堆与优先队列
堆(Heap)
堆是一种完全二叉树,同时满足堆序性(物理存储通常用数组,效率更高)。
491cedfb-4101-46ef-9bd4-276cfe8727ff
完全二叉树就是满二叉树最后一层不满且左对齐。
- 大根堆(Max Heap):每个父节点的值 ≥ 其左右子节点的值(堆顶是最大值);
- 小根堆(Min Heap):每个父节点的值 ≤ 其左右子节点的值(堆顶是最小值)。
完全二叉树的用存储数组,为了方便计算索引一般从1开始
对于索引为i的节点:
- 左子节点索引:
2*i - 右子节点索引:
2*i - 父节点索引:(int)i/2
示例(小根堆):
逻辑结构(完全二叉树): 数组存储:[1, 3, 2, 6, 4, 5]
1
/ \
3 2
/ \ /
6 4 5堆排序
建堆:从最底部开始,确保每个局部根节点最大,不符合就交换,维护堆
排序:下沉调整,把根放到最后,之后维护堆,所以最终大根队排序,最大值在数组最后
<algorithm>库可以方便的实现建堆和排序
make_heap(nums.begin(), nums.end());//执行后构建大根堆
sort_heap(nums.begin(), nums.end());//执行后变成升序数组堆排序是原地排序,除了交换的中间量不需要额外内存。
升序用大根堆,降序用小根堆,时间复杂度 O(nlogn),空间复杂度 O(1)(原地实现);
堆排序是不稳定排序,适合内存受限、需要稳定时间复杂度的场景;
堆排序时候大规模数据。
优先队列
C++ 中的 优先队列(priority_queue) 是一种容器适配器,基于堆(heap) 数据结构实现,核心特性是:每次访问 / 删除的元素都是 “优先级最高” 的元素(默认是最大值优先,即大顶堆)。
使用优先队列需包含 <queue> 头文件并using namespace std;
| 函数名 | 功能描述 | 时间复杂度 |
|---|---|---|
push(val) | 向队列中插入元素,自动调整堆结构 | O(log n) |
pop() | 删除队首(优先级最高)元素,自动调整堆 | O(log n) |
top() | 访问队首元素(不删除),返回 const 引用 | O(1) |
empty() | 判断队列是否为空,返回 bool | O(1) |
size() | 返回队列中元素个数 | O(1) |
swap(pq) | 与另一个 priority_queue 交换内容 | O(1) |
堆结构:基于完全二叉树实现,保证:
- 插入元素(
push):O (logn)(堆化向上) - 删除堆顶(
pop):O (logn)(堆化向下) - 访问堆顶(
top):O(1)
注意:优先队列不支持随机访问,只能通过 top() 访问堆顶元素,遍历需通过 top()+pop() 实现(遍历后队列清空)。
误认为队列是有序的:优先队列仅保证堆顶是极值,其他元素的顺序不保证(底层是堆,不是有序数组)。
Top K 问题:
leetcode最后一块石头的重量
这个是求用当前最大两个数的问题。
class Solution {
public:
int lastStoneWeight(vector<int>& stones) {
priority_queue<int> q;
for(auto i : stones){
q.push(i);
}
while(q.size() > 1){
int a =q.top();
q.pop();
int b =q.top();
q.pop();
if(a > b){q.push(a - b);}
}
return q.empty() ? 0 : q.top();
}
};优先队列会维护堆排序,二次排序快。
leetcode最小K个数
O (nlogn)写法:
class Solution {
public:
vector<int> smallestK(vector<int>& arr, int k) {
priority_queue<int,vector<int>,greater<int>> q;
for(auto i : arr){
q.push(i);
}
vector<int> ans;
for(int i = 0;i < k;++i){
ans.push_back(q.top());
q.pop();
}
return ans;
}
};用优先队列(priority_queue)求 Top K 问题(前 K 大 / 前 K 小元素)的时间复杂度最优是 O (n log K),空间复杂度是 O (K),其中 n 是原始数据的总个数,K 是需要找的 “前 K” 数量。
O (nlogK)写法:
class Solution {
public:
vector<int> smallestK(vector<int>& arr, int k) {
priority_queue<int,vector<int>> q;
vector<int> ans;
if(k == 0){return{};}
for(int i = 0;i < k;++i){
q.push(arr[i]);
}
for(int i = k;i < arr.size(); ++i){
if(arr[i] < q.top()){
q.pop();
q.push(arr[i]);
}
}
for(int i = 0;i < k;++i){
ans.push_back(q.top());
q.pop();
}
return ans;
}
};leetcode最小的K对数
找两个升序数组成的对的和的最小的K个
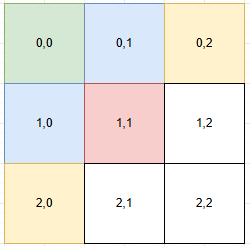 由于
由于 nums1 和 nums2 均为非递减排序,最小的数对一定是 (nums1 [0], nums2 [0]),后续候选数对只能是 (i+1,j) 或 (i,j+1)(即当前数对的右邻或下邻)—— 其他位置的数对和必然更大,无需考虑。但是这种后续对的选择会产生重复浪费,对于【1,0】和【0,1】都会将【1,1】入队。
为了解决这种大规模的重复,我们使用哈希编码的方法(L1行L2列)
从【0,0】向右编码是 0,1,2,3,…,L2,L2 + 1,…,2 L2,2 L2 + 1,…,L1 * L2 + L2
可以发现每行第一个为 i * (L2 + 1) + 0,每个数都有唯一编码i * (L2 + 1) + j。
class Solution {
public:
vector<vector<int>> kSmallestPairs(vector<int>& nums1, vector<int>& nums2, int k) {
vector<vector<int>> ans;
int l1 = nums1.size(), l2 = nums2.size();
priority_queue<vector<int>, vector<vector<int>>, greater<vector<int>>> pq;
unordered_set<long long> visited;
if (l1 > 0 && l2 > 0) {
long long key = static_cast<long long>(0) * l2 + 0;
visited.insert(key);
pq.push({nums1[0] + nums2[0], 0, 0});
}
while (k-- > 0 && !pq.empty()) {
auto curr = pq.top();
pq.pop();
int i = curr[1], j = curr[2];
ans.push_back({nums1[i], nums2[j]});
if (i + 1 < l1) {
long long key = static_cast<long long>(i + 1) * l2 + j;
if (!visited.count(key)) {
visited.insert(key);
pq.push({nums1[i+1] + nums2[j], i+1, j});
}
}
if (j + 1 < l2) {
long long key = static_cast<long long>(i) * l2 + (j + 1);
if (!visited.count(key)) {
visited.insert(key);
pq.push({nums1[i] + nums2[j+1], i, j+1});
}
}
}
return ans;
}
};
 浙公网安备 33010602011771号
浙公网安备 33010602011771号