
0.ml基础
1.交叉验证测量准确率
在模型训练中,若使用全部的训练数据进行一次训练,可能会出现预测精度非常高的情况,此时应警惕出现了过拟合。因为在对模型效果进行评估时,可以考虑使用K折交叉验证。
采用分层抽样的方法将数据集分为k份,其中k-1份用于训练,剩余1份用于测试,共训练k次,使用k个测试结果的均值。
model=LogisticRegression() from sklearn.model_selection import cross_val_score cross_val_score(model,x_train,y_train,cv=3,scoring='roc_auc')
2.混淆矩阵
交叉验证方法虽然通过求均值的方式避免了因为数据过拟合产生的准确率虚高的假象,但对于一个有偏数据集而言(比如90%数据都是0,只有10%数据是1,此时若预测结果恒为1,仍有90%的准确率但模型没有意义),因此考虑引入混淆矩阵来多维度衡量模型。
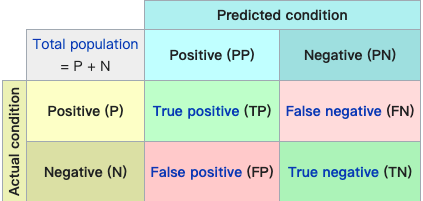
矩阵的行表示真实值,列表示预测值。对于一个完美的分类器而言,只会有True的结果,所以只会在对角线上有值。
根据混淆矩阵可以定义精度和召回率来综合衡量模型
$精度=\frac{TP}{TP+FP}$
$召回率=\frac{TP}{TP+FN}$
召回率也称为灵敏度或者真正类率,是分类器正确检测到的正类实例的比率。
由于精度和召回率不能同时升高,在不同的应用场景下需要进行取舍。可定义F1分数来将精度和召回率组合成单一的指标
$F_{1}=\frac{2}{\frac{1}{精度}+\frac{1}{召回率}}$
3.ROC曲线
ROC曲线的横轴是假正率,纵轴是真正率(召回率)
假正率是被错误分为正类的负类实例比率,$FPR=\frac{FP}{FP+TN}$
召回率越高,假正类率越大,虚线表示随机分类器的roc曲线,一个好的分类器应该离虚线越远越好。
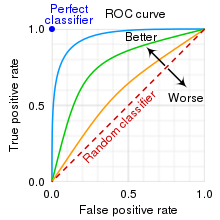
若要更好的量化分类器的好坏,还可以测量曲线下面积(AUC),AUC越大的模型,分类越准确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号