
数据采集与融合技术实践作业三
作业①:气象网站图片爬取
1.1 代码实现与运行结果
单线程&&多线程
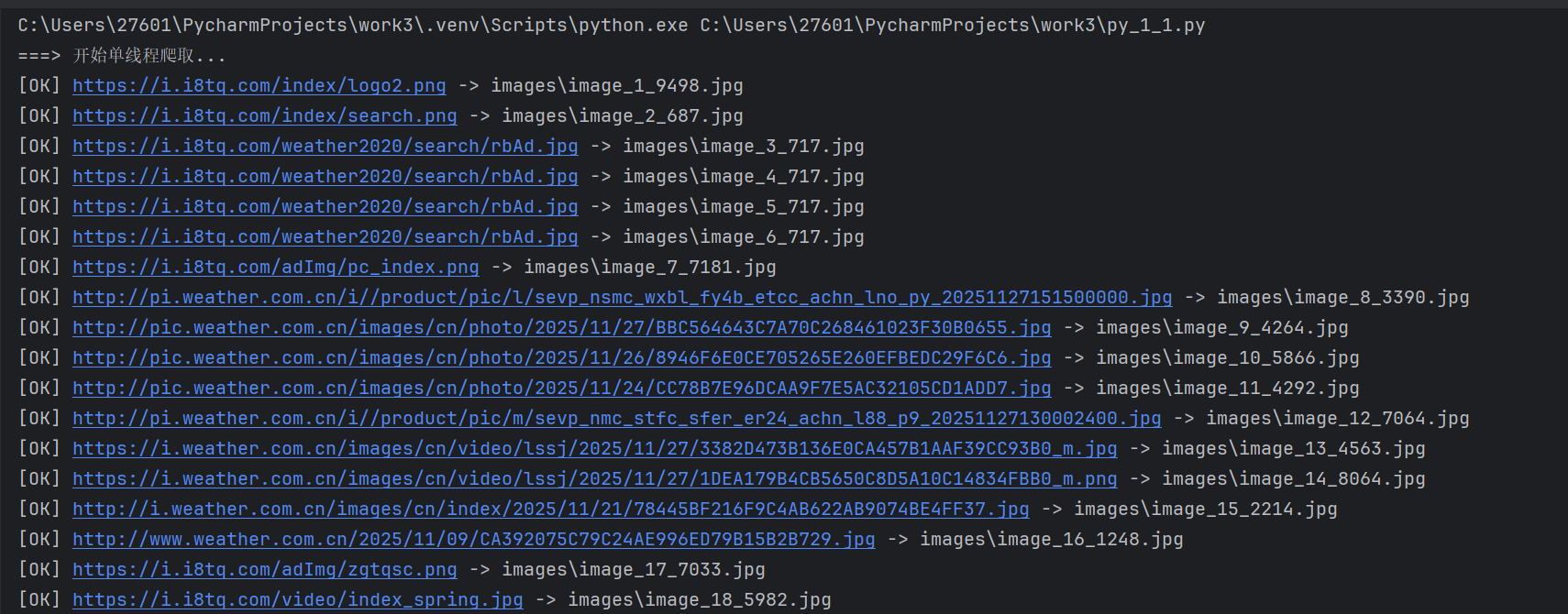
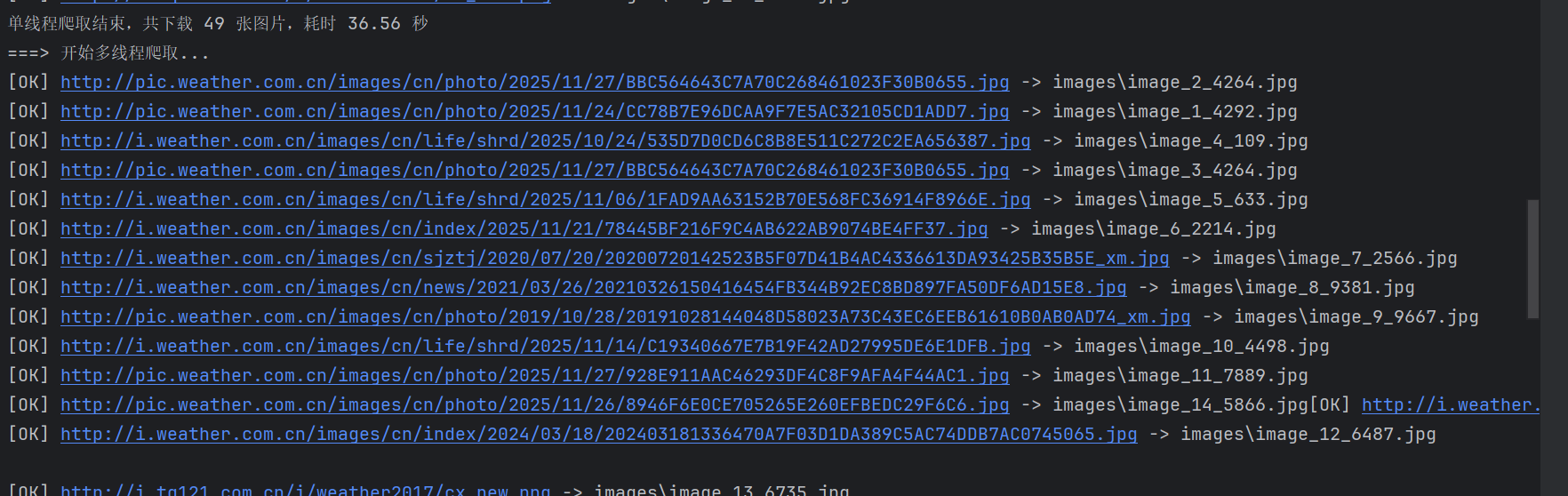
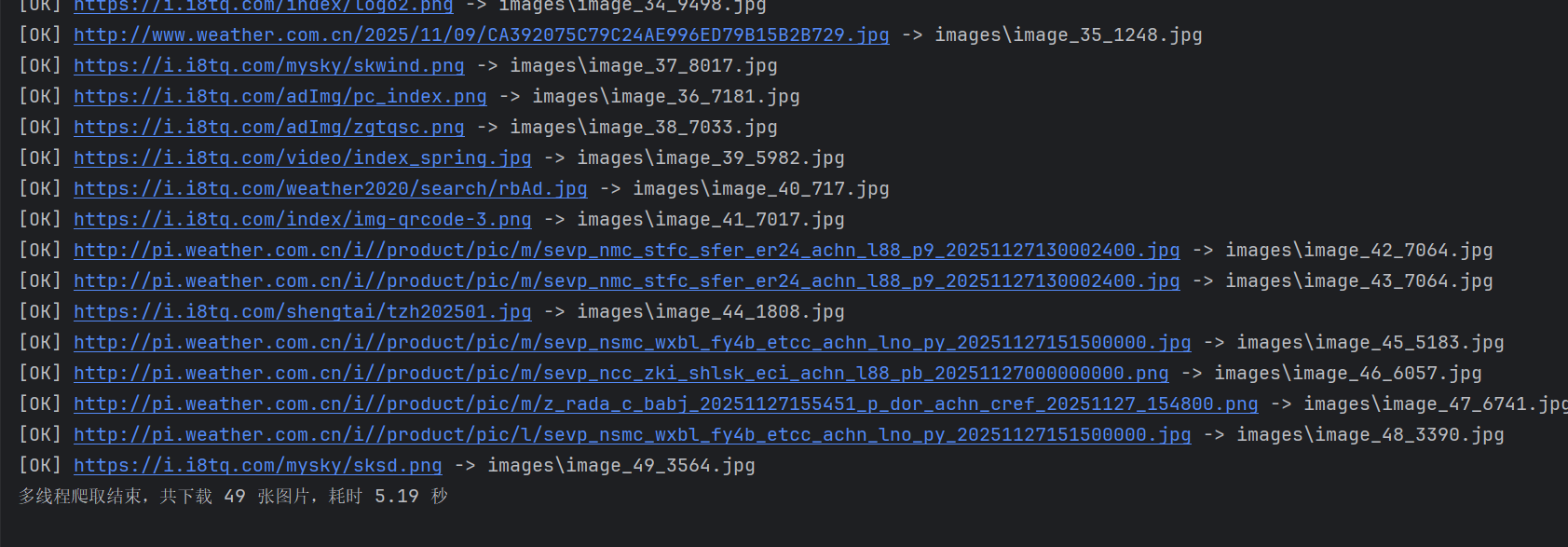
代码
import os
import time
import threading
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
class WeatherPicSpider:
def __init__(self, root_url: str = "http://www.weather.com.cn"):
# 基础配置
self.root_url = root_url
self.save_folder = "images"
self.page_limit = 25 # 学号尾数2位控制总页数(依然保留这个配置,但与原代码一样未使用)
self.image_limit = 125 # 学号尾数3位控制总图片数
# 计数器
self.download_counter = 0
# 线程锁(保证多线程下计数更安全,不改变原来“最多 image_limit 张”的本质行为)
self._lock = threading.Lock()
# 准备保存目录
if not os.path.isdir(self.save_folder):
os.makedirs(self.save_folder, exist_ok=True)
# 公共请求头
self._headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36"
)
}
# ---------------- 工具方法 ---------------- #
def _is_image_url(self, link: str) -> bool:
