

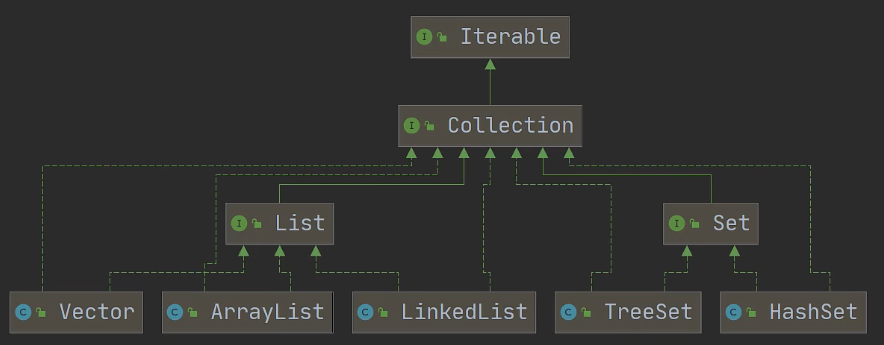
Collection单列 -- 个人随笔
集合对比数组的好处:
可以
动态保存任意多个对象,使用方便提供了一系列方便的操作方法:add、remove、set、get等
使用集合添加、删除新元素,
长度可变
- 单列集合
- List
- Vector
- ArrayList
- LinkedList
- Set
- TreeSet
- HashSet
- 双列集合
- HashMap
- LinkedHashMap
- HashTable
- Properties
- TreeMap
1.集合遍历方式,适用于List所有的子类
-
迭代器iterator()
-
增强for,底层也是使用迭代器,就是简化版本的迭代器
-
for循环遍历,索引便利
2.迭代器 iterator()
-
本身不存储元素,只指出元素值
-
iterator()是Iterable中重要的方法,所有集合都实现了iterator()方法。
-
hasNext(),判断是否还有数据
-
next(),指针后移,并将元素返回
3.List接口--单列集合
-
List集合元素
有序(添加、取出顺序一致),元素可以重复 -
List元素都有对应的索引
list.add();
list.indexOf("张三");//返回张三的索引
list.lastIndexOf("张三");//最后一个元素是张三的索引
list.remove(0);//移除索引为0的元素
3.1 ArrayList
-
ArrayList可以存Null,允许多个
-
ArrayList线程不安全,但是效率高
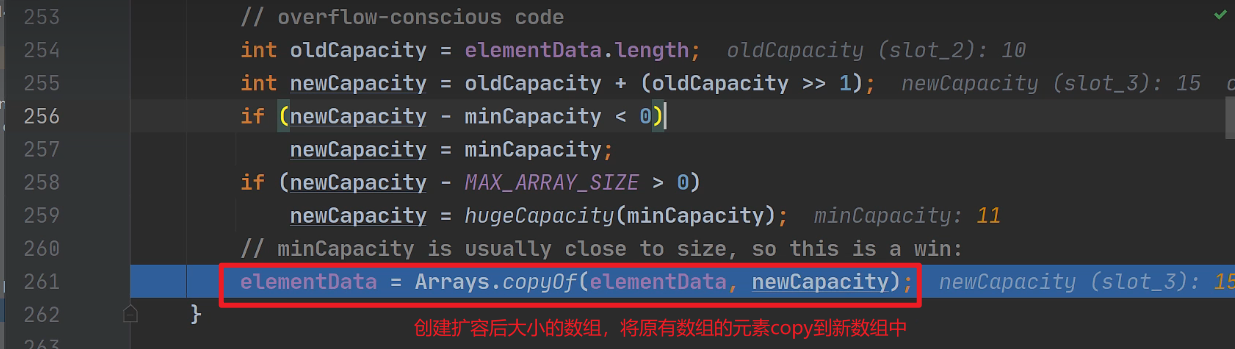
扩容底层:
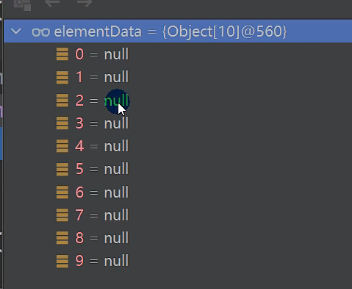
ArrayList维护了一个Object类型的数组elementData。
当创建ArrayList对象是,若不指定大小,默认为
空数组,当存放元素,第一次扩充elementData为10,后续扩充,elementData为1.5倍。若指定ArrayList容量大小,初始elementData为指定大小,扩容时也是根据指定大小
1.5倍扩容。扩容后未放值的位置使用
null填充(创建10个元素值为null数组)
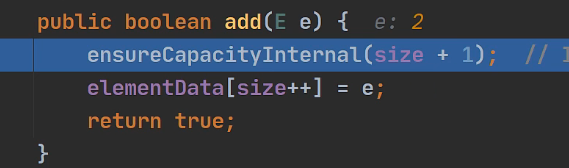
每次添加新元素都会判断需不需要扩容。
第二行是判断是否需要扩容
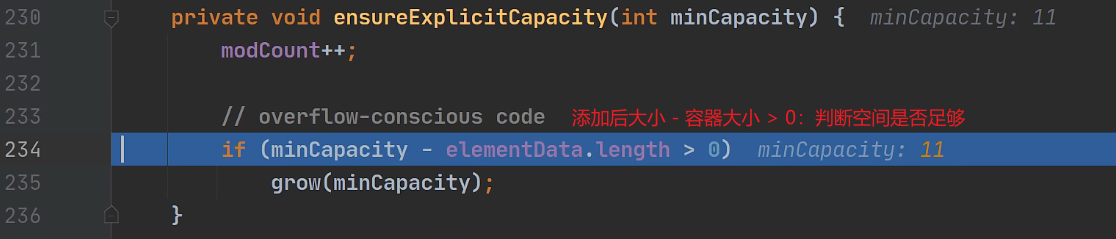
进入第二行判断是否扩容底层
进入grow()方法扩容1.5倍
3.2 Vector
-
线程安全
synchronized修饰方法 -
