
数据采集与融合技术实践作业四
作业一:
代码:
import requests
import pymysql
import time
import json
DB_HOST = 'localhost'
DB_USER = 'root'
DB_PASSWORD = '123456' # 【请在这里修改你的数据库密码】
DB_NAME = 'china_stock_db'
TABLE_NAME = 'shenzhen_stocks'
MAX_PAGES = 5
def init_database():
print("正在连接数据库并检测表结构...")
conn = pymysql.connect(host=DB_HOST, user=DB_USER, password=DB_PASSWORD, charset='utf8mb4')
cursor = conn.cursor()
try:
cursor.execute(f"CREATE DATABASE IF NOT EXISTS {DB_NAME} DEFAULT CHARSET utf8mb4 COLLATE utf8mb4_general_ci;")
conn.select_db(DB_NAME)
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {TABLE_NAME} (
id INT AUTO_INCREMENT PRIMARY KEY,
stock_code VARCHAR(20) COMMENT '股票代码',
stock_name VARCHAR(50) COMMENT '股票名称',
latest_price DECIMAL(10, 2) COMMENT '最新价',
change_percent DECIMAL(10, 2) COMMENT '涨跌幅%',
change_amount DECIMAL(10, 2) COMMENT '涨跌额',
volume BIGINT COMMENT '成交量(手)',
turnover DECIMAL(20, 2) COMMENT '成交额(元)',
amplitude DECIMAL(10, 2) COMMENT '振幅%',
high_price DECIMAL(10, 2) COMMENT '最高',
low_price DECIMAL(10, 2) COMMENT '最低',
open_price DECIMAL(10, 2) COMMENT '今开',
prev_close DECIMAL(10, 2) COMMENT '昨收',
crawl_time DATETIME DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
cursor.execute(create_table_sql)
print("数据库环境准备就绪。")
except Exception as e:
print(f"数据库初始化失败: {e}")
exit()
finally:
cursor.close()
conn.close()
def save_to_mysql(data_list):
"""保存数据到MySQL"""
if not data_list:
return
conn = pymysql.connect(host=DB_HOST, user=DB_USER, password=DB_PASSWORD, database=DB_NAME, charset='utf8mb4')
cursor = conn.cursor()
sql = f"""
INSERT INTO {TABLE_NAME}
(stock_code, stock_name, latest_price, change_percent, change_amount,
volume, turnover, amplitude, high_price, low_price, open_price, prev_close)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
try:
cursor.executemany(sql, data_list)
conn.commit()
print(f" -> 成功入库 {len(data_list)} 条数据")
except Exception as e:
conn.rollback()
print(f" -> 入库失败: {e}")
finally:
cursor.close()
conn.close()
def crawl_eastmoney_api():
base_url = "http://4.push2.eastmoney.com/api/qt/clist/get"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
for page in range(1, MAX_PAGES + 1):
print(f"正在抓取第 {page} 页...")
params = {
"pn": page, # 页码
"pz": 20, # 每页数量
"po": 1, # 排序方向
"np": 1, # 不清楚具体含义,通常设为1
"ut": "bd1d9ddb04089700cf9c27f6f7426281", # 固定的访问令牌
"fltt": 2,
"invt": 2,
"fid": "f3", # 排序字段 (f3代表按涨跌幅排序)
"fs": "m:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23,m:0 t:81 s:2048", # 沪深A股的筛选代码
"fields": "f12,f13,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18" # 需要返回的字段
}
try:
# 发送GET请求
response = requests.get(base_url, params=params, headers=headers, timeout=10)
if response.status_code == 200:
res_json = response.json()
if res_json.get('data') and res_json.get('data').get('diff'):
stock_list = res_json['data']['diff']
parsed_data = []
for stock in stock_list:
def get_val(key):
val = stock.get(key, 0)
return 0 if val == '-' else val
data_tuple = (
stock.get('f12'), # 代码
stock.get('f14'), # 名称
get_val('f2'), # 最新价
get_val('f3'), # 涨跌幅
get_val('f4'), # 涨跌额
get_val('f5'), # 成交量
get_val('f6'), # 成交额
get_val('f7'), # 振幅 (API有时候用f7)
get_val('f15'), # 最高
get_val('f16'), # 最低
get_val('f17'), # 今开
get_val('f18') # 昨收
)
parsed_data.append(data_tuple)
# 存入数据库
save_to_mysql(parsed_data)
else:
print("API返回数据为空,可能已到达最后一页。")
break
else:
print(f"请求失败,状态码: {response.status_code}")
except Exception as e:
print(f"抓取过程出错: {e}")
time.sleep(1)
if __name__ == "__main__":
# 1. 建库建表
init_database()
crawl_eastmoney_api()
print("\n所有任务完成!")