"""简单判断链接是否为图片地址"""
if not link:
return False
exts = (".jpg", ".jpeg", ".png", ".gif", ".bmp")
return link.lower().endswith(exts)
def _request_html(self, url: str) -> str | None:
"""请求页面并返回 HTML 文本"""
try:
resp = requests.get(url, headers=self._headers, timeout=10)
resp.encoding = "utf-8"
return resp.text
except Exception as exc:
print(f"获取页面失败:{url} -> {exc}")
return None
def _collect_images_from_page(self, page_url: str) -> list[str]:
"""解析页面中的所有图片 URL"""
html = self._request_html(page_url)
if html is None:
return []
soup = BeautifulSoup(html, "html.parser")
urls: list[str] = []
for img_tag in soup.find_all("img"):
src = img_tag.get("src")
if not src:
continue
if not self._is_image_url(src):
continue
# 拼成完整 URL(保持与原逻辑一致,基于 base_url 拼接)
full = urljoin(self.root_url, src)
urls.append(full)
return urls
def _save_image(self, img_url: str) -> bool:
"""下载并保存单张图片"""
# 先检查是否超过数量限制
with self._lock:
if self.download_counter >= self.image_limit:
return False
try:
resp = requests.get(img_url, headers=self._headers, timeout=10)
except Exception as exc:
print(f"请求图片失败:{img_url} -> {exc}")
return False
if resp.status_code != 200:
print(f"图片请求状态异常:{img_url} -> {resp.status_code}")
return False
# 再次加锁更新计数并生成文件名
with self._lock:
if self.download_counter >= self.image_limit:
return False
self.download_counter += 1
idx = self.download_counter
filename = os.path.join(
self.save_folder,
f"image_{idx}_{abs(hash(img_url)) % 10000}.jpg"
)
try:
with open(filename, "wb") as fp:
fp.write(resp.content)
print(f"[OK] {img_url} -> {filename}")
return True
except Exception as exc:
print(f"保存图片失败:{img_url} -> {exc}")
return False
# ---------------- 爬取模式 ---------------- #
def crawl_single_thread(self) -> None:
"""单线程方式抓取首页所有图片"""
print("===> 开始单线程爬取...")
