chosenGreeter = greeter; } } if (chosenGreeter == null) { System.out.println("No suitable greeter"); } else { System.out.println(chosenGreeter.greet("Modular World")); } } }provides 和 uses 声明的效果,是使得消费该服务的模块允许访问私有实现类。
21.14.操作模块的工具
- jdeps 工具可以分析给定的 JAR 文件集之间的依赖关系。略。
第22章 安全
22.1.类加载器
-
虚拟机只加载程序所执行时所需要的类文件。例如,假设程序从 MyProgram.class 开始允许,下面是虚拟机执行的步骤:
- 虚拟机有一个用于加载类文件的机制。例如,从磁盘上读取文件或者请求 Web 上的文件,它使用该机制来加载 MyProgram 类文件中的内容。
- 如果 MyProgram 类拥有类型为另一个类的域,或者是拥有超类,那么这些类文件也会被加载。(加载某个类所以来的所有类的过程称为类的解析。)
- 接着,虚拟机执行 MyProgram 中的 main 方法(它是静态的,无须创建类的实例)。
- 如果 main 方法或者 main 调用的访问要用到更多的类,那么接下来就会加载这些类。
-
类加载机制并非只使用单个的类加载器。每个 Java 程序至少拥有三个类加载器:
- 引导类加载器。
- 平台类加载器。
- 系统类加载器(有时被称为应用类加载器)。
-
引导类加载器负责加载包含下列模块以及大量 JDK 内部模块中的平台类:
java.base、java.datatransfer、java.desktop、java.instrument、java.logging、java.management、java.management.rmi、java.naming、java.prefs、java.rmi、java.security.sasl、java.xml。
引导类加载器没有对应的 ClassLoader 对象。例如
StringBuilder.class.getClassLoader()返回 null。 -
在 Java9 之前,Java 平台类位于 rt.jar 中。如今,Java 平台是模块化的,每个平台模块都包含一个 JMOD 文件。平台类加载器都会加载引导类加载器没有加载的 Java 平台中的所有类。
-
系统类加载器会从模块路径和类路径中加载应用类。
-
类加载器有一种父/子结构。根据规定,类加载器会为它的父类加载器提供一次机会,以便加载任何给定的类,并且只有在其父类加载器加载失败时,它才会加载该给定类。
-
某些程序具有插件结构,其中代码的某些部分是作为可选的插件打包的。如果插件被打包为 JAR 文件,那就可以直接用 URLClassLoader 类的实例去加载插件类。如:
URL url = new URL("file:///path/path/to/plugin.jar"); URLClassLoader pluginLoader = new URLClassLoader(new URL[]{ url }); Class<?> cl = pluginLoader.loadClass("mypackage.MyClass");由于在 URLClassLoader 构造器中没有指定父类加载器,因此 pluginLoader 的父亲就是系统类加载器。如图展示了这种层级结构:
![]()
在 Java9 之前,系统类加载器是 URLClassLoader 类的实例。有些程序员会使用强制类型转换来访问其 getURLs 方法,或者通过反射机制调用受保护的 addURLs 方法将 JAR 文件添加到类路径中。现在无法这样操作了。
-
// TODO 类加载器倒置 -
每个线程都有一个对类加载器的引用,称为上下文类加载器。主线程的上下文加载器是系统类加载器。当新线程创建时,它的上下文类加载器会被设置为创建该线程的上下文类加载器。可以通过下面的调用将其设置为任何类加载器:
Thread t = Thread.currentThread(); t.setContextClassLoader(loader); -
在同一个虚拟机中,可以有两个类,它们的类名和包名都是相同的。类是由它的全名和类加载器来确定的。
-
编写自己的类加载器,需要继承 ClassLoader 类,覆盖 findClass 方法,实现该方法需要做到:
- 为来自本地文件系统或其他来源的类加载其字节码。
- 调用 ClassLoader 超类的 defineClass 方法,向虚拟机提供字节码。
ClassLoader 超类的 loadClass 方法用于将类的加载操作委托其父类加载器去进行,只有当该类尚未加载并且父类加载器也无法加载该类时,才会调用 findClass 方法。
-
当类加载器将新加载的 Java 平台类的字节码传递给虚拟机时,这些字节码首先要接受校验器的校验。校验器负责检查哪些指令无法执行的明显由破坏性的操作。除了系统类外,所有的类都要被检验。
以下是校验器执行的一些检查,任何一条没有通过,那么该类就被认为遭到了破坏,斌且给不予加载:
- 变量要在使用之前进行初始化。
- 方法调用与对象引用类型之间要匹配。
- 访问私有数据和方法的规则没有被违反。
- 对本地变量的访问都落在运行时堆栈内。
- 运行时堆栈没有溢出。
22.2.安全管理器与访问权限
-
一旦某个类被加载到虚拟机中,并由检验器检查过之后,Java 平台的第二种安全机制就会启动,这个机制就是安全管理器。安全管理器是一个负责控制具体操作是否允许执行的类。安全管理器负责检查的操作包括以下内容:
- 创建一个新的类加载器。
- 退出虚拟机。
- 使用反射访问另一个类的成员。
- 访问本地文件。
- 打开 socket 连接。
- 启动打印作业。
- 访问系统剪切板。
- 访问 AWT 事件队列。
- 打开一个顶层窗口。
在运行 Java 应用程序时,默认的设置是不安装安全管理器的,这样所有的操作都是允许的。
-
例如,拒绝在 Tomcat 实例中调用 System.exit(关闭 JVM)终止 Tomcat 实例。Runtime 类的 exit 方法(完整代码如下)会调用安全管理器的 checkExit 方法,如果安全管理器同意了退出请求,那么 checkExit 便直接返回并继续处理下面正常的操作,否则抛出异常。exitInternal 方法是本地私有,终止虚拟机的运行,由于是私有的,因此任何试图退出虚拟机的代码都必须通过 exit 方法,从而在不触发安全异常的情况下,通过 checkExit 安全检查。
public void exit(int status) { SecurityManager security = System.getSecurityManager(); if (security == null) { security.checkExit(status); } exitInternal(status); } -
JDK 1.0 提供了一个非常简单的安全模型:本地类拥有所有的权限,而远程类只能在沙盒里运行。JDK 1.1 进行了微小的修改,如果远程代码带有可信赖的实体签名,将被赋予和本地类相同的访问权限。但两者提供的是“要么都有,要么都没有”的权限赋予方法。
Java 1.2 开始,Java 平台拥有了更灵活的安全机制,它的安全策略建立了代码来源和访问权限集之间的映射关系,如图所示:
![]()
代码来源是由一个代码位置和一个证书集指定的,代码位置指定了代码的来源,证书的目的是要有某一方来保障代码没有被篡改过。
权限是指由安全管理器负责检查的任何属性。Java 平台支持许多访问权限类,每个类都封装了特定权限的详细信息。可以使用权限类的构造方法构造方法创造对应权限了实例,也可以从安全策略文件中读取权限。如:
var p = new FilePermission("/tmp/*", "read,write");permission java.io.FilePermission "/tmp/*", "read,write"; -
Java 1.2 中提供的权限类的层次结构:
![]()
每个类都有一个保护域,它是一个用于封装类的代码来源和权限集合的对象。当 SecurityManager 类需要检查某个权限时,它查看当前位于调用堆栈上的所有方法的类,然后它要获得所有类的保护域,并且访问每个保护域,其权限集合是否允许执行当前正在被检查的操作。所有域都同意检查得以通过,否则抛出 SecurityException 异常。通过检查整个调用堆栈,安全机制就能够确保一个类绝不会要求另一个类代表自己去执行某个敏感的操作。
-
可以将安全策略文件安装到标准位置上。默认情况下,有两个位置可以安装:Java 平台主目录的
java.policy文件、用户主目录的.java.policy文件。可以在 jdk/conf/security/java.security 配置文件中(policy.url)修改安装的位置。
策略文件中允许存放任意数量的策略 URL。
如果想将策略文件存储到文件系统之外,那么可以去实现 Policy 类的一个子类,让其去收集所允许的权限。然后在 java.security 配置文件中更改下面这行:
policy.provider=sun.security.provider.ProlicyFile测试期间通常不修改这些标准文件,更愿意为每一个应用程序单独命名策略文件,这样将权限写入一个独立的文件(如 MyApp.policy)即可。应用这个策略文件有两种选择:
-
在应用程序的 main 方法内部设置系统属性。如:
System.setProperty("java.security.policy", "MyApp.policy"); -
命令行启动虚拟机添加选项。如:
java -Djava.security.policy=MyApp.policy MyApp java -Djava.security.policy==MyApp.policy MyApp # 相比于前者,这只会使用指定的策略文件,标准策略文件将被忽略。
-
-
如前所述,默认情况下不安装安全管理器。可以通过在 main 中调用 setSecurityManager 方法,或命令行设置参数来设置。如:
System.setSecurityManager(new SecurityManager());java -Djava.security.manager -Djava.security.policy=MyApp.policy MyApp -
策略文件具有以下形式:
grant codesource { permission1; permission2; ... };-
