爬虫技术:分布式
1.简单的分布式流程图
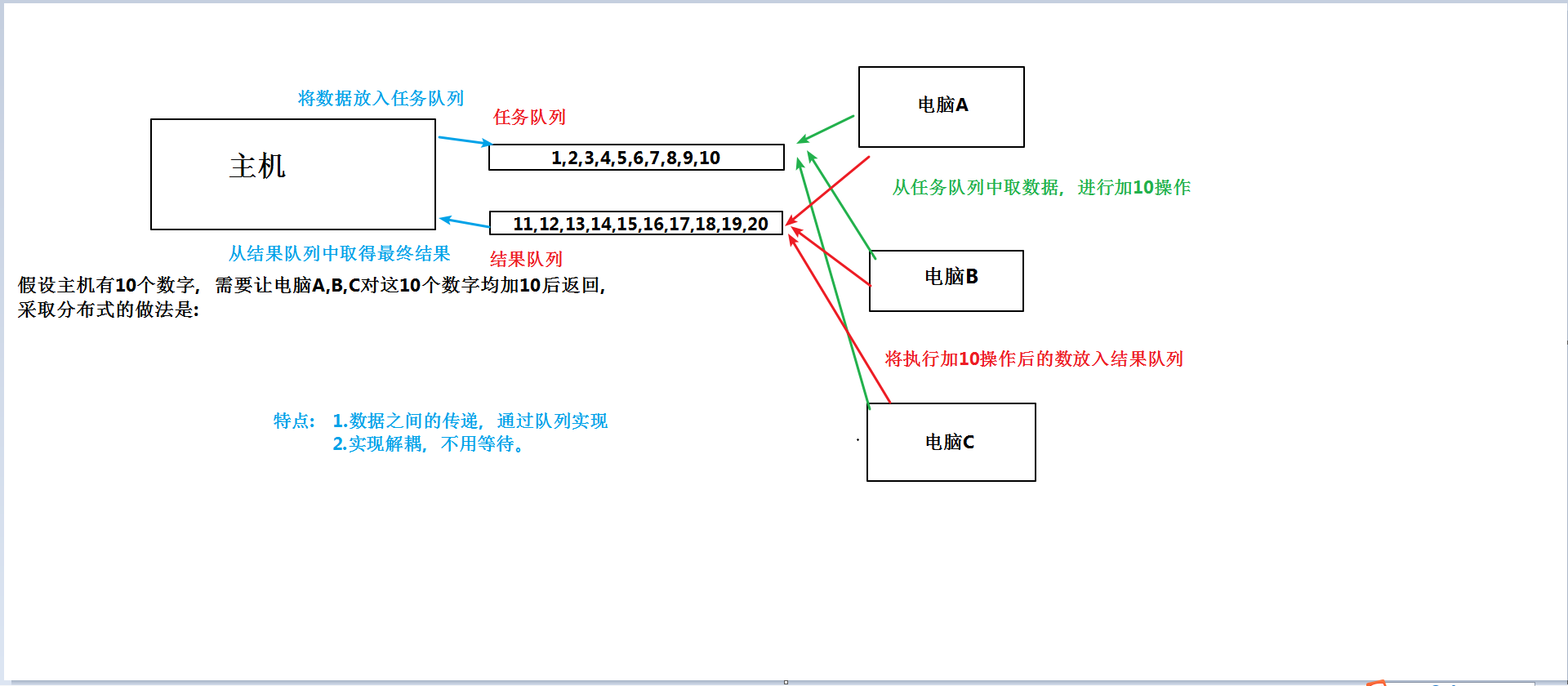
分布式:
import multiprocessing import multiprocessing.managers # 进程管理器 import random,time # 分布式进程 task_queue = multiprocessing.Queue() # 任务 resule_queue = multiprocessing.Queue() # 结果 def return_task(): """ :return: 任务队列 """ return task_queue def return_result(): """ :return: 结果队列 """ return resule_queue # 创建管理器类 class QueueManager(multiprocessing.managers.BaseManager): """ 进程管理器,实现队列和客户端共享 """ pass if __name__ == '__main__': multiprocessing.freeze_support() # 开启分布式支持 QueueManager.register("get_task",callable=return_task) # 注册函数给客户端调用 QueueManager.register("get_result",callable=return_result) # 注册函数给客户端调用 manager = QueueManager(address=("192.168.33.39",8888),authkey=123456) # 创建管理器,绑定ip、port和链接密码 # 开启管理器实例 manager.start() task = manager.get_task() result = manager.get_result() # 初始化数据 for i in range(10000): print("给任务队列里面放入数据:{}".format(i)) task.put(i) print("---" * 100) for i in range(10000): ret = result.get() print("从结果队列中取出数据:{}".format(ret)) # 关闭服务器 manager.shutdown
import multiprocessing import multiprocessing.managers # 进程管理器 import random,time # 分布式进程 task_queue = multiprocessing.Queue() # 任务 result_queue = multiprocessing.Queue() # 结果 # 创建管理器类 class QueueManager(multiprocessing.managers.BaseManager): """ 进程管理器,实现队列和客户端共享 """ pass if __name__ == '__main__': QueueManager.register("get_task") # 注册函数调用服务器 QueueManager.register("get_result") # 注册函数调用服务器 manager = QueueManager(address=("192.168.33.39",8888),authkey=123456) # 创建管理器,绑定ip、port和链接密码 # 链接服务器 manager.connect() task = manager.get_task() result = manager.get_result() for i in range(10000): data = task.get() print("客户端获取任务队列中的数据") data += 10 print("客户端将加工过的数据放入结果队列中") result.put(data)
