2019-9-18练手爬虫日记
今天找了一个国外的网站练手,页面不是很难,就类似于主页面下面有很多子页面,使用火狐浏览器+xpath helper ,一切都像平时那样的随意,一切都很平常,但是在运行的时候将解析出来的数据进行打印,毫不犹豫的给到我了4个【】 ,ok没关系,代码出错了还好,接下来就从界面开始一点点的分析,沃德天,和我开始分析的一模一样,接下来开始质疑是不是js,沃德天,这个渣渣网站根本不是js,每个都是get方式,ok继续分析,沃德天,搞不出来了,那就问别人。
找了一个爬虫的群然后丢代码,丢问题,丢网站,丢自己尝试过的方式,丢自己目前的思路(这其实是提问的一种艺术)
里面先来了两个小白,居然质疑我的xpath解析式,我明明取的是@href ,他们居然告诉我要改成//text(),沃德天,谢谢你俩
后面来了一个应该和我差不多风采的,也许技术比我强那么一点点,但是他觉对没有我帅!
他使用的是这样的://a[contains(@href,'.aspx')]/@href
contains()方法,查看了下xpath官方文档

带图的是这样的,不带图的是下面这样:
说的太官方了,接着我按照大佬的解析式,去原文查看了下对应的结果,
发现是不太满意,因为aspx结尾的链接全搞进来了,并不是我想要的那块的链接, 没关系继续研究,
突然有一股力量冲进了我的大脑,拿着浏览界面的内容去对比下网页源码,很好,看到一个了不得的东西。
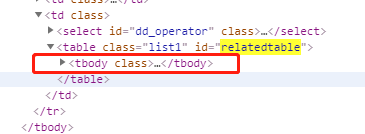
这是浏览界面,也就是xpath helper解析的那个。
接下来是源码界面:
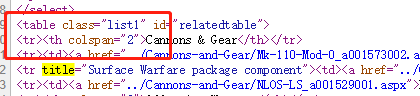
完全没有tbody这个鬼东西,沃德天,接下来按照源码去解析,成功拿到需要的东西。

最后总结一点:看到的不一定就是真的。保持理性的头脑,无时无刻你都是最帅的男人!
本文来自博客园,作者:黑山老道,转载请注明原文链接:https://www.cnblogs.com/meipu/p/11543979.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号