start = time.time()
img_links = self._collect_images_from_page(self.root_url)
for url in img_links:
with self._lock:
if self.download_counter >= self.image_limit:
break
self._save_image(url)
duration = time.time() - start
print(
f"单线程爬取结束,共下载 {self.download_counter} 张图片,"
f"耗时 {duration:.2f} 秒"
)
def crawl_multi_thread(self) -> None:
"""多线程方式抓取首页所有图片"""
print("===> 开始多线程爬取...")
start = time.time()
img_links = self._collect_images_from_page(self.root_url)
threads: list[threading.Thread] = []
for url in img_links:
with self._lock:
if self.download_counter >= self.image_limit:
break
t = threading.Thread(target=self._save_image, args=(url,))
threads.append(t)
t.start()
for t in threads:
t.join()
duration = time.time() - start
print(
f"多线程爬取结束,共下载 {self.download_counter} 张图片,"
f"耗时 {duration:.2f} 秒"
)
if __name__ == "__main__":
spider = WeatherPicSpider()
# 单线程
spider.crawl_single_thread()
# 重置计数后再用多线程
spider.download_counter = 0
spider.crawl_multi_thread()
作业二
Scrapy框架+Xpath股票爬取实验
要求:熟练掌握 Scrapy 中 Item、Pipeline 数据的序列化输出方法;使用 Scrapy + XPath + MySQL 数据库存储技术路线爬取股票相关信息。
框架
EastmoneyScraperProject/
├── venv/
└── eastmoney_spider/ <-- Scrapy项目目录
├── scrapy.cfg
└── eastmoney_spider/
├── __init__.py
├── items.py <-- 定义数据结构
├── middlewares.py
├── pipelines.py <-- 数据处理管道
├── settings.py <-- 项目配置
└── spiders/ <-- 存放爬虫文件
└── __init__.py
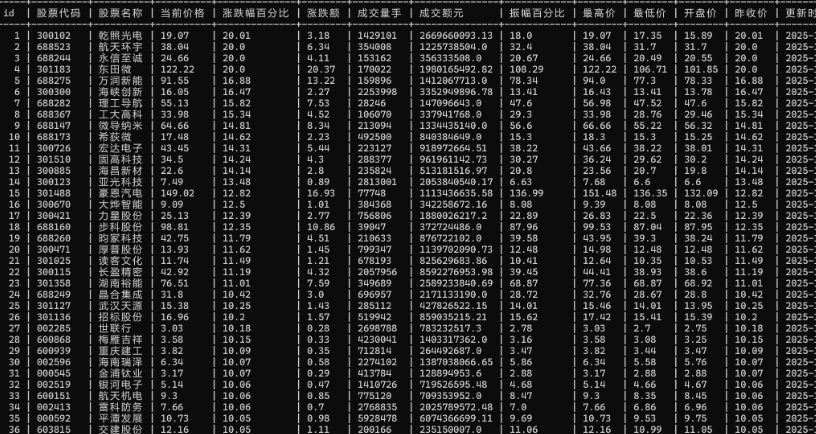
代码:
# eastmoney_spider/items.py
import scrapy
class EastmoneySpiderItem(scrapy.Item):
# 定义你想要抓取的数据字段,和作业要求一致
serial_number = scrapy.Field() # 序号
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
latest_price = scrapy.Field() # 最新报价
change_percent = scrapy.Field() # 涨跌幅
change_amount = scrapy.Field() # 涨跌额
trading_volume = scrapy.Field() # 成交量
turnover = scrapy.Field() # 成交额 (注意:作业图片上的“涨跌额”实际上应为成交额)
amplitude = scrapy.Field() # 振幅
highest = scrapy.Field() # 最高
lowest = scrapy.Field() # 最低
open_price = scrapy.Field() # 今开
prev_close = scrapy.Field() # 昨收
# eastmoney_spider/spiders/stock_info_spider.py
import scrapy
import json
from ..items import EastmoneySpiderItem
class StockInfoSpider(scrapy.Spider):
name = 'stock_info' # 爬虫的唯一名称
allowed_domains = ['eastmoney.com']
