


以Mysql为代表的传统关系型数据库为例,开发中遵循范式化设计,设计E-R一切围绕关系,不同类型的数据会使用不同的表,通过数据库主键或业务主键关联,比如在用户管理业务中,用户-地址-通讯信息会使用3张表存储。
这种范式化设计的优点在于容易维持数据的一致性,减少数据的冗余,从数据角度看是一种比较完美的形式。
但存在以下问题
1.业务实际需要的是什么数据
业务代码中更多时候需要的是用户信息+用户地址信息+用户通讯方式的组合,从业务系统视角如下。
| userId | userName | address | tel |
| 1 | zhangsan | 上海市浦东新区 | 12345678 |
以Mysql为例,查询索引+查询行,获得一份业务需要的数据需要2次IO,分别存储于3张表,共计2 * 3 = 6次IO。如果查询的数据是10条,100条会带来大量IO开销。
对于MongoDB来说如果聚合在一个文档内,只需要两次IO开销,索引和查询。
2.数据使用
另外实际场景中,70%的查询仅访问一条数据,20%查询是同一个表中的多行数据,只有10%查询是多表关联查询,但却依赖50%基础支撑,这会带来大量资源浪费。
3.可扩展性
常见的方案是分库分表,比如这里可以根据userId或用户ip按照一定规则把一批数据存在一台服务器内,以保证可以继续使用join查询。但这样会侵入业务逻辑,虽然可以依赖分库分表中间件单也会带来额外复杂度。
对于MongoDB来说,一个分布式表的分片在逻辑上为一个整体,使用中无需关心数据存储在哪个服务器上。
MongoDB使用去范式化设计,是一种NoSql数据库,以对象的方式组织数据,把数据按照对象的方式组织在一起,牺牲数据的完美型,可能存在冗余,可能存在不一致,换来三个优点
1.是降低应用的复杂度,更易于使用
2.节省磁盘IO
3.更易于完成分布式存储,水平扩容。
MongoDB数据模型设计上总体有以下两个原则
1)原则上一起使用的数据,就应该一起存储。
2)不在一起使用的数据,不应该一起存储。
第二点需要从MongoDB读数据和写数据的过程解释下,
先说读数据,假设db.test.find({},{a:1,b:1,c:1}),假设这个文档还有d字段,并且存储数据长度较长,查询引擎依然会将d字段全部读取,并将数据裁切返回a,b,c三个字段。
区别于关系型数据库可以只读出a,b,c三个字段,MongoDB之所以全部读出来,是因采用动态数据模型,不会定义有哪些列。由于没有元数据支持,只有读取阶段才能知道文档有哪些字段,所以必须经过一个数据裁切过程。简而言之,这个过程就是将这条文档数据全部读出,之后过滤出需要的列。从这个角度上说,MongoDB会将整条文档全部读出,为了避免额外性能消耗,不在一起使用的数据,不应该一起存储。
再说写数据,db.test.update({_id:1},{$set:{a:1}}); 对于该条更新操作,MongoDB会以如下方式进行。
V2在缓存内存储的是V1的增量,这样可以节省内存空间,但是写入磁盘前会按V1 + V2 + ... + Vn的顺序计算最终结果,然后写入磁盘。
虽然修改的是a字段,但写入的是整个文档。
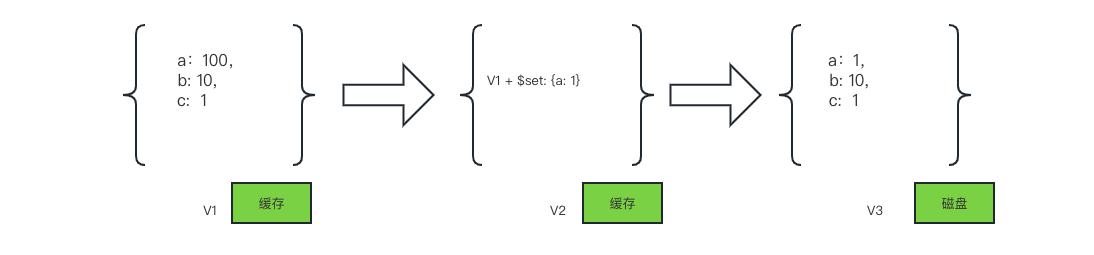
综上所述,一个文档会被作为一个整体被读或者被写。