效率低
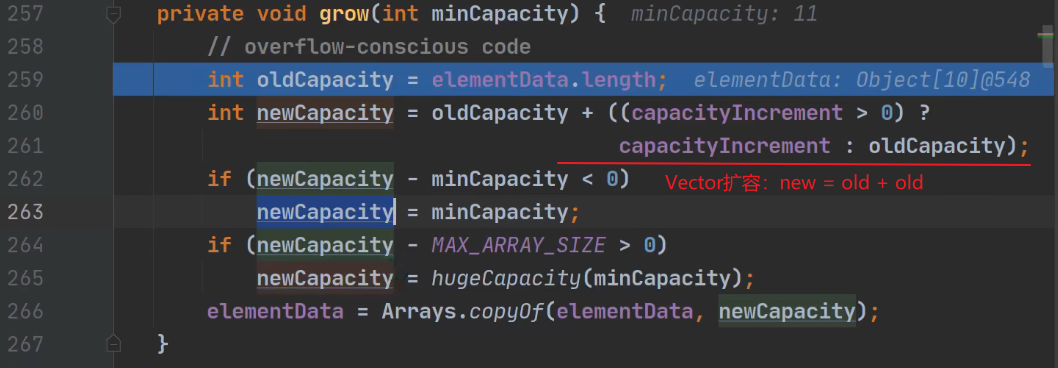
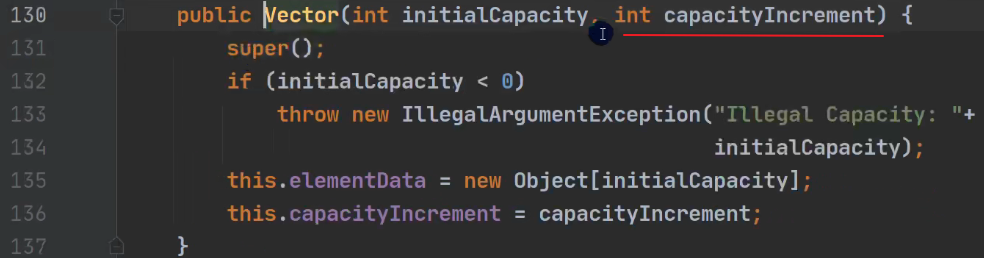
Vector扩容
不指定大小,默认
10,扩容两倍指定大小,扩容指定大小的
两倍
以下两个图片,说明
capacityIncrement写死了,一直为0.所以Vector扩容就是原有大小的两倍

3.3 ArrayList 与 Vector 比较
-
线程安全(同步),效率
-
扩容倍率

3.4 LinkedList
-
LinkedList底层实现了
双向链表和双端队列的特点 -
可以添加任意元素(元素可以重复),包括null
-
线程不安全,没有实现同步
-
添加、删除效率高
LinkedList中维护了两个属性first和last分别指向首节点和尾节点
- 每个节点node对象,有prev、next、item三个属性
- prev指向前一个,next指向后一个节点,实现双链表结构
LinkedList底层逻辑:
初始化,fast、last都是null
添加新元素,是将newNode赋值给lastNode
删除元素调用remove(),底层调用的是
removeFrist(),删除的是第一个节点。
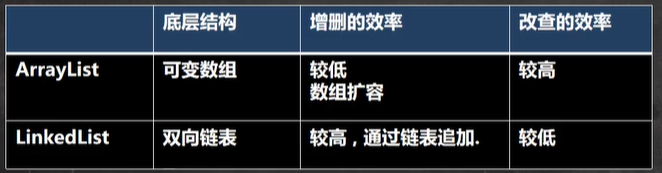
3.5 ArrayList和LinkedList比较
-
改查多,使用ArrayList
-
增删多,使用LinkedList
4.Set接口
-
Set接口也是Collection的子接口,蝉蛹方法与Collection一致
-
可以使用迭代器,增强for,但不能用
索引for循环,没有get()方法 -
不能存放重复我元素,可以存入null
-
数据存放无序
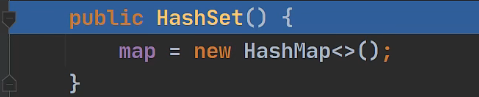
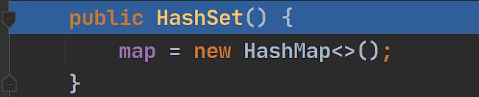
4.1 HashSet
-
底层是实现,
HashMap -
可以存放null,但只能有一个,元素不重复,无序
-
存入的是地址,String等引用类型地址可能不行
HashSet底层:
初始化
添加操作,会返回一个boolean结果,调用HashMap的
put()方法添加元素,先得到一个
hash值--》转成索引值
找到存储数据表table,查询
索引位置是否已经有存放的元素。不是直接的hashcode,进行了jiagong
如果没有直接加入。
如果没有,调用
equals比较,如果相同,就放弃添加,如果不相同,添加到链表最后。JDK8链表长度达到
8,并且表table大小达到64,会将链表转化为红黑树,
HashSet底层扩容:HashMap扩容
reSize()