# 东方财富网A股行情数据接口
# pn: 页码
# pz: 每页大小
# fs: 板块代码 (m:0+t:6,m:0+t:13,m:0+t:80 分别代表沪A、深A、北A)
# fields: 需要获取的数据字段
base_url = 'http://82.push2.eastmoney.com/api/qt/clist/get?pn={}&pz=50&po=1&np=1&ut=bd1d9ddb040897001ac6977435a58752&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80&fields=f2,f3,f4,f5,f6,f7,f8,f12,f14,f15,f16,f17,f18'
# 设置起始页码
start_page = 1
def start_requests(self):
# 从第一页开始请求
yield scrapy.Request(self.base_url.format(self.start_page), callback=self.parse)
def parse(self, response):
# 解析返回的JSON数据
data = json.loads(response.text)
# 提取股票列表数据
stock_list = data.get('data', {}).get('diff', [])
if stock_list:
# 遍历股票列表
for i, stock in enumerate(stock_list):
item = EastmoneySpiderItem()
# 计算全局序号
current_page = int(response.url.split('pn=')[1].split('&')[0])
item['serial_number'] = (current_page - 1) * 50 + i + 1
# 提取并填充数据,对于'-'的数据填充为None或0
item['stock_code'] = stock.get('f12')
item['stock_name'] = stock.get('f14')
item['latest_price'] = stock.get('f2') if stock.get('f2') != '-' else 0.0
item['change_percent'] = stock.get('f3') if stock.get('f3') != '-' else 0.0
item['change_amount'] = stock.get('f4') if stock.get('f4') != '-' else 0.0
# 成交量和成交额需要单位转换
volume = stock.get('f5')
if isinstance(volume, (int, float)):
item['trading_volume'] = f"{volume / 10000:.2f}万手" if volume > 10000 else f"{volume}手"
else:
item['trading_volume'] = '0手'
turnover_val = stock.get('f6')
if isinstance(turnover_val, (int, float)):
if turnover_val > 100000000:
item['turnover'] = f"{turnover_val / 100000000:.2f}亿"
else:
item['turnover'] = f"{turnover_val / 10000:.2f}万"
else:
item['turnover'] = '0万'
item['amplitude'] = stock.get('f7') if stock.get('f7') != '-' else 0.0
item['highest'] = stock.get('f15') if stock.get('f15') != '-' else 0.0
item['lowest'] = stock.get('f16') if stock.get('f16') != '-' else 0.0
item['open_price'] = stock.get('f17') if stock.get('f17') != '-' else 0.0
item['prev_close'] = stock.get('f18') if stock.get('f18') != '-' else 0.0
yield item
# 获取总股票数和当前页码,判断是否需要爬取下一页
total_stocks = data.get('data', {}).get('total', 0)
current_page = int(response.url.split('pn=')[1].split('&')[0])
# 如果当前已爬取的数量小于总数,则请求下一页
if current_page * 50 < total_stocks:
next_page = current_page + 1
# 为了练习,我们只爬取前3页数据。如果你想爬取所有数据,请删除下面两行。
if next_page > 3:
return
yield scrapy.Request(self.base_url.format(next_page), callback=self.parse)
# eastmoney_spider/pipelines.py
import pymysql
class EastmoneyMysqlPipeline:
def open_spider(self, spider):