代码来源包含一个代码基(如果某一项适用于所用来源的代码,则代码基可以省略)和指定信赖的用户特征(principal)与证书签名者的名字(如果不要求对该项签名,则可以省略)。代码基可以设定为
codeBase "url",URL 总是以“/”作为文件分隔符,即使是 Windows 中的文件 URL,如果 URL 以“/”结束,那么它是个目录,否则被视为一个 JAR 文件名字。编译 Java 代码的应用需要大量的权限,JDK9 之前可以被授权获得对 tools.jar 中代码的所有权限,但之后这个 JAR 文件不见了,因此需要想下面这样赋予对适合的模块进行访问的权限:
grant codeBase "jrt:/jdk.compiler" { permission java.security.AllPermission; }; -
权限采用
permission className targetName, actionList;结构。类名是权限类的全称类名,目标名是个与权限相关的值(如文件权限中的目录名或者文件名,或者是 socket 权限中的主机和接口),操作列表与权限相关是一个操作方式的列表(多个用逗号分隔)。有些权限类并不需要目标名和操作列表。下表列出标准的权限和它们执行的操作:![]()
![]()
![]()
这些权限类都继承自 BasicPermission 类。文件、socket 和属性权限的目标较复杂,这里单独介绍如下:
-
文件的权限目标可以有这些形式:
形式 表示内容 file 文件 directory/ 目录 directory/* 目录中的所有文件 * 当前目录中的所有文件 directory/- 目录和其子目录中的所有文件 - 当前目录和其子目录中的所有文件 <<ALL FILES>> 文件系统中的所有文件 如
permission java.io.FIlePermission "/myapp/-", "read,write,delete";。对于 Windows 需要使用\\来表示文件名中的反斜杠。 -
Socket 权限的目标由主机和端口范围组成。对主机的描述具有下面几种形式:
形式 表示内容 hostname 或 IPaddress 某个主机 localhost 或空字符串 本地主机 *.domainSuffix 以给定后缀结尾的域中所有的主机 * 所有主机 端口范围是可选的,具有下面几种形式:
形式 表示内容 :n 某个端口 :n- 编号大于等于 n 的所有端口 :-n 编号小于等于 n 的所有端口 :n1-n2 位于给定范围内的所有端口 如
permission java.net.SocketPermission "*.meyok.xyz:8000-8999", "connect";。 -
属性权限的目标可以采用下面两种形式之一:
形式 表示内容 property 一个具体的属性 propertyPrefix.* 带有给定前缀的所有属性 如
permission java.util.PropertyPermission "java.vm.*", "read";。
可以在策略文件中使用系统属性。为了创建平台无关的策略文件,应该使用 file.separator 属性而不是使用显式的
/或\\分隔符。如:permission java.io.FilePermission "${user.home}${/}-", "read,write"; -
-
-
实现自己的权限类,可以继承 Permission 类,并提供以下方法:
- 带有两个 String 参数的构造器,这两个参数分别是目标和操作列表。
String getAction()。boolean equals(Object other)。int hashCode()。boolean implies(Permission other)。
权限有一个排序,其中更加泛化的权限隐含了更加具体的权限。如果定义了自己的权限类,那么必须对权限对象定义一个适合的隐含法则,这是 implies 方法要做的事。
务必把自定义权限类设为 public。策略文件加载器不能加载具有包可视性的类,并且它会悄悄忽略其无法找到的所有类。
-
如以下程序,确保不能输入“不良单词 sex、drugs、C++”。可以使用 Permission 类中的 getName 方法获取权限的目标。
package permissions; import java.security.*; import java.util.*; public class WordCheckPermission extends Permission { private String action; public WordCheckPermission(String target, String anAction) { super(target); action = anAction; } @Override public String getActions() { return action; } @Override public boolean equals(Object other) { if (other == null) { return false; } if (!getClass().equals(other.getClass())) { return false; } var b = (WordCheckPermission) other; if (!Objects.equals(action, b.action)) { return false; } if ("insert".equals(action)) { return Objects.equals(getName(), b.getName()); } else if ("avoid".equals(action)) { return badWordSet().equals(b.badWordSet()); } else { return false; } } @Override public int hashCode() { return Objects.hash(getName(), action); } @Override public boolean implies(Permission other) { if (!(other instanceof WordCheckPermission)) { return false; } var b = (WordCheckPermission) other; if (action.equals("insert")) { return b.action.equals("insert") && getName().indexOf(b.getName()) >= 0; } else if (action.equals("avoid")) { if (b.action.equals("avoid")) { return b.badWordSet().containsAll(badWordSet()); } else if (b.action.equals("insert")) { for (String badWord : badWordSet()) { if (b.getName().indexOf(badWord) >= 0) { return false; } } return true; } else { return false; } } else { return false; } } public Set<String> badWordSet() { var set = new HashSet<String>(); set.addAll(List.of(getName().split(","))); return set; } }package permissions; import javax.swing.*; import java.awt.*; public class PermissionTest { public static void main(String[] args) { System.setProperty("java.security.policy", "permission/PermissionTest.policy"); System.setSecurityManager(new SecurityManager()); EventQueue.invokeLater(() -> { var frame = new PermissionTestFrame(); frame.setTitle("PermissionTest"); frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); frame.setVisible(true); }); } } class PermissionTestFrame extends JFrame { private JTextField textField; private WordCheckTextArea textArea; private static final int TEXT_ROWS = 20; private static final int TEXT_COLUMNS = 60; public PermissionTestFrame() { textField = new JTextField(20); var panel = new JPanel(); panel.add(textField); var openButton = new JButton("Insert"); panel.add(openButton); openButton.addActionListener(event -> insertWords(textField.getText())); add(panel, BorderLayout.NORTH); textArea = new WordCheckTextArea(); textArea.setRows(TEXT_ROWS); textArea.setColumns(TEXT_COLUMNS); add(new JScrollPane(textArea), BorderLayout.CENTER); pack(); } public void insertWords(String words) { try { textArea.append(words + "\n"); } catch (SecurityException ex) { JOptionPane.showMessageDialog(this, "I am sorry, but I cannot do that."); ex.printStackTrace(); } } } class WordCheckTextArea extends JTextArea { @Override public void append(String text) { var p = new WordCheckPermission(text, "insert"); SecurityManager manager = System.getSecurityManager(); if (manager != null) { manager.checkPermission(p); } super.append(text); } }
