搜索引擎入门 (建立一个简单的java Lucene实例)
实例说明
实现对 钢铁是怎样练成的.txt 进行全文索引,以及和普通检索方式 (java.lang.String的 equals)进行效率对比
开发过程
1.将大文档切分成多个小文档
这一步 并非 是必须的,为了更好的展示 Lucene的一些功能,将文档切分为多个较小的文档,并给每个文档一个唯一的ID(文件名称)
3.eclipse 编写代码
4.效果测试
通过Lucene的检索 和 java字符串检索,进行性能上的比较,得出结论
项目准备
 eclipse 导入这两个jar包 (由于是入门实例 jar包为老版本,太新会报错)
eclipse 导入这两个jar包 (由于是入门实例 jar包为老版本,太新会报错)
1.文档预处理类
FilePreprocess
package lucene; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; public class FilePreprocess {
//预处理 public static void preprocess(File file,String outputDir){ try{
//拆分成小文件 splitToSmallFiles(file,outputDir); }catch(Exception e ){ e.printStackTrace(); } } public static void splitToSmallFiles(File file,String outputpath)throws IOException{ int filePointer = 0; //文件命名 自增序列 int MAX_SIZE = 10240; //设置文件大小 BufferedWriter writer = null; BufferedReader reader = new BufferedReader(new FileReader(file)); StringBuffer buffer = new StringBuffer(); String line = reader.readLine(); while(line != null){ buffer.append(line).append("\r\n"); if(buffer.toString().getBytes().length >= MAX_SIZE){ //如果超出限制大小 new file writer = new BufferedWriter(new FileWriter(outputpath + "output" + filePointer+".txt")); writer.write(buffer.toString()); writer.close(); filePointer ++; buffer = new StringBuffer(); } line = reader.readLine(); } writer = new BufferedWriter(new FileWriter(outputpath + "output" + filePointer + ".txt")); writer.write(buffer.toString()); writer.close(); }
//入口 public static void main(String [] args){ String inputFile = "f:\\book.txt"; //读取文件 String outputf = "f:\\outputFolder\\"; //文件预处理后输出目录 if(!new File(outputf).exists()){ new File(outputf).mkdirs(); } FilePreprocess f = new FilePreprocess(); f.preprocess(new File(inputFile), outputf); //分块处理 } }
》运行后 输出路径 则会生成 多个小文档

2.创建处理文档的索引类 IndexProcessor
package lucene; import java.io.BufferedReader; import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.index.IndexWriter; import jeasy.analysis.MMAnalyzer; public class IndexProcessor {
//索引存储目录 private String INDEX_STORE_PATH = "f:\\index"; //创建索引 public void createIndex(String inputDir){ try { //利用分词工具创建 IndexWriter IndexWriter writer = new IndexWriter(INDEX_STORE_PATH,new MMAnalyzer(),true); File filesDir = new File(inputDir); //取得 要建立 索引的文件数组 File[] files = filesDir.listFiles(); for(int i = 0 ;i < files.length ; i++){ String fileName = files[i].getName(); if(fileName.substring(fileName.lastIndexOf(".")).equals(".txt")){ //创建新的Document Document doc = new Document(); //为文件名创建一个 Field Field field = new Field("filename",files[i].getName(),Field.Store.YES,Field.Index.TOKENIZED); doc.add(field); field = new Field("content",loadFileToString(files[i]),Field.Store.NO,Field.Index.TOKENIZED); doc.add(field); //把Document加入 IndexWriter writer.addDocument(doc); } } writer.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } //加载文档 生成字符串 public String loadFileToString(File f) { try{ BufferedReader br = new BufferedReader(new FileReader(f)); StringBuffer sb = new StringBuffer(); String line = br.readLine(); while(line != null){ sb.append(line); line = br.readLine(); } br.close(); return sb.toString(); } catch (IOException e) { e.printStackTrace(); return null; } } public static void main(String[] args){ IndexProcessor pr = new IndexProcessor(); pr.createIndex("f://outputFolder"); } }
 索引目录生成
索引目录生成
3.创建索引搜索类 Search
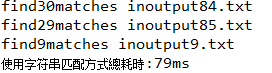
package lucene; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.util.Date; import java.util.Iterator; import java.util.LinkedHashMap; import java.util.Map; import org.apache.lucene.index.Term; import org.apache.lucene.index.TermDocs; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.TermQuery; public class Search { private String INDEX_STORE_PATH = "f:\\index"; //利用lucene 索引 搜索 public void indexSearch(String searchType,String searchKey){ try{ System.out.println("##使用索引方式搜索##"); System.out.println("======================"); //根据索引位置简历 IndexSearch IndexSearcher searcher = new IndexSearcher(INDEX_STORE_PATH); //建立搜索单元,searchType 代表要搜索的Field,searchKey代表关键字 Term t = new Term(searchType,searchKey); //由Term产生 Query Query q = new TermQuery(t); //搜索开始时间 Date beginTime = new Date(); //获取一个 <document,frequency>的枚举对象 TermDocs TermDocs docs = searcher.getIndexReader().termDocs(t); while(docs.next()){ System.out.print("find" + docs.freq() + "matches in"); System.out.println(searcher.getIndexReader().document(docs.doc()).getField("filename").stringValue()); } Date endTime = new Date(); long timeofsearch = endTime.getTime() - beginTime.getTime(); System.out.println("总耗时:" + timeofsearch); } catch(Exception e){ e.printStackTrace(); } } public void stringSearch(String keyword,String searchDir){ System.out.println("##使用字符串方式搜索##"); System.out.println("======================"); File filesDir = new File(searchDir); //返回目录文件夹所有文件数组 File[] files = filesDir.listFiles(); //HM 保存文件名和匹配次数对 Map rs = new LinkedHashMap(); //搜索开始时间 Date beginTime = new Date(); for(int i = 0 ;i < files.length ; i ++){ int hits = 0; try{ BufferedReader br = new BufferedReader(new FileReader(files[i])); StringBuffer sb = new StringBuffer(); String line = br.readLine(); while(line != null){ sb.append(line); line = br.readLine(); } br.close(); //将 stringBuffer 转化成 String,以便于搜索 String stringToSearch = sb.toString(); //从 0 索引 查询 -length + length = 0 int fromIndex = -keyword.length(); int len = stringToSearch.indexOf(keyword,fromIndex + keyword.length()); while((fromIndex = len)!= -1){ hits++; } //将文件名 和 匹配次数 加入 HashMap rs.put(files[i].getName(), new Integer(hits)); } catch(Exception e){ e.printStackTrace(); } } Iterator it = rs.keySet().iterator(); while(it.hasNext()){ String fileName = (String)it.next(); Integer hits = (Integer)rs.get(fileName); System.out.println("find" + hits.intValue() + "matches in"+ fileName); } Date endTime = new Date(); long timeOfSearch = endTime.getTime() - beginTime.getTime(); System.out.println("使用字符串匹配方式總耗時:" + timeOfSearch + "ms"); } public static void main(String[] args) { Search s = new Search(); s.indexSearch("content", "保尔"); System.out.println(); s.stringSearch("保尔", "f:\\outputFolder"); } }
通过控制台比对 效率 发现 索引匹配方式效率更高

同是大家闺秀,何必苦苦相逼

 浙公网安备 33010602011771号
浙公网安备 33010602011771号