# 爬虫启动时调用,用于连接数据库
# !!! 请根据你的实际情况修改这里的数据库连接信息 !!!
self.connection = pymysql.connect(
host='localhost', # 数据库主机地址
user='stock_user', # 你的用户名
password='YourPassword123', # 你的密码
db='stock_data', # 你的数据库名
charset='utf8mb4'
)
self.cursor = self.connection.cursor()
spider.logger.info("MySQL connection opened")
# 在爬虫启动时创建数据表(如果不存在)
# 使用了 VARCHAR 来存储可能包含单位的字符串
create_table_sql = """
CREATE TABLE IF NOT EXISTS stock_info (
id INT AUTO_INCREMENT PRIMARY KEY,
serial_number INT,
stock_code VARCHAR(10),
stock_name VARCHAR(50),
latest_price DECIMAL(10, 2),
change_percent DECIMAL(10, 2),
change_amount DECIMAL(10, 2),
trading_volume VARCHAR(50),
turnover VARCHAR(50),
amplitude DECIMAL(10, 2),
highest DECIMAL(10, 2),
lowest DECIMAL(10, 2),
open_price DECIMAL(10, 2),
prev_close DECIMAL(10, 2),
UNIQUE (stock_code)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
self.cursor.execute(create_table_sql)
self.connection.commit()
spider.logger.info("Table 'stock_info' created or already exists.")
# 清空表数据,以便每次运行都是最新的数据
self.cursor.execute("TRUNCATE TABLE stock_info;")
self.connection.commit()
spider.logger.info("Table 'stock_info' truncated.")
def close_spider(self, spider):
# 爬虫关闭时调用,用于关闭数据库连接
self.cursor.close()
self.connection.close()
spider.logger.info("MySQL connection closed")
def process_item(self, item, spider):
# 每当爬虫yield一个item时,这个方法就会被调用
# 使用参数化查询防止SQL注入
insert_sql = """
INSERT INTO stock_info (
serial_number, stock_code, stock_name, latest_price,
change_percent, change_amount, trading_volume, turnover, amplitude,
highest, lowest, open_price, prev_close
) VALUES (
%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s
)
"""
try:
self.cursor.execute(insert_sql, (
item['serial_number'],
item['stock_code'],
item['stock_name'],
item['latest_price'],
item['change_percent'],
item['change_amount'],
item['trading_volume'],
item['turnover'],
item['amplitude'],
item['highest'],
item['lowest'],
item['open_price'],
item['prev_close']
))
self.connection.commit()
except Exception as e:
spider.logger.error(f"Failed to insert item: {item}. Error: {e}")
self.connection.rollback()
return item
作业三
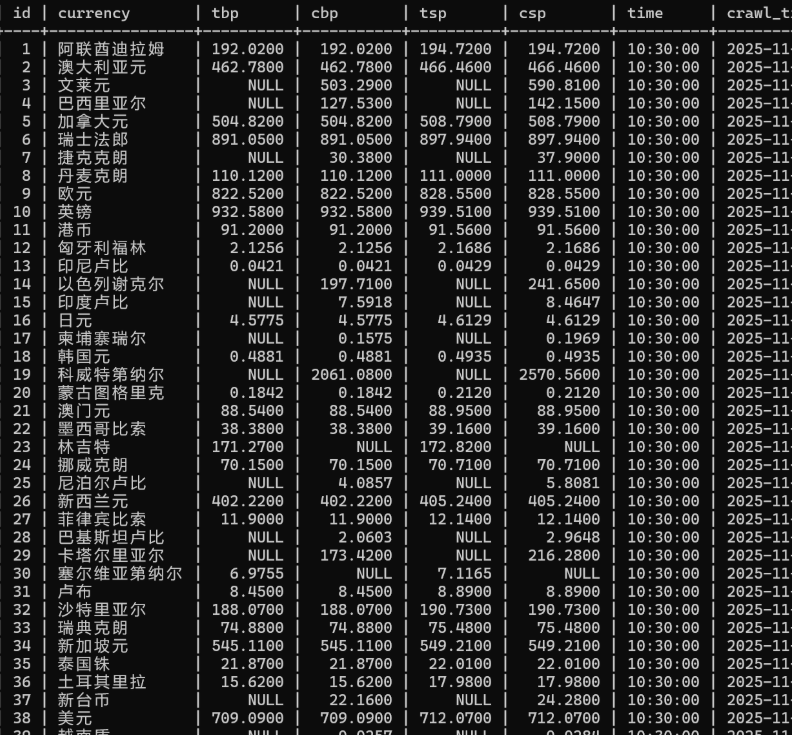
Scrapy框架+Xpath爬取外汇信息实验
要求:熟练掌握 Scrapy 中 Item、Pipeline 数据的序列化输出方法;使用 Scrapy 框架 + XPath + MySQL 数据库存储技术路线爬取外汇网站数据。
代码
class BocRateSpider(scrapy.Spider):
name = "boc_rate"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