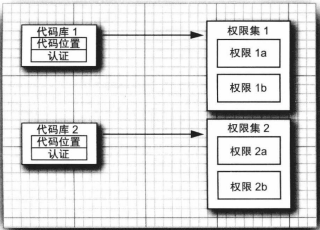
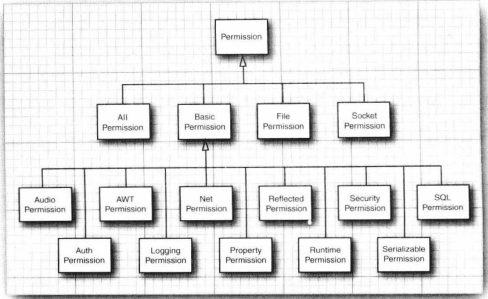
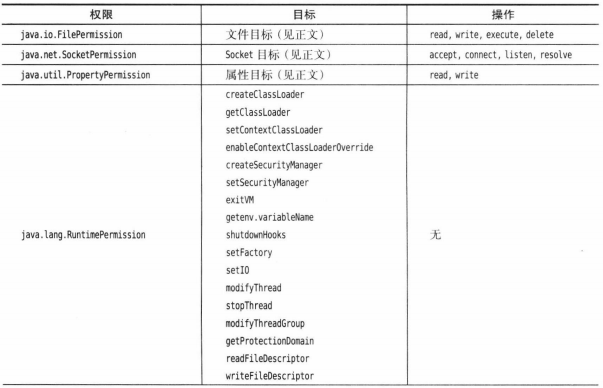
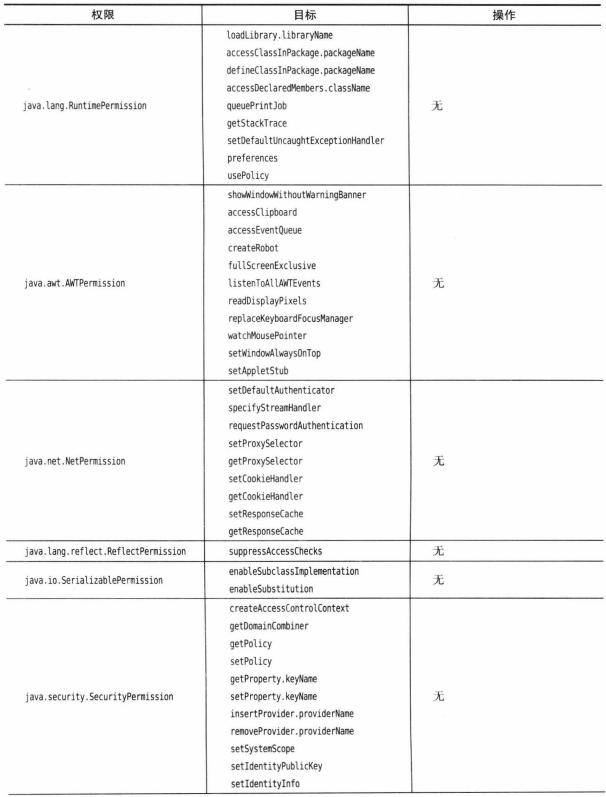
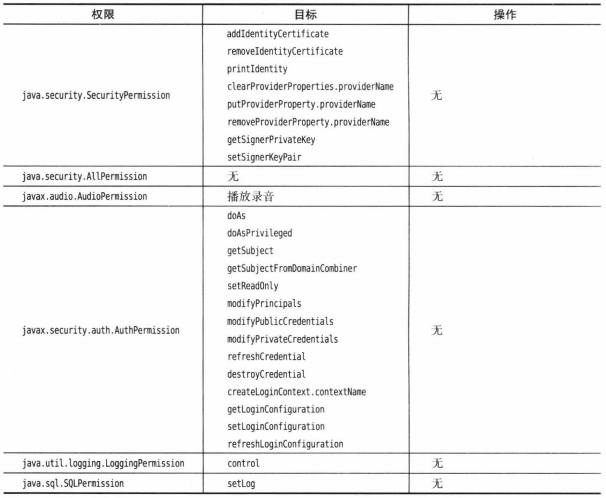
22.3.用户认证
-
Java API 提供了 JAAS(Java Authentication and Authorization)框架,它将平台提供的认证与权限管理集成起来。其包含两部分:“认证”部分主要复杂确定程序使用者的身份,而“授权”将各个用户映射到相应的权限。
-
JAAS 是一个可插拔的 API,可以将 Java 应用程序与实现认证的特定技术分离开来。除此之外,JAAS 还支持 UNIX 登录、NT 登录、Kerberos 认证和基于证书的认证。
-
一旦用户通过认证,就可以为其附加一组权限。如:
grant principal com.sun.securtiy.auth.UnixPrincipal "harry" { permission java.util.PropertyPermission "user.*", "read"; }com.sun.security.auth.UnixPrincipal 类检查运行该运行程序的 UNIX 用户名字,它的 getName 方法返回 UNIX 登录名,然后就可检查该名字是否等于”harry“。
可以使用一个 LoginContext 以使得安全管理器能够检查这样的授权语句。下面是登录代码的基本轮廓:
try { System.setSecurityManager(new SecurityManager()); var context = new LoginContext("Login1"); // defined in JAAS configuration file context.login(); // get the authenticated Subject Subject subject = context.getSubject(); ... context.logout(); } catch (LoginException exception) { // thrown if login was not successful exception.printStackTrace(); }LoginContext 构造器中的字符串参数”Login1“是指 JAAS 配置文件中具有相同名字的项。如:
Login1 { com.sun.security.auth.module.UnixLoginModule required; com.whizzbang.auth.module.RetinaScanModule sufficient; }JDK 在 com.sun.security.auth.module 包中包含这些模块:UnixLoginModule、NTLoginModule、Krb5LoginModule、JndiLoginModule、KeyStoreLoginModule。一个登录策略由一个登录模块序列组成,每个模块被标记为 required、sufficient、requisite 或 optional。
登录时要对登录的主体进行认证,该主体可以拥有多个特征。特征描述了主体的某些属性,比如用户名、组 ID 或角色等。特征管制者各个权限。com.sun.security.auth.UnixPrincipal 类描述了 UNIX 登录名,UnixNumericalGroupPrincipal 类可以用来检测用户是否属于某个 UNIX 用户组。
当用户登录后,就会在独立的访问控制上下文中,运行要求检测用户特征的代码。使用静态的 doAs 或 doAsPrivileged 方法,启动一个新的 privilegedAction,其 run 方法就会执行这段代码。doAsPrivileged 相较于 doAs 方法会开始于一个新的上下文,这允许将登录代码和”业务逻辑“的权限相分离。
如以下示例展示了限制某些用户的权限:
package auth; import javax.security.auth.Subject; import javax.security.auth.login.LoginContext; import javax.security.auth.login.LoginException; public class AuthTest { public static void main(String[] args) { System.setSecurityManager(new SecurityManager()); try { var context = new LoginContext("Login1"); context.login(); System.out.println("Authentication successful."); Subject subject = context.getSubject(); System.out.println("Subject=" + subject); SysPropAction action = new SysPropAction("user.home"); String result = Subject.doAsPrivileged(subject, action, null); System.out.println(result); context.logout(); } catch (LoginException e) { e.printStackTrace(); } } }package auth; import java.security.PrivilegedAction; public class SysPropAction implements PrivilegedAction<String> { private String propertyName; public SysPropAction(String propertyName) { this.propertyName = propertyName; } @Override public String run() { return System.getProperty(propertyName); } }auth/AuthTest.policy:
grant codebase "file:login.jar" { permission javax.security.auth.AuthPermission "createLoginContext.Login1"; permission javax.security.auth.AuthPermission "doAsPrivileged"; }; grant principal com.sun.security.auth.UnixPrincipal "harry" { permission java.util.PropertyPermission "user.*", "read"; };auth/jaas.config:
Login1 { com.sun.security.auth.module.UnixLoginModule required; };要使该例子能够运行,必须将登录类和操作类的代码封装到两个独立的 JAR 文件中:
javac auth/*.java jar cvf login.jar auth/AuthTest.class jar cvf action.jar auth/SysPropAction.classjava -classpath login.jar:action.jar \ -Djava.security.policy=auth/AuthTest.policy \ -Djava.security.auth.login.config=auth/jaas.config \ auth.AuthTest -
基于角色的认证对于大量用户的管理来说是十分必要的。
登录模块的工作之一是组装被认证的主体的特征集。如果一个登录模块支持某些角色,该模块就添加 Principal 对象来描述这些角色。
如以下示例实现:
这里自定义了 Principal,该类直接存储了一个描述值/对,如”role=admin“。
package jaas; import java.security.Principal; import java.util.Objects; public class SimplePrincipal implements Principal { private String descr; private String value; public SimplePrincipal(String descr, String value) { this.descr = descr; this.value = value; } @Override public String getName() { return descr + "=" + value; } @Override public boolean equals(Object otherObject) { if (this == otherObject) { return true; } if (otherObject == null) { return false; } if (getClass() != otherObject.getClass()) { return false; } var other = (SimplePrincipal) otherObject; return Objects.equals(getName(), other.getName()); } @Override public int hashCode() { return Objects.hashCode(getName()); } }登录模块会在包含如这种的文本文件中查找用户、密码和角色:
