入门学习正则表达式regex(更新ing)
首发于个人的CSDN上: 入门学习正则表达式regex(更新ing)
前序
“以正则表达式来思考(think regularexpression)”——精通正则表达式(第三版)
- 所谓正则表达式,就是
一种描述字符串结构模式的形式化表达方法。
在发展的初期,这套方法仅限于描述正则文本,故此得名“
正则表达式(regular expression)”。
随着正则表达式研究的深入和发展,特别是
Perl语言的实践和探索,正则表达式的能力已经大大突破了传统的、数学上的限制,成为威力巨大的实用工具,在几乎所有主流语言中获得支持。
莫不如此,甚至
功能稍强大一些的文本编辑工具(IDEA、VS Code),都支持正则表达式。
尤其是在Web 兴起之后,开发任务中的一大部分甚至全部,都是对字符串的处理。相比简单的字符串比较、查找、替换,正则表达式提供了强大得多的处理能力(最重要的是,它能够处理“符合某种抽象模式”的字符串,而不是固化的、具体的字符串)。
熟练运用它们,能够节省大量的开发时间。
优势
-
一方面,因为正则表达式
处理的对象是字符串,或者抽象地说,是一个对象序列,而这恰恰是当今计算机体系的本质数据结构,我们围绕计算机所做的大多数工作,都归结为在这个序列上的操作,因此,正则表达式用途广阔。 -
另一方面,与大多数其他技术不同,
正则表达式具有超强的结构描述能力,而在计算机中,正是不同的结构把无差别的字节组织成千差万别的软件对象,再组合成为无所不能的软件系统,因此,描述了结构,就等于描述了系统。在这方面,正则表达式的地位是独特的。
What is 正则表达式?

正则表达式是``⼀组由字⺟和符号组成的特殊⽂本`,它可以⽤来从⽂本中找出满⾜你想要的格式的句⼦。
正则表达式可以从⼀个基础字符串中根据⼀定的匹配模式
替换⽂本中的字符串、验证表单、提取字符串
等等。
- ⼀个正则表达式是
⼀种从左到右匹配主体字符串的模式。
“
Regular expression”这个词⽐较拗⼝,我们常使⽤缩写的术语“regex”或“regexp”。
举例
假设⼀个⽤户命名的规则,让⽤户名包含字符、数字、下划线和连字符,以及限制字符的个数,好让名字看起来没那么丑。
我们使⽤以下正则表达式来验证⼀个⽤户名:
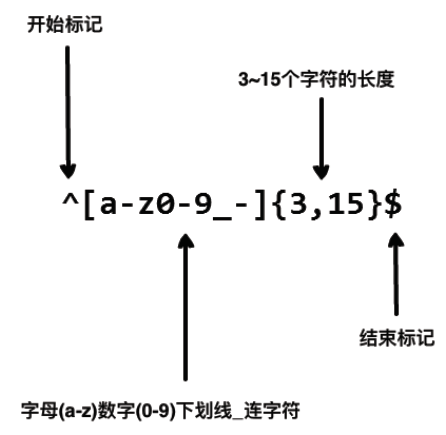
以上的正则表达式可以接受 john_doe 、jo-hn_doe 、john12_as 。
但不匹配Jo ,因为它包含了⼤写的字⺟⽽且太短了。
入门
- 正则表达式中"
/"是表达式开始和结束的标记。
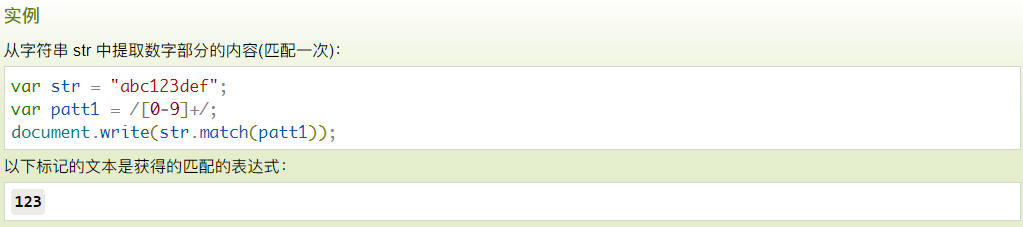
1 基本匹配
- 正则表达式其实就是在执⾏搜索时的格式,它由⼀些字⺟和数字组合⽽成。
- 例如:⼀个正则表达式
the,它表示⼀个规则:由字⺟t开始,接着是h,再接着是e。
- 例如:⼀个正则表达式
"the" => The fat cat sat on the mat.
