数据采集与融合技术作业1
1.作业①:
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
输出信息:
1.1作业代码和图片
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
from prettytable import PrettyTable
import importlib, sys
importlib.reload(sys)
url="http://www.shanghairanking.cn/rankings/bcur/2023"
req=urllib.request.Request(url)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"html.parser")
List=soup.select("tbody tr")
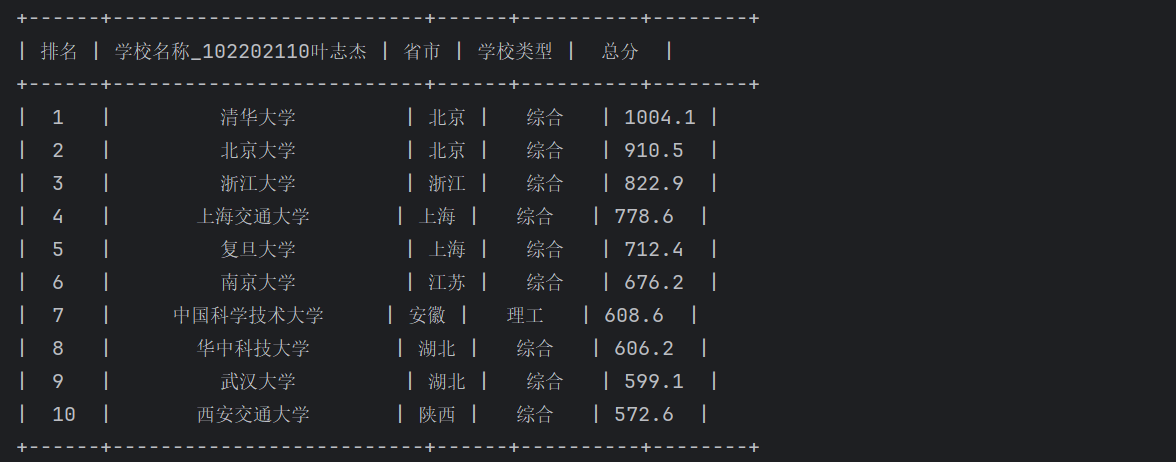
table = PrettyTable(['排名','学校名称_102202110叶志杰','省市','学校类型','总分'])
#由于返回的学校名称都是这种类型:清华大学TsinghuaUniversity双一流/985/211
#写一个函数把xx大学这个子串拎出来
def extract_name(school_info):
uni_idx = school_info.find('大学')
name = school_info[:uni_idx+2]
return name
for item in List[0:10]:
ls=item.select("td")
length=len(ls)
cnt=0
school=[]
for i in ls[0:5]:
cnt+=1
text = i.text.replace(" ", "").replace("\n", "")
school.append(text)
#制成表格更清晰,用制表符的话有很多格式对齐问题,有点丑。
table.add_row([school[0], extract_name(school[1]),school[2], school[3], school[4]]);
print(table)
1.2 心得体会
通过本次实践,我对于用requests和BeautifulSoup库方法爬取网站信息有了更深的理解,也在一定程度上增强了我对于HTML的理解,也提高了我的编码实践能力,为后续要完成更加复杂的实践任务打下基础
2.作业②:
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
2.1作业代码和图片
import requests
import re