结果:

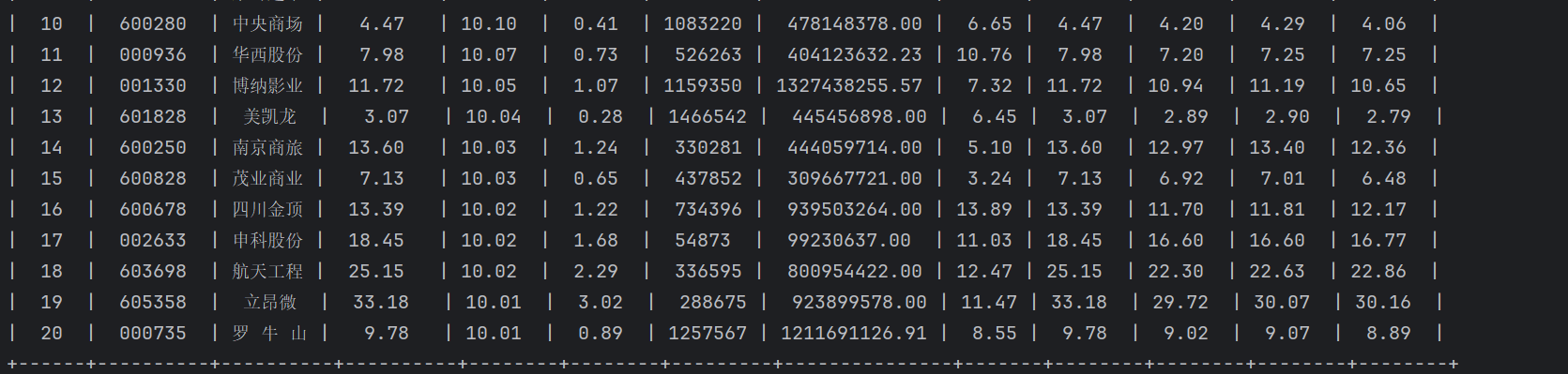
心得体会:
学会了本地部署MySQL,以及python程序如何连接MySQL。比起直接调用SQLite库,用MySQL多了个配置连接的步骤,其余的步骤都差不多。我觉得用MySQL存储的好处就是爬完数据之后,再用SQL语句对数据进行查询、更新等其他操作的时候更方便,而且MySQL在各种场景下,比如Web应用、云应用开发时,使用更加广泛。
作业二
代码:
import pymysql
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.service import Service
# ================= 配置区域 =================
# 数据库配置
DB_HOST = 'localhost'
DB_USER = 'root'
DB_PASSWORD = '123456' # 【请务必修改为你的数据库密码】
DB_NAME = 'mooc_db'
TABLE_NAME = 'course_info'
# 搜索关键词
SEARCH_KEYWORD = "Python数据分析"
# Chrome 浏览器安装路径 (你提供的路径)
CHROME_PATH = r"C:\Program Files\Google\Chrome\Application\chrome.exe"
# ===========================================
def init_database():
"""初始化数据库和表"""
print("正在初始化数据库...")