多进程分布式爬虫的案例:
模块共6个:控制管理类(control_manager.py),网页内容下载类(download.py),页面解析类(Htmparse.py),数据写入类(save_manager.py),url管理类(url_manager.py),爬虫节点类(spidernode.py)
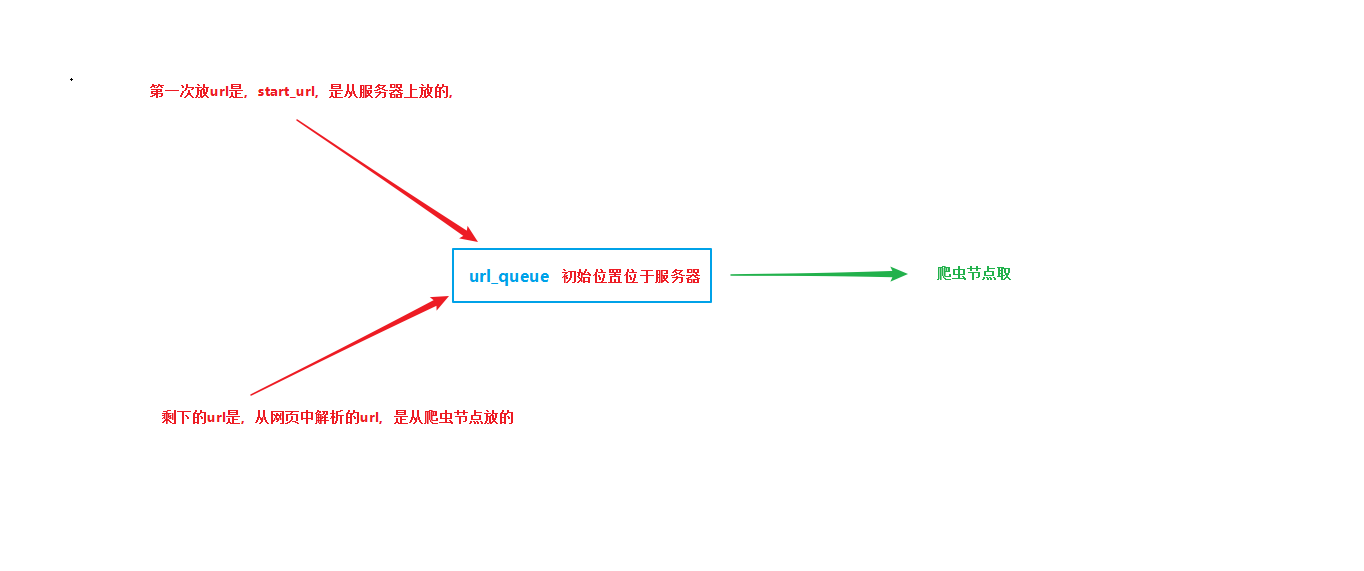
一:contorl_manager.py类似于服务器,几个队列分别放置在这里,url队列,结果队列,消息队列,存储队列
url队列:存放url,谁放,放在那里,谁取,从哪里取。
import time # 时间模块用来睡眠 from multiprocessing import Process # 创建进程 from multiprocessing.managers import BaseManager # 分布式进程之间通信的类 import multiprocessing from fenbushi_spider import url_manage from fenbushi_spider import save_manager class QueueManager(BaseManager): def start_manage(self, url_queue, result_queue):
# 用来开启队列管理器类,返回一个管理器的实例对象 QueueManager.register("get_url_queue", callable=lambda: url_queue)
# 继承了BaseManager类,使用里面的register方法,目的是注册一个方法(暴露接口给服务器之外),其他的进程用这个方法就能得到队列,进行取值和放值。 QueueManager.register("get_result_queue", callable=lambda: result_queue) manager = QueueManager(address=("192.168.33.31", 8888), authkey=123321) # 设置服务器的地址和链接口令,并返回服务器的实例对象 return manager def url_manage_process(self, url_queue, connect_queue, root_url):
# 开启url的管理进程,负责url的管理工作,例如去重等工作 urlmanager = url_manage.UrlManager() # 创建url管理类的实例对象,操作类里面的去重等方法。 urlmanager.add_new_url(root_url) # 将初始的url放入set集合中,进行md5的去重 while True: while (urlmanager.has_new_url()): # 调取url管理类的方法,看看未爬取的url集合是否为空。 new_url = urlmanager.get_new_url() # 从集合中取出新的url,然后这个url就要被md加密后,扔进爬取过的url集合中了。 url_queue.put(new_url) # 放入到url_queue,爬虫调度的时候,取出这个值。 print("url_queue是否为空{}".format(url_queue.empty())) print("已爬取集合的大小:{}".format(urlmanager.old_urls_size())) # 这个值一直为1,但是也能爬取 # TODO需要进一步研究 if (urlmanager.old_urls_size()) > 2000: # 通知爬虫节点结束工作 url_queue.put("end") # 用end的方式让其他进程结束 print("控制节点发起结束通知")
# 当超过2000的时候,会创建一个txt文件,显示已经爬过的url和未爬取的url。 