- 正则表达式
123匹配字符串123。它逐个字符的与输⼊的正则表达式做⽐较。 - 正则表达式是
⼤⼩写敏感的,所以The不会匹配the。
"The" => The fat cat sat on the mat.
2 元字符
- 正则表达式
主要依赖于元字符。 - 元字符不代表他们本身的字⾯意思,
他们都有特殊的含义。- ⼀些元字符写在⽅括号中的时候有⼀些特殊的意思。以下是⼀些元字符的介绍:
| 元字符 | 描述 |
|---|---|
. |
句号匹配任意单个字符除了换⾏符 |
[] |
字符种类。匹配⽅括号内的任意字符 |
[^] |
否定的字符种类。匹配除了⽅括号⾥的任意字符 |
* |
匹配>=0个重复的在*号之前的字符 |
+ |
匹配>=1个重复的+号前的字符 |
? |
标记?之前的字符为可选 |
{n,m} |
匹配num个⼤括号之前的字符或字符集 (n <= num <= m) |
(xyz) |
字符集,匹配与 xyz 完全相等的字符串 |
| ` | ` |
\ |
转义字符,⽤于匹配⼀些保留的字符 `[ ] ( ) { } . * + ? ^ $ \ |
^ |
从开始⾏开始匹配 |
$ |
从末端开始匹配 |
2.1 锚点
2.1.1 ^ 号
^⽤来检查匹配的字符串是否在所匹配字符串的开头。- 例如,在
abc中使⽤表达式^a会得到结果a。但如果使⽤^b将匹配不到任何结果。因为在字符串abc中并不是以b开头。 - 例如,
^(T|t)he匹配以The或the开头的字符串。
- 例如,在
"(T|t)he" => The car is parked in the garage.
"^(T|t)he" => The car is parked in the garage.
2.2.2 $ 号
- 同理于
^号,$号⽤来匹配字符是否是最后⼀个。 - 例如,
(at\.)$匹配以at.结尾的字符串。
"(at\.)" => The fat cat. sat. on the mat.
"(at\.)$" => The fat cat. sat. on the mat.
2.2 运算符.
-
.是元字符中最简单的例⼦。 -
.匹配任意单个字符(包括空格),但不匹配换⾏符。- 例如,表达式
.ar匹配⼀个任意字符后⾯跟着是a和r的字符串。
- 例如,表达式
".ar" => The car parked in the garage.
2.3 字符集(字符组)
-
字符集也叫做字符类。 -
⽅括号
[]⽤来指定⼀个字符集。 -
在
[]中使⽤连字符来指定字符集的范围。- 在
[]中的字符集不关⼼顺序。
- 在
-
例如,表达式
[Tt]he匹配the和The。
"[Tt]he" => The car parked in the garage.
- ⽅括号的句号
[.]就表示句号. - 表达式
ar[.]匹配ar.字符串
"ar[.]" => A garage is a good place to park a car.
2.3.1 否定字符集
- ⼀般来说
^表示⼀个字符串的开头- 但,它⽤在⼀个⽅括号的开头的时候,
[^]它表示这个字符集是否定的。
- 但,它⽤在⼀个⽅括号的开头的时候,
- 例如,表达式
[^c]ar匹配⼀个后⾯跟着ar的除了c以外的任意字符,如sar、gar、par、#ar、&ar……
" [^c]ar" => The car parked in the garage.