conn = pymysql.connect(host=DB_HOST, user=DB_USER, password=DB_PASSWORD, charset='utf8mb4')
cursor = conn.cursor()
try:
# 创建库
cursor.execute(f"CREATE DATABASE IF NOT EXISTS {DB_NAME} DEFAULT CHARSET utf8mb4 COLLATE utf8mb4_general_ci;")
conn.select_db(DB_NAME)
# 创建表
sql = f"""
CREATE TABLE IF NOT EXISTS {TABLE_NAME} (
Id INT AUTO_INCREMENT PRIMARY KEY,
cCourse VARCHAR(100) COMMENT '课程名称',
cCollege VARCHAR(100) COMMENT '学校名称',
cTeacher VARCHAR(50) COMMENT '主讲老师',
cTeam VARCHAR(255) COMMENT '团队成员',
cCount VARCHAR(50) COMMENT '参加人数',
cProcess VARCHAR(100) COMMENT '课程进度',
cBrief TEXT COMMENT '课程简介'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
cursor.execute(sql)
print("数据库表结构准备就绪。")
except Exception as e:
print(f"数据库初始化失败: {e}")
exit()
finally:
cursor.close()
conn.close()
def save_course(data):
"""保存单条课程数据"""
conn = pymysql.connect(host=DB_HOST, user=DB_USER, password=DB_PASSWORD, database=DB_NAME, charset='utf8mb4')
cursor = conn.cursor()
sql = f"""
INSERT INTO {TABLE_NAME} (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
try:
cursor.execute(sql, data)
conn.commit()
print(f" [入库成功] {data[0]}")
except Exception as e:
print(f" [入库失败] {e}")
finally:
cursor.close()
conn.close()
def run_spider():
# 1. 浏览器配置
options = webdriver.ChromeOptions()
options.binary_location = CHROME_PATH # 使用你之前填好的路径
# 尽可能伪装成正常浏览器
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_argument("--start-maximized") # 【新增】让浏览器自动最大化,方便你操作
print("正在启动 Chrome 浏览器...")
try:
service = Service(executable_path=r'./chromedriver.exe')
driver = webdriver.Chrome(service=service, options=options)
except Exception as e:
print(f"启动失败: {e}")
return
try:
# 2. 打开网页
url = f"https://www.icourse163.org/search.htm?search={SEARCH_KEYWORD}"
print(f"正在访问: {url}")
driver.get(url)
# ==========================================
# 【关键修改点:给足时间让你手动处理】
# ==========================================
print("\n" + "=" * 50)
print("❗❗ 重要提示 ❗❗")
print("浏览器已打开。请看一眼浏览器:")
print("1. 如果有【登录弹窗】或【广告】,请马上手动点叉号关掉!")
print("2. 确保能看到课程列表。")
print("程序将暂停 20 秒等待你操作,倒计时开始...")
time.sleep(20)
print("倒计时结束,开始抓取数据...")
print("=" * 50 + "\n")
# 3. 获取课程卡片 (使用更宽松的定位方式)
# 查找所有包含 "u-clist" 类名的 div
course_cards = driver.find_elements(By.XPATH, '//div[contains(@class, "u-clist")]')
if len(course_cards) == 0:
print("❌ 依然没有找到课程数据!")
print("可能是网页没加载出来,或者被反爬虫拦截了。")
# 截图保存,方便你看发生了什么
driver.save_screenshot("error_screenshot.png")
print("已保存错误截图到 error_screenshot.png,请查看。")
return
print(f"✅ 成功发现 {len(course_cards)} 门课程,开始抓取前 3 门...")