harry|secret|admin、carl|guessme|HR(实际上这些信息可能存储在数据库或目录中)。这里自定义了 LoginModule,其 checkLogin 方法用于检测输入的用户名和密码是否与密码文件中的用户记录相匹配,如果匹配成功,则会将添加两个 SimplePrincipal 对象到主体的特征集中。initialize 方法接受这些参数:用于认证的 subject、获取登录信息的 handler、一个 sharedState 映射表(可用于登录模块之间的通信)、一个 options 映射表(包含登录配置文件中设置的名/值对)。package jaas; import javax.security.auth.Subject; import javax.security.auth.callback.*; import javax.security.auth.login.LoginException; import javax.security.auth.spi.LoginModule; import java.io.IOException; import java.nio.charset.StandardCharsets; import java.nio.file.Paths; import java.security.Principal; import java.util.Arrays; import java.util.Map; import java.util.Scanner; import java.util.Set; public class SimpleLoginModule implements LoginModule { private Subject subject; private CallbackHandler callbackHandler; private Map<String, ?> options; @Override public void initialize(Subject subject, CallbackHandler callbackHandler, Map<String, ?> sharedState, Map<String, ?> options) { this.subject = subject; this.callbackHandler = callbackHandler; this.options = options; } @Override public boolean login() throws LoginException { if (callbackHandler == null) { throw new LoginException("no handler"); } var nameCall = new NameCallback("username: "); var passCall = new PasswordCallback("password: ", false); try { callbackHandler.handle(new Callback[] { nameCall, passCall }); } catch (UnsupportedCallbackException e) { var e2 = new LoginException("Unsupported callback"); e2.initCause(e); throw e2; } catch (IOException e) { var e2 = new LoginException("I/O exception in callback"); e2.initCause(e); throw e2; } try { return checkLogin(nameCall.getName(), passCall.getPassword()); } catch (IOException ex) { var ex2 = new LoginException(); ex2.initCause(ex); throw ex2; } } private boolean checkLogin(String username, char[] password) throws LoginException, IOException { try (var in = new Scanner(Paths.get("" + options.get("pwfile")), StandardCharsets.UTF_8)) { while (in.hasNext()) { String[] inputs = in.nextLine().split("\\|"); if (inputs[0].equals(username) && Arrays.equals(inputs[1].toCharArray(), password)) { String role = inputs[2]; Set<Principal> principals = subject.getPrincipals(); principals.add(new SimplePrincipal("username", username)); principals.add(new SimplePrincipal("role", role)); return true; } } return false; } } @Override public boolean logout() { return true; } @Override public boolean abort() { return true; } @Override public boolean commit() { return true; } }handler 是在创建 LoginContext 时指定的。如
var context = new LoginContext("Login1", new com.sun.security.auth.callback.DialogCallbackHandler());,这里使用自定义 handler.package jaas; import javax.security.auth.callback.*; public class SimpleCallbackHandler implements CallbackHandler { private String username; private char[] password; public SimpleCallbackHandler(String username, char[] password) { this.username = username; this.password = password; } @Override public void handle(Callback[] callbacks) { for (Callback callback : callbacks) { if (callback instanceof NameCallback) { ((NameCallback) callback).setName(username); } else if (callback instanceof PasswordCallback) { ((PasswordCallback) callback).setPassword(password); } } } }这里通过一个测试的实现:
package jaas; import javax.swing.*; import java.awt.*; public class JAASTest { public static void main(String[] args) { System.setSecurityManager(new SecurityManager()); EventQueue.invokeLater(() -> { var frame = new JAASFrame(); frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); frame.setTitle("JAASTest"); frame.setVisible(true); }); } } class JAASFrame implements JFrame { ... }安全策略文件 jaas/JAASTest.policy:
grant codebase "file:login.jar" { permission java.awt.AWTPermission "showWindowWithoutWarningBanner"; permission java.awt.AWTPermission "accessEventQueue"; permission javax.security.auth.AuthPermission "createLoginContext.Login1"; permission javax.security.auth.AuthPermission "doAsPrivileged"; permission javax.security.auth.AuthPermission "modifyPrincipals"; permission java.io.FilePermission "jaas/password.txt", "read"; }; grant principal jaas.SimplePrincipal "role=admin" { permission java.util.PropertyPermission "*", "read"; };jaas.config:
Login1 { jaas.SimpleLoginModule required pwfile="jaas/password.txt" debug=true; };执行:
javac *.java jar cvf login.jar JAAS*.class Simple*.class jar cvf action.jar SysPropAction.classjava -classpath login.jar:action.jar \ -Djava.security.policy=JAASTest.policy \ -Djava.security.auth.login.config=jaas.config \ JAASTest
22.4.数字签名
-
MessageDigest 类使用于创建封装了指纹算法的对象的”工厂“,它的静态方法 getInstance 返回继承了 MessageDigest 类的某个类的对象。在获取了 MessageDigest 对象后,可以通过反复调用 update 方法,将信息中的所有字节提供给该对象。如果这些字节存放在一个数组中,那就可以异常完成整个数组的更新。完成上述操作后,调用 digest 方法,该方法按照指纹算法的要求补齐输入,并且进行相应的计算,然后以字节数组的形式返回消息摘要。
