
软工作业4-词频统计
一、基本信息
编译环境:pycharm2018、python3.8
项目名称:词频统计-基本功能
作者:1613072043 李文斌 1613072044 张扬
二、项目分析
2.1读取文件到缓冲区
def process_file(dst): # 读文件到缓冲区
try: # 打开文件
f = open(dst, 'r') # dst为文本的目录路径
except IOError as s:
print(s)
return None
try: # 读文件到缓冲区
bvffer = f.read()s
except:
print('Read File Error!')
return None
f.close()
return bvffer
2.2统计文件的有效行数
def process_rowCount(bvffer): # 计算文章的行数
if bvffer:
count = 1
for word in bvffer: # 开始计数
if word == '\n':
count = count + 1
print("lines:{:}".format(count))
f = open('result.txt', 'w')
print("lines:{:}".format(count),file=f)
f.close()
2.3用正则表达式筛选合格单词并统计
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 将文本内容都小写
bvffer = bvffer.lower()
# 用空格消除文本中标点符号
words = bvffer.replace(punctuation, ' ').split(' ')
# 正则匹配至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写
regex_word = "^[a-z]{4}(\w)*"
# 停词表模块
txtWords = open("stopwords.txt", 'r').readlines() # 读取停词表文件
stopWords = [] # 存放停词表的list
for i in range(len(txtWords)):
txtWords[i] = txtWords[i].replace('\n', '')
stopWords.append(txtWords[i])
for word in words:
if word not in stopWords: # 当单词不在停词表中时,使用正则表达式匹配
if re.match(regex_word, word):
# 数据字典已经存在该单词,数量+1
if word in word_freq.keys():
word_freq[word] = word_freq[word] + 1
# 不存在,把单词存入字典,数量置为1
else:
word_freq[word] = 1
return word_freq, len(words)
2.4输出出现频率前十的单词并保存到文件夹
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
print("<%s>:%d " % (item[0], item[1]))
f = open("result.txt", 'w')
print("<%s>:%d " % (item[0], item[1]), file=f)
f.close()
2.5停用词模块
def process_twoPhrase(words):
useless_twoPhrase =['they were','would have','there were','have been','that would']
words_group = []
for i in range(len(words) - 1):
str = '%s %s' % (words[i], words[i + 1])
words_group.append(str)
word_freq = {}
for word in words_group:
if word in useless_twoPhrase:
continue
else:
word_freq[word] = word_freq.get(word, 0) + 1 # 将词组进行计数统计
return word_freq
def process_threePhrase(words):
words_group = []
for i in range(len(words) - 2):
str = '%s %s %s' % (words[i], words[i + 1], words[i + 2])
words_group.append(str)
word_freq = {}
for word in words_group:
word_freq[word] = word_freq.get(word, 0) + 1 # 将词组进行计数统计
return word_freq
2.6高频词组
def output_result(word_freq):
if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 频率高的 print("<{:}>:{:}".format(item[0], item[1])) f = open('result.txt','a') print("<{:}>:{:}".format(item[0], item[1]), file=f) f.close()
2.7主函数
if __name__ == "__main__":
# 把分析结果保存到文件中
cProfile.run("main()", filename="result.wordcount")
p = pstats.Stats("result.wordcount")
p.strip_dirs().sort_stats("calls").print_stats(10)
p.strip_dirs().sort_stats("cumulative", "name").print_stats(10)
p.print_callers(0.5, "process_transform")
p.print_callers(0.5, "process_rowCount")
p.print_callers(0.5, "process_wordNumber")
p.print_callers(0.5, "process_stopwordSelect")
p.print_callers(0.5, "process_twoPhrase")
p.print_callers(0.5, "process_threePhrase")
p.print_callers(0.5, "output_result")
p.print_callees("process_buffer")
2.8程序运行截图
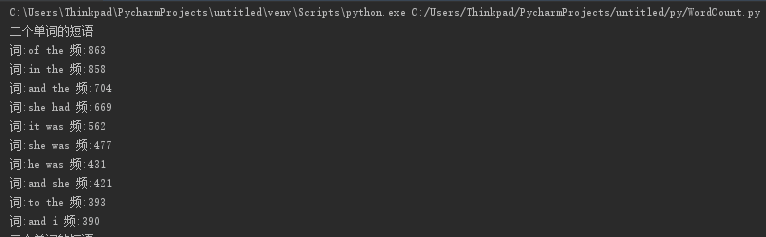

三、性能分析

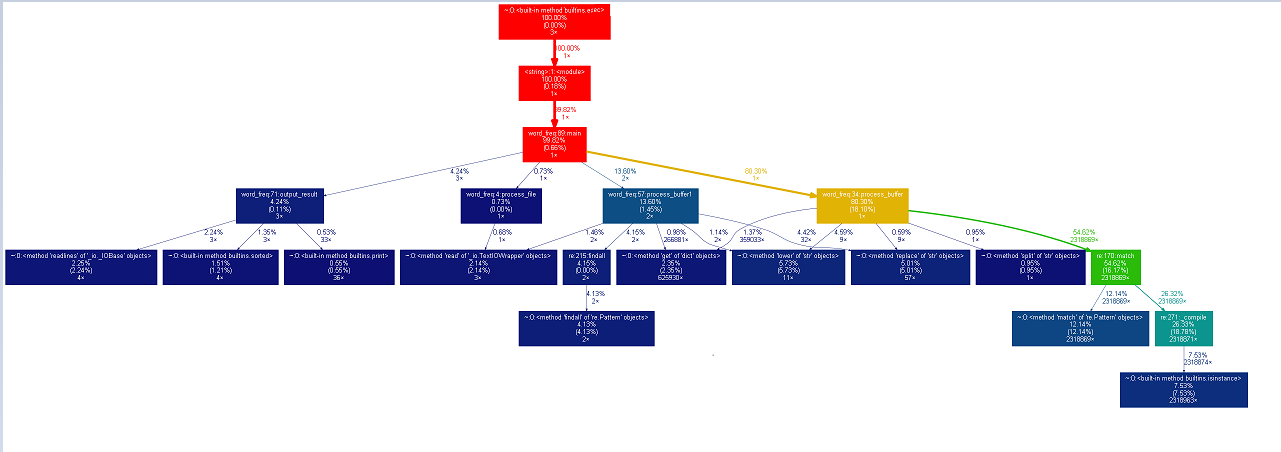
整个程序运行时间在0.7秒
以下为性能图表:
四、其他
1.结对编程实践开销:由于我们两人的基础较弱,共花费大概两周的时间
2.结对编程照片

,
五、事后分析与总结
1.简述结对编程时,针对某个问题时的讨论
在碰到出现分歧的问题通常分别实现两人不同的观点来观察哪个效率更高,并且通过向其他同学求助最后得出采用谁的方案。当决定采用其中一人的方案时,另一人会全力进行帮助来达到完成实验的目的。
2.互相评价对方
(1)张扬评论李文斌:具有悟性和耐心,有着很强的行动能力,在结对的过程中经常帮助搭档分担工作。不足的方面是在细节方面容易出现错误
(2)李文斌评论张扬:很有悟性,善于去学习与理解。不足的方面是基础能力较弱
3.评价整个结对过程及建议
整个过程的时间跨度比较长,在这段时间内互相磨合与调整,从而达到团队的效果。在这个过程中互相帮助理解,这次的合作让我们知道了一个人负责一个项目是过于劳累,而通过结对互助可以加快
对项目的理解与帮助。结对编程使得原本枯燥无味的过程变得生动有趣,同时也教会了我们如果遇到分歧时该如何解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号