2.4 重复次数
- 后⾯跟着元字符
+、*or?的,⽤来指定匹配⼦模式的次数。- 这些元字符在不同的情况下有着不同的意思。
*和+限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
2.4.1 * 号
*号匹配那些在*之前的字符出现⼤于等于0 次的字符。
*和+限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
- 例如,表达式
a*匹配0或更多个以a开头的字符。 - 表达式
[a-z]*匹配⼀个⾏中所有以⼩写字⺟开头的字符串。
"[a-z]*" => The car parked in the garage #21.
*字符和.字符搭配,可以匹配所有的字符.*。*和\s(表示匹配空格的符号)连起来⽤,如表达式\s*cat\s*匹配0或更多个空格开头、0或更多个空格结尾的cat字符串。
"\s*cat\s*" => The fat cat sat on the concatenation.
2.4.2 + 号
+号匹配那些在+号之前出现 >=1 次的字符。- 例如,表达式
c.+t匹配以⾸字⺟ c 开头以 t 结尾,中间跟着⾄少⼀个字符的字符串。
- 例如,表达式
"c.+t" => The fat cat sat on the mat.
2.4.3 ? 号
- 在正则表达式中,标记在元字符
?前⾯的字符为可选,即出现 0 或 1 次。- 例如,表达式
[T]?he匹配字符串he和The。
- 例如,表达式
"[T]he" => The car is parked in the garage.
"[T]?he" => The car is parked in the garage.
2.5 { } 号
- 在正则表达式中
{}是⼀个量词,常⽤来限定⼀个或⼀组字符可以重复出现的次数。- 例如, 表达式
[0-9]{2,3}匹配最少 2 位最多 3 位 0~9 的数字。
- 例如, 表达式
"[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
可以省略第⼆个参数。- 例如,
[0-9]{2,}匹配⾄少两位 0~9 的数字。
- 例如,
"[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
区别两个正则表达式,上式是
{2,}下式是{2}"[0-9]{2}" => The number was 9.99 97 but we rounded it off to 10.0.
- 如果逗号也省略掉则表示重复固定的次数。
- 例如,
[0-9]{3}匹配三位0~9的数字
- 例如,
"[0-9]{3}" => The number was 9.9997 but we rounded it off to 10.0.
2.6 | 或运算符
- 或运算符
|就表示或,⽤作判断条件。- 例如
(T|t)he|car匹配(T|t)he或car
- 例如
"(T|t)he|car" => The car is parked in the garage.
2.7 (...) 特征标群
特征标群是⼀组写在(...)中的子模式。(...)中包含的内容将会被看成⼀个整体,和数学中⼩括号()的作⽤相同。- 例如, 表达式
(ab)*匹配连续出现 0 或更多个 ab 的字符串。 - 如果没有使⽤
(...),那么表达式ab*将匹配连续出现 0 或更多个 b。
- 例如, 表达式
- 再⽐如之前说的
{}是⽤来表示前⾯⼀个字符出现指定次数。 - 但如果在
{}前加上特征标群(...)则表示整个标群内的字符重复 n 次。 - 我们还可以在
()中⽤ 或字符|表示或。- 例如,
(c|g|p)ar匹配car或gar或par
- 例如,
"(c|g|p)ar" => The car is parked in the garage.
2.8 \ 转义符号
-
反斜线
\在表达式中⽤于转义紧跟其后的字符。⽤于指定{ } [ ] / \ + * . $ ^ | ?这些特殊字符。 -
如果想要匹配这些特殊字符则要在其前⾯加上反斜线
\。- 但是!!!
\在字符组[]内部无效!!!
-
例如
.是⽤来匹配除换⾏符外的所有字符的。如果想要匹配句⼦中的.则要写成\. -
以下这个例⼦的
\.?是选择性匹配.
"(f|c|m)at\.?" => The fat cat sat on the mat.