如计算 SHA 指纹:
MessageDigest alg = MessageDigest.getInstance("SHA-1"); InputStream in = ...; int ch; while ((ch = in.read()) != -1) { alg.update((byte) ch); } // 或 byte[] bytes = ...; alg.update(bytes); byte[] hash = alg.digest(); -
有关消息签名等相关内容查看我的另一篇博客:网络安全。
-
JDK 配有一个命令行工具 keytool,负责管理密钥库、证书数据库和私有/公有密钥对。密钥库中的每一项都有一个”别名“。
Alice 创建一个密钥库 alice.certs 并且用别名生成一个密钥对:
keytool -genkeypair -keystore alice.certs -alias alice当新建或者打开一个密钥库时,系统将提示输入密钥库口令,最后必须设定一个密钥口令(按回车键会将密钥库口令作为密钥口令来使用),keytool 工具使用 X.500 格式的名字。
Alice 想把她的公共密钥提供给 Bob,她必须导出一个证书文件:
keytool -exportcert -keystore alice.certs -alias alice -file alice.cer这时 Alice 就可以把证书发送给 Bob,当 Bob 收到该证书时,他就可以将证书打印出来:
keytool -printcert -file alice.cerBob 想检测他是否得到了正确的证书,可以询问 Alice。
有些证书发送者将证书指纹公布到在他们的网站上。例如,要检查 jre/lib/security/cacerts 目录中的密钥库里的 DigiCert 公司的证书,可以使用 -list 选项:
keytool -list -v -keystore jre/lib/security/cacerts该密钥库的口令是 changeit。
一旦 Bob 信任该证书,他就可以将它导入密钥库中:
keytool -importcert -keystore bob.certs -alias alice -file alice.cer绝对不要将你并不完全信任的证书导入到密钥库中。一旦证书添加到密钥库中,使用密钥库的任何程序都会认为这些证书可以用来对签名进行校验。
jarsigner 工具负责对 JAR 文件进行签名和校验。
Alice 使用 jarsigner 工具将签名添加到文件中,她必须指定要使用的密钥库,JAR 文件和密钥的别名:
jarsigner -keystore alice.certs document.jar alice当 Bob 收到 JAR 文件时,他可以使用 jarsigner 程序的 -verify 选项,对文件进行校验:
jarsigner -verify -keystore bob.certs document.jarBob 不需要设定密钥别名,jarsigner 程序会在数字前面中找到密钥所有者的 X.500 名字,并在密钥库中搜寻匹配的证书。
-
以下模拟 ACME 公司某个部门作为 CA,实现 Alice 向 Cindy 发送证书。
CA 首先创建密钥库并生成密钥对、导出公共密钥:
keytool -genkeypair -keystore acmesoft.certs -alias acmeroot keytool -exportcert -keystore acmesoft.certs -alias acmeroot -file acmeroot.cerCindy 需要将 CA 公共密钥添加到自己的密钥库中:
keytool -importcert -keystore cindy.certs -alias acmeroot -file acmeroot.cer如果 Alice 要想发送消息给 Cindy,她需要将自己的公钥发送给 CA,使其颁发证书。这个功能在 keytool 中是缺失的,假如 CertificateSigner(该程序必须拥有 CA 密钥库访问权限,并且知道密钥库命令)解决了这个问题,那么:
java CertificateSigner -keystore cindy.certs -alias acmeroot -infile alice.cer -outfile alice_signedby_acmeroot.cer现在 Cindy 将证书导入到自己的密钥库中:
keytool -importcert -keystore cindy.certs -alias alice -file alice_signedby_acmeroot.cer -
大多数 CA 都运行着更加复杂的软件来管理证书,并且使用的证书格式也略有不同。
使用 OpenSSL 示例:
创建 CA,需要运行 CA 脚本(确切位置却决于 OS)。这会在当前目录创建一个 demoCA 子目录,该子目录包含一个根密钥对,并存储了证书与证书册小列表。公共密钥是 PEM(隐私增强型邮件)格式而不是密钥库更容易接受的 DER 格式。
/usr/lib/ssl/misc/CA.pl -newca将 demoCA/cacert.pem 复制为 acmeroot.pem,去除 BEGIN CERTIFICATE/END CERTIFICATE 标记之外的内容。
以通常方式将 acmeroot.pem 导入每个密钥库中:
keytool -importcert -keystore cindy.certs -alias alice -file acmeroot.pem要对 Alice 的公共密钥签名,需要生成一个证书请求,它包含这个 PEM 格式的证书:
keytool -certreq -keystore alice.store -alias alice -file alice.pem要签名这个证书,需要运行以下指令,并去除 alice_signedby_acmeroot.pem 中 BEGIN CERTIFICATE/END CERTIFICATE 标记之外的内容。
openssl ca -in alice.pem -out alice_signedby_acmeroot.pem然后,将其导入到密钥库中:
keytool -importcert -keystore cindy.certs -alias alice -file alice_signedby_acmeroot.pem -
对 JAR 文件签名,并配置 Java 以校验这种签名:
ACME 生成根证书,包含私有根密钥的密钥库必须存放在一个安全的地方,因此为公共证书建立第二个密钥库 client.certs 并将其添加进去:
keytool -genkeypair -keystore acmesoft.certs -alias acmeroot keytool -exportcert -keystore acmesoft.certs -alias acmeroot -file acmeroot.cer keytool -importcert -keystore client.certs -alias acmeroot -file acmeroot.cer为引用密钥库,策略文件必须以
keystore "keystoreURL", "keystoreType"格式开头。URL 可以是相对的(相对于策略文件)或绝对的。如果密钥库是 keytool 工具生成,则类型为 JKS。keystore "client.certs", "JKS";grant 子句可以有
signedBy, "alias"后缀,如:grant signedBy, "acmeroot" { ... };所有可以用与别名相关联的公共密钥进行校验的签名代码现在都已经在 grant 语句中被授予了权限。
22.5.加密
-
“Java 密码扩展”包含一个 Cipher 类,该类是所有加密算法的超类。
JDK 中默认由名为“SunJCE”的提供商提供密码。
调用静态方法 getInstance 可获得一个密码对象。获取密码对象后可通过其 init 方法设置模式和密钥对它初始化。模式有 ENCRYPT_MODE、DECRYPT_MODE、WRAP_MODE、UNWRAP_MODE(均为 Cipher 的静态变量),后两种模式会用一个密钥对另一个密钥进行加密。如:
Cipher cipher = Cipher.getInstance(algorithmName); int mode = ...; Key key = ...; cipher.init(mode, key);现在可以反复调用 update 方法来对数据块进行加密。如:
int blockSize = cipher.getBlockSize(); byte[] inBytes = new byte[blockSize]; ... // read inBytes int outputSize = cipher.getOutputSize(blockSize); var outBytes = new byte[outputSize]; int outLength = cipher.update(inBytes, 0, outputSize, outBytes); ... // write outBytes完成上述操作后还必须调用一次 doFinal 方法。如果还有最后一个输入数据块(其字节数小于 blockSize),那么就调用:
outBytes = cipher.doFinal(inBytes, 0, inLength);如果所有的输入数据都已经加密,则用下面的方法调用来代替:
outBytes = cipher.doFinal();doFinal 会对最后的块进行填充。可以对剩余字节用 0 填充,但解密时数据库结尾会附加若干个 0 字节,需要一个填充方案来避免这个问题,常用的是 PKCS 描述的方案,该方案会使用等于填充字节数量的值作为填充值进行填充。
AES 算法的数据块大小为 8 字节。
-
为了加密,需要生成密钥。每个密码都有不同的用于密钥的格式,我们需要确保密钥的生成是随机的。这需要遵循以下步骤:
- 为机密算法获取 KeyGenerator。
- 用随机源来初始化密钥发生器。如果密码块的长度是可变的,还需要指定期望的密码块长度。
- 调用 generateKey 方法。
如生成 AES 密钥:
KeyGenerator keygen = KeyGenerator.getInstance("AES"); SecureRandom random = new SecureRandom(); keygen.init(random); Key key = keygen.generateKey();或者可以从一组固定的原生数据(也许是由口令或者随机击键产生的)中生成一个密钥,这时可以使用如下的 SecretKeyFactory:
byte[] keyData = ...; var key = new SecretKeySpec(keyData, "AES");如果生成密钥,必须使用“真正的随机数”。Random 类是根据当前日期和时间来产生随机数的,因此它不够随机。可以使用 SecureRondom 类生成,仍需提供一个种子;另一个合理的随机输入源是在键盘上的盲打,每次敲击键盘只为随机种子提供 1 位或 2 位,一旦在字节数组中收集到这种随机位后,就可以将它传递给 setSeed 方法。如:
var secrand = new SecureRandom(); var b = new byte[20]; ... // fill with truly random bits secrand.setSeed(b);如果没有为随机数发生器提供种子,那么它将通过启动线程,使它睡眠,然后测量它们被唤醒的准确时间,一次来计算自己的 20 个字节的种子。
-
加密算法示例:
package aes; import javax.crypto.Cipher; import java.io.*; import java.security.GeneralSecurityException; public class Util { public static void crypt(InputStream in, OutputStream out, Cipher cipher) throws IOException, GeneralSecurityException { int blockSize = cipher.getBlockSize(); int outputSize = cipher.getOutputSize(blockSize); byte[] inBytes = new byte[blockSize]; byte[] outBytes = new byte[outputSize]; int inLength = 0; var done = false; while (!done) { inLength = in.read(inBytes); if (inLength == blockSize) { int outLength = cipher.update(inBytes, 0, blockSize, outBytes); out.write(outBytes, 0, outLength); } else { done = true; } } if (inLength > 0) { outBytes = cipher.doFinal(inBytes, 0, inLength); } else { outBytes = cipher.doFinal(); } out.write(outBytes); } }package aes; import javax.crypto.*; import java.io.*; import java.security.*; public class AESTest { public static void main(String[] args) throws IOException, GeneralSecurityException, ClassNotFoundException { if (args[0].equals("-genkey")) { KeyGenerator keygen = KeyGenerator.getInstance("AES"); SecureRandom random = new SecureRandom(); keygen.init(random); SecretKey key = keygen.generateKey(); try (var out = new ObjectOutputStream(new FileOutputStream(args[1]))) { out.writeObject(key); } } else { int mode = args[0].equals("-encrypt") ? Cipher.ENCRYPT_MODE : Cipher.DECRYPT_MODE; try (var keyIn = new ObjectInputStream(new FileInputStream(args[3])); var in = new FileInputStream(args[1]); var out = new FileOutputStream(args[2])) { var key = (Key) keyIn.readObject(); Cipher cipher = Cipher.getInstance("AES"); cipher.init(mode, key); Util.crypt(in, out, cipher); } } } }编译之后,可以通过以下调用:
java aes.AESTest -genkey secret.key java aes.AESTest -encrypt plaintextFile encryptedFile secret.key java aes.AESTest -decrypt encryptedFile decryptedFile secret.key -
JCE 库提供了一组使用便捷的流类,用于对流数据进行自动加密或解密。如以下是对文件数据进行加密的方法:
Cipher cipher = ...; cipher.init(Cipher.ENCRYPT_MODE, key); var out = new CipherOutputStream(new FileOutputStream(outputFileName), cipher); var bytes = new byte[BLOCKSIZE]; int inLength = getData(bytes); // get data from data source while (inLength != -1) { out.write(bytes, 0 , inLength); inLength = getData(bytes); // get more data from data source } out.flush();同样地,可以使用 CipherInputStream,对文件的数据进行读取和解密:
Cipher cipher = ...; cipher.init(Cipher.DECRYPT_MODE, key); var in = new CipherInputStream(new FileInputStream(inputFileName), cipher); var bytes = new byte[BLOCKSIZE]; int inLength = in.read(bytes); while (inLength != -1) { putData(bytes, inLength); // put data to destination inLength = in.read(bytes); }密码流类能够偷袭地调用 update 和 doFinal 方法,所以非常方便。
-
常见的公共密钥算法是 RAS 算法。使用 RAS 算法,需要 KeyPairGenerator 来获得公共/私有密钥。如:
KeyPairGenerator pairgen = KeyPairGenerator.getInstance("RSA"); var random = new SecureRandom(); pairgen.initialize(KEYSIZE, random); KeyPair keyPair = pairgen.generateKeyPair(); PublicKey publicKey = keyPair.getPublic(); PrivateKey privateKey = keyPair.getPrivate();一般会使用公共密钥对对称密钥加密:
Key key = ...; // an AES key key publicKey = ...; // a public RSA key Cipher cipher = Cipher.getInstance("RSA"); cipher.init(Cipher.WRAP_MODE, publicKey); byte[] wrappedKey = cipher.wrap(key);
第23章 高级 Swing 和图形化编程
第24章 本地方法
-
建议只有在必需的时候才使用本地代码。特别是以下三种情况:
- 应用需要访问的系统特性和设备通过 Java 平台无法实现。
- 已经有了大量的测试过和调试过的用另一种语言编写的代码,并且知道如何将其导入到所有的目标平台上。
- 通过基准测试,发现所编写的 Java 代码比所用其他语言编写的等价代码要慢得多。
-
Java 平台有一个用于和本地 C 代码进行互操作的 API,称为 JNI(Java 本地接口)。这里讨论 JNI。
JNI 并不支持 Java 类和 C++ 类之间的任何映射机制。可以在 C++ 中使用
extren "C"来修改语言链接性。
24.1.从 Java 程序中调用 C 函数
-
对本地代码处理流程:
![]()
- 在 Java 类中声明一个本地方法。
- 运行 javah 以获得包含该方法的 C 声明的头文件。
- 用 C 实现该本地方法。
- 将代码置于共享类库中。
- 在 Java 程序中加载该类库。
如一个本地方法实现打印
"Hello, Native World!"字符串示例:-
声明包含本地方法的 Java 类:
public class HelloNative { public static native void greeting(); } -
生成头文件:
-h指定头文件的放置目录。javac -h . HelloNative.java这个示例会生成如头文件:
/* DO NOT EDIT THIS FILE - it is machine generated */ #include <jni.h> /* Header for class HelloNative */ #ifndef _Included_HelloNative #define _Included_HelloNative #ifdef __cplusplus extern "C" { #endif /* * Class: HelloNative * Method: greeting * Signature: ()V */ JNIEXPORT void JNICALL Java_HelloNative_greeting (JNIEnv *, jclass); #ifdef __cplusplus } #endif #endif -
