

没压岁钱了(一)- 浅谈事务隔离级别
最近在读《高性能MySQL》,这里和大家分享一些个人觉得比较重要且随着时间的流逝,老手们也可能生疏的知识点,希望和大家多多交流,阅读所需时间少于10分钟。
:)
隔离级别
隔离性其实比想象的要复杂。在SQL标准定义了四种隔离级别,每种级别多规定了一个事务中所做的修改哪些在事务内和事务间是可见的,哪些是不可见的。低级别的隔离通常可以执行高并发,系统开销更低。
下面介绍下四种隔离级别:
- READ UNCOMMITTED(未提交读)
- 事务中的修改,即使没有提交,对其它事务也都是可见的。事务可以读取未提交的数据,也被称之为脏读(Dirty Read)。从性能角度来讲,READ UNCOMMITED不会比其他级别好太多,但是缺乏其他级别的很多好处,一般很少使用。正所谓鱼与熊掌不可兼得,但可兼失。
- READ COMMITTED(提交读)
- 大多数数据库系统的默认隔离级别都是READ COMMITTED,虽然MySQL不是lol。在READ COMMITTED中,一个事务开始时,只能访问已经提交的事务所做的修改。这个级别有时也被称之为不可重复读(Non-Repeatable Read),因为两次执行同样的查询,可能会得到不一样的结果。举个🌰:事务T1读取了某一数据a = 2333,事务T2读取并将数据修改为a = 9527,T1再次读取该数据时便得到了不同的结果。
- REPEATABLE READ(可重复读)
- REPEATABLE READ解决了脏读的问题。该级别保证了在同一事务中多次读取同样的记录,结果是一致的。但是理论上,可重复读这一隔离级别仍然无法解决 幻读(Phantom Read)的问题。幻读是指当事务T1在读取某个范围内的记录时,另外一个事务T2又在该范围内插入了新的记录,当T1再次读取该范围的记录时,会产生幻读。
- 可重复读是MySQL的默认事务隔离级别
- SERIALIZABLE(可串行化)
- SERIALIZABLE是最高的隔离级别。它通过强制事务串行执行,避免了前面说的幻读。简单来说,SERIALIZABLE会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用的问题。实际应用中也很少会用到。
只看结果来说,似乎不可重复读和幻读表现都为两次读取的结果不一致,但是细细一品,区别还是比较大的。
不可重复读和幻读的区别
如果使用锁机制实现这两种隔离级别,那么在可重复读中,事务T1第一次读到数据后,就将这些数据加锁,不会导致其他事务修改这些数据,即可实现可重复读。但是这种方法无法锁住insert操作。也就是说:当事务T1读取了数据d1,或者修改了数据d1,事务T2还是可以insert数据,这时事务T1如果计算数据总数,就会懵逼的发现数据多了一条,这就是幻读。
这里引用一下Wikipedia的话:
A non-repetable read occurs, when during the course of a transaction, a row is retrieved twice and the values within the row differ between reads.
A phantom read occurs when, in the course of a transaction, two identical queries are excuted, and the collection of rows returned by the second query is different from the first.
画个图比较形象:
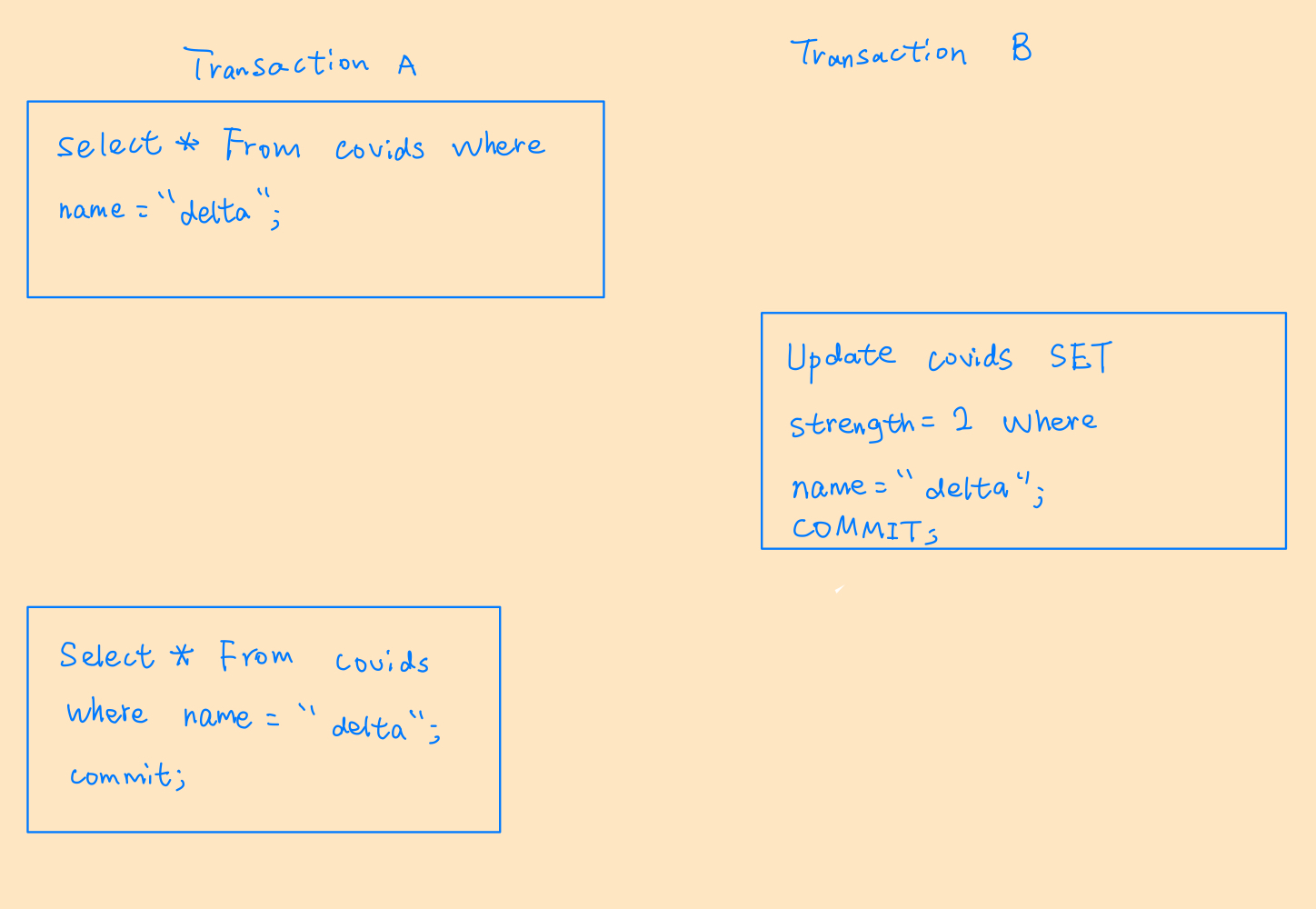
1. 不可重复读(Non-repetable Read)
初始化Covids表:
| name | strength |
| delta | 1 |
该例中事务B已经提交成功,意味着事务B做的改动应该是可见的。然而事务A读取的两次值中,strength是不同的。
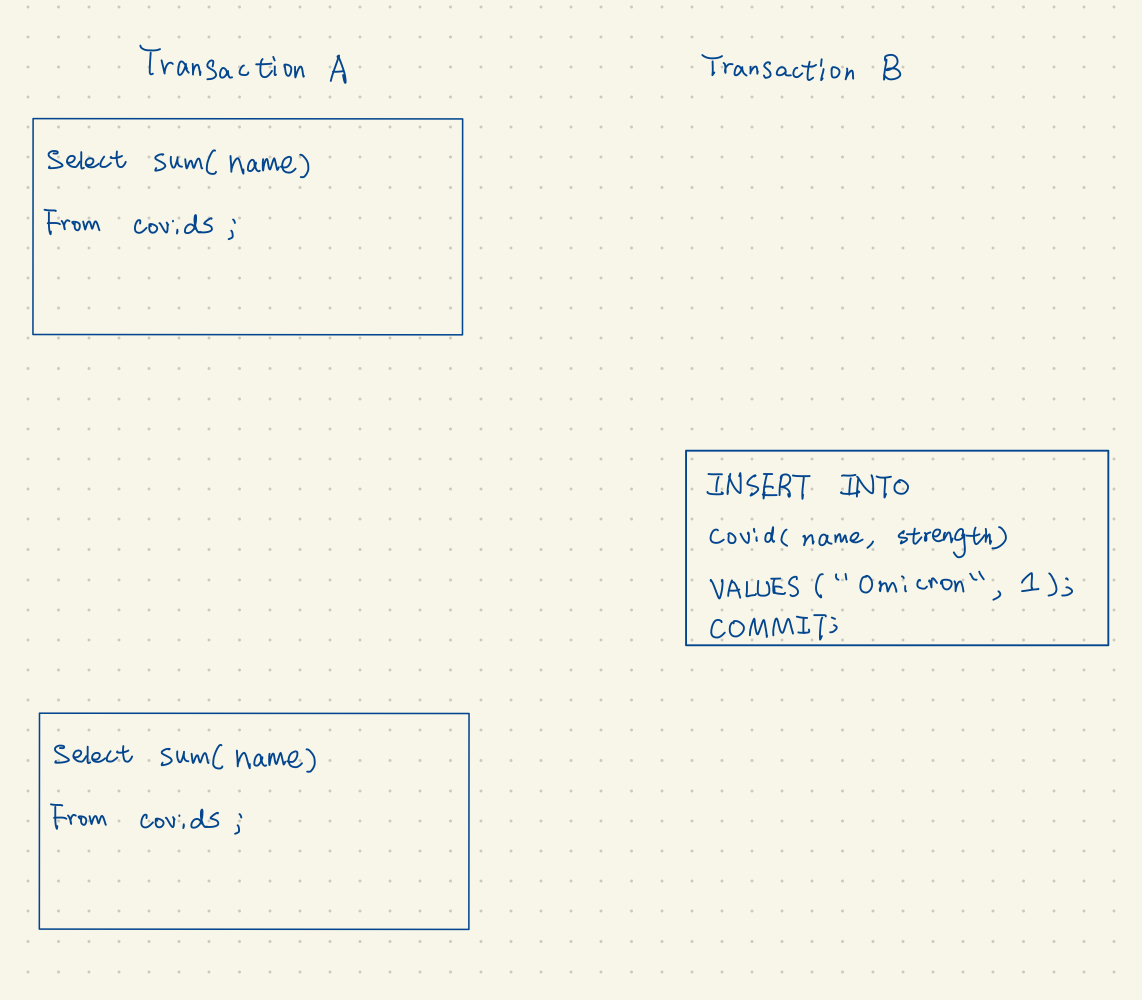
2. 幻读(Phantom Read)
如果我们使用的是SERIALIZABLE隔离级别,那么两次SELECT将会获得相同的数据。但是,如果只是Repeatable Read级别的话,第一次读数据将获得1, 第二次读将获得2。
知道了问题所在,那么怎么去解决他们呢?
找到解决方法前,先引入三个锁的概念:
-
Record Lock:
A record lock is a lock on an index record. For example,
SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE;prevents any other transaction from inserting, updating, or deleting rows where the value oft.c1is10.简而言之,就是事务T1读数据时,防止其他事务(如事务T2)针对这一行数据做出改动。
-
Gap Lock:
A gap lock is a lock on a gap between index records, or a lock on the gap before the first or after the last index record. For example,
SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE;prevents other transactions from inserting a value of15into columnt.c1, whether or not there was already any such value in the column, because the gaps between all existing values in the range are locked.举个例子,就是事务T1读一个range的数据(比如(10, 15])时,其他事务不能插入10、16这样的值。
-
Next-key Lock:
A next-key lock is a combination of a record lock on the index record and a gap lock on the gap before the index record.
简单来说,Next-key lock就是record lock和gap lock的结合体。
Innodb 在查询或者扫描表索引时使用行级锁,设置共享锁或者排他锁。因此行级锁实际上是index-record lock。next-key会影响该index record之前的gap,也就是说,next-key lock在这个index record与两边的index record之前的gap加一个锁,这样一操作,其他事务就不能在这个间隙修改或者插入记录。
再举个🌰:假设一个索引包含10,11,13,20这四个值,next-key locks可以锁住这些间隔:
- (negative infinity, 10]
- (10, 11]
- (11, 13]
- (13, 20]
- (20, positive infinity] (负无穷和正无穷只是看上去唬人,实际情况下并不指代真实的index record,而是整个索引两边的索引值)
有了gap lock的加持,可以保证在事务在执行期间不会被插入数据。
根据上述的三种锁,这里简单说一下我的思路:
解决不可重复读:使用record lock对当前执行操作的row加锁,防止其他事务对该行进行操作,解决不可重复读的问题。
解决幻读:使用next-key lock,分别对当前执行操作的row以及两边的gap进行加锁,这样就可以防止其他事务对当前访问的数据两边进行插入或删除操作,解决幻读的问题。
REF:
- Difference between Phantom Read and Dirty Read
- 高性能MySQL(第三版)
- Isolation in Wikipedia
- 可重复读的隔离级别
- The Repeatable Read Isolation Level - SQLPerformance.com
- MySQL :: MySQL 8.0 Reference Manual :: 15.7.1 InnoDB Locking
- MySQL间隙锁原理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号