"ega.att.com" => megawatt.compu ting wwega.att.comzz
"ega\.att\.com" => megawatt.compu ting wwega.att.comzz
进阶
- 正则表达式中"
/"是表达式开始和结束的标记。
1 简写字符集
正则表达式提供⼀些常⽤的字符集简写。如下:
| 简写 | 功能 |
|---|---|
. |
除换⾏符外的所有字符(包括空格) |
\w |
匹配所有字⺟数字,等同于 [a-zA-Z0-9_] |
\W |
匹配所有⾮字⺟数字,即符号,等同于: [^\w] |
\d |
匹配数字,即 [0-9] |
\D |
匹配⾮数字,即 [^\d] |
\s |
匹配所有空格字符,等同于: [\t\n\f\r\p{Z}] |
\S |
匹配所有⾮空格字符: [^\s] |
\f |
匹配⼀个换⻚符 |
\n |
匹配⼀个换⾏符 |
\r |
匹配⼀个回⻋符 |
\t |
匹配⼀个制表符 |
\v |
匹配⼀个垂直制表符 |
\p |
匹配 CR/LF(等同于 \r\n ),⽤来匹配 DOS ⾏终⽌符 |
2 标志
- js中使用正则对象:
new RegExp("模式"[,"标记"]))pattern(模式)表示正则表达式的文本flags(标志)表示i(忽略大小写)g(全文查找出现的所有匹配字符)m(多行查找)gi(全文查找、忽略大小写)ig(全文查找、忽略大小写)
2.1 i 忽略大小写(Case Insensitive)
- 修饰语
i⽤于忽略⼤⼩写。 - 例如,表达式
/The/gi表示在全局搜索The,- 其中的
i将其条件修改为忽略⼤⼩写,则变成搜索the和The,g表示全局搜索。
- 其中的
"/The/" => The fat cat sat on the mat.
"/The/gi" => The fat cat sat on the mat.
2.2 g 全局搜索 (Global search)
- 修饰符
g常⽤于执⾏⼀个全局搜索匹配,即“不仅仅返回第⼀个匹配的,⽽是返回全部”。- 例如,表达式
/.(at)/g表示搜索 任意字符(除了换⾏)+ at,并返回全部结果。
- 例如,表达式
"/.(at)/" => The fat cat sat on the mat.
"/.(at)/g" => The fat cat sat on the mat.
2.3 m 多行查找(Multiline)
- 多⾏修饰符
m常⽤于执⾏⼀个多⾏匹配。 - 像之前介绍的
(^,$)⽤于检查格式是否是在待检测字符串的开头或结尾。但我们如果想要它在每⾏的开头和结尾⽣效,我们需要⽤到``多⾏修饰符 m` 。- 例如,表达式 ``/at(.)?$/gm
表示⼩写字符 a 后跟⼩写字符 t ,末尾可选除换⾏符外任意字符`。
- 例如,表达式 ``/at(.)?$/gm
- 根据
m修饰符,以下例子表达式匹配每⾏的结尾:
"/.at(.)?$/" => The fat
cat sat
on the mat.
"/.at(.)?$/gm" => The fat
cat sat
on the mat.
3 贪婪匹配与惰性匹配 (Greedy vs lazy matching)
*和+限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
- 正则表达式
默认采⽤贪婪匹配模式,在该模式下意味着会匹配尽可能⻓的⼦串。 - 我们可以使⽤
?将贪婪匹配模式转化为惰性匹配模式。
"/(.*at)/" => The fat cat sat on the mat.
"/(.*?at)/" => The fat cat sat on the mat.
结尾(推荐正则表达式网站)
正则表达式用在比较复杂的情况时,就会比较头疼,多试试吧。这里给出我平时使用正则表达式的3个网站:
学习正则表达式的网站:
测试正则表达式的平台:
参考资料
[2] 正则表达式-菜鸟教程
Java的正则流派
//TODO 待学习……

 浙公网安备 33010602011771号
浙公网安备 33010602011771号