实现函数:
#include "HelloNative.h" #include <stdio.h> JNIEXPORT void JNICALL Java_HelloNative_greeting(JNIEnv * env, jclass cl) { printf("Hello Native World!\n"); }如果使用 C++,则:
#include "HelloNative.h" #include <iostream> extern "C" JNIEXPORT void JNICALL Java_HelloNative_greeting(JNIEnv *, jclass) { std::cout << "Hello, Native World!" << std::endl; } -
将本地 C 代码编译到一个动态装载库中,具体方法依赖于编译器。
如 Linux 下的 Gnu C 编译器:
gcc -fPIC -I jdk/include -I jdk/include/linux -shared -o libHelloNative.so HelloNative.c又如 Windows 下的微软编译器:
cl -I jdk\include -I jdk\include\win32 -LD HelloNative.c -FeHelloNative.dll -
最后,需要在程序中添加一个对 System.loadLibray 方法的调用:
public class HelloNativeTest { public static void main(String[] args) { HelloNative.greeting(); } static { System.loadLibrary("HelloNative"); } }
一些本地代码的共享库必须先运行初始化代码。可以把初始化代码放到 JNI_OnLoad 方法中。类似地秒如果提供该方法,当虚拟机关闭时,将会调用 JNI_OnUnload 方法。它们的原型是:
jint JNI_OnLoad(JavaVM* vm, void* reserved); void JNI_OnUnload(JavaVM* vm, void* reserved);JNI_OnLoad 返回它所需的虚拟机最低版本,如 JNI_VERSION_1_2。
24.2.数值参数与返回值
-
Java 数据类型和 C 数据类型的对应关系:
![]()
这些在 jni.h 中使用 typedef 定义,还定义了常量 JNI_FALSE = 0 和 JNI_TRUE = 1。

24.3.字符串参数
-
JNI 有两种操作字符串的函数,一组把 Java 字符串转换成“modified UTF-8”字节序列,另一组将它们转换成 UTF-16 数值的数值,也就是说转换成 jchar 数组。如果 C 代码已经使用了 Unicode,那么可以使用第二组转换函数;如果字符串仅限于使用 ASCII 字符,那么就可以使用“modified UTF-8”转换函数。
-
带有字符串参数的本地方法实际上都需要接受一个 jstring 类型的值,而带有字符串参数返回值的本地方法必须返回一个 jstring 类型的值。
-
所有对 JNI 函数的调用都使用到了 env 指针,该指针是每一个本地方法的第一个参数。env 指针是指向函数指针表的指针。
![]()
-
JNI 的字符串相关函数:
-
NewStringUTF 函数会从包含 ASCII 字符的字符数组,或者是更一般的“modified UTF-8”编码的字节序列中,创建一个新的 jstring 对象。如:
JNIEXPORT jstring JNICALL Java_HelloNative_getGreeting(JNIEnv* env, jclass cl) { jstring jstr; char greeting[] = "Hello, Native World\n"; jstr = (*env) -> NewStringUTF(env, greeting); return jstr; }C++ 中对 JNI 函数访问要简单写。JNIEnv 类的 C++ 版本有一个内联成员函数,它负责帮助查找函数指针。如这样调用 NewStringUTF 函数:
jstr = env -> NewStringUTF(greeting); -
GetSTringUTFChars 函数读取现有 jstring 对象的内容。该函数返回指向描述字符串的“modified UTF-8”字符的 const jbyte* 指针。
-
虚拟机必须知道我们何时使用完字符串,这样它就进行垃圾回收。基于这个原因,我们必须调用 ReleaseStringUTFChars 函数。
-
调用 GetStringRegion 或 GetStringUTFRegion 方法提供自己的缓存,以存放字符串的字符。
-
GetStringUTFLength 函数返回字符串的“modified UTF-8”编码所需的字符个数。
-
24.4.访问域
-
对于使用对象方法访问对象域,与之前的静态方法不同,这里的函数原型第二个参数为 jobject 而不是 jclass。
-
JNI 会要求程序员使用特殊的 JNI 函数来获取和设置数据的值,其通用语法为:
x = (*env) -> GetXxxField(env, this_obj, fieldID); (*env) -> SetXxxField(env, this_obj, fieldID, x);Xxx 代表 Java 数据类型(Object、Boolean、Byte 或其他)。
-
GetFieldID 函数获取 fieldID,必须提供域的名字、它的签名以及它的类型编码。
-
两种方法获取一个类引用。
- GetObjectClass 函数返回任意对象的类。
- FindClass 函数可以以字符串形式来指定类名。
类引用只在本地方法返回之前有效。因此,不能在代码中缓存 GetObjectClass 的返回值。否则必须使用 NewGlobalRef 来锁定该引用,结束对类的使用时调用 DeleteGlobalRef 方法。如:
static jclass class_X = 0; static jfieldID id_a; ... if (class_X = 0) { jclass cx = (*env) -> GetObjectClass(env, obj); class_X = (*env) -> NewGlobalRef(env, cx); id_a = (*env) -> GetFieldID(env, cls, "a", "..."); }(*env) -> DeleteGlobalRef(env, class_X); -
使用本地方法实现以下 Java 方法示例,其中 salary 是实例字段:
public void raiseSalary(double byPercent) { salary *= 1 + byPercent / 100; }JNIEXPORT void JNICALL Java_Employee_raiseSalay(JNIEnv* env, jobject this_obj, jdouble byPercent) { jclass class_Employee = (*env) -> GetObjectClass(env, this_obj); jfieldId id_salary = (*env) -> GetFieldID(env, class_Employee, "salary", "D"); jdouble salary = (*env) -> GetDoubleField(env, this_obj, id_salary); salary *= 1 + byPercent / 100; (*env) -> setDoubleField(env, this_obj, id_salary, salary); } -
访问静态域与访问非静态域类似,要使用 GetStaticFieldID 和 GetStaticXxxField/SetStaticXxxField 函数。只是由于没有对象,所以必须使用 FindClass 而不是 GetObjectClass;访问域时,要提供类而非实例对象。如
jclass class_System = (*env) -> FindClass(env, "java/lang/System"); jfieldId id_out = (*env) -> GetStaticFiledID(env, class_System, "out", "Ljava/io/PrintStream;"); jobject obj_out = (*env) -> GetStaticObjectField(env, class_System, id_out);
24.5.编码签名
-
数据类型的编码:
编码 Java 类型 B byte S short I int J long D double F float C char Z boolean Lclassname; 类的类型(分隔符是 /而不是.)V void 对于数组,要使用
[。如字符串数组[Ljava/lang/String;,float[][]数组为[[F。对于方法的签名,需要用括号把参数类型列出来,其后跟返回值。如
(II)I、(Ljava/lang/String;DLjava/util/Date;)V。可以使用带
-s的选项的 javap 命令来从类文件中产生方法签名。如:javap -s -private Employee
24.6.调用 Java 方法
-
使用如下的 CallXxxMethod 方法来实现本地方法的 C 函数中调用 Java 的实例方法:
(*env) -> CallXxxMethod(env, implicit parameter, methodID, explicit parameters);Xxx 为方法的返回类型(如 Void、Int、Object)。
可以调用 getMethodID 来获取方法的 methodID,需要提供该类、方法的名字和方法签名。
数值型的方法 ID 和域 ID 在概念上和反射 API 中的 Method 和 Field 对象相似。可以使用以下函数在两者之间进行转换:
jobject ToReflectedMethod(JNIEnv* env, jclass class, jmethodID methodID); methodID FromReflectedMethod(JNIEnv* env, jobject method); jobject ToReflectedField(JNIEnv* env, jclass class, jfieldID fieldID); fieldID fromReflectedField(JNIEnv* env, jobject field); -