url = 'https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&category_id=4003728&type=4003728&att=1000012%3A1873#J_tab'
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
}
response = requests.get(url,headers = headers)
data = response.text
start=(re.search(r'<ul class="bigimg cloth_shoplist" id="component_38">.*</ul>',data)).start()
end=(re.search(r'<ul class="bigimg cloth_shoplist" id="component_38">.*</ul>',data)).end()
table=data[start:end] #截取含有需要内容的html源码
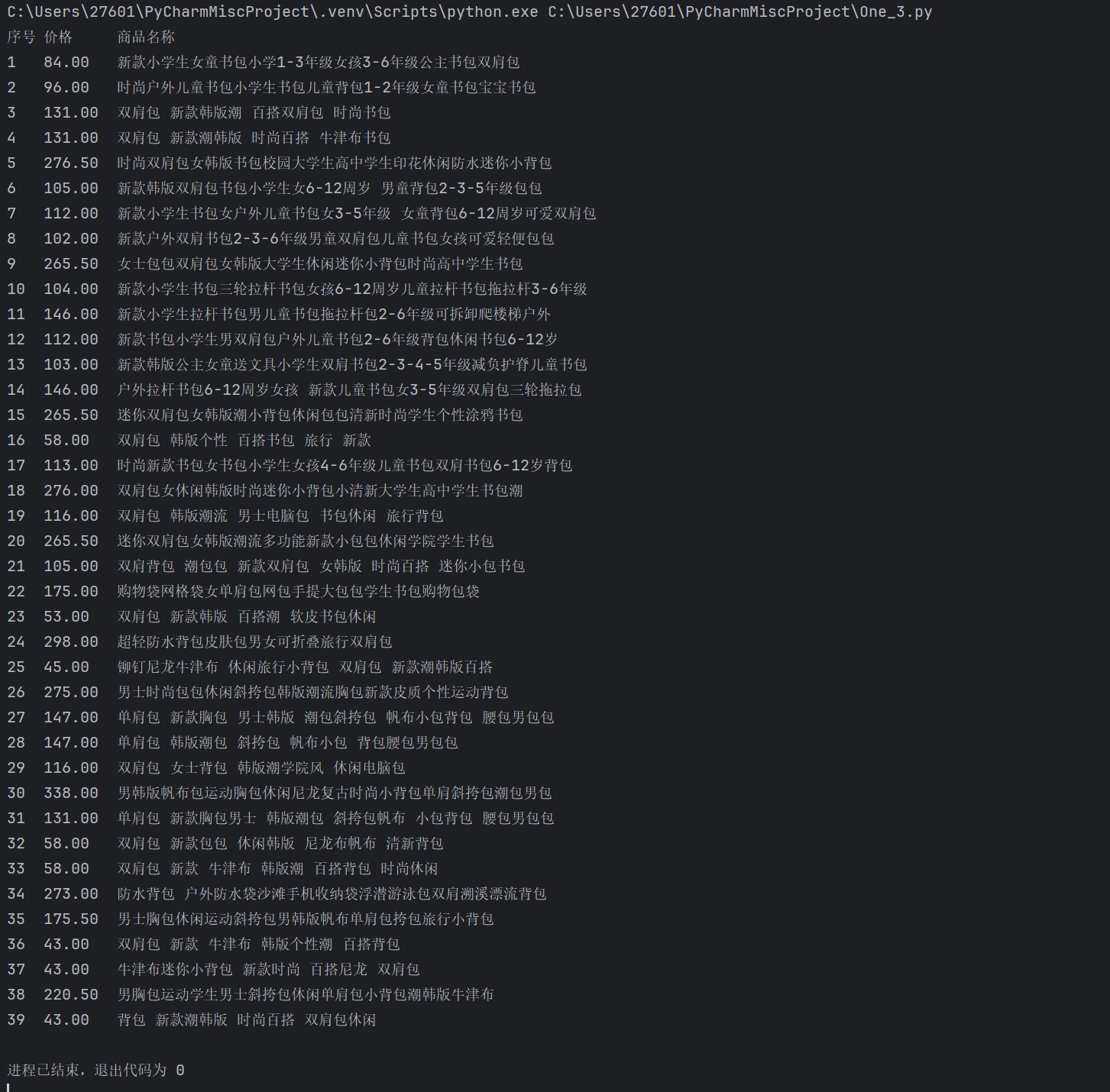
if table:
print("序号\t价格\t\t商品名称")
i=1
while re.search(r'<a title=" ', table)!=None:#每找到一组需要的书包名称和价格就将table缩短,去掉含有已经找到信息的源码
start = re.search(r'<a title=" ', table).end()
end = re.search(r' ddclick=', table).start()
name_bag = table[start:end - 1]#提取书包名称
start = re.search(r'<span class="price_n">', table).end()
end = re.search(r'</span>', table).start()
price_bag = table[start+5:end]#提取书包的价格
table = table[end:]
xin = re.search('</li>', table).end()
table = table[xin:]#去除包含已经找到信息的源码后的新的table
if price_bag and name_bag:#打印找到的书包的名称和价格
print("{}\t{}\t{}".format(i, price_bag, name_bag))
i += 1
else:
print("{}\t未找到商品价格或名称".format(i))
i += 1
except Exception as err:
print(err)
2.2 心得体会