# 找到主内容区域里的第一张表
table = response.xpath('//div[contains(@class,"BOC_main")]//table[1]')
# 跳过第一行表头,从第二行开始都是数据
rows = table.xpath('.//tr[position()>1]')
self.logger.info("共解析到 %s 行外汇记录", len(rows))
for tr in rows:
# 当前行所有单元格文本(XPath)
tds = tr.xpath('./td//text()').getall()
# 去掉空白
tds = [t.strip() for t in tds if t.strip()]
if len(tds) < 8:
continue
item = WhpjItem()
item["currency"] = tds[0]
item["tbp"] = tds[1]
item["cbp"] = tds[2]
item["tsp"] = tds[3]
item["csp"] = tds[4]
item["time"] = tds[7]
print(">>> item:", item["currency"], item["tbp"], item["cbp"],
item["tsp"], item["csp"], item["time"])
yield item
import sqlite3
class SqlitePipeline(object):
def open_spider(self, spider):
"""爬虫启动时:连接/创建数据库,并建表"""
self.conn = sqlite3.connect("whpj.db")
self.cursor = self.conn.cursor()
create_sql = """
CREATE TABLE IF NOT EXISTS fx_rate (
id INTEGER PRIMARY KEY AUTOINCREMENT,
currency TEXT,
tbp TEXT,
cbp TEXT,
tsp TEXT,
csp TEXT,
time TEXT
);
"""
self.cursor.execute(create_sql)
self.conn.commit()
def close_spider(self, spider):
"""爬虫结束:关闭连接"""
self.cursor.close()
self.conn.close()
def process_item(self, item, spider):
"""每次来一个 item 就写库"""
insert_sql = """
INSERT INTO fx_rate(currency, tbp, cbp, tsp, csp, time)
VALUES (?, ?, ?, ?, ?, ?)
"""
data = (
item.get("currency"),
item.get("tbp"),
item.get("cbp"),
item.get("tsp"),
item.get("csp"),
item.get("time"),
)
print(">>> 插入记录:", data) # 调试输出
self.cursor.execute(insert_sql, data)
self.conn.commit()
return item
import sqlite3
class SqlitePipeline(object):
def open_spider(self, spider):
"""爬虫启动时:连接/创建数据库,并建表"""
self.conn = sqlite3.connect("whpj.db")
self.cursor = self.conn.cursor()
create_sql = """
CREATE TABLE IF NOT EXISTS fx_rate (
id INTEGER PRIMARY KEY AUTOINCREMENT,
currency TEXT,
tbp TEXT,
cbp TEXT,
tsp TEXT,
csp TEXT,
time TEXT
);
"""
self.cursor.execute(create_sql)
self.conn.commit()
def close_spider(self, spider):
"""爬虫结束:关闭连接"""
self.cursor.close()
self.conn.close()
def process_item(self, item, spider):
"""每次来一个 item 就写库"""
insert_sql = """
INSERT INTO fx_rate(currency, tbp, cbp, tsp, csp, time)
VALUES (?, ?, ?, ?, ?, ?)
"""
data = (
item.get("currency"),
item.get("tbp"),
item.get("cbp"),
item.get("tsp"),
item.get("csp"),
item.get("time"),
)
print(">>> 插入记录:", data) # 调试输出
self.cursor.execute(insert_sql, data)
self.conn.commit()
return item
结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号