论文笔记 - Coresets for Data-efficient Training of Machine Learning Models
Motivation
- 训练深度网络存在的问题:需要大量训练数据,进而需要更强的计算资源等。因此如何在减少这些开销(例如使用更小的数据集)的同时,不影响模型的性能成为了一个至关重要的问题;
- 挑选 coreset 的四大挑战:
- 选取 sample 的规则尚不明确;
- 检索的速度要快,否则就失去了加速训练的意义;
- 光找出 coreset 仍不够,还要为 coreset 中的每个 datapoint 决定他们各自的学习率;
- 即使某个策略在一些数据集上起作用了,也要用数学的方法进行分析(为什么有用)。
Analysis
目标:找出完整数据集 $V$ 的一个子集 $S^{*}$,使得:
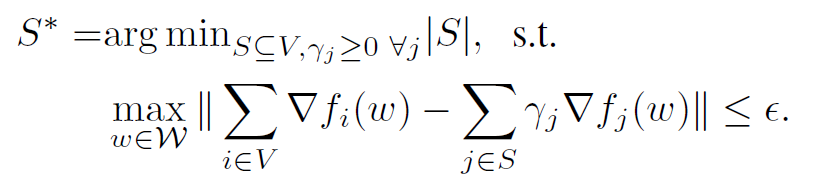
其中 w 是模型权重参数,W 是 w 所有可能取值的区域, $\beta$ 是权重,对于 Coreset 中的每个样本有不同的权重(代表重要程度),使用 Coreset 进行训练时,学习率可以根据权重调整。
上图中的范数部分成为估计误差(即挑选子集的梯度和全数据集梯度的差距)。
直接用此式是不可行的,因为需要计算每个可能的 w,而 W 一般是连续的。
两步转化,获得估计误差的上界(针对一个特定的 w):
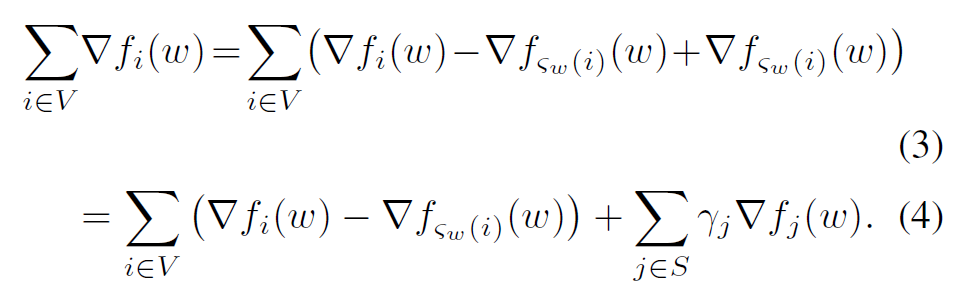
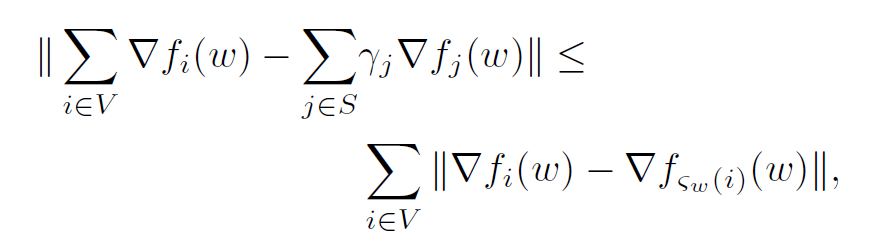
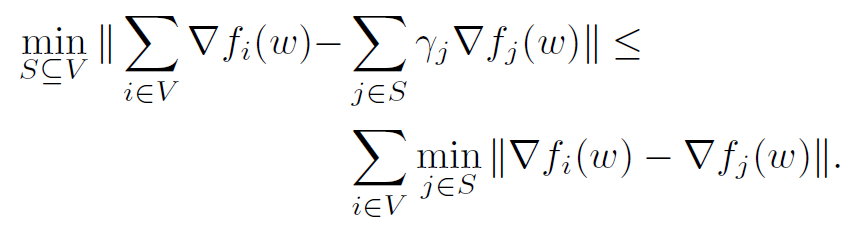
因此问题变成了,找出完整数据集 $V$ 的一个 $S^{*}$,使得(为了解决 w 连续的问题,约定 $d_{ij}$ 为最大误差时的 w,也就是相当于又取了一次上界):
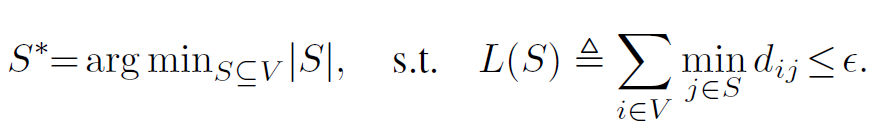
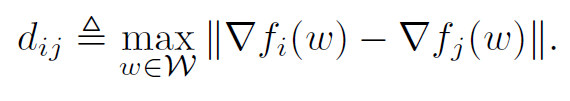
解决这个问题是 NP-hard 的,因为必须计算每一种可能的 S 组合,因此可以用次模函数,利用贪心算法得到一个近似的解:
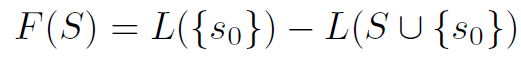
问题变成了:
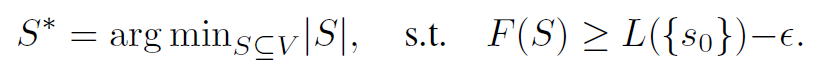


 浙公网安备 33010602011771号
浙公网安备 33010602011771号