通过本次实践任务,进一步加深了我对正则表达式操作符的理解,也让我掌握了更多re库的方法,懂得如何运用具体的正则表达式操作符爬取需要的信息,提高了个人的编程实践能力。
3.作业③:
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
输出信息:将自选网页内的所有JPEG、JPG或PNG格式图片件保存在一个文件夹中
3.1作业代码和图片
import urllib.request
import re
import os
import time
from urllib.parse import urljoin, urlparse
def get_page_content(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
req = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(req, timeout=10)
html_content = resp.read().decode('utf-8')
return html_content
except Exception as e:
print(f"获取页面失败: {e}")
return None
def get_image_urls(html_content, page_url):
# 匹配img标签中的src属性
img_pattern = r'<img[^>]+src="([^">]+)"'
img_urls = re.findall(img_pattern, html_content, re.I)
# 匹配CSS背景图片
css_pattern = r'background-image:\s*url\([\'"]?([^\'"\)]+)[\'"]?\)'
css_urls = re.findall(css_pattern, html_content, re.I)
# 合并所有图片URL
all_urls = img_urls + css_urls
valid_image_urls = []
# 将相对路径转换为绝对路径
for img_url in all_urls:
full_url = urljoin(page_url, img_url)
valid_image_urls.append(full_url)
return valid_image_urls
def download_image(img_url, download_folder):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'https://news.fzu.edu.cn/'
}