实现以下 Java 方法的本地方法,其中需要调用 PrintWriter 的实例方法 print:
public native static void fprintf(PrintWriter out, String s, double x);class_PrintWriter = (*env) -> GetObjectClass(env, out); id_print = (*env) -> getmethodID(env, class_PrintWriter, "print", "(Ljava/lang/String;)V"); (*env) -> CallVoidMethod(env, out, id_print, str); -
从本地方法调用静态方法与调用非静态方法类似。只不过使用 GetStaticMethodID、CallStaticMethod 函数;当调用方法时,要提供类对象而不是隐式的参数对象。
如从本地方法调用
System.getProperty("java.class.path")静态方法:jclass class_System = (*env) -> FindClass(env, "java/lang/System"); jmethodId id_getProperty = (*env) -> GetStaticMethodID(env, class_System, "getProperty", "(Ljava/lang/String;)Ljava/lang/String;"); jobject obj_ret = (*env) -> CallStaticObjectMethod(env, class_Sytem, id_getProperty, (*env) -> NewStringUTF(env, "java.class.path"));方法的返回类型为 jobject,如果要把它当作字符串操作,C 中可以直接操作,C++ 中必须强制类型转换为 jstring。
-
调用构造器可使用 NewObject 函数,可以指定方法名为
"<int>"。如本地方法创建 FileOutputStream 对象示例:const char[] fileName = "..."; jstring str_fileName = (*env) -> NewStringUTF(env, fileName); jclass class_FileOutputStream = (*env) -> FindClass(env, "java/io/FileOutputStream"); jmethodId id_FileOutputStream = (*env) -> GetMethodID(env, class_FileOutputStream, "<init>", "(Ljava/lang/String;)V"); jobject obj_stream = (*env) -> NewObject(env, class_FileOutputStream, id_FileOutputStream, str_fileName); -
有若干种 JNI 函数的变体都可以从本地方法调用 java 方法。
CallNonvirtualXxxMethod 函数接受一个隐式参数、一个方法 ID、一个类对象(必须对应于隐式参数的超类)和一个显式参数。这个函数将调用指定类种的指定版本的方法,而不使用常规的动态调度机制。
所有调用函数都有后缀“A”和“V”的版本,用于接受数值中或 va_list 中的显式参数(就像在 C 头文件 stdarg.h 所定义的那样)。
24.7.访问数组元素
-
Java 的所有数组类型都有相对应的 C 语言类型:
![]()
C 中这些数组类型实际上都是 jobject 的同义类型,C++ 中被安排在继承层次结构中(jarray 类型表示一个泛型数组):
![]()
-
GetArrayLength 函数返回数组长度。
-
怎样访问数组元素取决于存储的是对象还是基本类型。
-
可以通过 GetObjectArrayElement、SetObjectArrayElement 方法访问对象数组的元素。如:
jobjectArray array = ...; int i, j; jobject x = (*env) -> GetObjectArrayElement(env, array, i); (*env) -> SetObjectArrayElement(env, array, j, x); -
对于基本类型数组,使用 GetXxxArrayElements 函数返回一个指向数组起始元素的 C 指针,不需要该指针时需要调用 ReleaseXxxArrayElements 函数通知虚拟机。这里的 Xxx 是基本类型。
虚拟机是否确实需要对数组进行拷贝取决于它是如何分配数组和如何进行垃圾回收的。
由于指针可能会指向一个副本,只有调用了 ReleaseXxxArrayElements 所做的改变才能保证在源数组中得到反映。
通过把一个指向 jboolean 变量的指针作为第三个参数传递给 GetXxxArrayElements 就可发现是否是副本(是的话则为 JNI_TRUE)。对这个信息不感兴趣可传递一个空指针。
-
-
访问一个大数组的多个元素,可以用 GetXxxArrayRegion、SetXxxArrayRegion 方法,它能把一定范围内的元素从 Java 数组复制到 C 数组中或从 C 数组赋值到 Java 数组中。
-
可以用 NewXxxArray 函数在本地方法中创建新的 Java 数组。需要指定长度、数组元素的类型和所有元素的初始值。如:
jclass class_Employee = (*env) -> FindClass(env, "Employee"); jobjectArray array_e = (*env) -> NewObjectArray(env, 100, class_Employee, NULL);基本类型的数组只需提供数组长度。如:
jdoubleArray array_d = (*env) -> NewDoubleArray(env, 100); -
下面的方法用来操作“直接缓存”:
jobject NewDirectByteBuffer(JNIEnv* env, void* address, jlong capacity); void* GetDirectBufferAddress(JNIEnv* env, jobject buf); jlong GetDirectBufferCapacity(JNIEnv* env, jobejct buf);java.nio 包中使用了直接缓存来支持更高效的输入输出操作,并尽可能减少本地和 Java 数组之间的复制操作。
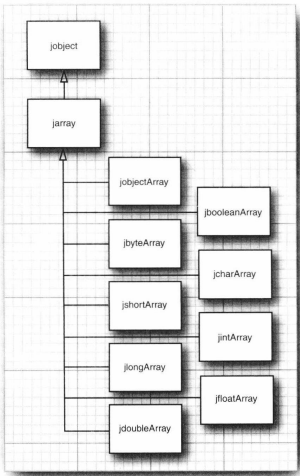
24.8.错误处理
-
C 语言没有异常,必须调用 Throw 和 ThrowNew 函数来创建一个新的异常对象。当本地方法退出时,Java 虚拟机就会抛出异常。
-
使用 Throw 函数,需要调用 NewObject 创建一个 Trowable 子类的对象。如抛出一个 EOFException 对象实例:
jclass class_EOFException = (*env) -> FindClass(env, "java/io/EOFException"); jmethodID id_EOFException = (*env) -> GetMethodID(env, class_EOFException, "<init>", "()V"); jthrowable obj_exc = (*env) -> NewObject(env, class_EOFException, id_EOFException); (*env) -> Throw(env, obj_exc); -
通常调用 ThrowNew 会更加方便,只需提供一个类和一个“modified UTF-8”字节序列,该函数就会创建一个异常对象。如:
(*env) -> ThrowNew(env, (*env) -> FindClass(env, "java/io/EOFException"), "Unexpected end of file"); -
Throw 和 ThrowNew 不会中断本地方法的控制流,只有当该方法返回时,JVM 才会抛出异常。所以 Throw 和 ThrowNew 通常紧跟 return 语句。
-
C++ 实现本地方法无法抛出 Java 异常。
-
ExceptionOcurred 方法在有异常时返回异常对象引用,否则返回 NULL。
只检测是否有异常抛出则调用 ExceptionCheck 方法。
ExceptionClear 方法清除异常。
三者都只以 env 作为参数调用。
24.9.使用调用 API
-
invocation API(调用 API)使我们能够把 JVM 嵌入到 C 或 C++ 程序中。下面是初始化虚拟机所需的基本代码:
JavaVMOption options[1]; JavaVmInitArgs vm_args; JavaVM* jvm; JNIEnv* env; options[0].optionString = "-Djava.class.path=."; memset(&vm_args, 0, sizeof(vm_args)); vm_args.version = JNI_VERSION_1_2; vm_args.noptions= 1; vm_args.options = options; JNI_createJavaVM(&jvm, (void**) &env, &vm_args);提供任意数目的选项,只需增加选项数组的大小和 vm_args.nOptions 的值。
对 JNI_createJavaVM 的调用将创建 JVM,并且使 jvm 指向 JVM,env 指向执行环境。
当陷入麻烦导致程序崩溃,从而不能初始化 JVM 或者不能装载类时,请打开 JNI 调试模式。设置一个选项如下:
options[i].optionString = "-verbose:jni";这会看到一系列说明 JVM 初始化进程的消息。如果看不到装载的类,请检查路径和类路径的设置。
-
只有在调用 API 中的其他函数时,才需要 jvm 指针。目前这样的函数有 4 个。其中以下调用终止虚拟机:
(*jvm) -> DestoryJavaVM(jvm);
24.10.完整的示例:访问 Windows 注册表
- Windows 注册表是一个存放 Windows 操作系统的应用程序的配置信息的数据仓库。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号