urlmanager.save_process("new_url.txt", urlmanager.new_urls) urlmanager.save_process("old_url.txt", urlmanager.old_urls) return
# 当未爬取的url为空的时候。 try: if not connect_queue.empty(): url = connect_queue.get() urlmanager.new_urls.add(url) except BaseException as e: print(e) time.sleep(0.1) def result_solve_process(self, result_queue, connect_queue, store_queue): while True: try: if not result_queue.empty(): content = result_queue.get(True) if content["new_urls"] == "end": print("结果分析进程收到结束通知后结束") store_queue.put("end") return connect_queue.put(content["new_urls"]) store_queue.put(content["data"]) else: time.sleep(0.1) except BaseException as e: print(e) time.sleep(0.1) def save_process(self, store_queue): output = save_manager.DataOutput() while True: if not store_queue.empty(): data = store_queue.get() if data == "end": print("存储进程收到结束通知后结束") output.output_end(output.filepath) return output.store_data(data) else: time.sleep(0.1) if __name__ == '__main__': url_queue = multiprocessing.Queue() result_queue = multiprocessing.Queue() connect_queue = multiprocessing.Queue() store_queue = multiprocessing.Queue() node = QueueManager() manager = node.start_manage(url_queue, result_queue) url_manage_proc = Process(target=node.url_manage_process, args=( url_queue, connect_queue, "https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB")) result_solve_proc = Process(target=node.result_solve_process, args=(result_queue, connect_queue, store_queue)) save_proc = Process(target=node.save_process, args=(store_queue,)) url_manage_proc.start() result_solve_proc.start() save_proc.start() server = manager.get_server() server.serve_forever()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号