初始化 1 << 4 = 16,初始大小是16
第一次临界值(
threshold):加载因子 * 表大小,0.75 * 16 = 12,依次类推;临界值,是表内所有元素的总是,包table上的基数,以及基数下链表上的元素,可以使用size
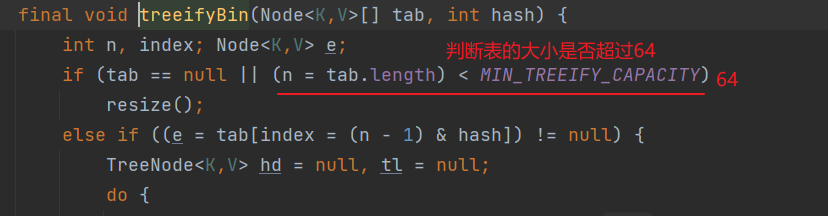
// HashMap put final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { //临时参数 Node<K,V>[] tab; Node<K,V> p; int n, i; //判断table是否创建 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //判断数据hash值对应的table上是否有值 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; // 存入数据与tab的第一个元素比较hash、地址、值 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 该节点是不是红黑树 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // 与第一个值不相同,并且也不是红黑树,那么就与链表下的数据依次比较 //1.比较后,都不相同(hash、地址、值),新建节点挂到链表的最后位置。立即判断,链表长度是否达到8,调用treeifyBin()方法转成红黑树 //2.相同,直接break,放弃添加;注,这个for是死循环 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; // p下移,e=p.next,相当于p的下一个元素 p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
4.2 LinkedHashSet
-
LinkedHashSet是HashSet的子类
-
底层是
LinkedHashMap(HashMap的子类),底层维护数组+双向链表;注:HashMap底层是个单向链表 -
1.每个节点有 before 和 after 属性,这样就形成了双向链表。
2.存储元素与HashSet原理相同,算hash,求索引,确认table位置,比较,存入初始扩容16
4.3 TreeSet
-
不适用构造器时,默认无序
-
实现Comparator接口(
比较器),重写compare()方法,可以实现规则排序,默认使用compareTo()比较 -

 浙公网安备 33010602011771号
浙公网安备 33010602011771号