
3. read_execl()函数
pandas.read_execl("midwest.xlsx",#路径
sheet_name = 0,#sheet分表
header = 0,#表头
index_col=None,#行索引,相当于一个竖的header
usecols = None,#使用的列
skiprows=None)#跳过行
-
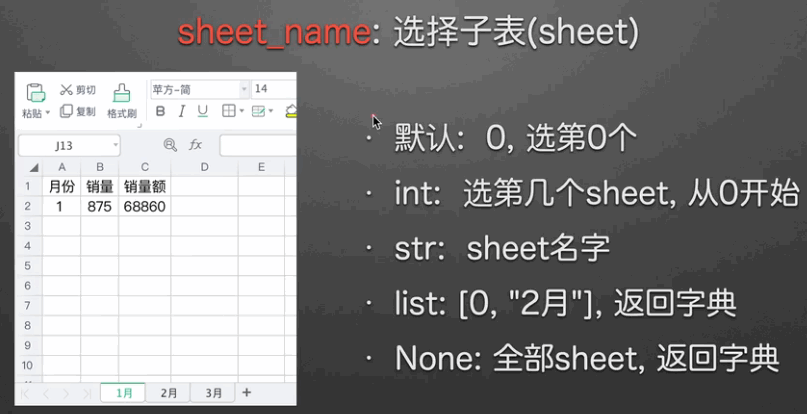
sheet参数
![]()
-
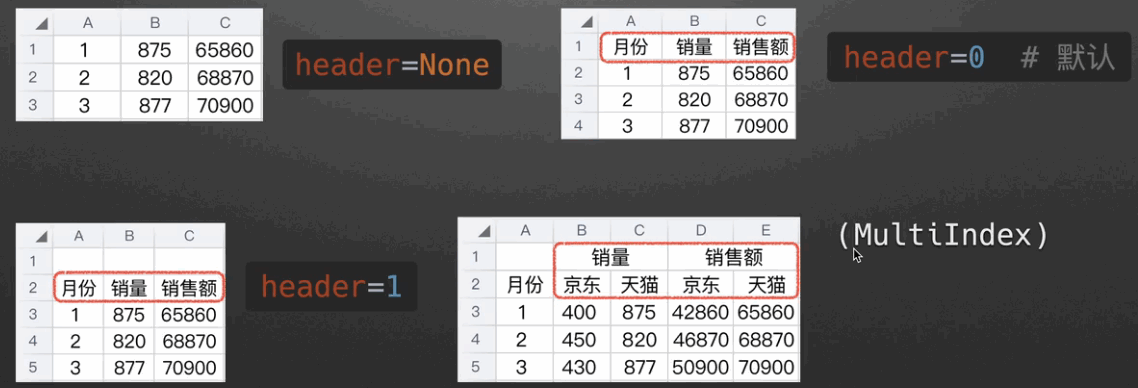
header参数
![]()
-
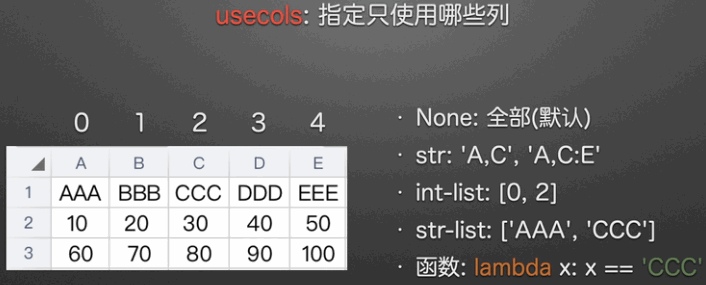
usecols参数
![]()
-
skiprows参数,跳过行
![]()

-
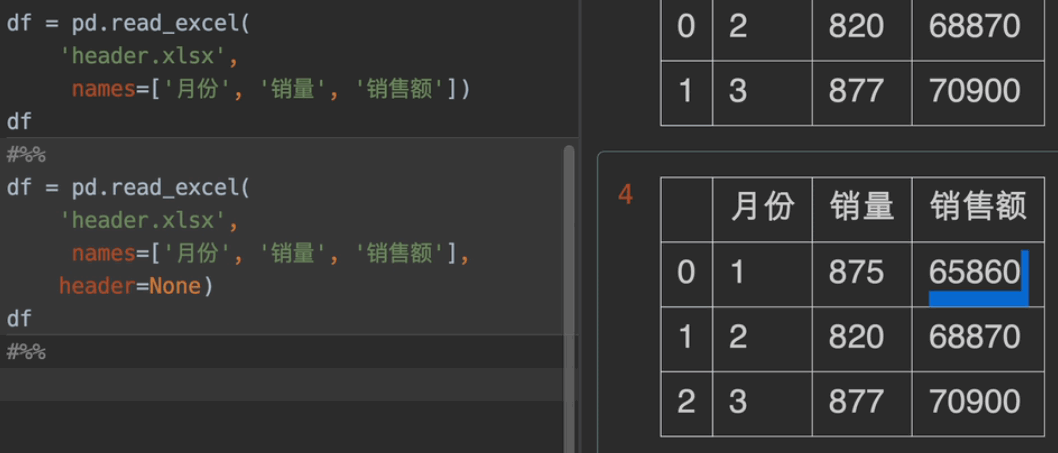
name参数,用于命名列名,常与header = None一起使用
![]()
-
dtype参数
传递一个字典参数,告诉read_execl()函数,每一列对应的是什么类型的数据
![]()
df = pd.read_execl("good_base.xlsx",
dtype = {"货号":"str",
"商品代码":"string"})

-
处理缺失值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号