main_window = driver.current_window_handle
# 循环抓取
# 注意:这里只取前3个,防止越界
for i, card in enumerate(course_cards[:3]):
try:
# 重新定位一下元素,防止页面刷新后元素失效 (StaleElementReferenceException)
current_cards = driver.find_elements(By.XPATH, '//div[contains(@class, "u-clist")]')
if i >= len(current_cards): break
current_card = current_cards[i]
# === 列表页信息 ===
try:
# 查找包含 "人参加" 字样的文本
count_text = current_card.find_element(By.XPATH, './/span[contains(text(), "人参加")]').text
except:
count_text = "统计中"
# === 点击进入详情 ===
# 尽量点图片或标题,避免点到空白处
img_area = current_card.find_element(By.TAG_NAME, "img")
img_area.click()
time.sleep(3) # 等待新窗口
# 切换窗口
all_handles = driver.window_handles
driver.switch_to.window(all_handles[-1])
# 等待标题加载
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, "course-title")))
# === 抓取详情 ===
c_course = driver.find_element(By.CLASS_NAME, "course-title").text
try:
c_college = driver.find_element(By.XPATH,
'//div[contains(@class,"school-name")] | //a[contains(@class,"school-name")]').text
except:
c_college = "未知学校"
# 抓取老师
try:
teachers = driver.find_elements(By.XPATH,
'//div[contains(@class,"m-teachers")]//a[contains(@class,"f-fc3")]')
t_names = [t.text for t in teachers if t.text.strip()]
c_teacher = t_names[0] if t_names else "未知"
c_team = "、".join(t_names)
except:
c_teacher = "未知"
c_team = "无"
# 抓取时间
try:
# 尝试多种可能的结构
c_process = driver.find_element(By.XPATH,
'//*[contains(@class,"course-enroll-info_time")]').text.replace(
'\n', ' ')
except:
c_process = "时间待定"
# 抓取简介
try:
c_brief = driver.find_element(By.CLASS_NAME, "m-termInfo_cont").text[:100].replace('\n',
' ') + "..."
except:
c_brief = "暂无简介"
# === 入库 ===
data = (c_course, c_college, c_teacher, c_team, count_text, c_process, c_brief)
save_course(data)
# 关窗回退
driver.close()
driver.switch_to.window(main_window)
time.sleep(2)
except Exception as e:
print(f"抓取第 {i + 1} 个出错: {e}")
if len(driver.window_handles) > 1:
driver.close()
driver.switch_to.window(main_window)
continue
except Exception as e:
print(f"主程序报错: {e}")
driver.save_screenshot("fatal_error.png")
finally:
driver.quit()
print("程序结束。")
if __name__ == '__main__':
# 1. 初始化
init_database()
# 2. 运行爬虫
run_spider()
结果

心得体会
爬取web的方式用的webdriver,遍历数组当中的所有web,查找元素一开始用的Xpath,发现团队人员的名字一直爬取不了(应该也是写得太限制了),之后用全页面搜索,只搜索span.count,再用正则表达式匹配数字进行提取,反而成功了。说明有的时候查找元素没必要从上面几层一个个递归查找,只要保证该元素的属性名唯一,就可以直接查找了
作业三
任务一:
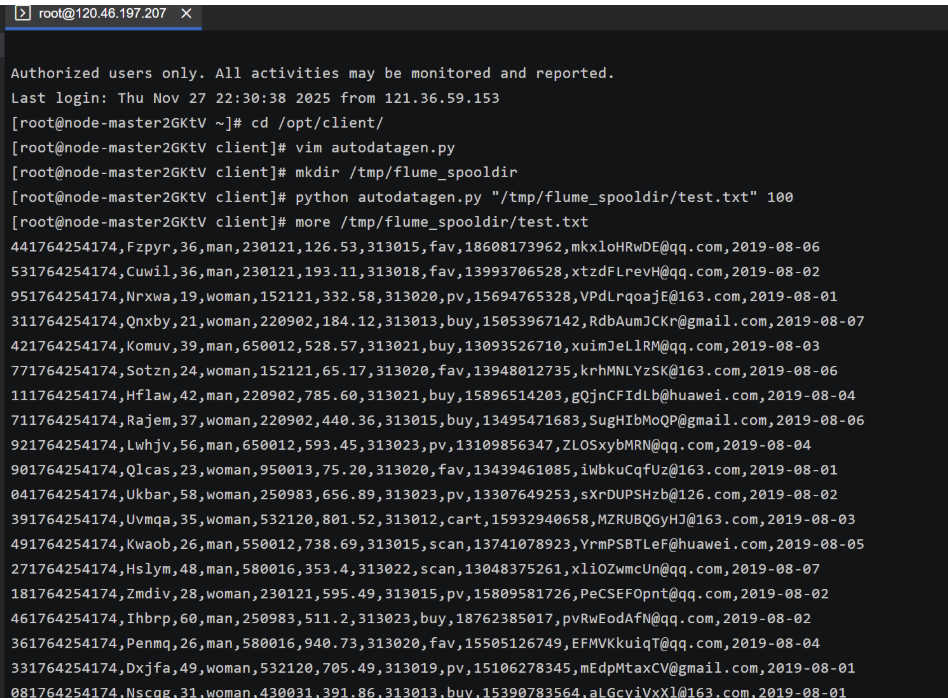
任务二:


任务三:

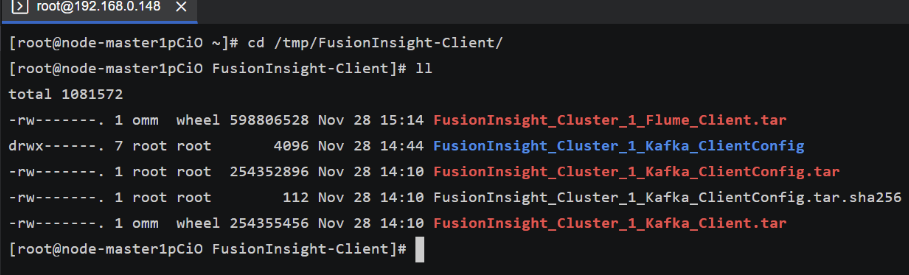


任务四:
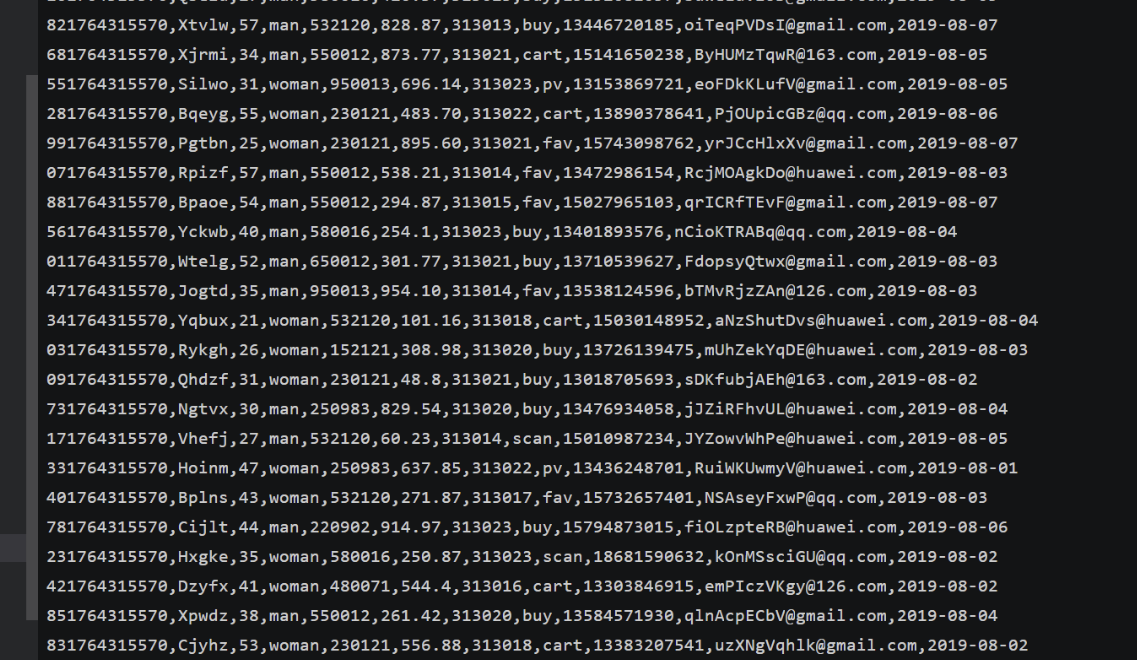
心得体会
创建topic要注意kafka的连接和网络的稳定,不然会因为超时而错误

 浙公网安备 33010602011771号
浙公网安备 33010602011771号