
目标网址:url = 'https://xiang.zu.anjuke.com/fangyuan/p3/#'
最终目的:将所有信息建立数据库并存入。
代码:
import re,requests,pymongo client = pymongo.MongoClient('localhost',27017) message = client['message'] add = message['123456'] headers = { 'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' } url = 'https://xiang.zu.anjuke.com/fangyuan/p3/#' def getlinks(url): wb_data = requests.get(url,headers=headers) links = re.findall('div class="zu-info".*?href="(.*?)"',wb_data.text,re.S) for link in links: link = link.strip('<%= item.url %>') getinfos(link) def getinfos(url): try: wb_data = requests.get(url,headers=headers) addresses = re.findall('class="house-info-item l-width".*?<a.*?>(.*?)</a>.*?<a.*?>(.*?)</a>.*?<a.*?>(.*?)</a>',wb_data.text,re.S) names = re.findall('class="broker-name".*?>(.*?)</h2>',wb_data.text,re.S) phones = re.findall('div class="broker-mobile".*?class="iconfont".*?</i>(.*?)</div>',wb_data.text,re.S) moneys = re.findall('class="price".*?>.*?<em.*?>(.*?)</em>',wb_data.text,re.S) areas = re.findall('class="house-info-item".*?span class="info".*?>(.*?)</span>',wb_data.text,re.S) for address,name,phone,money,area in zip(addresses,names,phones,moneys,areas): data = { 'url':url, '地址':address[1]+address[2]+address[0], '联系人':name, '电话':phone, '月租':money, '面积':area } add.insert_one(data) except: pass getlinks(url)
总结:此项目并没有什么难度,主要是re的构造以精准抓取以及信息的提取。
最终效果图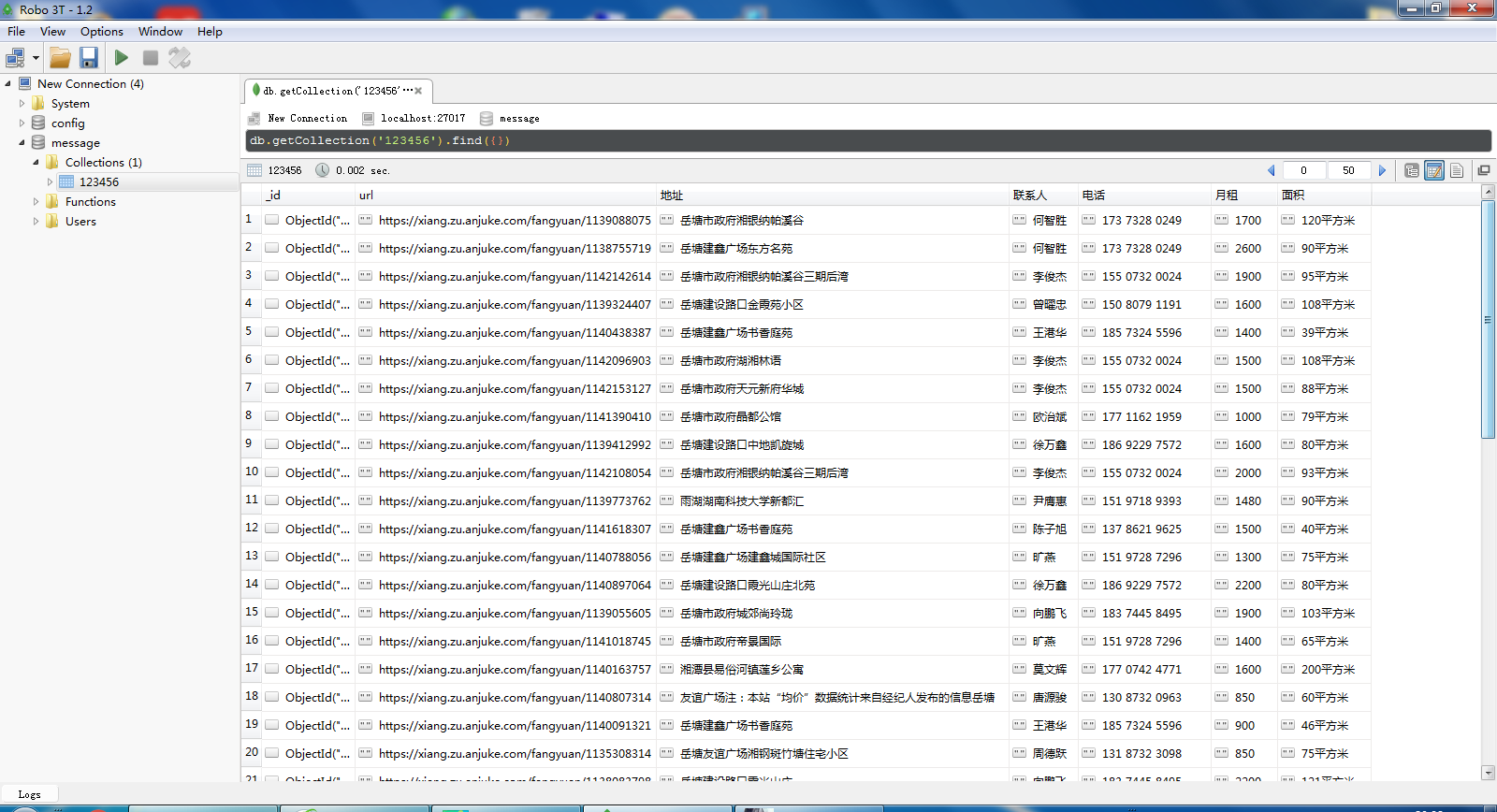
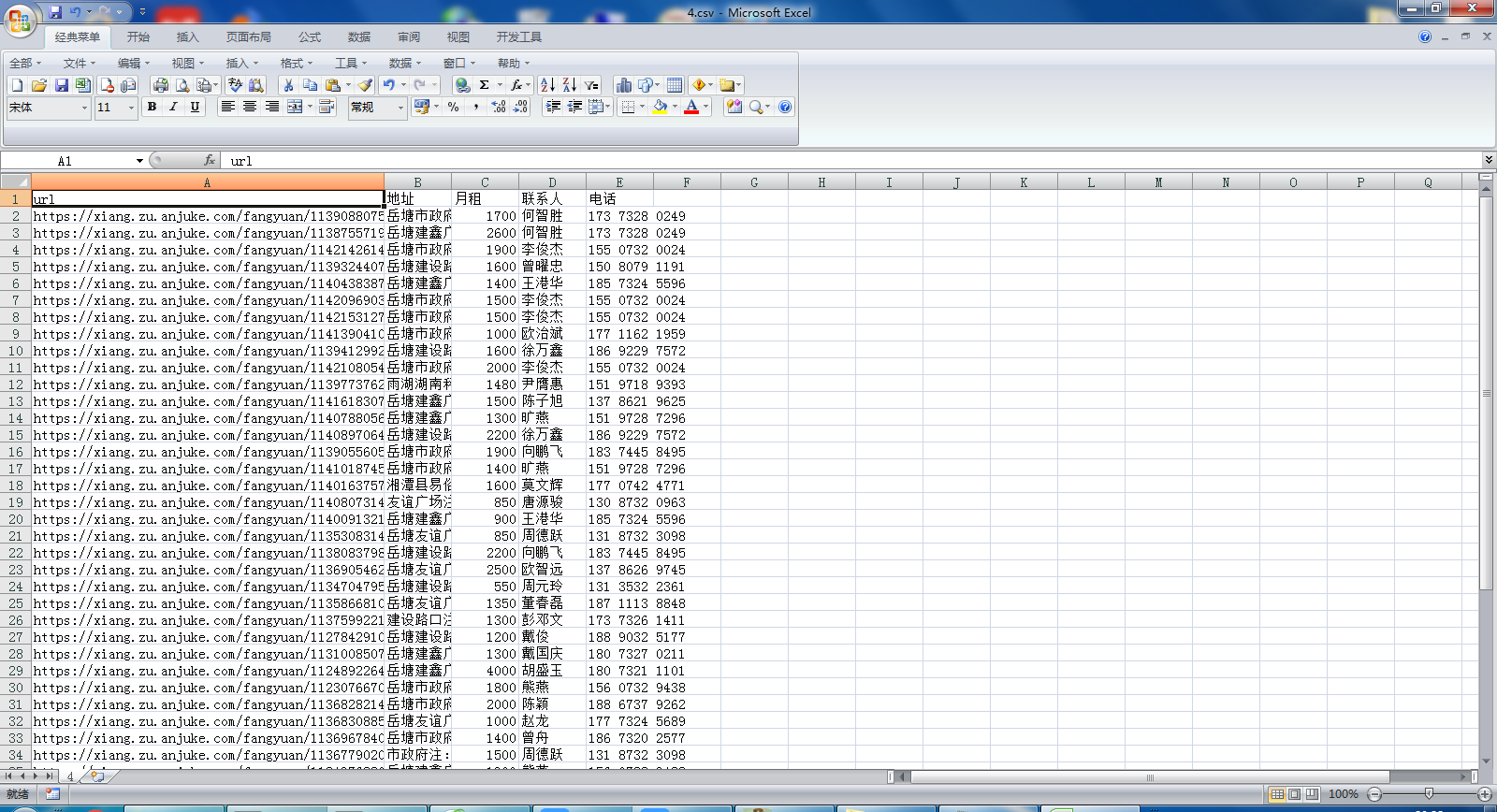
我们还可以将数据库导出成xls文件更加方便查看 如果没有数据库可视化工具的话。
mogonexport -d 库名 -c 表名 --csv -f 导出字段 -o 2.csv文件类型 #在bin文件夹下

总有一个理由,会让我们开始变强。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号