# 请求图片
req = urllib.request.Request(img_url, headers=headers)
response = urllib.request.urlopen(req, timeout=10)
img_data = response.read()
# 从URL中提取文件名
filename = os.path.basename(urlparse(img_url).path)
if not filename:
filename = f"image_{int(time.time())}.jpg"
filepath = os.path.join(download_folder, filename)
with open(filepath, 'wb') as f:
f.write(img_data)
print(f"下载成功: {filename}")
return True
except Exception as e:
print(f"下载失败: {e}")
return False
def main():
url = "https://news.fzu.edu.cn/yxfd.htm"
download_folder = "fzu_images"
if not os.path.exists(download_folder):
os.makedirs(download_folder)
html_content = get_page_content(url)
if not html_content:
return
image_urls = get_image_urls(html_content, url)
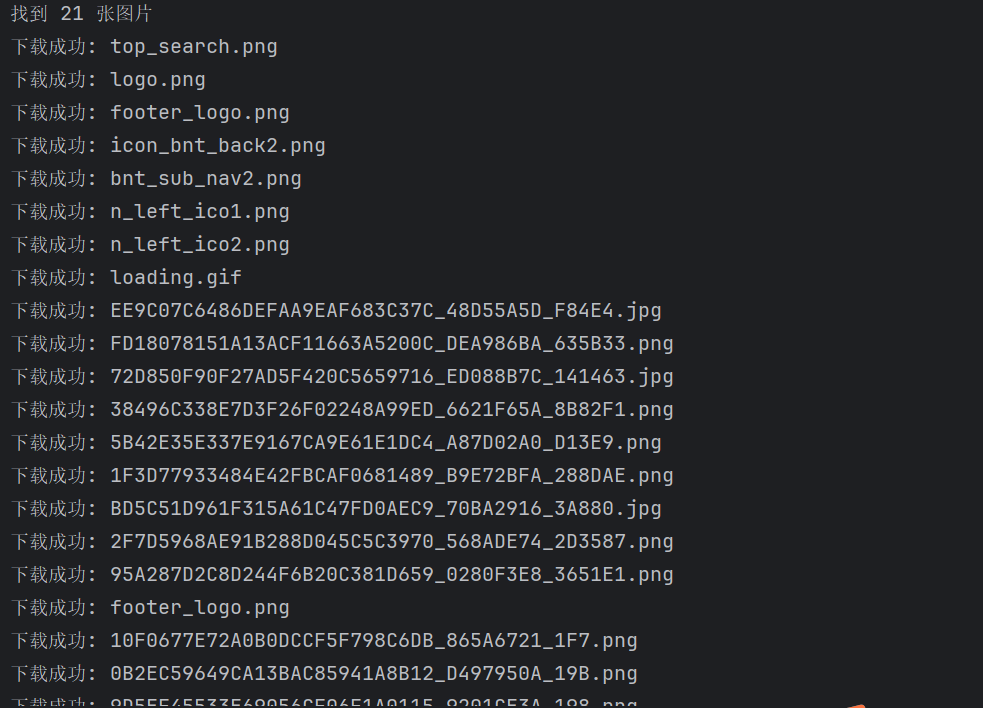
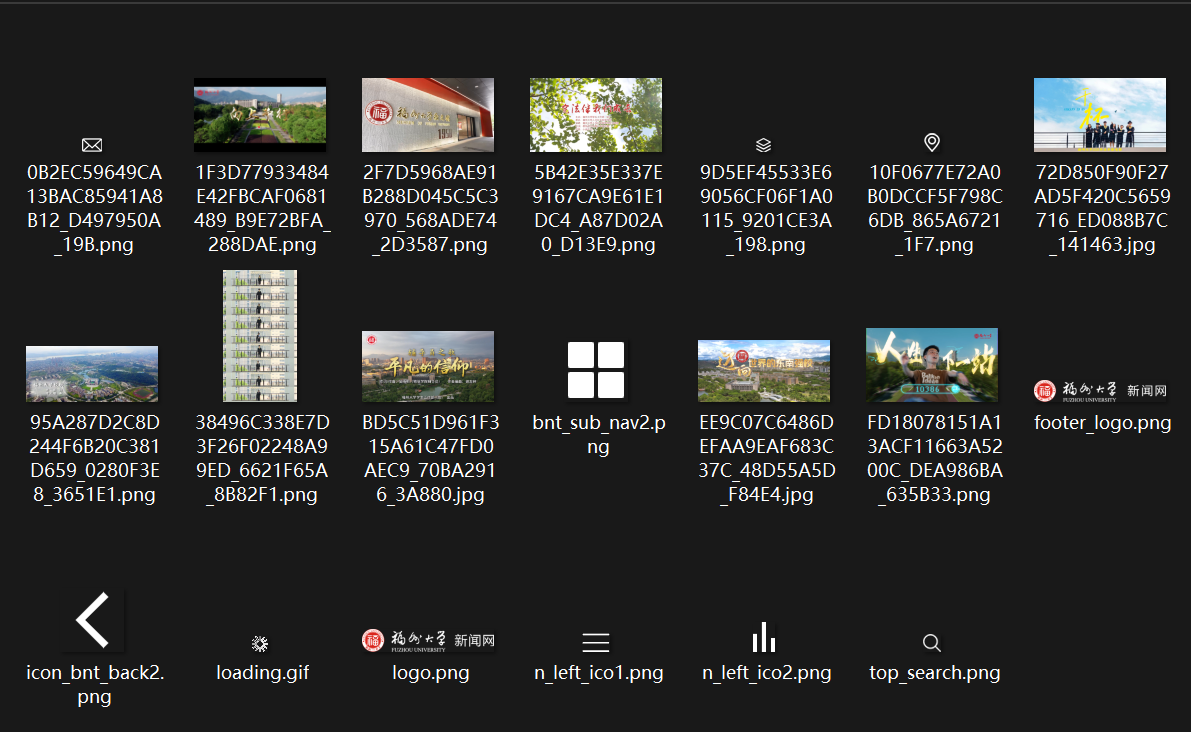
print(f"找到 {len(image_urls)} 张图片")
# 下载图片
downloaded_count = 0
for img_url in image_urls:
if download_image(img_url, download_folder):
downloaded_count += 1
time.sleep(0.5)
print(f"下载完成! 共下载 {downloaded_count} 张图片")
if __name__ == "__main__":
main()
3.2 心得体会
通过本次实践任务,进一步加深了我对爬取网页信息实践过程的理解,也让我掌握了更多与爬虫相关库方法的使用,懂得如何运用相应的方法和步骤爬取并保存网站上的图片,也提高了个人的编程实践能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号